本文将说明单变量和多变量金融时间序列的不同模型,特别是条件均值和条件协方差矩阵、波动率的模型。
均值模型
本节探讨条件均值模型。
iid模型
我们从简单的iid模型开始。iid模型假定对数收益率xt为N维高斯时间序列:
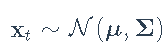
均值和协方差矩阵的样本估计量分别是样本均值
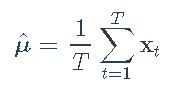
和样本协方差矩阵
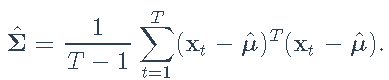
我们从生成数据开始,熟悉该过程并确保估计过程给出正确的结果(即完整性检查)。然后使用真实的市场数据并拟合不同的模型。
让我们生成合成iid数据并估算均值和协方差矩阵:
-
-
X <- rmvnorm(n = T, mean = mu, sigma = Sigma)
-
-
-
-
-
-
-
-
norm(Sigma_scm - Sigma, "F")
-
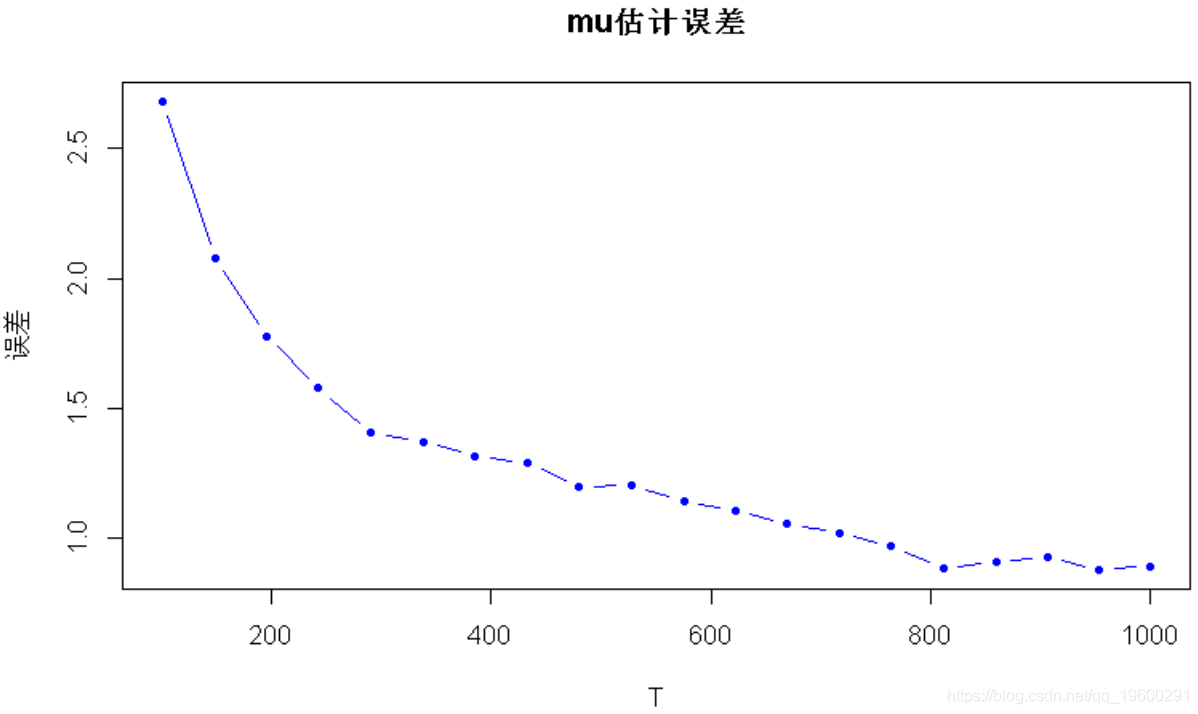
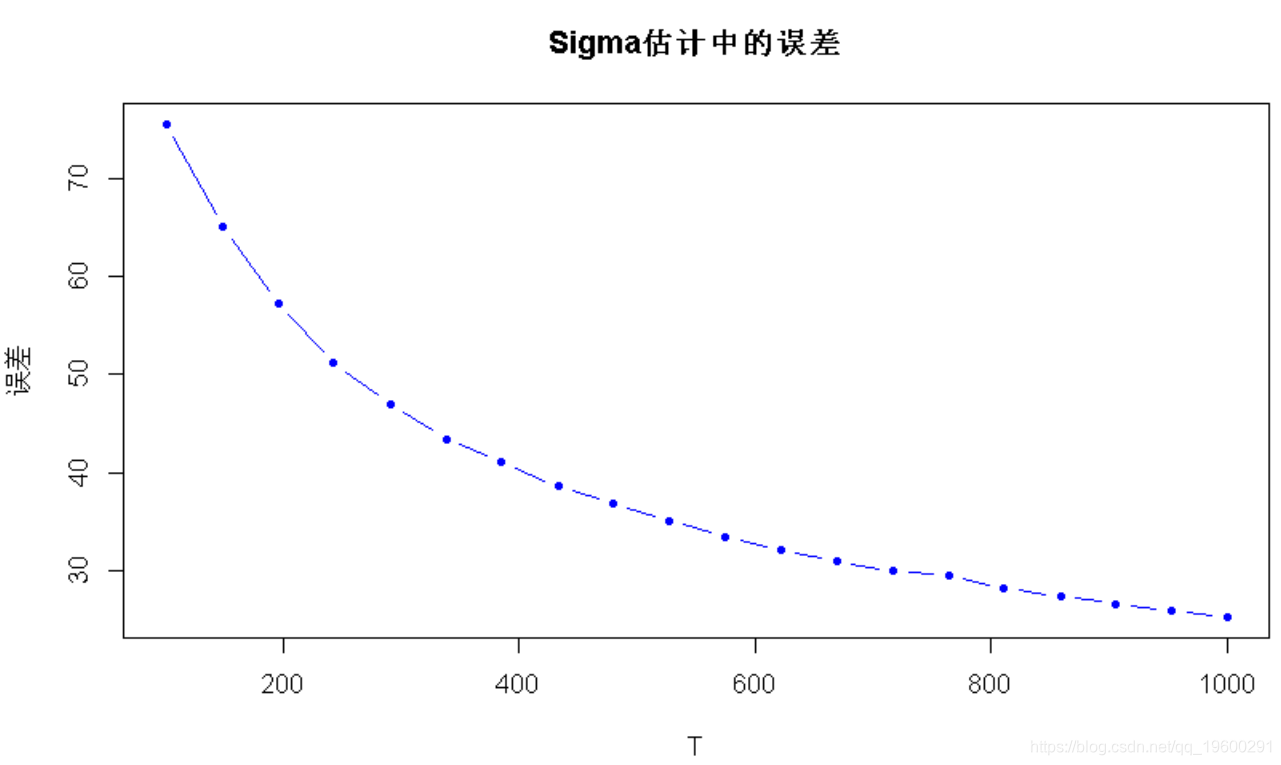
现在,让我们针对不同数量的观测值T再做一次:
-
-
-
X <- rmvnorm(n = T_max, mean = mu, sigma = Sigma)
-
-
-
-
-
-
-
-
-
-
error_mu_vs_T <- c(error_mu_vs_T, norm(mu_sm - mu, "2"))
-
error_Sigma_vs_T <- c(error_Sigma_vs_T, norm(Sigma_scm - Sigma, "F"))
