

拓端tecdat|python用支持向量机回归(SVR)模型分析用电量预测电力消费
原文链接:http://tecdat.cn/?p=23921
原文出处:拓端数据部落公众号
本文描述了训练支持向量回归模型的过程,该模型用于预测基于几个天气变量、一天中的某个小时、以及这一天是周末/假日/在家工作日还是普通工作日的用电量。
关于支持向量机的快速说明
支持向量机是机器学习的一种形式,可用于分类或回归。尽可能简单地说,支持向量机找到了划分两组数据的最佳直线或平面,或者在回归的情况下,找到了在容差范围内描述趋势的最佳路径。
对于分类,该算法最大限度地减少了对数据进行错误分类的风险。
对于回归,该算法使回归模型在某个可接受的容差范围内没有获得的数据点的风险最小化。
导入一些包和数据
-
-
import pandas as pd # 对于数据分析,特别是时间序列
-
import numpy as np # 矩阵和线性代数的东西,类似MATLAB
-
from matplotlib import pyplot as plt # 绘图
-
Scikit-learn是Python中的大型机器学习包之一。
-
from sklearn import svm
-
from sklearn import cross_validation
-
from sklearn import preprocessing as pre
在此随机插入更好的数据可视化。
-
# 设置颜色
-
graylight = '#d4d4d2'
-
gray = '#737373'
-
red = '#ff3700'
-
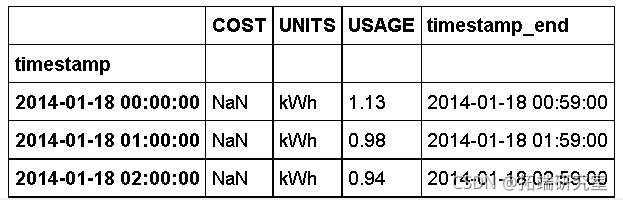
我在这个模型中使用的数据是通过公寓中安装的智能电表中获得的。
USAGE "字段给出了该小时内的用电度数。
-
-
elec.head(3)
![]()
Out[5]:
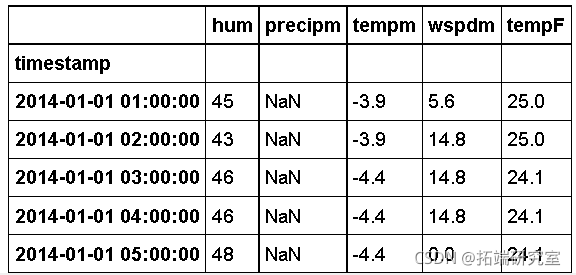
天气数据提取。
-
-
weather.head()
![]()
![]()
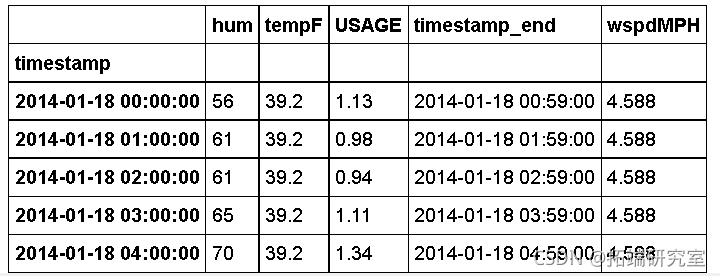
预处理
合并电力和天气
首先,我们需要将电力数据和天气数据合并到一个数据框中,并去除无关的信息。
-
-
# 合并成一个Pandas数据框架
-
pd.merge(weather, elec,True, True)
-
-
# 从数据框架中删除不必要的字段
-
del elec['tempm'], elec['cost']
-
-
# 将风速转换为单位
-
elec['wspdm'] * 0.62
-
-
elec.head()
-
![]()
-
fig = plt.figure(figsize=[14,8])
-
-
elecweather['USAGE'].plot
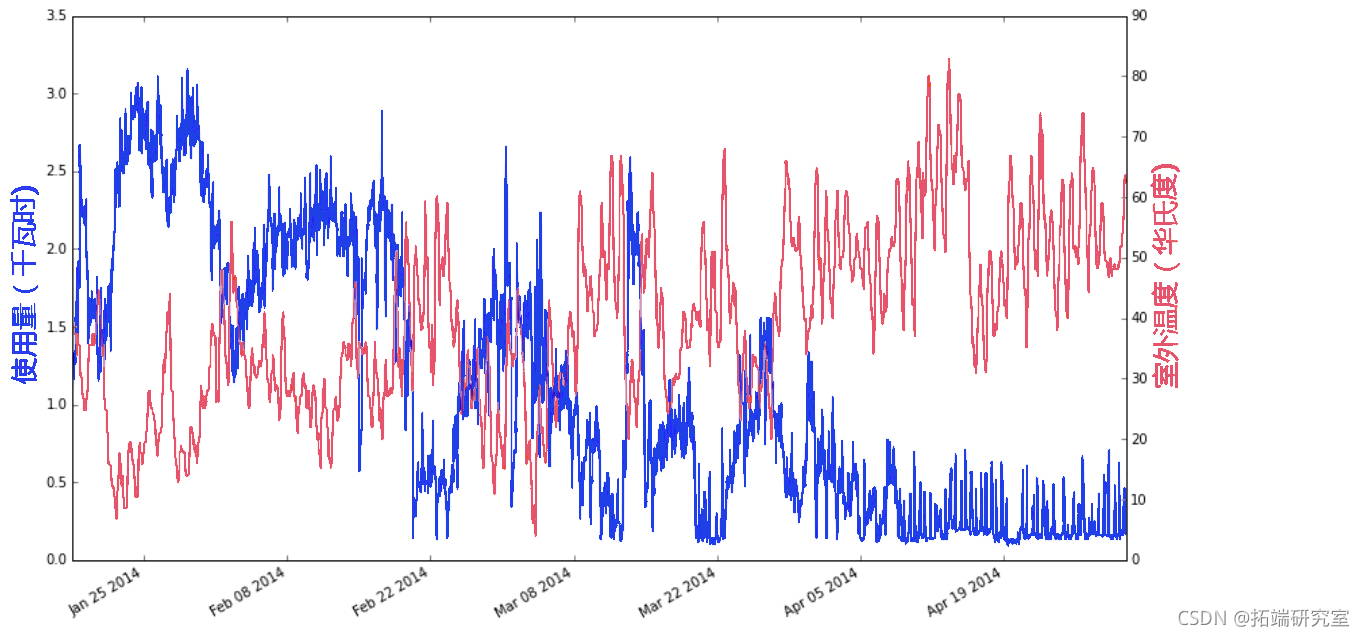
