

拓端tecdat|【数据分享】学生受欢迎程度评价数据集
原文链接: http://tecdat.cn/?p=10809
http://tecdat.cn/?p=10809
原文出处:拓端数据部落公众号
数据简介
受欢迎程度(简称:流行度)数据集由来自不同班级的学生组成,并且由于每个学生都属于一个唯一的班级,因此它是一个嵌套设计。因变量是“流行度”,它是一个学生自评的受欢迎程度,范围为0-10。预测指标包括学生级别的性别(二分变量)和Extrav(连续的自我评价的外向得分),以及班级的Texp(年份为单位的老师经验, 是连续的)。
数据详情
数据格式
sav
字段
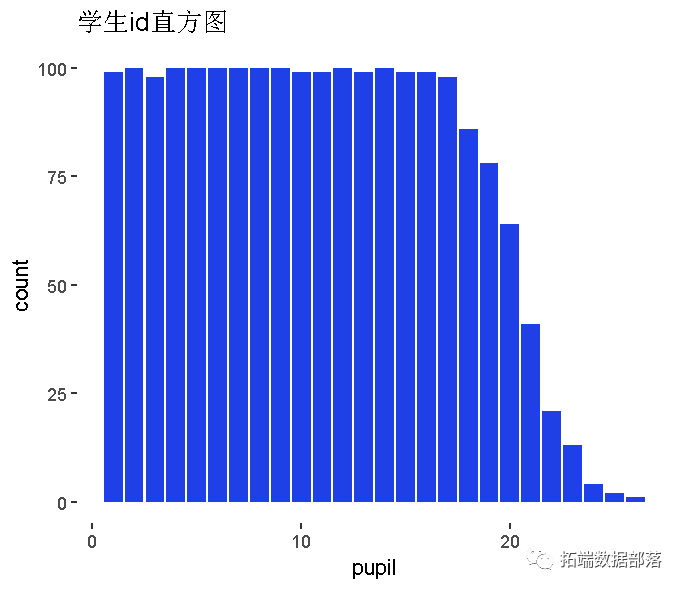
学生id
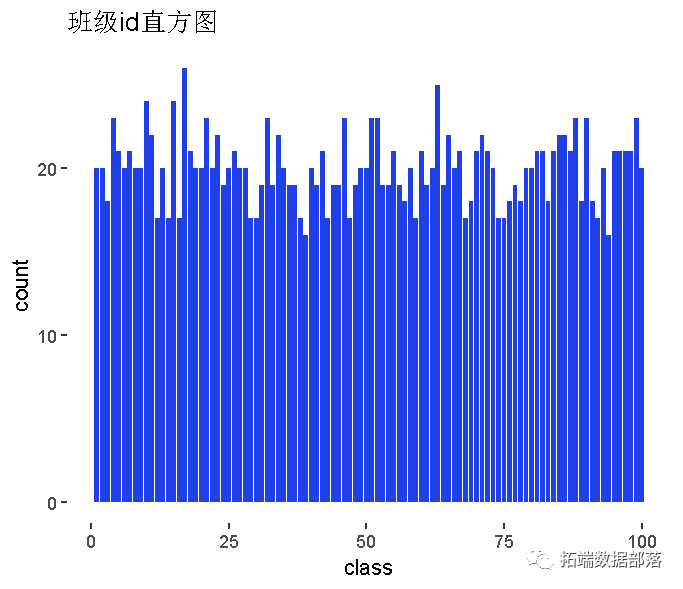
班级id
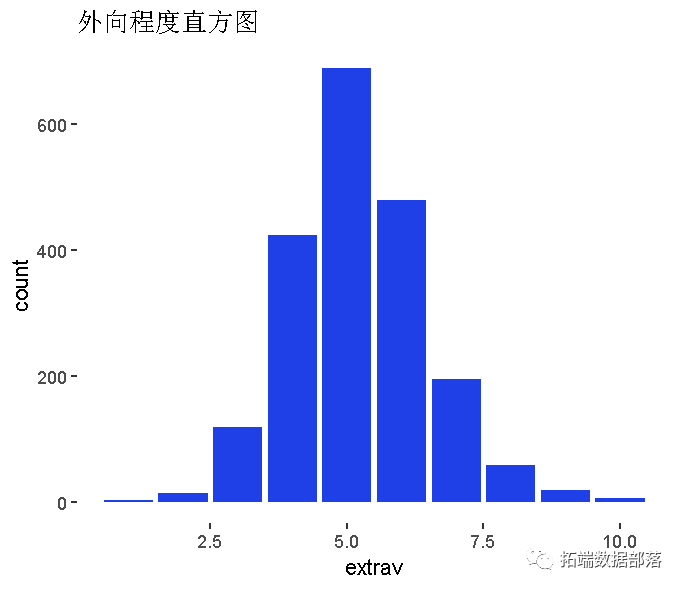
