

拓端数据tecdat|python代写拉勾数据职位分析
简介:试着,做了一个拉勾网数据分析师职位的数据分析。
其实,虽然很想做数据分析师,但是是跨行,心里相当忐忑,做这个分析就相当于加深自己对数据分析这个行业的了解了。
思路
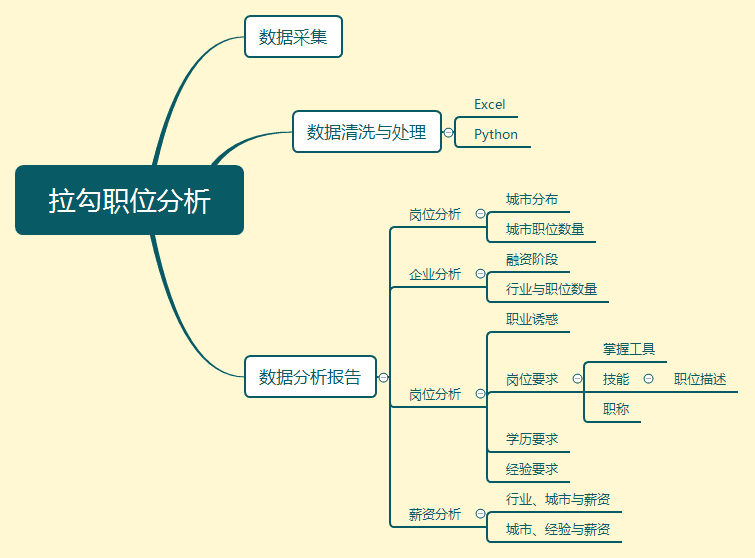
大致思路
起始 数据来源
本来是想自己写个爬虫的,可是学了好久,还是不能融会贯通,总会出一些bug,只能继续学习,争取早日修成爬神功。又想着,总不能还没开始,就结束了这次实验。最后无意中发现了一个爬虫工具--八爪鱼、、只需要点点点(其实,当时有种挫败感)。不过,总算数据总算有了。
数据的采集
数据的具体采集过程如下:
- 下载安装八爪鱼采集器。
- 创建任务,选择列表及详情。
- 输入任务名称、备注。
- 输入采集网址
- 设置详情页链接,也就是点进具体的详情页。
- 设置好翻页。
- 点击需要采集的数据信息。
- 开始采集。
- 数据导出为excel。
过程 数据的清洗与处理
这里试着用了两种工具,Excel + Python,也比较了一下二者的优点。与前人所述基本一致,纸上得来终觉浅啊。
想说一下字段的命名,如果用了Python进行处理的话,最好还是把字段命名为英文,或者说字母。可以简化后期处理,会方便很多。
当然,你如果全用Excel是用中文命名,也是没有问题的。

字段
Excel的处理过程 预防万一
所谓预防万一,就是将Excel另存一份源数据,以免后期发生不可预知错误。
清洗与处理 命名字段

处理salary列
新建工作表,将salary字段复制过来。
- 清除所有格式。
- 数据-分列-固定符号-"-"