-
-
-
plot(T_sweep, error_mu_vs_T,
-
-
plot(
T_sweep, error_Sigma_vs_T
-
main =
"Sigma估计中的误差", ylab = "误差"
单变量ARMA模型
对数收益率xt上的ARMA(p,q)模型是
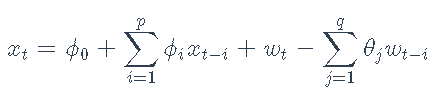
其中wt是均值为零且方差为σ2的白噪声序列。模型的参数是系数ϕi,θi和噪声方差σ2。
请注意,ARIMA(p,d,q)模型是时间差分为d阶的ARMA(p,q)模型。因此,如果我们用xt代替对数价格,那么先前的对数收益模型实际上就是ARIMA(p,1,q)模型,因为一旦对数价格差分,我们就获得对数收益。
rugarch生成数据
我们将使用rugarch包 生成单变量ARMA数据,估计参数并进行预测。
首先,我们需要定义模型:
-
-
-
-
-
#> *----------------------------------*
-
-
#> *----------------------------------*
-
#> Conditional Mean Dynamics
-
#> ------------------------------------
-
#> Mean Model : ARFIMA(1,0,0)
-
-
-
#> Conditional Distribution
-
#> ------------------------------------
-
-
-
#> Includes Shape : FALSE
-
#> Includes Lambda : FALSE
