



【视频讲解】CatBoost、LightGBM和随机森林的海域气田开发特征分类研究
原文链接:https://tecdat.cn/?p=37208
原文出处:拓端数据部落公众号
分析师:Changlin Li
本文将通过视频讲解,展示如何用CatBoost、LightGBM和随机森林的海域气田开发特征智能分类,并结合一个python分类预测职员离职:逻辑回归、梯度提升、随机森林、XGB、CatBoost、LGBM交叉验证可视化的代码数据,为读者提供一套完整的实践数据分析流程。
本研究基于数据库,通过数据预处理、特征工程和机器学习算法,对1050个海域气田的全生命周期产量数据进行了深入分析。研究涵盖了数据清洗、标准化、样本平衡处理和特征离散化等步骤。进一步,通过算法应用与模型选择,本研究旨在探索不同储量类型海域气田的开发特征,并评估了CatBoost、LightGBM和随机森林等算法的性能。
1. 数据预处理
数据预处理是数据分析的关键步骤,包括数据清洗、去重、缺失值检查和数据标准化。本研究使用Python代码print(df.isnull().sum())对数据集中的缺失值进行了全面检查,确认数据集无缺失值。此外,采用最小-最大标准化法对数据进行了标准化处理,以消除不同量纲的影响,公式为 x−minmax−minmax−minx−min。

