solr 7.x 配置ikanalyzer
一.使用支持高版本的ikanalzyer进行分词配置(尾部有文件链接)
ikanalyzer最后更新是在2012年,对于高版本的lucee不支持.但网上还是有被修改过的Ikanalyzer的6.5.0版本,试了下可以支持lucene7.x整合到solr7.x中也没什么问题
1.jar包准备

2.把IkAnalyzer6.5的jar包放在tomcat8/webapps/solr/WEB-INF/lib目录下
3.把ext.dic,IKanalyzer.cfg.xml,stopword.dic放在tomcat8/webapps/solr/WEB-INF/classes目录下
4.修改solrcore下的的manged-schema(4.10的版本叫做schema.xml),增加以下代码
1 <!--配置中文分词器-->
2 <fieldType name="text_ik" class="solr.TextField">
3 <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
4 </fieldType>
5
6 <!--配置中文分词器使用的field-->
7 <field name="ik" type="text_ik" indexed="true" stored="true"/>
5.启动tomcat并选择我们配置好的ik进行测试
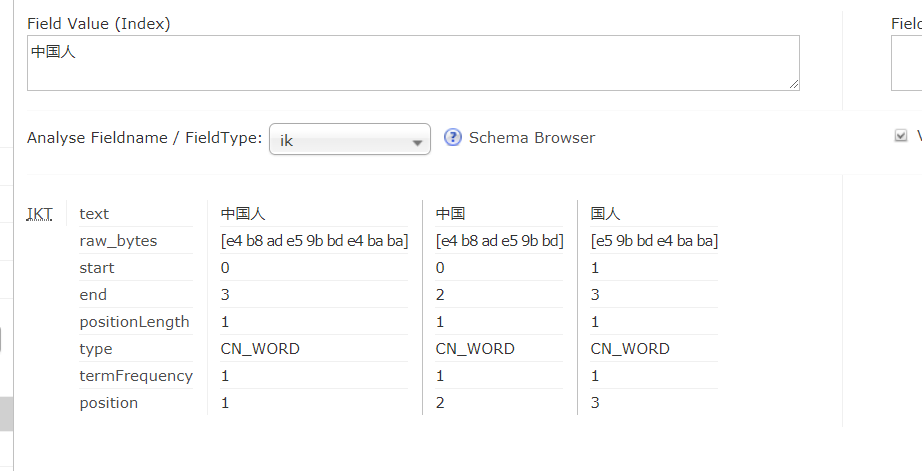
6.拓展分词字典
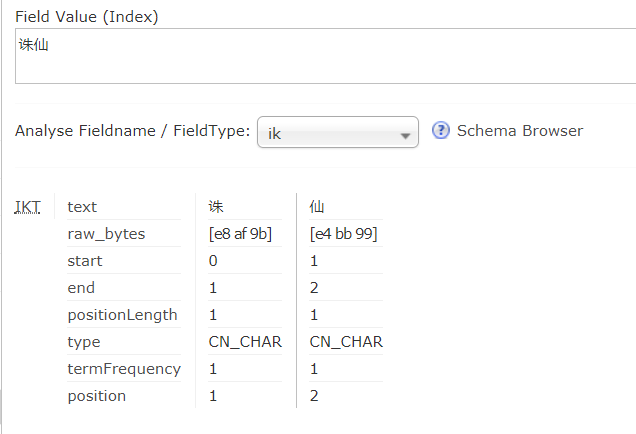
此时似乎ikanayzer并未生效,先停掉tomcat,然后编辑tomcat8/solr/webapps/WEB-INF/classes目录下的ext.dic,添加
"诛仙"(不要使用记事本进行编辑,如果已经用记事本打开过ext.dic,请换一款编辑器,并在另存为时选择文件编码为utf-8无bom,但是测试的时候发现stopword.dic可以直接用记事本编辑),重启后测试.
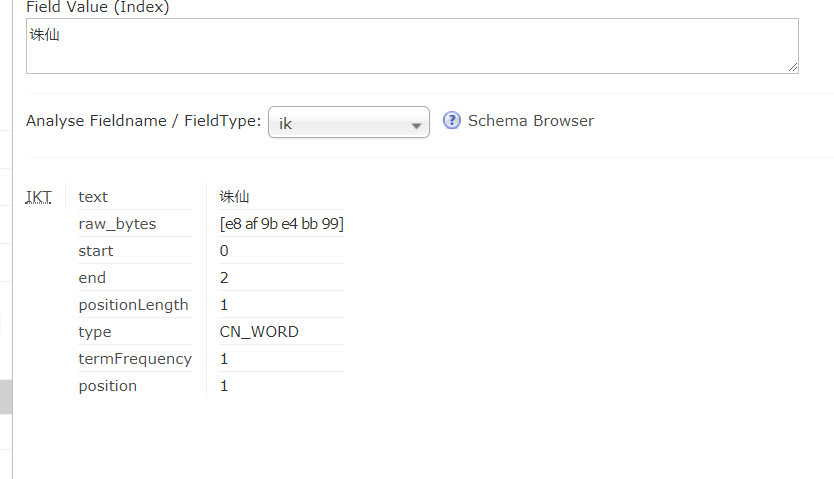
二.使用老版本的ikanalyzer与solr整合(尾部有文件链接)
1.jar包准备
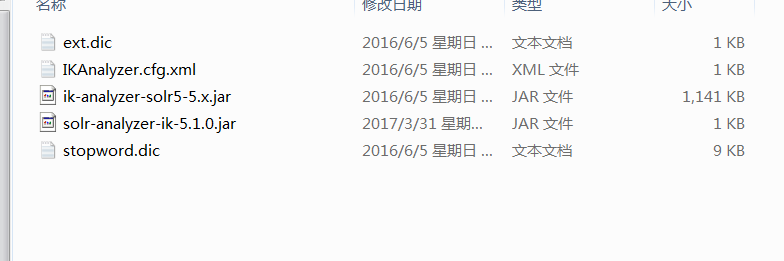
2.把ik-analyzer-solr5-5.5.x.jar以及solr-analyzer-ik-5.1.0.jar拷贝到tomcat8/webapps/solr/WEB-INF/lib目录下
把,把ext.dic,IKanalyzer.cfg.xml,stopword.dic放在tomcat8/webapps/solr/WEB-INF/classes目录下
3.重复一的4,5,6步骤即可
4.文件链接

 浙公网安备 33010602011771号
浙公网安备 33010602011771号