

MATLAB用CNN-LSTM神经网络的语音情感分类深度学习研究
全文链接:https://tecdat.cn/?p=38258
原文出处:拓端数据部落公众号
在语音处理领域,对语音情感的分类是一个重要的研究方向。本文将介绍如何通过结合二维卷积神经网络(2 - D CNN)和长短期记忆网络(LSTM)构建一个用于语音分类任务的网络,特别是针对语音情感识别这一应用场景。文中将展示相关代码和实验结果,包括数据处理、模型架构定义、训练以及测试等环节,并对重要步骤和结果进行详细阐述和分析。
方法
(一)数据准备
- 数据下载
本文使用柏林情感语音数据库(Emo - DB)来训练模型。这个数据集包含了由10个演员说出的535个语句,这些语句被标记为愤怒、无聊、厌恶、焦虑/恐惧、快乐、悲伤或中性这七种情感之一。 - 提取情感标签
文件名编码了说话者ID、所说文本、情感和版本信息。情感标签的编码如下:“W—愤怒”、“L—无聊”、“E—厌恶”、“A—焦虑/恐惧”、“F—快乐”、“T—悲伤”、“N—中性”。
-
filepaths = ads.Files;
-
[~,filenames] = fileparts(filepaths);
-
emotionLabels = extractBetween(filenames,6,6);
这段代码首先获取audioDatastore对象中所有音频文件的路径,然后提取文件名,并从文件名的第六个字符获取情感标签。
- 标签转换
将单字母代码形式的标签替换为描述性标签,并将标签转换为分类数组。 - 设置标签属性并查看分布
首先将提取并转换后的情感标签设置为audioDatastore对象的Labels属性。然后,通过绘制直方图来查看不同情感类别的数据分布情况。

- 读取样本、查看波形和试听
-
[audio,info] = read(ads);
-
fs = info.SampleRate;
-
sound(audio,fs)
上述代码从数据存储中读取一个音频样本,获取其采样率,播放该音频。同时,绘制音频的波形图,标题显示其情感类别
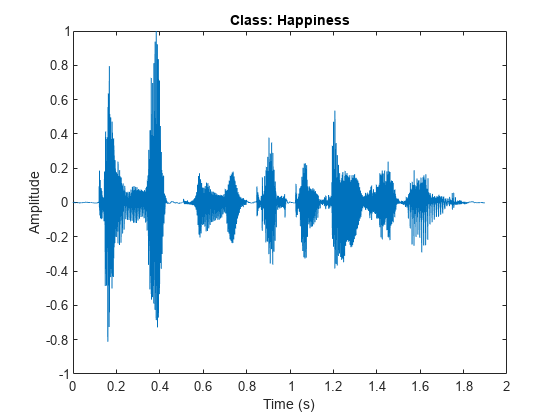
- 数据划分与增强
将数据划分为训练集、验证集和测试集,其中训练集占70%,验证集和测试集各占15%。
[adsTrain,adsValidation,adsTest] = splitEachLabel(ads,0.70,0.15,0.15);为了提高模型的拟合能力,在训练数据有限的情况下,可以通过数据增强的方式增加训练数据量。创建一个audioDataAugmenter对象,指定每个文件的增强次数、音高偏移概率、时间偏移概率和范围、添加噪声概率和信噪比范围等参数。
创建一个新文件夹来存储增强后的数据,然后通过循环遍历数据存储和使用音频数据增强器来增强训练数据。对于每个增强样本,进行归一化处理,并将其保存为WAV文件。
最后,创建增强数据的音频数据存储对象,并将其标签设置为原始训练数据标签的重复元素。
-
augadsTrain = audioDatastore(agumentedDataFolder);
-
augadsTrain.Labels = repelem(adsTrain.Labels,augmenter.NumAugmentations,1);
- 特征提取
使用audioFeatureExtractor对象从音频数据中提取特征,指定窗口长度、跳跃长度、窗口类型和要提取的频谱类型等参数。
设置特征提取器的参数,包括梅尔频带数量和是否禁用窗口归一化。
使用preprocessAudioData函数从训练集、验证集和测试集中提取特征和标签。
绘制一些训练样本的波形和听觉频谱图,如下代码所示:
-
numPlots = 3;
-
idx = randperm(numel(augadsTrain.Files),numPlots);
-
f = figure;
-
f.Position(3) = 2*f.Position(3);
-
-
tiledlayout(2,numPlots,TileIndexing = "columnmajor")
结果如训练样本的波形和频谱图所示。同时查看前几个观测值的大小,以确保网络能够支持训练数据,并计算输入层最短序列的长度。

