


拓端数据tecdat|R语言基于温度对城市层次聚类、kmean聚类、主成分分析和Voronoi图可视化
原文链接: http://tecdat.cn/?p=20960
为了说明层次聚类技术和k-均值,我使用了了城市温度数据集,其中包括几个城市的月平均气温。
我们有15个城市,每月进行一次观测
boxplot(temp[,1:12],main="月平均温度")
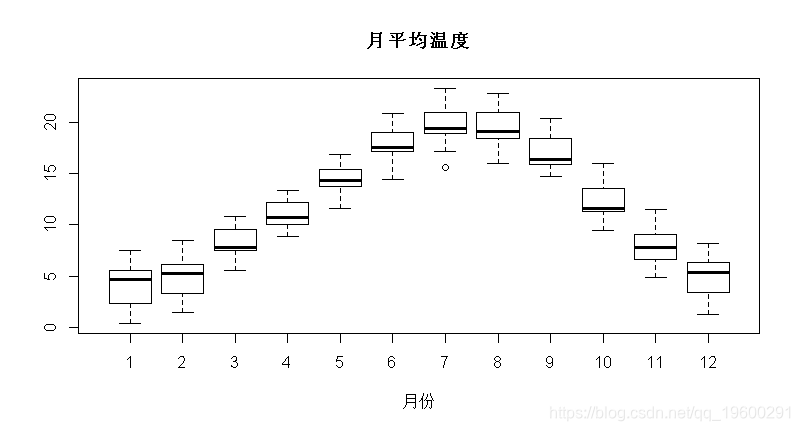
由于方差看起来相当稳定,我们不会将这里的变量“标准化”,
> apply(月份,2,sd)

为了得到一个层次聚类分析,使用实例
hclust(dist , method = "ward")