外向程度
学生性别
教师经验(年)
受欢迎程度 测量分数
受欢迎程度 教师评价
大小
169kb
样本量
2000
数据浏览
以前18名同学的数据为例,我们来预览一下:
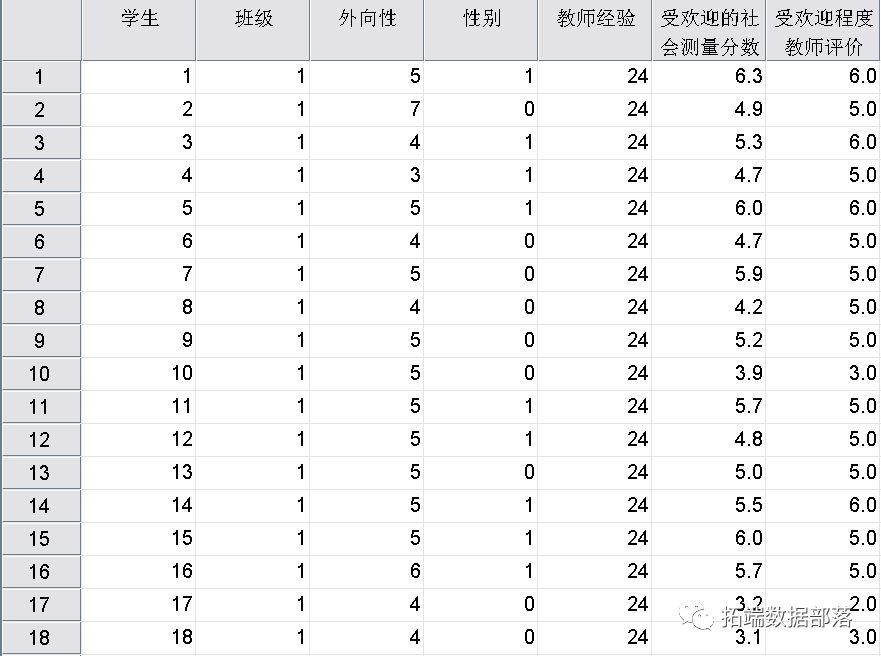
变量探索:
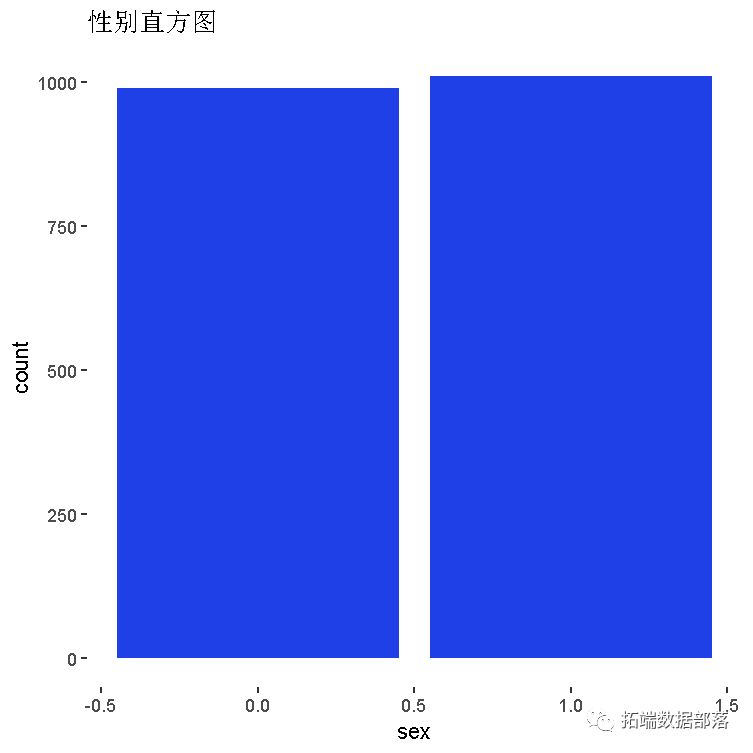
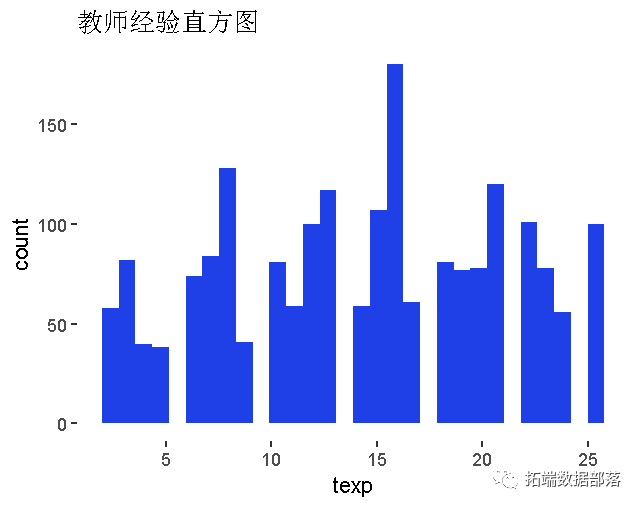
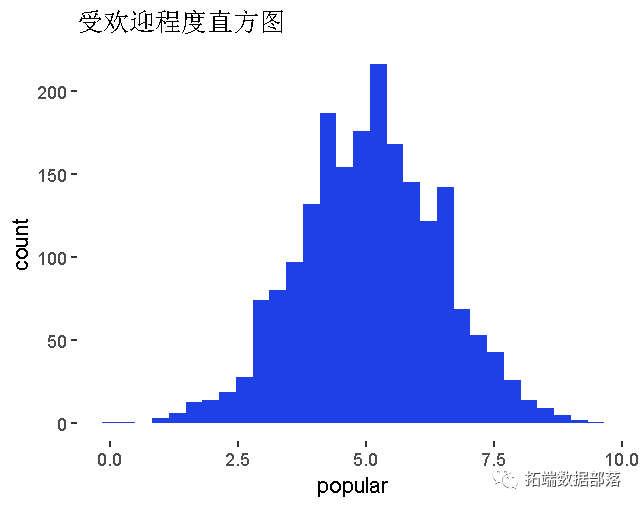
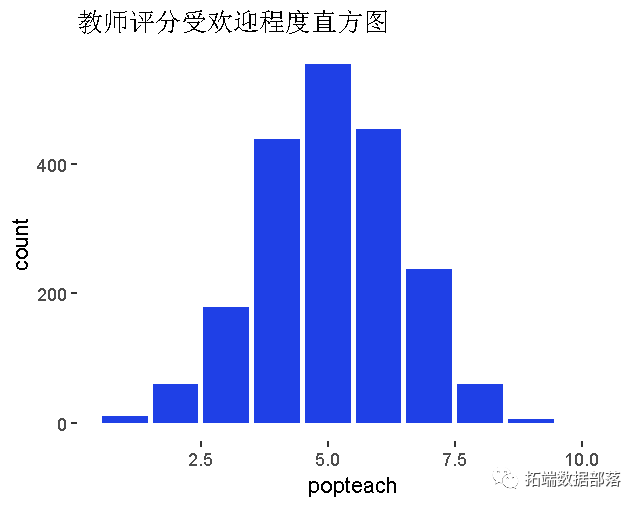
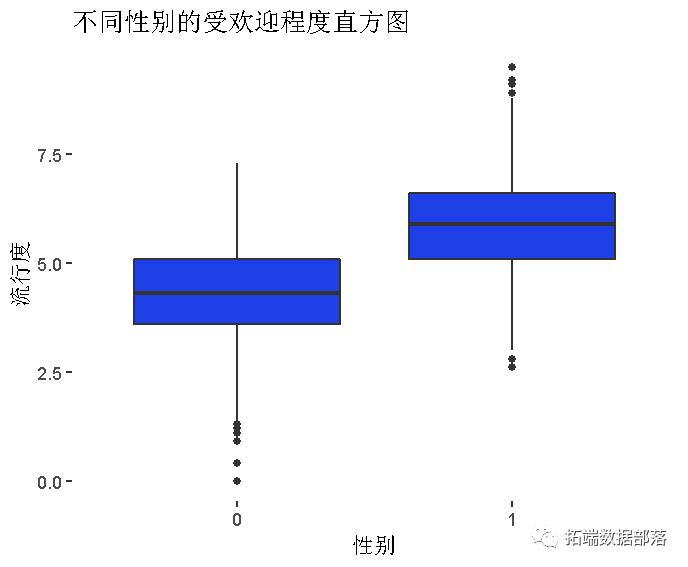
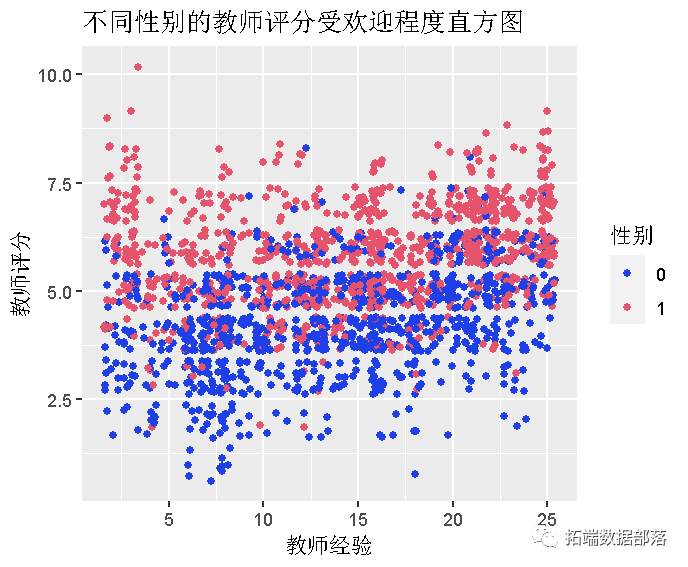
数据获取
在公众号后台回复“流行度数据”,可获取完整数据。
参考文献
Enders, Craig K. and Tofighi, Davood (2007). “Centering Predictor Variables in Cross-Sectional Multilevel Models: A New Look at an Old Issue.” Psychological Methods, vol. 12, pg. 121-138.
Hox, Joop J. (2010). Multilevel Analysis (2nd ed.). New York: Routledge
点击标题查阅往期内容
R语言用线性混合效应(多水平/层次/嵌套)模型分析声调高低与礼貌态度的关系
R语言nlme、nlmer、lme4用(非)线性混合模型non-linear mixed model分析藻类数据实例
R语言混合线性模型、多层次模型、回归模型分析学生平均成绩GPA和可视化
R语言线性混合效应模型(固定效应&随机效应)和交互可视化3案例
R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据
R语言混合效应逻辑回归(mixed effects logistic)模型分析肺癌数据
R语言建立和可视化混合效应模型mixed effect model
R语言用Rshiny探索lme4广义线性混合模型(GLMM)和线性混合模型(LMM)
R语言如何解决线性混合模型中畸形拟合(Singular fit)的问题
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
R语言用WinBUGS 软件对学术能力测验(SAT)建立分层模型
使用SAS,Stata,HLM,R,SPSS和Mplus的分层线性模型HLM
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型

