大数据算法——布隆过滤器
本文始发于个人公众号:TechFlow,原创不易,求个关注
今天的文章和大家一起来学习大数据领域一个经常用到的算法——布隆过滤器。如果看过《数学之美》的同学对它应该并不陌生,它经常用在集合的判断上,在海量数据的场景当中用来快速地判断某个元素在不在一个庞大的集合当中。它的原理不难,但是设计非常巧妙,老实讲在看《数学之美》之前,我也没有听说过这个数据结构,所以这篇文章也是我自己学习的笔记。
原理
在我之前的理解当中,如果想要判断某个元素在不在集合当中,经典的结构应该是平衡树和hash table。但是无论是哪一种方法,都逃不开一点,都需要存储原值。
比如在爬虫场景当中,我们需要记录下之前爬过的网站。我们要将之前的网址全部都存储在容器里,然后在遇到新网站的时候去判断是否已经爬过了。在这个问题当中,我们并不关心之前爬过的网站有哪些,我们只关心现在的网站有没有在之前出现过。也就是说之前出现过什么不重要,现在的有没有出现过才重要。
我们利用平衡树或者是Trie或者是AC自动机等数据结构和算法可以实现高效的查找,但是都离不开存储下所有的字符串。想象一下,一个网址大概上百个字符,大约0.1KB,如果是一亿个网址,就需要10GB了,如果是一百亿一千亿呢?显然这么大的规模就很麻烦了,今天要介绍的布隆过滤器就可以解决这个问题,而且不需要存储下原值,这是一个非常巧妙的做法,让我们一起来看下它的原理。
布隆过滤器本身的结构非常简单,就是一个一维的bool型的数组,也就是说每一位只有0或者1,是一个bit,这个数组的长度是m。对于每个新增的项,我们使用K种不同的hash算法对它计算hash值。所以我们可以得到K个hash值,我们用hash值对m取模,假设是x。刚开始的时候数组内全部都是0,我们把所有x对应的位置标记为1。
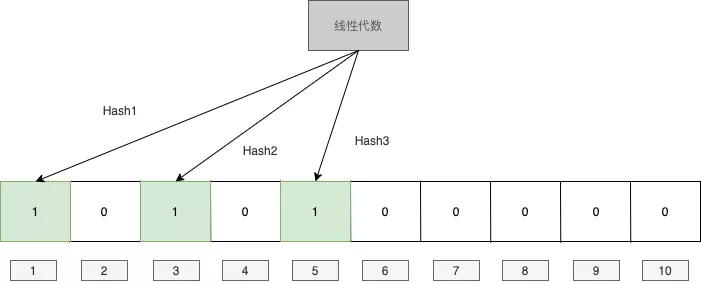
举个例子,假设我们一开始m是10,K是3。我们遇到第一个插入的值是”线性代数“,我们对它hash之后得到1,3,5,那么我们将对应的位置标记成1.
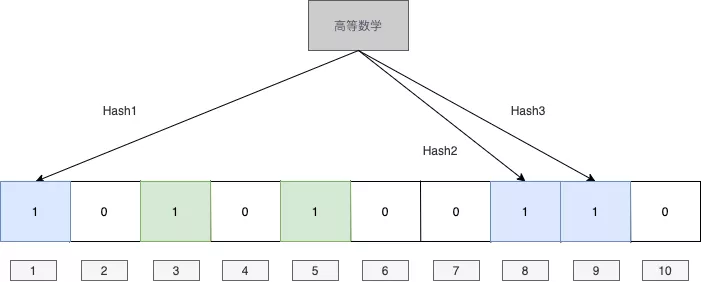
然后我们又遇到了一个值是”高等数学“,hash之后得到1,8,9,我们还是将对应位置赋值成1,会发现1这个位置对应的值已经是1了,我们忽略就好。
如果这个时候我们想要判断”概率统计”有没有出现过,怎么办?很简单,我们对“概率统计”再计算hash值。假设得到1,4,5,我们去遍历一下对应的位置,发现4这个位置是0,说明之前没有添加过“概率统计”,显然“概率统计”没有出现过。
但是如果“概率统计”hash之后的结果是1,3,8呢?我们判断它出现过就错了,答案很简单,因为虽然1,3,8这个hash组合之前没有出现过,但是对应的位置都在其他元素中出现过了,这样就出现误差了。所以我们可以知道,布隆过滤器对于不存在的判断是准确的,但是对于存在的判断是有可能有错误的。
代码
布隆过滤器的原理很简单,明白了之后,我们很容易写出代码:
# 插入元素
def BloomFilter(filter, value, hash_functions):
m = len(filter)
for func in hash_functions:
idx = func(value) % m
filter[idx] = True
return filter
# 判断元素
def MemberInFilter(filter, value, hash_functions):
m = len(filter)
for func in hash_functions:
idx = func(value) % m
if not filter[idx]:
return False
return True
错误率计算
之前的例子当中应该展示得很明白了,布隆过滤器虽然好用,但是会存在bad case,也就是判断错误的情况。那么,这种错误判断发生的概率有多大呢?