- 查找替换 k。这里说明下,清除格式后,无论查找大写K还是小写k,均可。
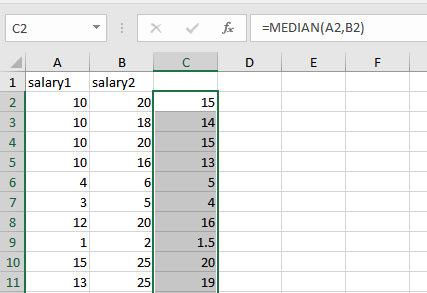
- 因为抓取的数据是一组区间值,无法直接使用,因此取薪资的中间值也就是平均值。使用函数 'MEDIAN' ,它会返回一组数的中值,或者使用 'AVERAGE' 也可。得到的值如下:
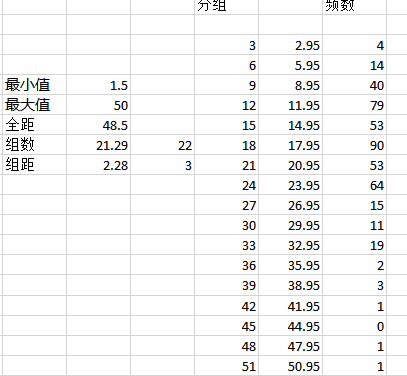
- 再对这组值进行数据分析,数据-数据分析-描述统计,得到最大值,最小值,全距,再根据公式计算组数,组距,进行数据分组,再根据 ' FREQUENCY '函数计算每组频率。
接下来,就可以绘制图表了。
ps:或者直接在第5步,采用数据分析工具中的直方图,进行分析。
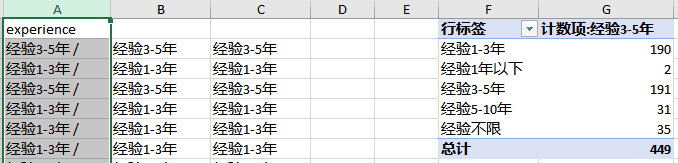
处理experience、city、education、property、scale列
新建工作表,复制。
- 清除所有格式。
- 使用函数 'SUBSTITUTE' 替换所有 "/",或者直接查找替换。
- 数据透视表统计,绘图。
处理field列
新建工作表,复制。
- 清除所有格式
- 查找替换"、",","为半角“,”。
- 分列。
这样,基本就处理完了。
数据展示 行业及职位数量
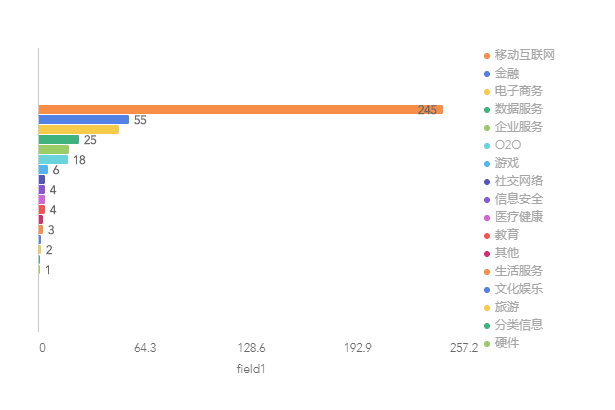
从图中可以看出,17个行业中,移动互联网对数据人才的需求量是最大的,其次是金融和电子商务,而生物服务、文化娱乐、旅游、分类信息、硬件等的需求量最少。我认为,这从一个侧面反映了移动互联网数据量的巨大,以及对人才的渴求。