-
-
-
#> Level Fixed Include Estimate LB UB
-
-
-
-
#> arfima 0.00 0 0 0 NA NA
-
#> archm 0.00 0 0 0 NA NA
-
#> mxreg 0.00 0 0 0 NA NA
-
#> sigma 0.20 1 1 0 NA NA
-
#> alpha 0.00 0 0 0 NA NA
-
-
#> gamma 0.00 0 0 0 NA NA
-
-
-
#> delta 0.00 0 0 0 NA NA
-
#> lambda 0.00 0 0 0 NA NA
-
#> vxreg 0.00 0 0 0 NA NA
-
-
#> shape 0.00 0 0 0 NA NA
-
#> ghlambda 0.00 0 0 0 NA NA
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
然后,我们可以生成时间序列:
-
-
-
-
-
-
-
-
plot(synth_log_returns, main =
"ARMA模型的对数收益率"
-
plot(synth_log_prices, main =
"ARMA模型的对数价格"
ARMA模型
现在,我们可以估计参数(我们已经知道):
-
-
arfimaspec(mean.model =
list(armaOrder = c(1,0), include.mean = TRUE))
-
-
-
-
-
-
-
-
-
-
我们还可以研究样本数量T对参数估计误差的影响:
-
-
-
-
estim_coeffs_vs_T <- rbind(estim_coeffs_vs_T, coef(arma_fit))
