
【Game Engine Architecture 2】
1、endian swap 函数

floating-point endian-swapping:将浮点指针reinterpert_cast 成整数指针,或使用 union 变成整形来swap.
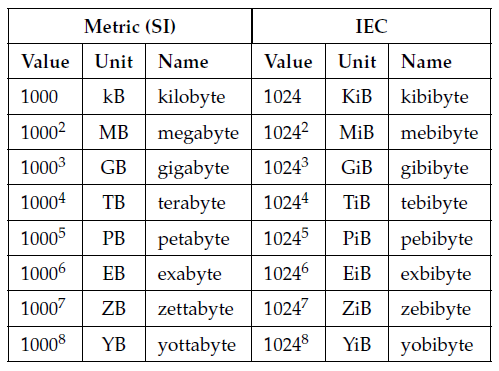
2、metric (SI) units like kilobytes (kB) and megabytes (MB) are power of 10. kilo means 10^3, not 1024.
To resolve this ambiguity, the International Electrotechnical Commission (IEC) in 1998 established a new set of SI-like prefixes for use in computer science.
kibibyte:1024 bytes. KiB
megibyte: 1024 x 1024 bytes. MiB
3、An object file contains not only the compiled machine code for all of the functions defined in the .cpp file, but also all of its global and static variables. In addition, an object file may contain unresolved references to functions and global variables defined in other .cpp files.
4、Declaration vs Definition
• A declaration is a description of a data object or function. It provides the compiler with the name of the entity and its data type or function signature (i.e., return type and argument type(s)).
• A definition, on the other hand, describes a unique region of memory in the program. This memory might contain a variable, an instance of a struct or class or the machine code of a function.
declaration -> 名字&类型
definition -> 名字&类型&内存
function signature with an optional prefix of extern:

变量的定义必须使用 extern:

5、inline function definitions must be placed in header files if they are to be used in more than one translation unit. Note that it is not sufficient to tag a function declaration with the inline keyword in a .h file and then place the body of that function in a .cpp file. The compiler must be able to “see” the body of the function in order to inline it.

6、Templates and Header Files
The definition of a templated class or function must be visible to the compiler across all translation units in which it is used. As such, if you want a template to be usable in more than one translation unit, the template must be placed into a header file (just as inline function definitions must be). The declaration and definition of a template are therefore inseparable: You cannot declare templated functions or classes in a header but “hide” their definitions inside a .cpp file, because doing so would render those definitions invisible within any other .cpp file that includes that header.
模板定义必须放在头文件中,和 inline function 一样。
7、Linkage
Every definition in C and C++ has a property known as linkage. A definition with external linkage is visible to and can be referenced by translation units other than the one in which it appears. A definition with internal linkage can only be “seen” inside the translation unit in which it appears and thus cannot be referenced by other translation units.
By default, definitions have external linkage. The static keyword is used to change a definition’s linkage to internal.
8、Executable Image
When a C/C++ program is built, the linker creates an executable file. Most UNIX-like operating systems, including many game consoles, employ a popular executable file format called the executable and linking format (ELF). Executable files on those systems therefore have a .elf extension. The Windows executable format is similar to the ELF format; executables under Windows have a .exe extension.
Whatever its format, the executable file always contains a partial image of the program as it will exist in memory when it runs.
The executable image is divided into contiguous blocks called segments or sections. image is usually comprised of at least the following four segments:
1. Text segment. Sometimes called the code segment, this block contains executable machine code for all functions defined by the program.
2. Data segment. This segment contains all initialized global and static variables. The memory needed for each global variable is laid out exactly as it will appear when the program is run, and the proper initial values are all filled in. So when the executable file is loaded into memory, the initialized global and static variables are ready to go.
3. BSS segment. “BSS” is an outdated name which stands for “block started by symbol.” This segment contains all of the uninitialized global and static variables defined by the program. The C and C++ languages explicitly define the initial value of any uninitialized global or static variable to be zero. But rather than storing a potentially very large block of zeros in the BSS section, the linker simply stores a count of how many zero bytes are required to account for all of the uninitialized globals and statics in the segment. When the executable is loaded into memory, the operating system reserves the requested number of bytes for the BSS section and fills it with zeros prior to calling the program’s entry point (e.g., main() or WinMain()).
4. Read-only data segment. Sometimes called the rodata segment, this segment contains any read-only (constant) global data defined by the program. For example, all floating-point constants (e.g., const float kPi = 3.141592f;) and all global object instances that have been declared with the const keyword (e.g., const Foo gReadOnlyFoo;) reside in this segment. Note that integer constants (e.g., const int kMaxMonsters = 255;) are often used as manifest constants by the compiler, meaning that they are inserted directly into the machine code wherever they are used. Such constants occupy storage in the text segment, but they are not present in the read-only data segment.
9、function static variable
A function-static variable is lexically scoped to the function in which it is declared (i.e., the variable’s name can only be “seen” inside the function). It is initialized the first time the function is called (rather than before main() is called, as with file-scope statics). But in terms of memory layout in the executable image, a function-static variable acts identically to a file-static global variable—it is stored in either the data or BSS segment based on whether or not it has been initialized.

