深入理解SVM,详解SMO算法
今天是机器学习专题第35篇文章,我们继续SVM模型的原理,今天我们来讲解的是SMO算法。
公式回顾
在之前的文章当中我们对硬间隔以及软间隔问题都进行了分析和公式推导,我们发现软间隔和硬间隔的形式非常接近,只有少数几个参数不同。所以我们着重来看看软间隔的处理。
通过拉格朗日乘子法以及对原问题的对偶问题进行求解,我们得到了二次规划:
它应该满足的KTT条件如下:
也就是说我们要在这些条件下去求解(1)式的极值,在这个约束的情况下,虽然我们已经把式子化简成了只有一种参数\(\alpha\),但这个极值又应该怎么求呢?为了解决这个问题,我们需要引入一个新的算法,也是今天的文章的主要介绍的内容——SMO算法。
SMO算法简介
SMO的全写是Sequential Minimal Optimization,翻译过来是序列最小优化算法。算法的核心思想是由于我们需要寻找的是一系列的\(\alpha\)值使得(1)取极值,但问题是这一系列的值我们很难同时优化。所以SMO算法想出了一个非常天才的办法,把这一系列的\(\alpha\)中的两个看成是变量,其它的全部固定看成是常数。
这里有一个问题是为什么我们要选择两个\(\alpha\)看成是变量而不选一个呢?选一个不是更加简单吗?因为我们的约束条件当中有一条是\(\sum y_i\alpha_i=0\),所以如果我们只选择一个\(\alpha\)进行调整的话,那么显然会破坏这个约束。所以我们选择两个,其中一个变化,另外一个也随着变化,这样就可以保证不会破坏约束条件了。
为了方便叙述,我们默认选择的两个\(\alpha\)分别是\(\alpha_1, \alpha_2\)。另外由于我们涉及\(x_i^Tx_j\)的操作,我们令\(K_{ij}=x_i^Tx_j\)。这样上面的(1)式可以写成:
其中由于\(y_1 = \pm 1\),所以\(y_i^2 = 1\),上面的Constant表示除了\(\alpha_1, \alpha_2\)以外的常数项。我们假设\(\alpha_1y_1 + \alpha_2y_2 = k\),其中\(\alpha_1, \alpha_2 \in [0, C]\),由于\(y_i\)只有两个选项1或者-1,所以我们可以分情况讨论。
分情况讨论
首先我们讨论\(y_1\)和\(y_2\)不同号时,无非两种,第一种情况是\(\alpha_1 - \alpha_2 = k\),也就是\(\alpha_2 = \alpha_1 - k\),我们假设此时k > 0,第二种情况是\(\alpha_2 = \alpha_1 + k\),我们假设此时k < 0。我们很容易发现对于第一种情况,如果 k < 0,其实就是第二种情况,同样对于第二种情况,如果k > 0其实就是第一种情况。这变成了一个线性规划问题,我们把图画出来就非常清晰了。

针对第一种情况,我们可以看出来\(\alpha_2\)的范围是\((0, C - \alpha_2 + \alpha_1)\),第二种情况的范围是\((\alpha_2 - \alpha_1, C)\)。这里我们把k又表示回了\(\alpha_1,\alpha_2\),由于我们要通过迭代的方法来优化\(\alpha_1,\alpha_2\)的取值,所以我们令上一轮的\(\alpha_1, \alpha_2\)分别是\(\alpha_{1o}, \alpha_{2o}\)。这里的o指的是old的意思,我们把刚才求到的结论综合一下,就可以得到\(\alpha_2\)下一轮的下界L是\(\max(0, \alpha_{2o} - \alpha_{1o})\),上界H是\(\min(C+\alpha_{2o} - \alpha_{1o}, C)\)。
同理,我们画出\(\alpha_1, \alpha_2\)同号时的情况,也有k > 0 和 k < 0两种。