城市与职位
首先看一下,职位主要分布的区域:

从图中可以看到,招聘公司主要位于南方,东三省竟然没有。我认为,这个时代,对数据的重视程度从某种程度上说明了发展的质量,就这个样本数据来说,从某种程度上反映了东三省的发展速度较慢,不如南方。
再看一下,城市与职位:
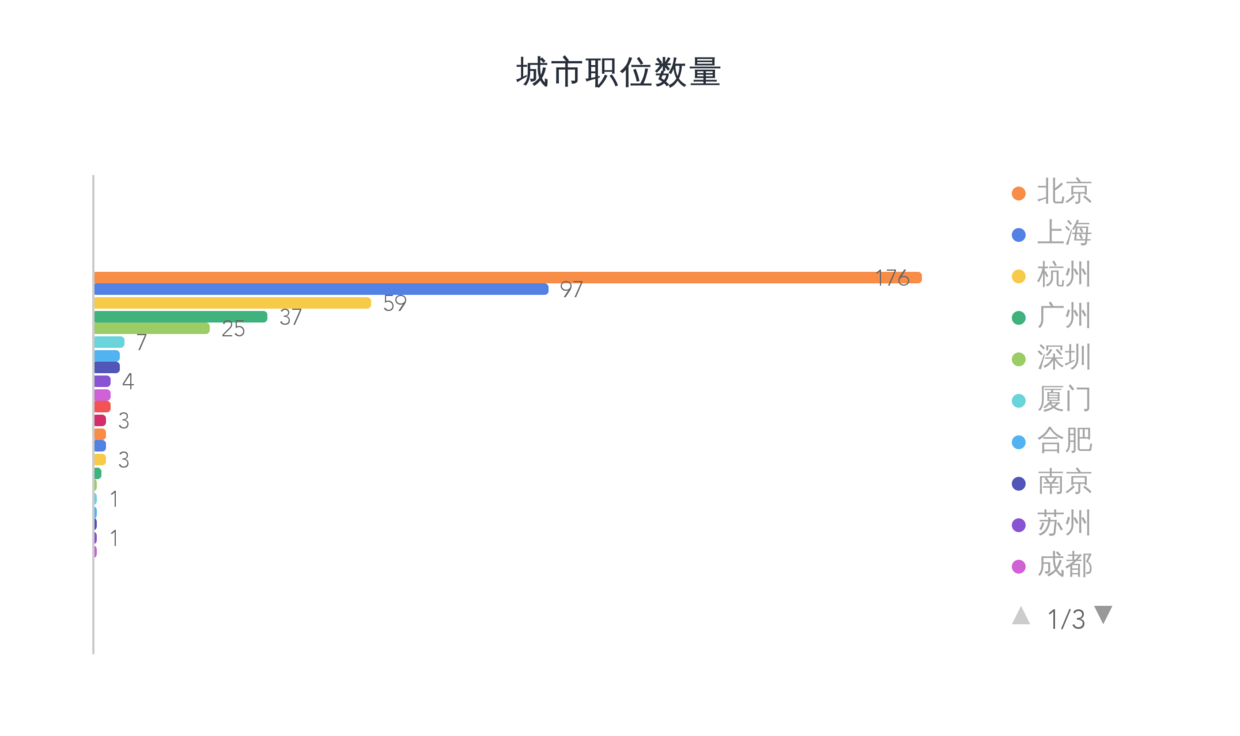
这里主要截取了前10个城市,毫无意外,北上广赫然在列,杭州也很多,排在广州前面。看来,我们这些想做数据分析师的人,都无法逃离北上广啊。嗯,你也可以去杭州,据在那儿生活了七八年的同学来说,他不想走了。
行业、城市与薪资
前面数据处理得到了每个职位的平均薪资,这里进一步处理得到了每个行业在每个城市的平均薪资。下图是招聘最多的几个行业在每个城市的平均薪资。
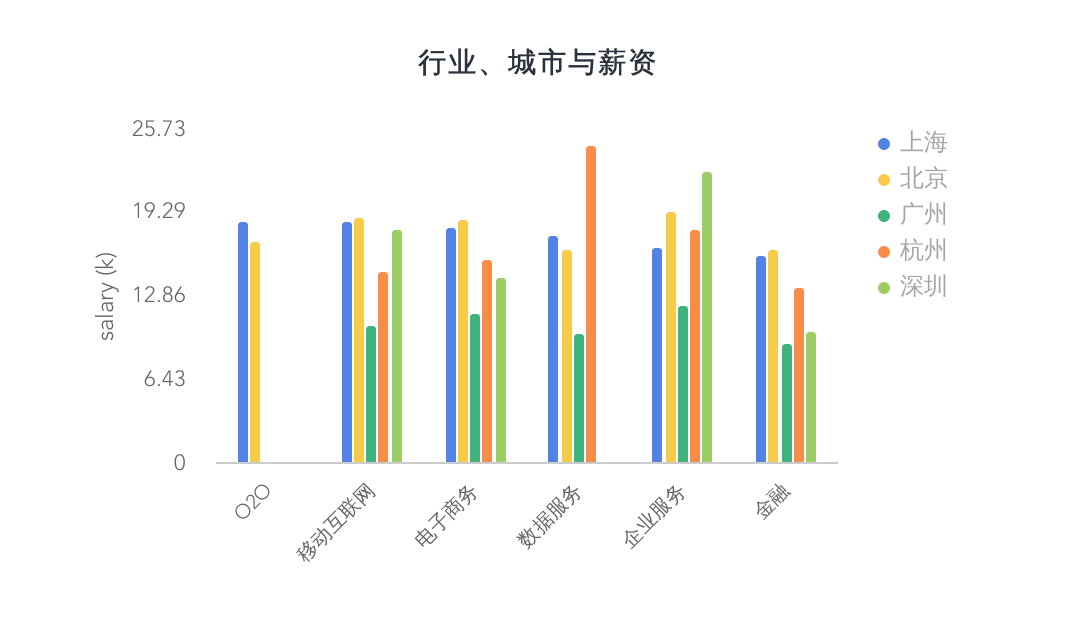
从图中可以知道,整体上相对来说,广州在这些行业中属于较低的。北京、上海差距不是太大。
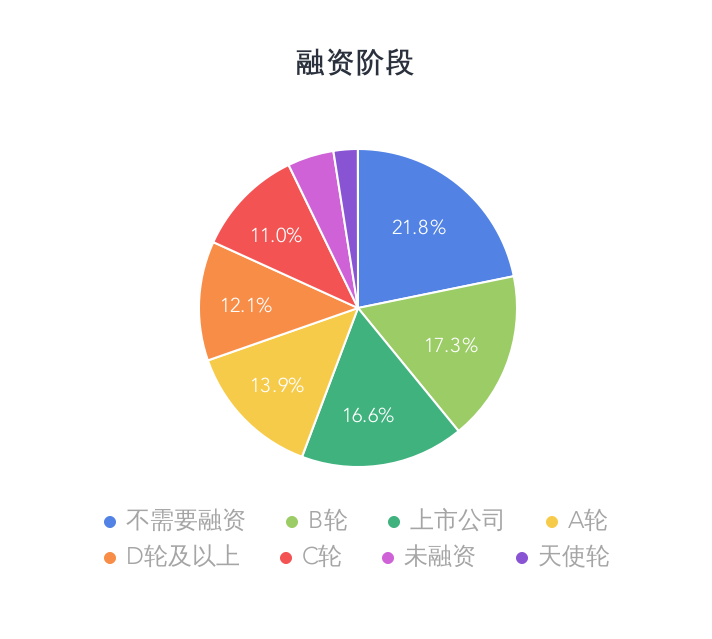
招聘公司融资阶段
招聘不同职称的数量
这里借助python进行了统计:
python import pandas as pd data = pd.DataFrame(pd.read_csv(r'C:\Users\sunshine\Desktop\2017.8.20.csv',encoding = 'gbk')) data.columns positionName = [] for i in range(len(data.position)): if "实习" in