

拓端数据tecdat|R语言代写聚类算法的应用实例
原文链接:http://tecdat.cn/?p=5265
一家批发经销商想将发货方式从每周五次减少到每周三次,简称成本,但是造成一些客户的不满意,取消了提货,带来更大亏损,项目要求是通过分析客户类别,选择合适的发货方式,达到技能降低成本又能降低客户不满意度的目的。
什么是聚类
聚类将相似的对象归到同一个簇中,几乎可以应用于所有对象,聚类的对象越相似,聚类效果越好。聚类与分类的不同之处在于分类预先知道所分的类到底是什么,而聚类则预先不知道目标,但是可以通过簇识别(cluster identification)告诉我们这些簇到底都是什么。
K-means
聚类的一种,之所以叫k-均值是因为它可以发现k个不同的簇,且每个簇的中心采用簇中所含值的均值计算而成。簇个数k是用户给定的,每一个簇通过质心来描述。
k-means的工作流程是:
- 随机确定k个初始点做为质心
- 给数据集中的每个点找距其最近的质心,并分配到该簇
- 将每个簇的质心更新为该簇所有点的平均值
- 循环上两部,直到每个点的簇分配结果不在改变为止
项目流程 载入数据集 import pandas as pd data = pd.read_csv("customers.csv"); 分析数据
显示数据的一个描述
from IPython.display import display display(data.discrie());
分析数据是一门学问,感觉自己在这方面还需要多加练习,数据描述包含数据总数,特征,每个特征的均值,标准差,还有最小值、25%、50%、75%、最大值处的值,这些都可以很容易列出来,但是透过这些数据需要看到什么信息,如何与需求目的结合,最开始还是比较吃力的。可以先选择几个数值差异较大的样本,然后结合数据描述和需求,对数据整体有一个把控。比如在Udacity的第三个项目中,给出客户针对不同类型产品的年度采购额,分析猜测每个样本客户的类型。
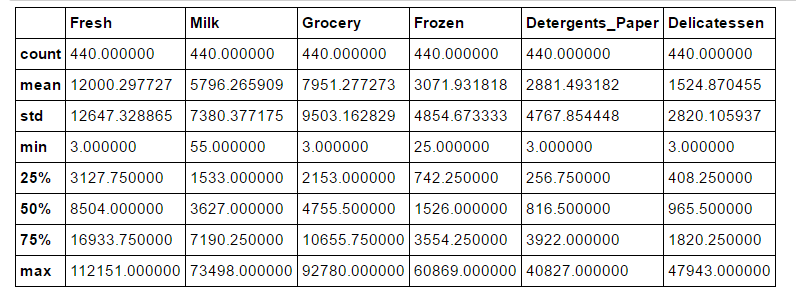
数据描述
三个样本客户
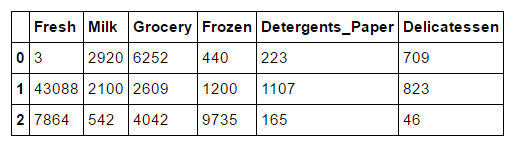
样本客户
每个客户究竟是什么类型,这个问题困扰我好久,第一次回答我只是看那个方面采购额最大,就给它一个最近的类型,提交项目后Reviewer这样建议:
恍然大悟,这才知道了该如何分析一份数据集,于是有了下面的回答

回答
所以分析数据一定要结合统计数据,四分位数和均值可以看做数据的骨架,能够一定程度勾勒出数据的分布,可以通过箱线图来可视化四分位数。
分析特征相关性
特征之间通常都有相关性,可以通过用移除某个特征后的数据集构建一个监督学习模型,用其余特征预测移除的特征,对结果进行评分的方法来判断特征间的相关性。比如用决策树回归模型和R2分数来判断某个特征是否必要。
如果是负数,说明该特征绝对不能少,因为缺少了就无法拟合数据。如果是1,表示少了也无所谓,有一个跟它相关联的特征能代替它,如果是0到1间的其他数,则可以少,只是有一定的影响,越靠近0,影响越大。
也可以通过散布矩阵(scatter matrix)来可视化特征分布,如果一个特征是必须的,则它和其他特征可能不会显示任何关系,如果不是必须的,则可能和某个特征呈线性或其他关系。
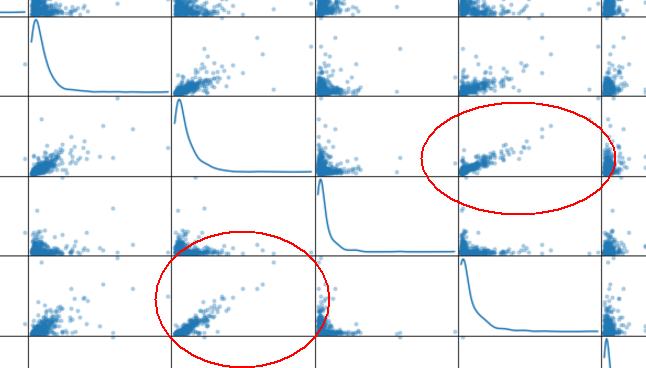
散布矩阵图举例
数据预处理
(一)特征缩放如果数据特征呈偏态分布,通常进行非线性缩放。
可以发现散布矩阵变成了下图
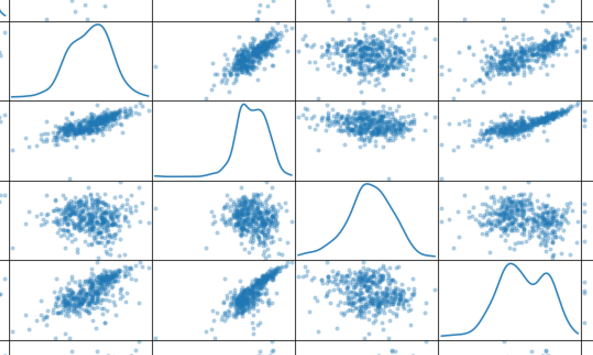
特征缩放后的散布矩阵
(二)异常值检测通常用Tukey的定义异常值的方法检测异常值。
移除异常值需要具体情况具体考虑,但是要谨慎,因为我们需要充分理解数据,记录号移除的点以及移除原因。可以用counter来辅助寻找出现次数大于1的离群点。
(三)特征转换特征转换主要用到主成分分析发,请查看之前介绍。
聚类
有些问题的聚类数目可能是已知的,但是我们并不能保证某个聚类的数目对这个数据是最优的,因为我们对数据的结构是不清楚的。但是我们可以通过计算每一个簇中点的轮廓系数来衡量聚类的质量。数据点的轮廓系数衡量了分配给它的簇的相似度,范围-1(不相似)到1(相似)。平均轮廓系数为我们提供了一种简单地度量聚类质量的方法。下面代码会显示聚类数为2时的平均轮廓系数,可以修改n_clusters来得到不同聚类数目下的平均轮廓系数。
如果您有任何疑问,请在下面发表评论。