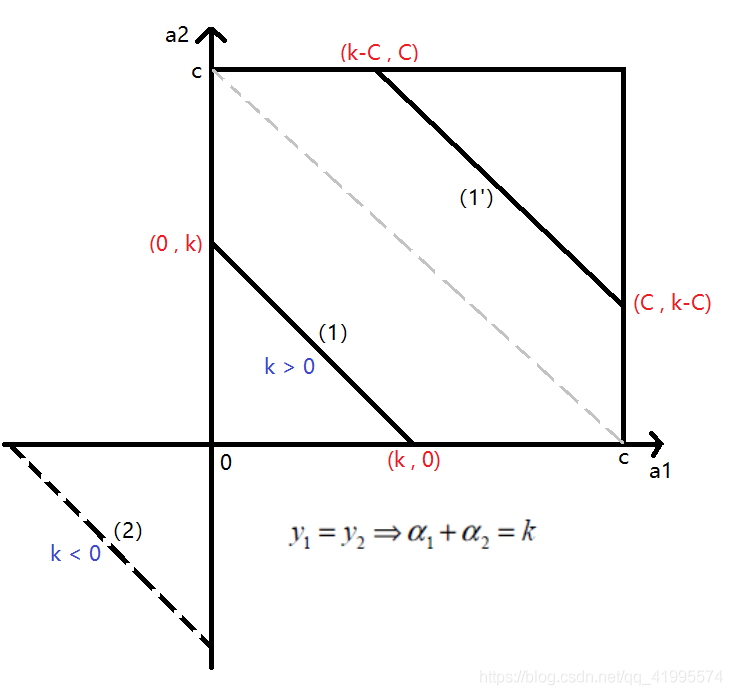
第一种情况是\(y_1 = y_2 = 1\),这时\(\alpha_1 + \alpha_2 = k\),此时 k > 0,对应的\(\alpha_2\)的取值是\((0, \alpha_{1o} + \alpha_{2o})\)。当k > C的时候,这时候也就是右上角1'的情况,此时过了中间的虚线,\(\alpha_2\)的范围是\((\alpha_{1o} + \alpha_{2o} - C, C)\)。
第二种情况是\(y_1 = y_2 = -1\),此时\(\alpha_1 + \alpha_2 = k\),此时k < 0,由于这个时候是不符合约束条件\(0\le \alpha_1, \alpha_2 \le C\)的,所以此时没有解。这两种情况综合一下,可以得到下界L是\(\max(0, \alpha_{1o} + \alpha_{2o} - C)\),上届H是\(\min(\alpha_{1o} + \alpha{2o}, C)\)。
我们假设我们通过迭代之后得到的下一轮\(\alpha_2\)是\(\alpha_{2new, unc}\),这里的unc是未经过约束的意思。那么我们加上刚才的约束,可以得到:
这里的\(\alpha_{2new,unc}\)是我们利用求导得到取极值时的\(\alpha_2\),但问题是由于存在约束,这个值并不一定能取到。所以上述的一系列操作就是为了探讨约束存在下我们能够取到的极值情况。如果看不懂推导过程也没有关系,至少这个结论需要搞明白。
代入消元
我们现在已经得到了下一轮迭代之后得到的新的\(\alpha_2\)的取值范围,接下来要做的就是像梯度下降一样,求解出使得损失函数最小的\(\alpha_1\)和\(\alpha_2\)的值,由于\(\alpha_1 + \alpha_2\)的值已经确定,所以我们求解出其中一个即可。
我们令\(\alpha_1y_1 + \alpha_2y_2 = \xi\),那么我们可以代入得到\(\alpha_1 = y_1(\xi - \alpha_2y_2)\)
我们把这个式子代入原式,得到的式子当中可以消去\(\alpha_1\),这样我们得到的就是只包含\(\alpha_2\)的式子。我们可以把它看成是一个关于\(\alpha_2\)的函数,为了进一步简化,我们令\(v_i = \sum_{j=3}^my_j \alpha_j K{i, j} , E_i = f(x_i ) - y_i = \sum_{j=1}^m \alpha_jy_jK_{i, j} + b - y_i\)
这里的\(E_i\)表示的是第i个样本真实值与预测值之间的差,我们把上面两个式子代入原式,化简可以得到:
接下来就是对这个式子进行求导求极值,就是高中数学的内容了。
我们求解这个式子,最终可以得到:
我们根据这个式子就可以求出\(\alpha_2\)下一轮迭代之后的值,求出值之后,我们在和约束的上下界比较一下,就可以得到在满足约束的情况下可以取到的最好的值。最后,我们把\(\alpha_2\)代入式子求解一下\(\alpha_1\)。这样我们就同时优化了一对\(\alpha\)参数,SMO算法其实就是重复使用上面的优化方法不停地选择两个参数进行优化,直到达到迭代次数,或者是不能再带来新的提升为止。
整个算法的逻辑其实是不难理解的,但是中间公式的推导过程实在是多了一些。这也是我把SVM模型放到机器学习专题最后来讲解的原因,在下一篇文章当中,我们将会为大家带来SVM模型核函数的相关内容,结束之后我们机器学习专题就将迎来尾声了,再之后我们将会开始深度学习的专题,敬请期待吧。
今天的文章到这里就结束了,如果喜欢本文的话,请来一波素质三连,给我一点支持吧(关注、转发、点赞)。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号