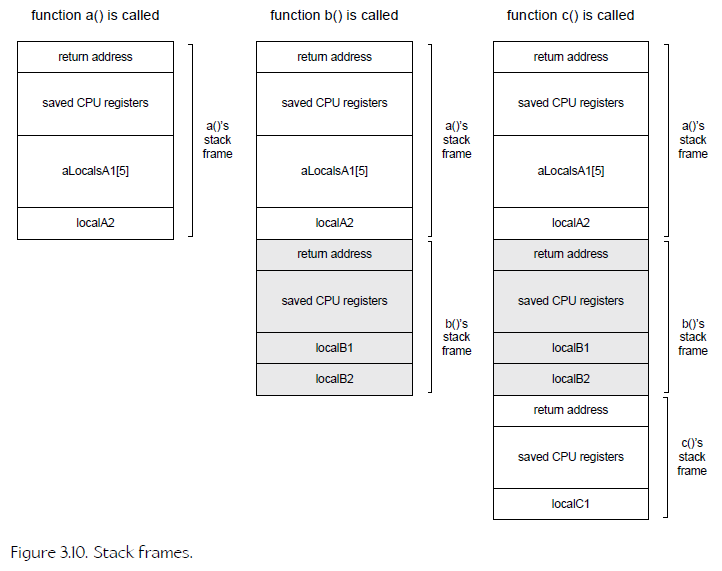
10、Stack Frame
1. It stores the return address of the calling function
2. The contents of all relevant CPU registers are saved in the stack frame.
3. all local variables declared by the function; these are also known as automatic variables.
11、The visibility of a class-static variable is determined by the use of public:, protected: or private: keywords in the class declaration.
类中的静态变量只是 declaration,必须在类外定义才行。

12、Why does the compiler leave these “holes”? The reason lies in the fact that every data type has a natural alignment, which must be respected in order to permit the CPU to read and write memory effectively. The alignment of a data object refers to whether its address in memory is a multiple of its size.
内存是为了CPU读写高效。对齐的意思是,数据的地址必须是其size的倍数。
alignment and packing
• An object with 1-byte alignment resides at any memory address.
• An object with 2-byte alignment resides only at even addresses (i.e., addresses whose least significant nibble is 0x0, 0x2, 0x4, 0x8, 0xA, 0xC or 0xE).
• An object with 4-byte alignment resides only at addresses that are a multiple of four (i.e., addresses whose least significant nibble is 0x0, 0x4, 0x8 or 0xC).
• A 16-byte aligned object resides only at addresses that are a multiple of 16 (i.e., addresses whose least significant nibble is 0x0).
末尾的padding,是为了 array context 环境下的对齐。
13、CPU
• an arithmetic/logic unit (ALU) for performing integer arithmetic and bit shifting,
• a floating-point unit (FPU) for doing floating-point arithmetic (typically using the IEEE 754 floating-point standard representation),
• virtually all modern CPUs also contain a vector processing unit (VPU) which is capable of performing floating-point and integer operations on multiple data items in parallel,
• a memory controller (MC) or memory management unit (MMU) for interfacing with on-chip and off-chip memory devices,
• a bank of registers which act as temporary storage during calculations (among other things)
• a control unit (CU) for decoding and dispatching machine language instructions to the other components on the chip, and routing data between them.

