二分图判定、匹配问题
二分图判定:
先由定理:
一张无向图是二分图, 当且仅当图中不存在奇数环.
证明如下:


由此可知, 如果要证明一张图是二分图, 可以采用两种颜色进行染色, 一个节点被标记后它的所有相邻节点应被标记为与之相反的颜色, 如果在标记过程中存在冲突则有奇数环的存在, 退出判定. 染色法可以用dfs实现.
以luogu P1330为例, 采用邻接表存图, 代码如下:
/* * @Author: Hellcat * @Date: 2020-03-07 11:32:52 * luogu P1330 */ #include <bits/stdc++.h> using namespace std; const int N = 2e5 + 10, M = 4e5 + 10; int n, m; int h[N], e[M], ne[M], query[N], idx, cnt, tmp, ans; int color[N]; void add(int a, int b) { e[idx] = b, ne[idx] = h[a], h[a] = idx++; } bool dfs(int u, int c) { color[u] = c; query[++cnt] = u; for(int i = h[u]; i != -1; i = ne[i]) { int j = e[i]; if(!color[j]) { if(!dfs(j, 3 - c)) return false; } else if(color[j] == c) return false; } return true; } int main() { memset(h, -1, sizeof(h)); scanf("%d%d", &n, &m); while(m--) { int a, b; scanf("%d%d", &a, &b); add(a, b), add(b, a); } bool flag = true; for(int i = 1; i <= n; i++) if(!color[i]) { if(!dfs(i, 1)) { flag = false; break; } else{ for(int i = 1; i <= cnt; i++) if(color[query[i]] == 1) tmp++; ans += min(tmp, cnt - tmp); tmp = 0; cnt = 0; } } if(flag) printf("%d\n", ans); else puts("Impossible"); }
二分图最大匹配:
匈牙利算法(Hungarian Algorithm)
匈牙利算法, 又称增广路算法, 是由匈牙利数学家Edmonds于1965年提出,因而得名。匈牙利算法是基于Hall定理中充分性证明的思想,它是部图匹配最常见的算法,该算法的核心就是寻找增广路径,它是一种用增广路径求二分图最大匹配的算法。
----摘自 进阶指南
匈牙利算法是一种在多项式时间内求解任务分配问题的组合优化算法,并推动了后来的原始对偶方法。美国数学家哈罗德·库恩于1955年提出该算法。此算法之所以被称作匈牙利算法,是因为算法很大一部分是基于以前匈牙利数学家Dénes Kőnig和Jenő Egerváry的工作之上创建起来的。
-- --摘自 维基百科
-----如果觉得定理难懂 看看博客趣写算法中的解释
以下参考自: https://blog.csdn.net/dark_scope/article/details/8880547
通过数代人的努力,你终于赶上了剩男剩女的大潮,假设你是一位光荣的新世纪媒人,在你的手上有N个剩男,M个剩女,每个人都可能对多名异性有好感(-_-||暂时不考虑特殊的性取向),如果一对男女互有好感,那么你就可以把这一对撮合在一起,现在让我们无视掉所有的单相思(好忧伤的感觉),你拥有的大概就是下面这样一张关系图,每一条连线都表示互有好感。
(由此也可以知道匈牙利算法中只会用到从第一个集合指向第二个集合的边,所以只用存一个方向的边 按照有向图处理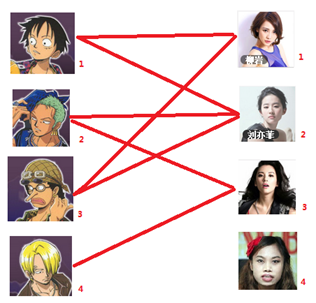
红线代表图中初始连边
本着救人一命,胜造七级浮屠的原则,你想要尽可能地撮合更多的情侣,匈牙利算法的工作模式会教你这样做:
==========================================================================
一: 先试着给1号男生找妹子,发现第一个和他相连的1号女生还名花无主,got it,连上一条蓝线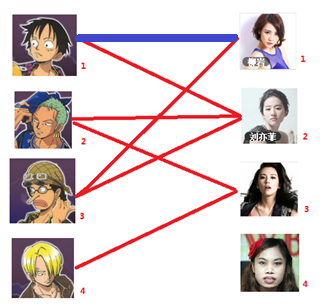
==========================================================================
二:接着给2号男生找妹子,发现第一个和他相连的2号女生名花无主,got it

==========================================================================
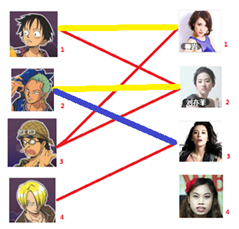
三:接下来是3号男生,很遗憾1号女生已经有主了,怎么办呢?
我们试着给之前1号女生匹配的男生(也就是1号男生)另外分配一个妹子。
(黄色表示这条边被临时拆掉) ((其实就是被绿啦
与1号男生相连的第二个女生是2号女生,但是2号女生也有主了,怎么办呢?我们再试着给2号女生的原配 重新找个妹子(注意这个步骤和上面是一样的,这是一个递归的过程)