另一种选择是使用
-
-
> plot(h2)
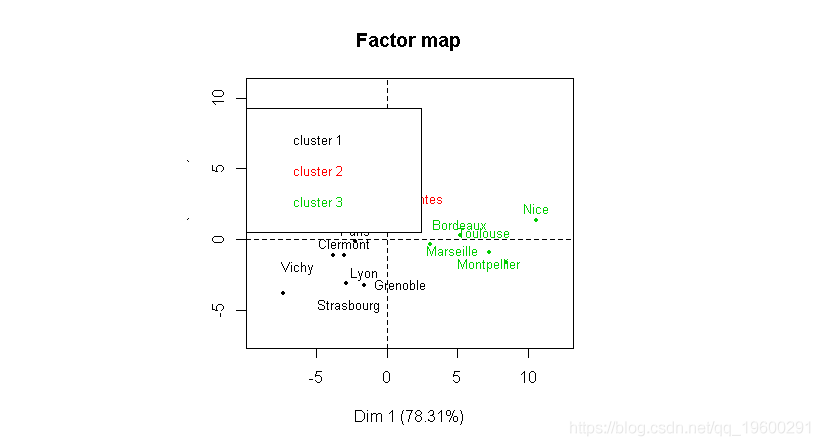
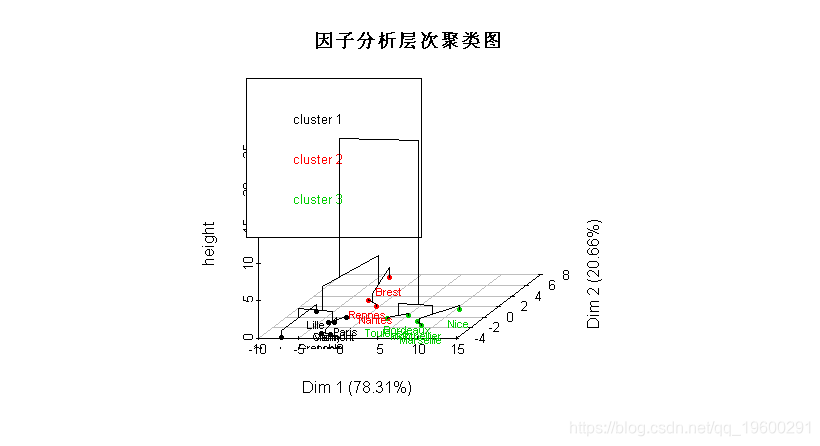
在这里,我们用主成分分析将观察结果可视化。我们这里还有一个自动选择类的数目,这里是3个。我们可以得到组的描述
或直接
cutree(cah,3)我们也可以自己可视化这些类,
-
PCA(X,scale.unit=FALSE)
-
plot( ind$coord[,1:2],col="white")
-
text( ind$coord[,1],acp$ind$coord[,2],
可以绘制出这些簇的中心点
> points(PT$Dim.1,PT$Dim.2,pch=19)如果我们在这些中心周围添加Voronoi集,我们看到的是中间的点,恰好是三个区域的交点
-
vormo(PT$Dim.1,PT$Dim.2)
-
plot(V,add=TRUE)
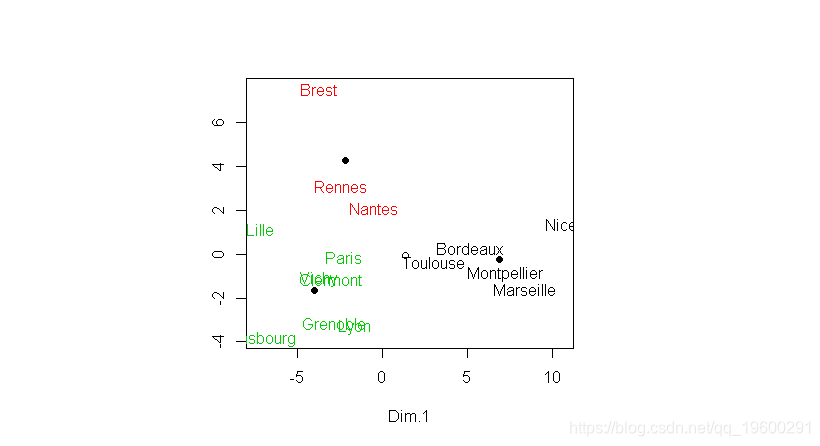
要可视化这些区域,请使用Voronoi图,它又叫泰森多边形或Dirichlet图,它是由一组由连接两邻点直线的垂直平分线组成的连续多边形组成。
-
p=function(x,y){
-
+ which.min((PT$Dim.1-x)^2+(PT$Dim.2-y)^2)
-
image(vx,vy,z,col=c(rgb(1,0,0,.2),
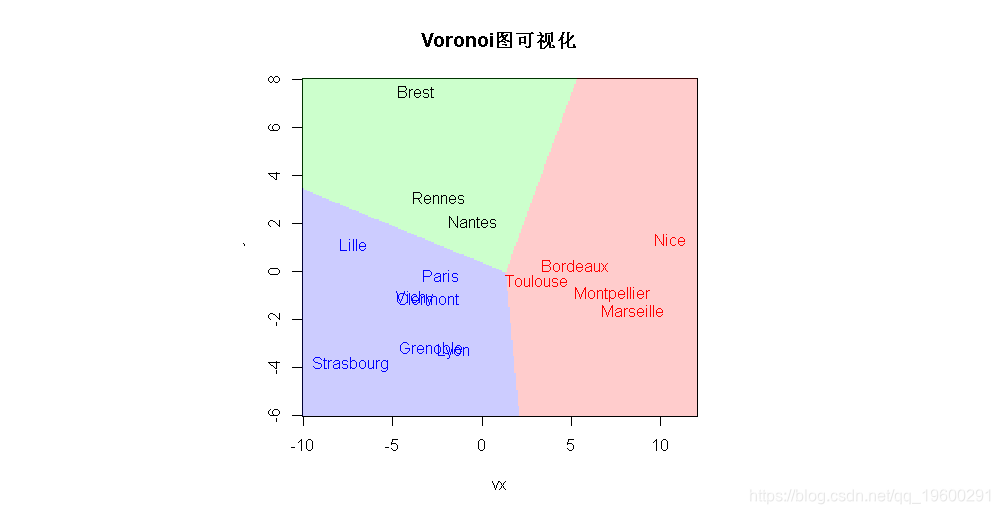
实际上,这三组(和这三个区域)也是我们用k-均值算法得到的,
-
kmeans(coord[,1:2],3)
-
-
K-means clustering
-
with 3 clusters of sizes 3, 7, 5
由于我们有一些空间数据,我们可以在地图上把它们可视化
points(Long,Lati,col=groups.3)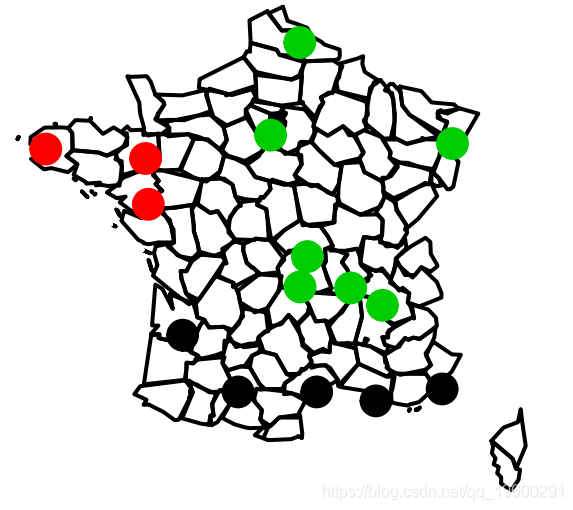
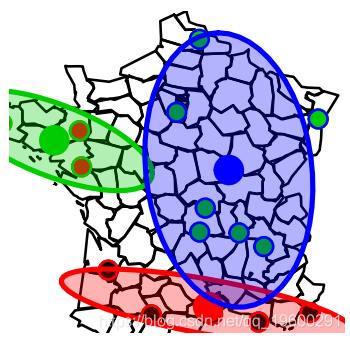
或者,为了可视化这些区域,使用
-
for(i in 1:3)
-
+ Ellipse( Long[groups.3==i],

最受欢迎的见解
3.R语言对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归
5.Python Monte Carlo K-Means聚类实战
▍关注我们
【大数据部落】第三方数据服务提供商,提供全面的统计分析与数据挖掘咨询服务,为客户定制个性化的数据解决方案与行业报告等。
▍咨询链接:http://y0.cn/teradat
▍联系邮箱:3025393450@qq.com