A vector processing unit (VPU) acts a bit like a combination ALU/FPU, in that it can typically perform both integer and floating-point arithmetic.
Today’s CPUs don’t actually contain an FPU per se. Instead, all floatingpoint calculations, even those involving scalar float values, are performed by the VPU. optimizing compilers will typically convert math performed on float variables into vectorized code that uses the VPU anyway.
14、Status Register
contains bits that reflect the results of the most-recent ALU operation. For instance, if the result of a subtraction is zero, the zero bit (typically named “Z”) is set within the status register, otherwise the bit is cleared. Likewise, if an add operation resulted in an overflow, meaning that a binary 1 must be “carried” to the next word of a multi-word addition, the carry bit (often named “C”) is set, otherwise it is cleared.
The flags in the status register can be used to control program flow via conditional branching, or they can be used to perform subsequent calculations, such as adding the carry bit to the next word in a multi-word addition.
15、Register Formats
FPU’s and VPU’s registers are typically wider than the ALU’s GPRs.
The physical separation of registers between ALU and FPU is one reason why conversions between int and float were very expensive, back in the days when FPUs were commonplace. Not only did the bit pattern of each value have to be converted back and forth but the data also had to be transferred physically between the general-purpose integer registers and the FPU’s registers.
16、Clock
CPU can perform at least one primitive operation on every cycle. It’s important to realize that one CPU instruction doesn’t necessarily take one clock cycle to execute.
17、MIPS & FLOPS
Power The “processing power” of a CPU or computer can be defined in various ways. One common measure is the throughput of the machine—the number of operations it can perform during a given interval of time. Throughput is expressed either in units of millions of instructions per second (MIPS) or floating-point operations per second (FLOPS).
Because instructions or floating-point operations don’t generally complete in exactly one cycle, and because different instructions take differing numbers of cycles to run, the MIPS or FLOPS metrics of a CPU are just averages.
18、Buses
Data is transferred between the CPU and memory over connections known as buses.
A bus is just a bundle of parallel digital “wires” called lines, each of which can represent a single bit of data. When the line carries a voltage signal it represents a binary one, and when the line has no voltage (0 volts) it represents a binary zero. A bundle of n single-bit lines arranged in parallel can transmit an n-bit number (i.e., any number in the range 0 through 2^n -1).
A typical computer contains two buses: An address bus and a data bus.
19、n-Bit Computers
You may have encountered the term “n-bit computer.” This usually means a machine with an n-bit data bus and/or registers.
20、Instruction Set Architecture (ISA)
The set of all instructions supported by a given CPU, along with various other details of the CPU’s design like its addressing modes and the in-memory instruction format, is called its instruction set architecture or ISA.
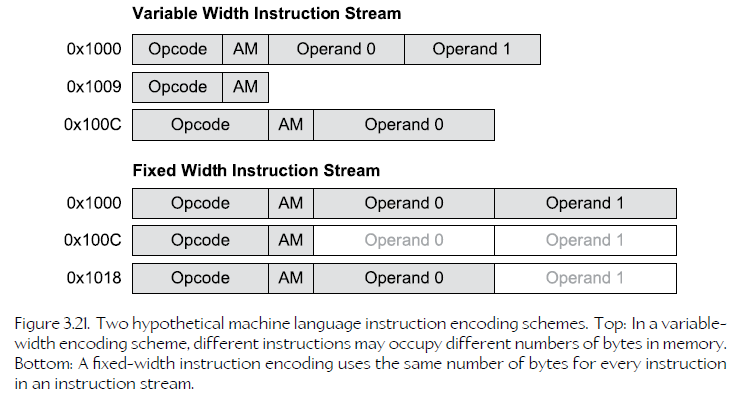
21、Machine Language
In some ISAs, all instructions occupy a fixed number of bits; this is typical of reduced instruction set computers (RISC). In other ISAs, different types of instructions may be encoded into differently-sized instruction words; this is common in complex instruction set computers (CISC).
22、Memory Mapping
Whenever a physical memory device is assigned to a range of addresses in a computer’s address space, we say that the address range has been mapped to the memory device
Address ranges needn’t all map to memory devices—an address range might also be mapped to other peripheral devices, such as a joypad or a network interace card (NIC). This approach is called memory-mapped I/O because the CPU can perform I/O operations on a peripheral device by reading or writing to addresses, just as if they were oridinary RAM.
memory-mapped I/O,CPU通过读写内存的操作,来实现硬件的IO操作。
23、Video Memory
A range of memory addresses assigned for use by a video controller is known as video RAM (VRAM).
A bus protocol such as PCI, AGP or PCI Express (PCIe) is used to transfer data back and forth between “main RAM” and VRAM, via the expansion slot’s bus. This physical separation between main RAM and VRAM can be a significant performance bottleneck, and is one of the primary contributors to the complexity of rendering engines and graphics APIs like OpenGL and DirectX 11.
24、Virtual Memory
Whenever a program reads from or writes to an address, that address is first remapped by the CPU via a look-up table that’s maintained by the OS. The remapped address 1) might end up referring to an actual cell in memory (with a totally different numerical address). 2) It might also end up referring to a block of data on-disk. 3) Or it might turn out not to be mapped to any physical storage at all.
the entire addressable memory space (that’s 2n byte-sized cells if the address bus is n bits wide) is conceptually divided into equally-sized contiguous chunks known as pages.Page sizes differ from OS to OS, but are always a power of two—a typical page size is 4 KiB or 8 KiB. Assuming a 4 KiB page size, a 32-bit address space would be divided up into 1,048,576 distinct pages, numbered from 0x0 to 0xFFFFF, as shown in Table 3.2.