此时发现2号男生还能找到3号女生,那么之前的问题迎刃而解了,回溯回去
2号男生可以找3号妹子~~~ 1号男生可以找2号妹子了~~~ 3号男生可以找1号妹子
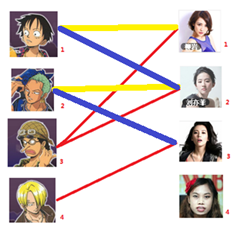
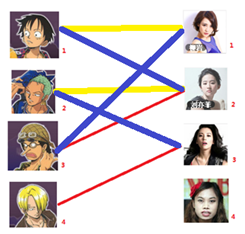
所以在第三步后得到的结果为:
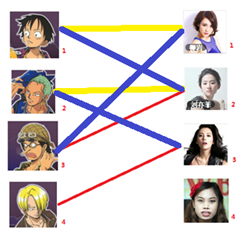
==========================================================================
四: 接下来是4号男生,很遗憾,按照第三步的节奏我们没法给4号男生腾出来一个妹子,我们实在是无能为力了……香吉士同学走好。
==========================================================================
这就是匈牙利算法的流程,其中找妹子是个递归的过程,最最关键的字就是“腾”字
其原则大概是:有机会上,没机会创造机会也要上 (匈牙利算法的核心
(追女生是不是也是这个道理呢
模板题为luogu P3386
使用邻接表存储的代码如下:


/* * @Author: Hellcat * @Date: 2020-03-07 20:40:04 */ #include <bits/stdc++.h> using namespace std; const int N = 1010, M = 1e6 + 10; bool vis[N]; // 标记第二个集合中的点是否被遍历 /* 邻接表存储所有边, 由于匈牙利算法中只会用到从第一 个集合指向第二个集合的边,所以这里只用存一个方向的边 */ int h[N], e[M], ne[M], idx; int n, m, k; int match[N]; // 配对的结果 即存储第二个集合中的每个点当前匹配到第一个集合中的点是哪个 inline int read() { int x = 0, f = 1; char ch = getchar(); while (ch < '0' || ch >'9') { if (ch == '-')f = -1; ch = getchar(); } while (ch >= '0'&& ch <= '9') { x = x * 10 + ch - '0'; ch = getchar(); } return f * x; } bool dfs(int x) { // 邻接表 for(int i = h[x]; ~i; i = ne[i]) { int j = e[i]; if(!vis[i]) { vis[i] = true; if(!match[j] || dfs(match[j])) { match[j] = x; return true; } } } return false; } void add(int a, int b) { e[idx] = b, ne[idx] = h[a], h[a] = idx++; } int main() { scanf("%d%d%d", &n, &m, &k); memset(h, -1, sizeof(h)); memset(match, 0, sizeof(match)); while(k--) { int a, b; a = read(); b = read(); if(a > n || b > m || a > m || b > n) continue; add(a, b); } int res = 0; for(int i = 1; i <= n; i++) { memset(vis, 0, sizeof(vis)); if(dfs(i)) res++; } printf("%d\n", res); }
耗时:

使用邻接矩阵的代码如下:
/* * @Author: Hellcat * @Date: 2020-03-07 20:40:04 */ #include <bits/stdc++.h> using namespace std; bool vis[1010]; int G[1010][1010]; int match[1010]; int n, m, k; inline int read() { int x = 0, f = 1; char ch = getchar(); while (ch < '0' || ch >'9') { if (ch == '-')f = -1; ch = getchar(); } while (ch >= '0'&& ch <= '9') { x = x * 10 + ch - '0'; ch = getchar(); } return f * x; } bool dfs(int x) { // 邻接矩阵 for(int i = 1; i <= m; i++) { if(!vis[i] && G[x][i]) { vis[i] = 1; if(!match[i] || dfs(match[i])) { match[i] = x; return true; } } } return false; } int main() { scanf("%d%d%d", &n, &m, &k); memset(G, 0, sizeof(G)); memset(match, 0, sizeof(match)); for(int i = 0; i < k; i++) { int a, b; a = read(); b = read(); if(a > n || b > m || a > m || b > n) continue; G[a][b] = 1; } int res = 0; for(int i = 1; i <= n; i++) { memset(vis, 0, sizeof(vis)); if(dfs(i)) res++; } printf("%d\n", res); }
耗时:

可以发现使用邻接表存储时间复杂度较低 事实上, 邻接矩阵复杂度O(V^3) 而邻接表为O(VE) 但由于匈牙利算法中重复匹配次数并不多 所以是低于这个最坏情况的复杂度.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号