(二)模型架构定义
定义二维CNN - LSTM网络,用于预测序列的类别标签,网络结构如下代码所示:
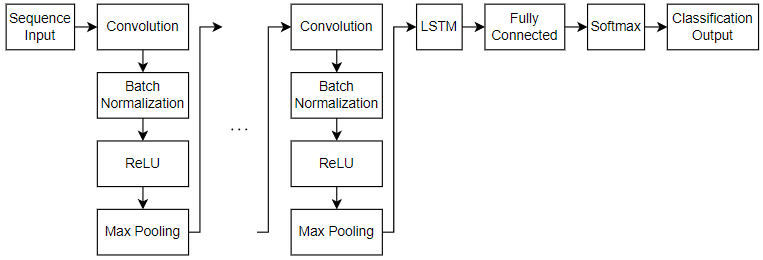
对于序列输入,指定一个序列输入层,其输入大小与输入数据匹配,并设置MinLength选项为训练数据中最短序列的长度。使用二维CNN架构来学习一维图像序列中的空间关系,包括四个重复的卷积、批量归一化、ReLU和最大池化层块,并逐渐增加第三和第四卷积层的滤波器数量。通过包含一个具有256个隐藏单元的LSTM层来学习一维图像序列中的长期依赖关系,并将OutputMode选项设置为"last",仅输出最后一个时间步。对于分类任务,包含一个全连接层和一个softmax层,最后添加一个分类层。
(三)训练选项指定
使用trainingOptions函数指定训练选项,包括使用Adam优化器、小批量大小、训练轮数、初始学习率、学习率调整策略、L2正则化项、序列填充方向、是否打乱数据、验证频率、是否显示训练进度以及是否在GPU上训练等参数,代码如下:
-
miniBatchSize = 32;
-
-
options = trainingOptions("adam",...
-
MaxEpochs = 3,...
-
MiniBatchSize = miniBatchSize,...
模型训练与测试
(一)训练网络
使用trainNetwork函数训练网络,如果没有GPU,训练可能会花费较长时间
训练过程的进度图如![训练进度图所示。
![{"String":"Figure Training Progress (05-May-2022 17:02:32) contains 2 axes objects and another object of type uigridlayout. Axes object 1 contains 10 objects of type patch, text, line. Axes object 2 contains 10 objects of type patch, text, line.","Tex":[],"LaTex":[]}](https://img-blog.csdnimg.cn/img_convert/624554706d2f7f7f7baa9c2da05ba687.png)
(二)测试网络
使用训练好的网络对测试数据进行分类,并通过比较预测结果和真实标签来评估模型的分类准确率。首先,对测试数据进行分类。
然后,通过绘制混淆矩阵来可视化预测结果,代码如下:
-
figure
-
confusionchart(labelsTest,labelsPred)

结果如混淆矩阵图所示。最后,通过计算预测结果和测试标签相同的比例来评估分类准确率,本次实验得到的准确率为0.6329。
结论
本文详细介绍了基于二维CNN - LSTM网络的语音情感分类模型的构建、训练和测试过程。通过对柏林情感语音数据库的实验,展示了模型在语音情感分类任务上的性能。虽然取得了一定的准确率,但仍有改进的空间,例如进一步优化数据增强策略、调整模型架构或训练参数等,未来的研究可以在此基础上继续深入。同时,本文中的方法和代码也可以为相关领域的研究人员提供参考和借鉴。
参考文献
[1] Burkhardt, Felix, A. Paeschke, M. Rolfes, Walter F. Sendlmeier, and Benjamin Weiss. “A Database of German Emotional Speech.” In Interspeech 2005, 1517–20. ISCA, 2005. https://doi.org/10.21437/Interspeech.2005 - 446.
[2] Zhao, Jianfeng, Xia Mao, and Lijiang Chen. “Speech Emotion Recognition Using Deep 1D & 2D CNN LSTM Networks.” Biomedical Signal Processing and Control 47 (January 2019): 312–23. https://doi.org/10.1016/j.bspc.2018.08.035.