data.position[i]: positionName.append("实习") elif "助理" in data.position[i]: positionName.append("助理") elif "专员" in data.position[i]: positionName.append("专员") elif "主管" in data.position[i]: positionName.append("主管") elif "经理" in data.position[i]: positionName.append("经理") elif "工程师" in data.position[i]: positionName.append("工程师") elif "总监" in data.position[i]: positionName.append("总监") elif "科学家" in data.position[i]: positionName.append("科学家") elif "架构" in data.position[i]: positionName.append("架构师") else: positionName.append("其他") data["positionName1"] = positionName data["positionName1"].value_counts()
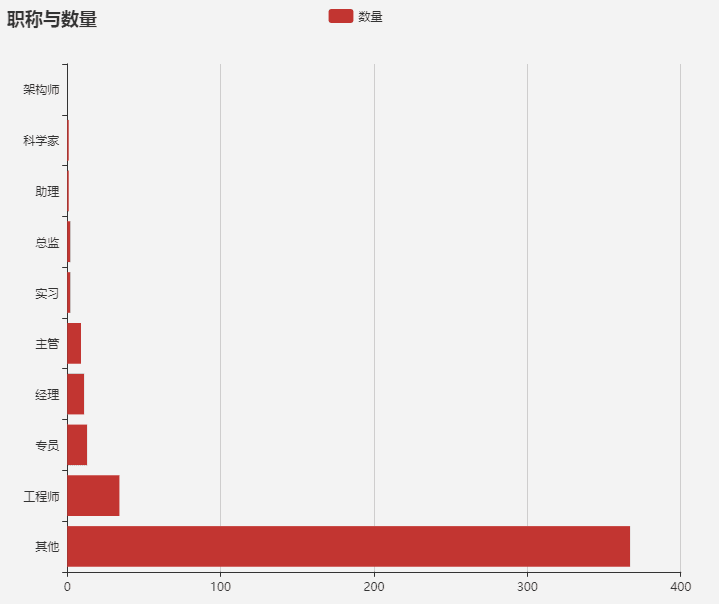
这里没有用matplotlib画,借用了echarts。
招聘公司对个人能力的要求 招聘公司对应聘者的学历要求