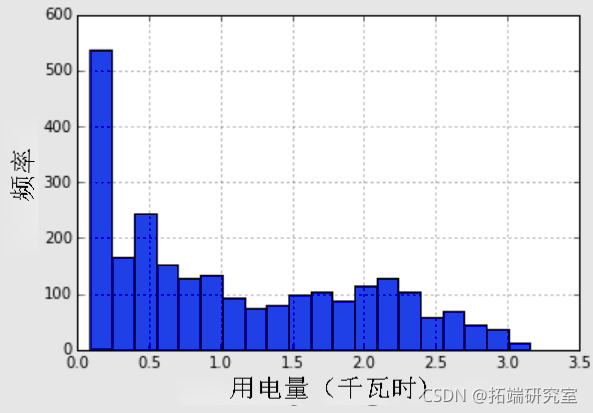
我想将典型的工作日与周末、假日和在家工作的日子区分开来。所以现在所有的正常工作日都是0,所有的假期、周末和在家工作的日子都是1。
分类变量:平日与周末/假期/在家工作日
-
-
## 将周末和节假日设置为1,否则为0
-
elecwea['Day'] = np.zeros
-
-
# 周末
-
elecwea['Atypical_Day'][(elecwea.index.dawe==5)|(elecwea.index.dawe==6)] = 1
-
-
# 假期,在家工作日
-
假期 = ['2014-01-01','2014-01-20']
-
workhome = ['2014-01-21','2014-02-13','2014-03-03','2014-04-04']
-
-
for i in range(len(holiday)):
-
elecwea['Day'][elecwea.index.date==np.datetime64(holidays[i])] = 1
-
for i in range(len(workhome)):
-
elecwea['Day'][elecwea.index.date==np.datetime64(workhome[i]) ] = 1
-
-
elecwea.head(3)
-

更多的分类变量:一周中的一天,小时
在这种情况下,一天中的每个小时是一个分类变量,而不是连续变量。做分析时,需要对一天中的每一个小时进行 "是 "或 "否 "的对应。
-
-
# 为一天中的每个小时创建新的列,如果index.hour是该列对应的小时,则分配1,否则分配0
-
-
for i in range(0,24):
-
elecweat[i] = np.zeros(len(elecweat['USAGE'))
-
elecweat[i][elecweat.index.hour==i] = 1
-
-
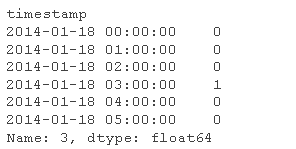
# 例子 3am
-
elecweat[3][:6]
-
时间序列:需要附加上以前的用电需求的历史窗口
由于这是一个时间序列,如果我们想预测下一小时的能耗,训练数据中任何给定的X向量/Y目标对都应该提供当前小时的用电量(Y值,或目标)与前一小时(或过去多少小时)的天气数据和用量(X向量)。
-
-
# 在每个X向量中加入历史用量
-
-
# 设置预测的提前小时数
-
hours = 1
-
-
# 设置历史使用小时数
-
hourswin = 12
-
-
-
for k in range(hours,hours+hourswin):
-
-
elec_weat['USAGE-%i'% k] = np.zero(len(elec_weat['USAGE'])