the address is split into two parts: the page index and an offset within that page (measured in bytes). For a page size of 4 KiB, the offset is just the lower 12 bits of the address, and the page index is the upper 20 bits, masked off and shifted to the right by 12 bits. For example, the virtual address 0x1A7C6310 corresponds to an offset of 0x310 and a page index of 0x1A7C6.
The page index is then looked up by the CPU’s memory management unit (MMU) in a page table that maps virtual page indices to physical ones. (The page table is stored in RAM and is managed by the operating system.)

25、The Translation Lookaside Buffer (TLB)
an average program will tend to reuse addresses within a relatively small number of pages, rather than read and write randomly across the entire address range. A small table known as the translation lookaside buffer (TLB) is maintained within the MMU on the CPU die, in which the virtual-to-physical address mappings of the most recently-used addresses are cached.
26、Memory Architectures for Latency Reduction
The simplest memory cell has a single port, meaing only one read or write operation can be performed by it at any given time. Multi-ported RAM allows multiple read and/or write operations to be performed simultaneously, thereby reducing the latency caused by contention when multiple cores, or multiple components within a single core, attempt to access a bank of memory simultaneously. As you’d expect, a multi-ported RAM requires more transistors per bit than a single-ported design, and hence it costs more and uses more real estate on the die than a single-ported memory.
27、The Memory Gap
Whereas a register-based instruction still takes between one and 10 cycles to complete on an Intel Core i7, an access to main RAM can take on the order of 500 cycles to complete!
28、Cache Lines
To take advantage of locality of reference, memory caching systems move data into the cache in contiguous blocks called cache lines rather than caching data items individually.
系统缓存的不仅仅是一个数据,而是一整块数据,叫做 cache line.
Mapping Cache Lines to Main RAM Addresses
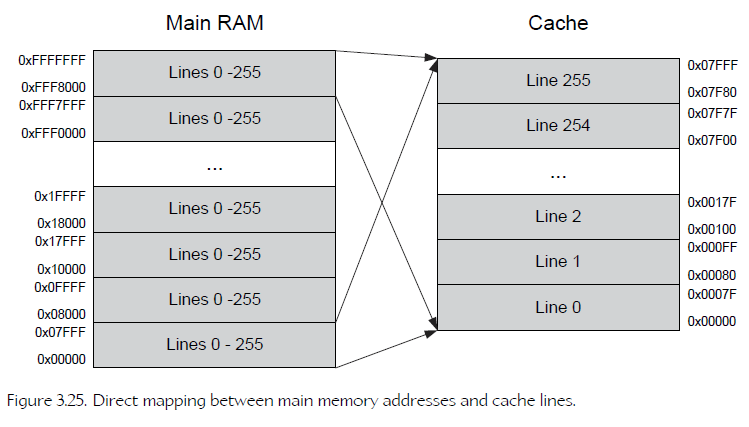
The cache can only deal with memory addresses that are aligned to a multiple of the cache line size . Put another way, the cache can really only be addressed in units of lines, not bytes. Hence we need to convert our byte’s address into a cache line index.
cache 只能按 line 访问,不按byte访问。
Consider a cache that is 2^M bytes in total size, containing lines that are 2^n in size. The n least-significant bits of the main RAM address represent the offset of the byte within the cache line. We strip off these n least-significant bits to convert from units of bytes to units of lines (i.e., we divide the address by the cache line size, which is 2n). Finally we split the resulting address into two pieces: The (M - n) least-significant bits become the cache line index, and all the remaining bits tell us from which cache-sized block in main RAM the cache line came from. The block index is known as the tag.
假设Cache大小为 2^M,CacheLine大小为 2^n。则一个物理地址的最右n位,为Line中的偏移;右起 n+1-M位(M-n)位为 cache line index;右起M+1位开始,中 block index (tag)