样本平衡处理方面,本研究采用了SMOTE算法生成新的少数类样本,有效克服了过拟合问题。同时,对字符和文本特征进行了特征离散化处理,以适应后续的数据分析。

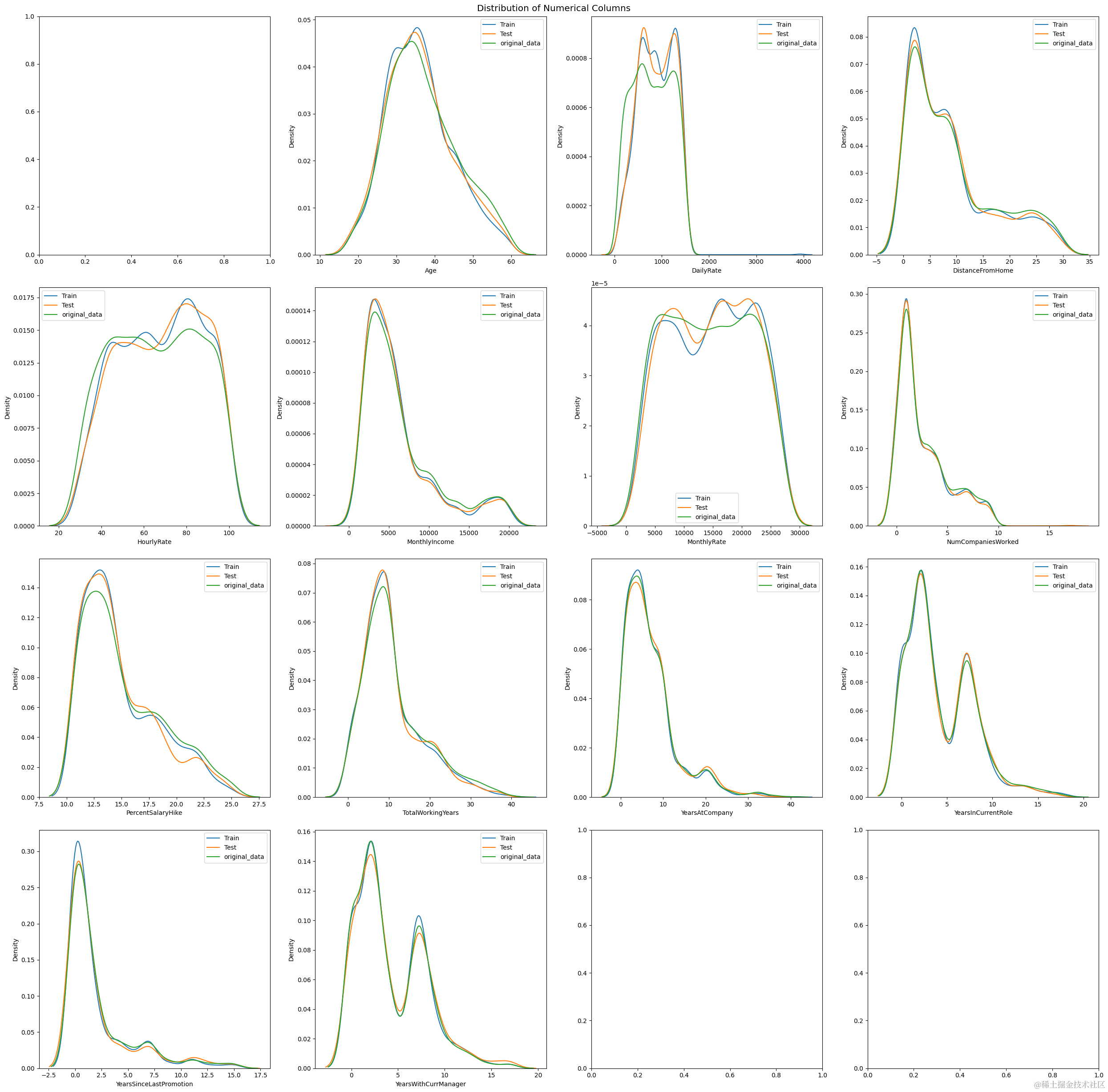
2. 数据探索性分析
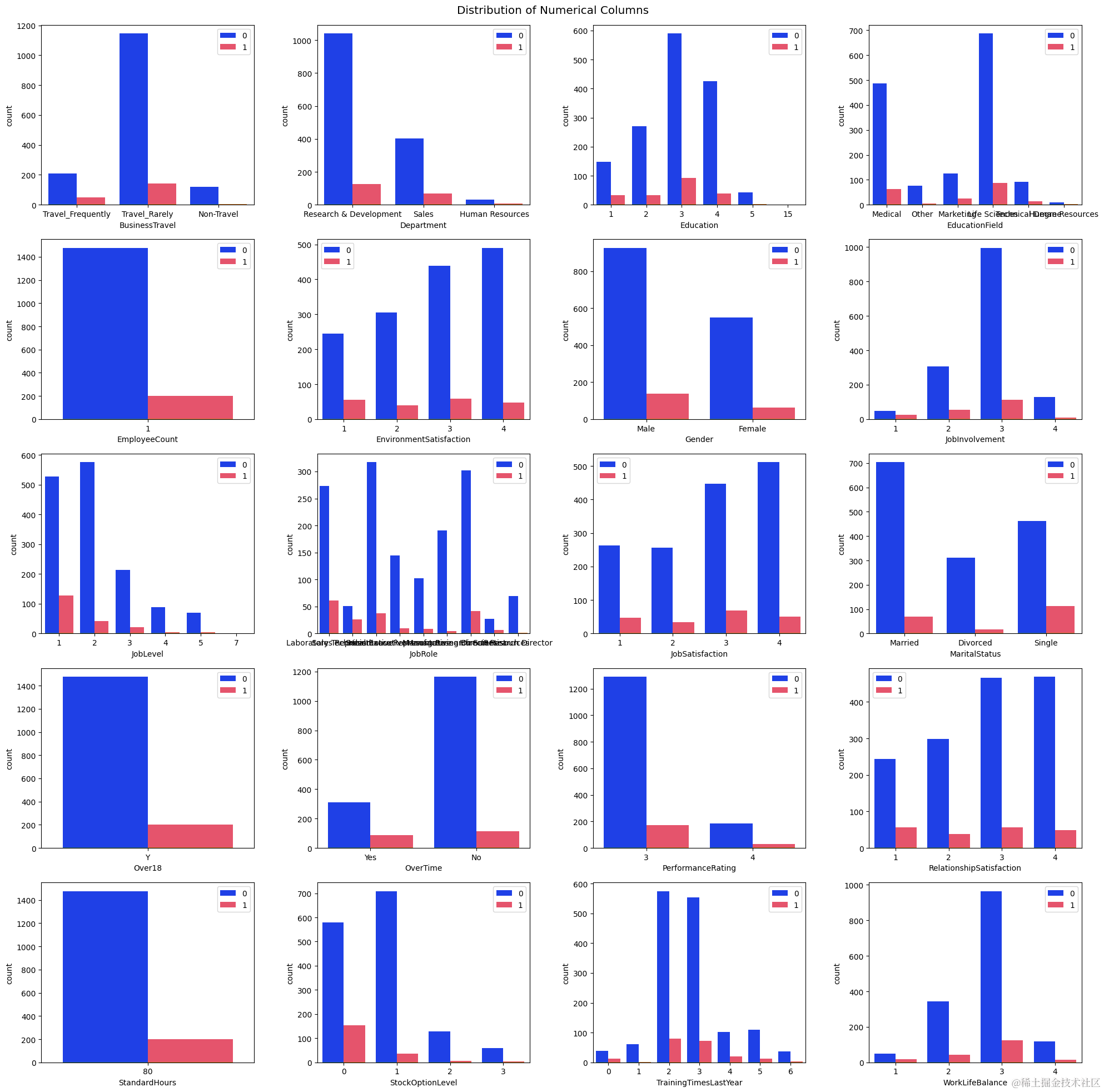
本研究对海域气田的开发特征进行了探索性分析,通过可视化手段展示了数据分布和关键特征。


3. 算法应用与模型选择
明确了数据挖掘算法的建模原理与过程后,本研究对CatBoost、LightGBM和随机森林三种算法进行了训练和参数调优。通过网格搜索法分析了不同参数对模型性能的影响,最终选择了最优的模型参数。


4. 模型性能评估
在模型训练过程中,本研究将数据集划分为训练集(70%)、测试集(20%)和验证集(10%)。通过混淆矩阵评估了三种模型的分类预测性能,包括准确率、精确度、召回率和F1得分。