-
-
-
-
for i in range(hours+hourswi,len(elecweat['USAGE']))。)
-
-
for j in range(hours,hours+hourswin):
-
-
elec_weat['USAGE-%i'% j][i] = elec_weat['USAGE]i-j] 。
-
-
-
elec_weat.head(3)
-

分成训练期和测试期
由于这是时间序列数据,定义训练期和测试期更有意义,而不是随机的零星数据点。如果它不是一个时间序列,我们可以选择一个随机的样本来分离出一个测试集。
-
-
# 定义训练和测试期
-
train_start = '18-jan-2014'(训练开始)。
-
train_end = '24-march-2014'.
-
test_start = '25-march-2014'(测试开始)。
-
test_end = '31-march-2014'。
-
-
-
-
# 分成训练集和测试集(仍在Pandas数据帧中)。
-
-
xtrain = elec_and_weather[train_start:train_end]。
-
del xtrain['US']
-
del xtrain['time_end']
-
-
-
ytrain = elec_and_weather['US'][train_start:train_end] 。
-
将训练集输出成csv,看得更清楚。
X_train_df.to_csv('training_set.csv')
![]()
scikit-learn包接收的是Numpy数组,而不是Pandas DataFrames,所以我们需要进行转换。
-
# 用于sklearn的Numpy数组
-
-
X_train = np.array(X_train_df)
标准化变量
所有的变量都需要进行标准化。该算法不知道每个变量的尺度是什么。换句话说,温度一栏中的73的值看起来会比前一小时的千瓦时使用量中的0.3占优势,因为实际值是如此不同。sklearn的预处理模块中的StandardScaler()将每个变量的平均值去除,并将其标准化为单位方差。当模型在按比例的数据上进行训练时,模型就会决定哪些变量更有影响力,而不是由任意的比例/数量级来预先决定这种影响力。
训练SVR模型
将模型拟合训练数据!
-
SVR_model = svm.SVR(kernel='rbf',C=100,gamma=.001).fit(X_train_scaled,y_train)
-
print 'Testing R^2 =', round(SVR_model.score(X_test_scaled,y_test),3)
![]()
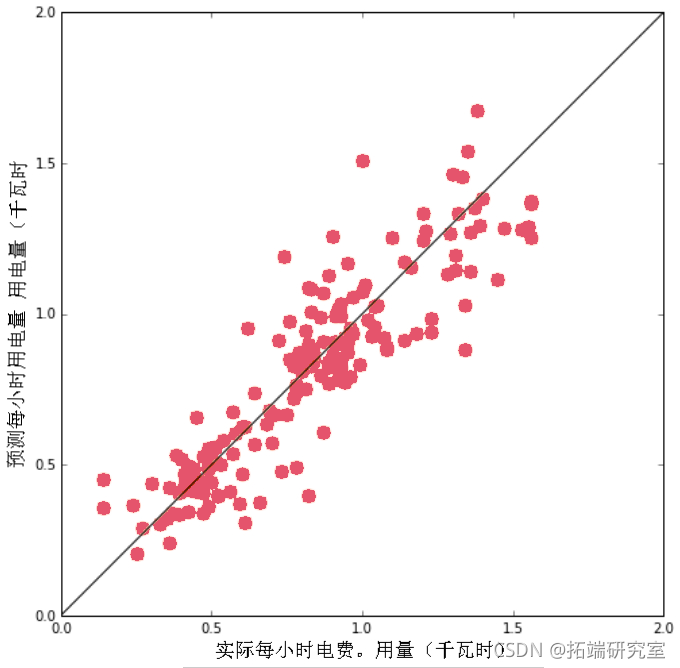
预测和测试
计算下一小时的预测(预测!)我们预留了一个测试数据集,所以我们将使用所有的输入变量(适当的缩放)来预测 "Y "目标值(下一小时的使用率)。