29、the complete sequence of events of reading a byte from main RAM
The CPU issues a read operation. The main RAM address is converted into an offset, line index and tag. The corresponding tag in the cache is checked, using the line index to find it.
If the tag in the cache matches the requested tag, it’s a cache hit. In this case, the line index is used to retrieve the line-sized chunk of data from the cache, and the offset is used to locate the desired byte within the line.
If the tags do not match, it’s a cache miss. In this case, the appropriate line-sized chunk of main RAM is read into the cache, and the corresponding tag is stored in the cache’s tag table. Subsequent reads of nearby addresses (those that reside within the same cache line) will therefore result in much faster cache hits.
所以注意,不同 Block 下相同的 Line Index ,会互相覆盖。这叫 cache evicting
30、2-way set associative cache,用于解决 cache evicting 问题。
2-way set associative cache, each main RAM address maps to two cache lines. This is illustrated in Figure 3.27.

31、Write Policy
The simplest kind of cache is called a write-through cache; in this relatively simple cache design, all writes to the cache are mirrored to main RAM immediately.
cache与 main RAM同步。
In a write-back (or copy-back) cache design, data is first written into the cache and the cache line is only flushed out to main RAM under certain circumstances, such as when a dirty cache line needs to be evicted in order to read in a new cache line from main RAM, or when the program explicitly requests a flush to occur.
cache 先缓存数据,当需要写入 main RAM时才写入。
32、Multi-Core
When multiple CPU cores share a single main memory store, things get more complicated. It’s typical for each core to have its own L1 cache, but multiple cores might share an L2 cache, as well as sharing main RAM

33、Nonuniform Memory Access (NUMA)
In a NUMA system, each core is provided with a relatively small bank of high-speed dedicated RAM called a local store.
Like an L1 cache, a local store is typically located on the same die as the core itself, and is only accessible by that core.
But unlike an L1 cache, access to the local store is explicit. A local store might be mapped to part of a core’s address space, with main RAM mapped to a different range of addresses. Alternatively, certain cores might only be able to see the physical addresses within its local store, and might rely on a direct memory access controller (DMAC) to transfer data between the local store and main RAM.
The PlayStation 3 is a classic example of a NUMA architecture. The PS3 contains a single main CPU known as the Power processing unit (PPU), eight coprocessors known as synergistic processing units (SPUs), and an NVIDIA RSX graphics processing unit (GPU).
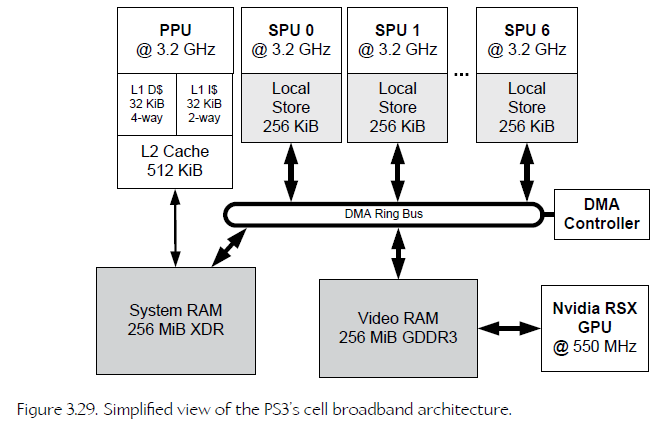
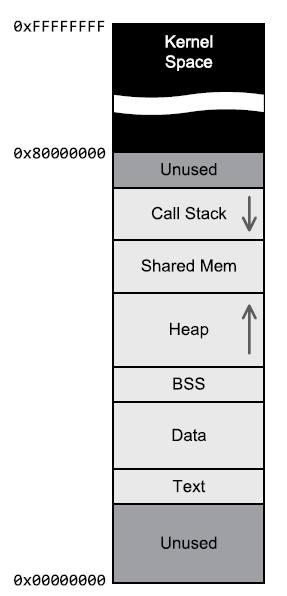
34、Example Process Memory Map
35、Threads
• a block of general-purpose memory associated with each thread, known as thread local storage (TLS).
36、
37、
38、

 浙公网安备 33010602011771号
浙公网安备 33010602011771号