5. 特征重要性分析

利用Python的Sklearn库对CatBoost模型的特征重要性进行了分析,确定了高峰产量、稳产期末累计产量和产量上升期结束产量等关键特征。这些特征对于预测不同类别的海上气田开发特征至关重要。
6. 预测
本研究通过广义翁氏模型和LSTM时间序列预测模型,对海域气田的产量参数进行了拟合和预测,为海上气田的开发技术政策制定、生产策略优化和生产潜力评估提供了科学依据。
python分类预测职员离职:逻辑回归、梯度提升、随机森林、XGB、CatBoost、LGBM交叉验证可视化
离职率是企业保留人才能力的体现。分析预测职员是否有离职趋向有利于企业的人才管理,提升组织职员的心理健康,从而更有利于企业未来的发展。
解决方案
任务/目标
采用分类这一方法构建6种模型对职员离职预测,分别是逻辑回归、梯度提升、随机森林、XGB、CatBoost、LGBM。确定某一职员属于是或否离职的目标类,并以此来探究职员大量离职的潜在因素。
数据源准备
员工离职数据,属性包括职员的年龄,出差频率、部门、受教育水平、工作参与度和工作等级等等。
特征转换
是否离职、性别等字符串型数据分别用0或1代替,出差频率等按等级用0-2的数字代替。
构造
以上说明了如何抽取相关特征,我们大致有如下训练样本(只列举部分特征)。
了解数据集的分布
划分训练集和测试集
以样本中测试集占比百分之二十的比例训练模型
summary(dftrain)
建模
使用Stratified K-Fold交叉验证来进行模型评估
-
def cross_valtion(model, X, y):
-
skf = StratiFold(n_splits = 10, random_state = 42, shuffle = True)
-
scores = []
-
predictions = np.ros(len(X))
-
-
for fold, (train_index, test_index) in enum
这是一个逻辑回归分类器的实例化,其中random_state参数用于指定随机的种子数,以便结果的可重复性。逻辑回归是一种线性模型,用于解决二元分类问题。
LogisticRegression(random_state = 42))梯度提升分类器的实例化,其中random_state参数同样用于指定随机种子数。梯度提升是一种集成学习算法,它将多个弱学习器结合成一个强学习器。
GradientBoostingClassifier(random_st随机森林分类器的实例化,其中random_state参数用于指定随机种子数。随机森林是一种基于决策树的集成学习算法。
RandomForestClassifier(random_state =使用XGBoost库的分类器的实例化,其中random_state参数用于指定随机种子数。XGBoost是一个高效的梯度提升库。
XGBClassifier(random_statCatBoost分类器的实例化,其中random_state参数用于指定随机种子数。CatBoost是一个使用梯度提升的库,可以处理分类和回归问题。
CatBoostClassifier(random_使用LightGBM库的分类器的实例化,其中random_state参数用于指定随机种子数。LightGBM是另一个梯度提升库,通常被认为在大型数据集上具有较高的性能。
LGBMClassifier(random_sta比较结果
逻辑回归

梯度提升分类器

随机森林

XGBClassifier

CatBoostClassifier

LGBMClassifier

在此案例中,CatBoost模型的分类预测能力是最理想的,能够很大程度找准真正离职的职员。
预测
-
model.pre_proba(tempdrop(columns = ['id']))[:, 1]
-
-
frame = dftest[['id']].copy()
总结
对职员离职预测进行了深入的研究,采用了多种机器学习算法进行分类预测,包括逻辑回归、梯度提升、随机森林、XGBoost、CatBoost和LightGBM,并进行了交叉验证和可视化。
通过数据预处理和特征工程,该论文构建了多个预测模型,包括逻辑回归、梯度提升、随机森林、XGBoost、CatBoost和LightGBM。这些模型在数据集上进行了训练和评估,并采用了交叉验证技术来评估模型的性能和稳定性。
其中,逻辑回归模型采用了L2正则化来防止过拟合,并使用了网格搜索技术来优化超参数。梯度提升模型采用了决策树作为基本单元,并使用了自适应权重的策略来优化提升过程。随机森林模型采用了多个决策树的集成方法,并使用了特征重要性来评估特征的重要性。XGBoost模型采用了梯度提升算法,并使用了正则化项来优化模型的复杂度。CatBoost模型采用了梯度提升算法,并使用了类别特征的独热编码来处理分类特征。LightGBM模型采用了决策树算法,并使用了高效的数据结构和算法来优化训练过程。
最终,得出了结论:在预测职员离职的分类问题上,不同的机器学习算法具有不同的性能表现和优劣。通过交叉验证和可视化技术,我们可以评估模型的性能和稳定性,并为实际应用提供可靠的预测结果。
关于分析师
在此对 Changxuan Li 对本文所作的贡献表示诚挚感谢,他在长江大学完成了油气大数据分析方向的本科学位,专注油气数据领域。擅长 SQL 语言、Python、R 、机器学习、数据分析、数据处理 。