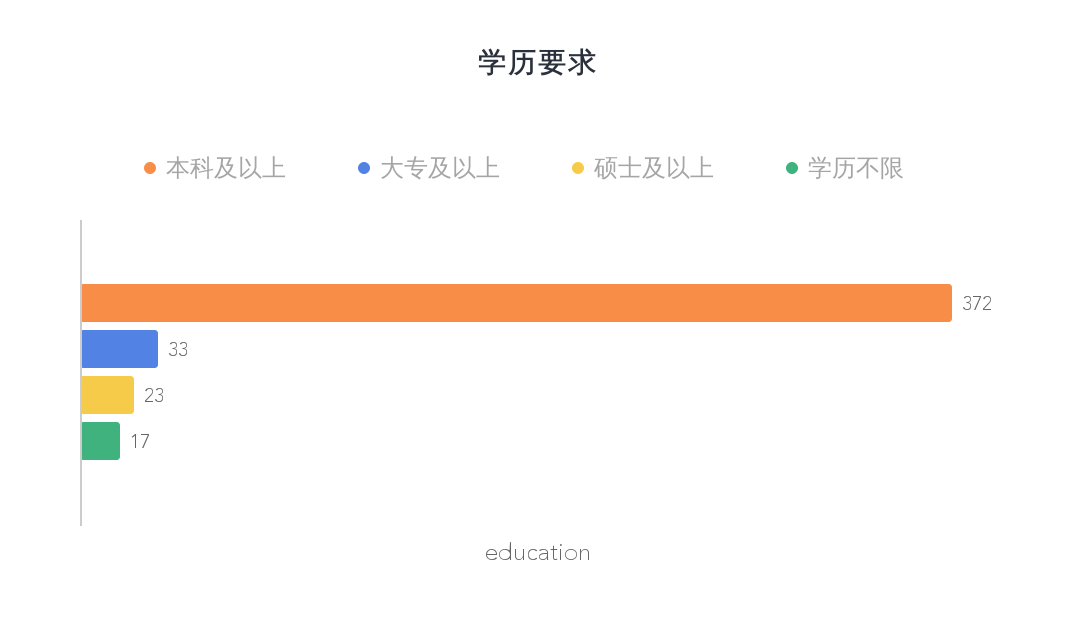
从图中我们很明显可以得到,公司对应聘者的学历要求,本科以上占了绝大部分,这说明,90%以上的公司对应聘者的学历要求很高,我认为,这可能有以下原因:
- 分析行业对应聘者的知识水平要求还是很高的,因为数据分析师不但要涉及很多高等数学,统计学,概率论,线性代数等数学知识,还要涉及很多行业知识。
- 这个行业需要应对很多日新月异的信息,各种东西更新迭代非常快,因此对应聘者的自学能力提出了很高的要求。
招聘公司对应聘者经验的要求
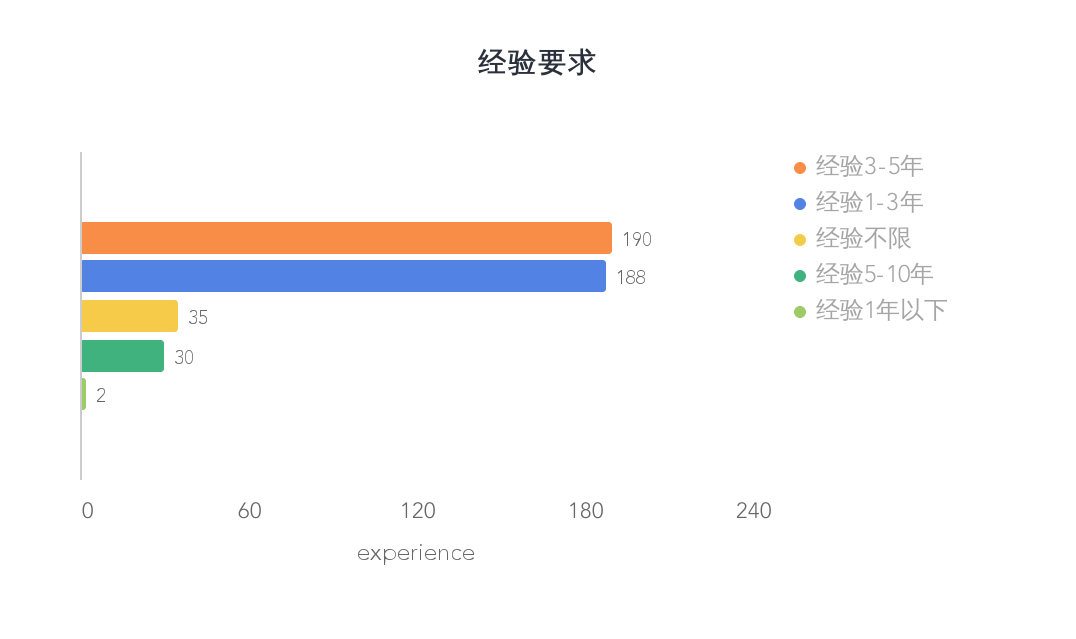
大部分公司招的都是1-5年的,1年之下和经验不限的很少,所以说,实习经验很重要,没有实习经历,太难入行了。我泪奔。公司需要的都是老鸟啊。
招聘公司对应聘者工具掌握的要求
这里使用了python进行了正则匹配,和词云生成。
python import re import numpy as np import pandas as pd import matplotlib.pyplot as plt import jieba as jb from wordcloud import WordCloud #转换数据格式 word_str = ''.join(data['deion']) #对文本进行分词 word_split = jb.cut(word_str) #使用|分割结果并转换格式 word_split1 = "| ".join(word_split) #设置要匹配的关键词 