-
-
# 使用SVR模型来计算预测的下一小时使用量
-
SVRpredict(X_test_scaled)
-
-
# 把它放在Pandas数据框架中,以便于使用
-
DataFrame(predict_y)
-
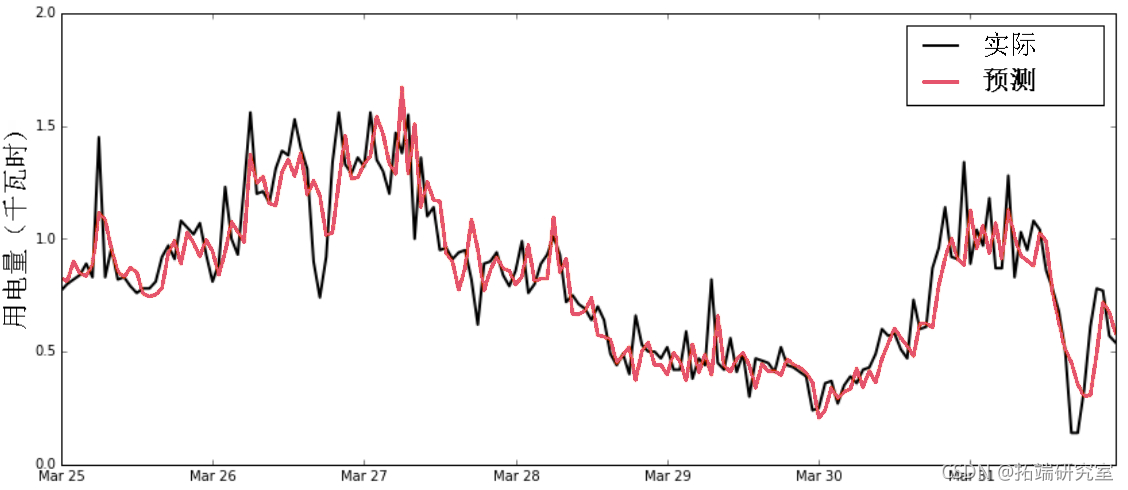
绘制测试期间的实际和预测电力需求的时间序列。
-
-
# 绘制预测值和实际值
-
-
plt.plot(index,y_test_df,color='k')
-
plt.plot(predictindex,predict_y)
重新取样的结果为每日千瓦时
-
-
### 绘制测试期间的每日总千瓦时图
-
-
-
y_test_barplot
-
ax.set_ylabel('每日总用电量(千瓦时)')
-
-
# Pandas/Matplotlib的条形图将x轴转换为浮点,所以需要找回数据时间
-
ax.set_xticklabels([dt.strftime('%b %d') for dt in

误差测量
以下是一些精度测量。
len(y_test_df)
![]()
均方根误差
这实际上是模型的标准误差,其单位与预测变量(或这里的千瓦时)的单位相同。
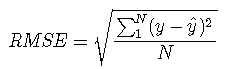
calcRMSE(predict_y, y_test_df)
![]()
平均绝对百分比误差
用这种方法,计算每个预测值和实际值之间的绝对百分比误差,并取其平均值;计量单位是百分比。如果不取绝对值,而模型中又没有什么偏差,你最终会得到接近零的结果,这个方法就没有价值了。
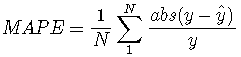
errorsMAPE(predict_y, y_test_df)
![]()
平均偏置误差
平均偏差误差显示了模型的高估或低估情况。初始SVM模型的平均偏差误差为-0.02,这表明该模型没有系统地高估或低估每小时的千瓦时消耗。
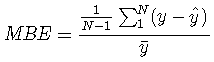
calcMBE(predict_y, y_test_df)
![]()
变异系数
这与RMSE类似,只是它被归一化为平均值。它表明相对于平均值有多大的变化。
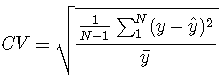
![]()
这与RMSE类似,只是它被归一化为平均值。它表明相对于平均值有多大的变化。
-
-
plot45 = plt.plot([0,2],[0,2],'k')

最受欢迎的见解
1.在python中使用lstm和pytorch进行时间序列预测
2.python中利用长短期记忆模型lstm进行时间序列预测分析

 浙公网安备 33010602011771号
浙公网安备 33010602011771号