这个概率的计算也不难:由于数组长度是\(m\),所以插入一个bit它被置为1的概率是\(\frac{1}{m}\),插入一个元素需要插入k个hash值,所以插入一个元素,某一位没有被置为1的概率是\((1-\frac{1}{m})^k\)。插入n个元素之后,某一位依旧为0的概率是\((1-\frac{1}{m})^{nk}\),它变成1的概率是\(1-(1-\frac{1}{m})^{nk}\)。
如果在某次判断当中,有一个没有出现过的元素被认为已经在集合当中了,那么也就是说它hash得到的位置均已经在之前被置为1了,这个时间发生的概率为:
这里用到了一个极限:
我们来求一下冲突率最低时k的取值,为了方便计算,我们令\(b=e^{\frac{n}{m}}\),代入:
两边求导:
我们令导数等于0,来求它的极值:
我们将\(b^{-k}=\frac{1}{2}\)代入,可以求出最值时的\(k=\ln2\cdot\frac{m}{n} \approx 0.7\frac{m}{n}\)
同理,我们也可以预设定集合元素n和错判率p,来求解对应的n,同样利用上面的公式推算,可以得到\(m=-\frac{n\ln p}{(\ln2)^2}\)
如果我们允许一定的容错,并且能够大概估计会出现的元素的个数,那么完全可以使用布隆过滤器来代替传统的容器判重的方法。这样不仅效率极高,而且对于存储的要求非常小。
灵魂拷问
原理也明白了,代码也看懂了,这个时候我们来思考一个问题:布隆过滤器可以删除元素吗?
很遗憾,布隆过滤器是不支持删除的。
因为布隆过滤器的每一个bit并不是独占的,很有可能多个元素共享了某一位。如果我们直接删除这一位的话,会影响其他的元素。
还是用上面的例子举例:我们删除线性代数,线性代数对应的位置是1,3,5,虽然我们并没有删除高等数学,但是由于我们移除了高等数学也用到的位置1,如果我们再去判断高等数学是否存在就会得到错误的结果,虽然我们并没有删除它。
当然,在一些必须要有删除功能的场景下,也是有办法的。方法也很简单,就是修改数据结构,将原本每一位一个bit改成一个int,当我们插入元素的时候,不再是将bit设置为true,而是让对应的位置自增,而删除的时候则是对应的位减一。这样,我们删除单个结果就不会影响其他元素了。
这种方法并不是完美的,由于布隆过滤器存在误判的情况,很有可能我们会删除原本就不存在的值,这同样会对其他元素产生影响。
布隆过滤器是一个优缺点都非常明显的数据结构,优点非常出色:速度足够快,内存消耗小,代码实现简单。但是缺点也很明显:不支持删除元素,会有误判的情况。这样特点鲜明的数据结构真的非常吸引人。
今天的文章就是这些,如果觉得有所收获,请顺手点个关注吧,你们的举手之劳对我来说很重要。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号