pattern=re.compile('sql|mysql|posgresql|python|excel|spss|matlab|ppt|powerpoint|sas|[\br\b]|hadoop|spark|hive|ga|java|perl|tableau|eviews|presto') #匹配所有文本字符 word_w=pattern.findall(word_split1) word_s = str(word_w) my_wordcloud = WordCloud().generate(word_s) plt.imshow(my_wordcloud) plt.axis("off") plt.show()

有点丑...
因此,换了个工具.....

好看点了,无论哪张图都说明,除了excel,如果,你懂R或者python,再加上SQL,和spss,喔,你是个香饽饽。
招聘公司对应聘者技能的要求

可以看到,公司对应聘者的要求大部分在数据分析能力和产品、业务等方面。看来,数据分析师最重要的还是懂业务,这也是我想发展的方向。至于数据挖掘方向,对数学功底要求太高了,毕竟我不是科班出身。但是,我觉得平时在实验室做的实验,其实和业务是一个道理。只不过,是将实验换成了产品。
总结
对于数据分析岗,招聘公司主要位于南方,但是以北京公司最多。不需要融资,B轮和上市公司对于该岗位的需求较大。并且主要是移动互联网行业的公司。企业对于应聘者的工具掌握多是Excel,Spss,Python,R,SQl等,如果你全会,那基本就是个香饽饽。在技能方面,企业比较看重数据分析,以及对业务、运营的理解。而对于应聘者而言,本科生学历完全足够了。就薪资而言,广州多有行业较其他城市偏低,北京和上海在同等工作经历下,薪资要领先于其他城市。