-
error_coeffs_vs_T <- rbind(error_coeffs_vs_T, abs(coef(arma_fit) - true_params)/true_params)
-
-
-
-
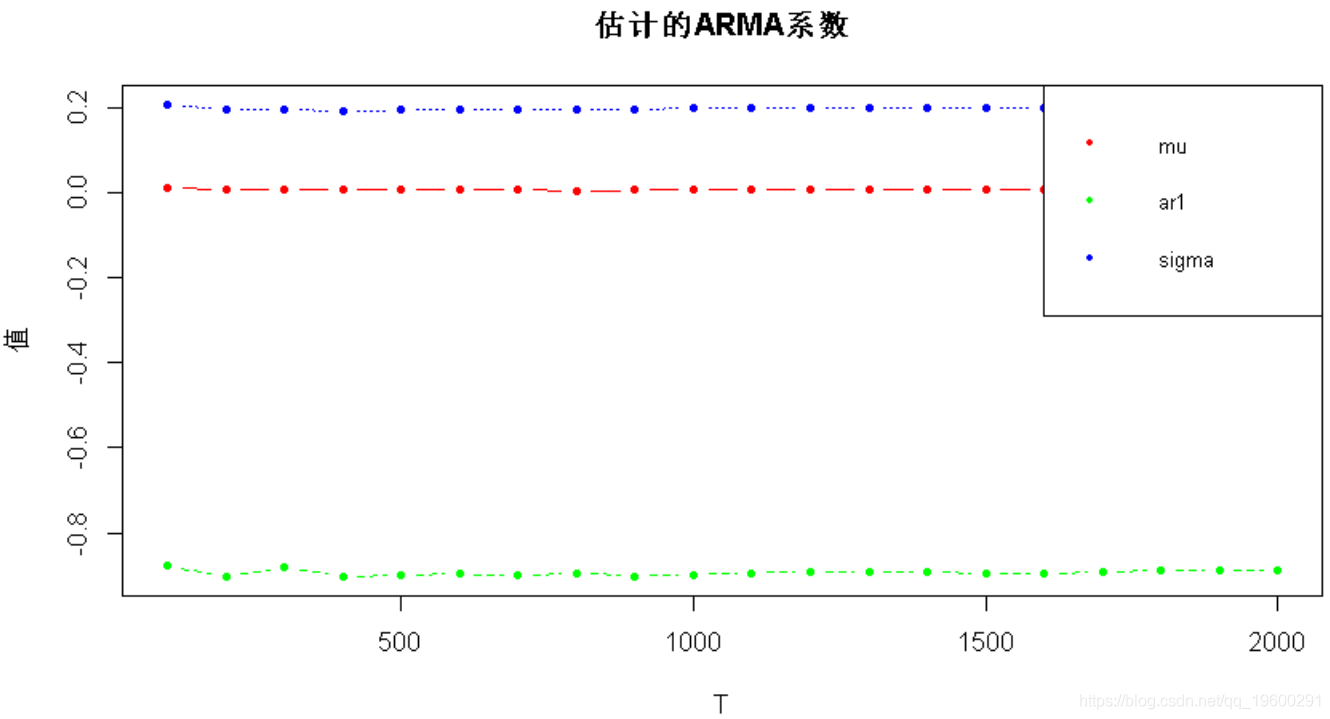
matplot(T_sweep, estim_coeffs_vs_T,
-
main =
"估计的ARMA系数", xlab = "T", ylab = "值",
-
matplot(T_sweep, 100*error_coeffs_vs_T,
-
main = "估计ARMA系数的相对误差", xlab = "T", ylab = "误差 (%)",
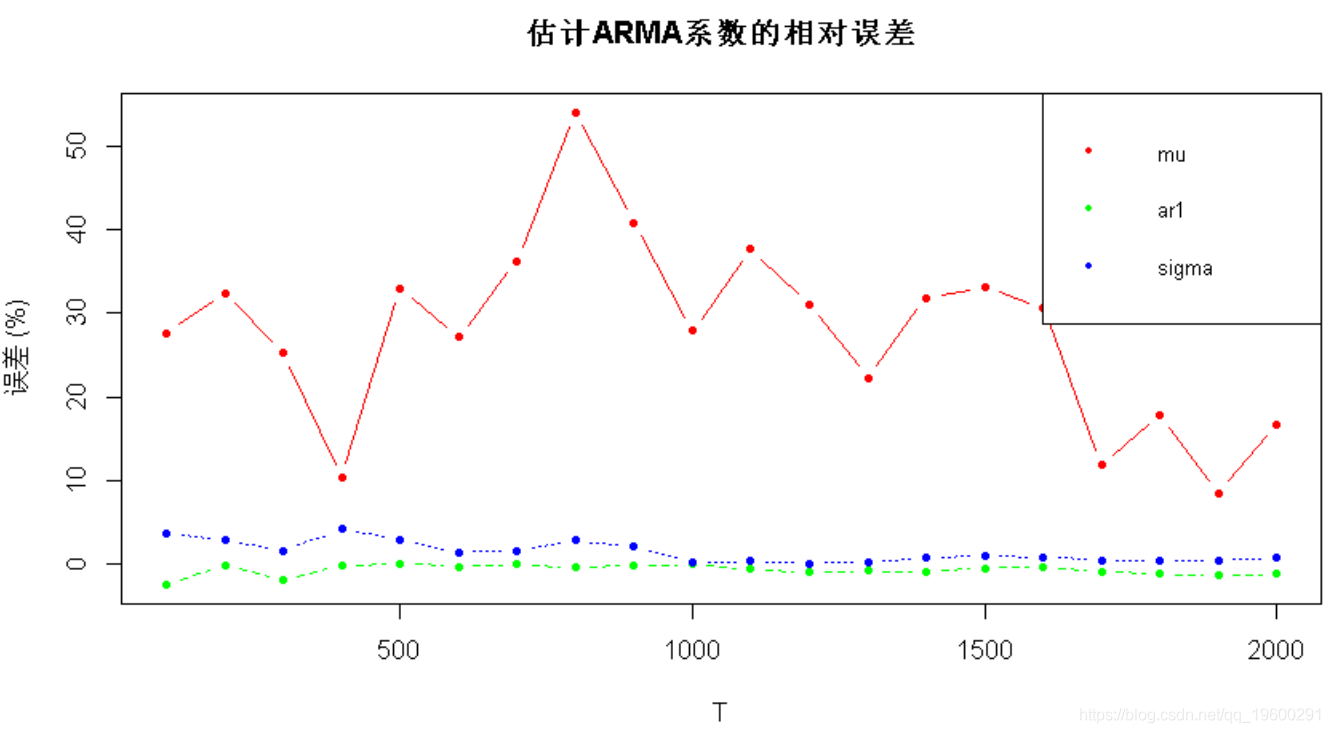
首先,真正的μ几乎为零,因此相对误差可能显得不稳定。在T = 800个样本之后,其他系数得到了很好的估计。
ARMA预测
为了进行健全性检查,我们现在将比较两个程序包 Forecast 和 rugarch的结果:
-
-
-
spec(mean.model = list(armaOrder = c(1,0), include.mean = TRUE),
-
fixed.pars = list(mu = 0.005, ar1 = -0.9, sigma = 0.1))
-
-
-
arfima(arma_fixed_spec, n.sim = 1000)@path$seriesSim
-
-
-
spec(mean.model = list(armaOrder = c(1,0), include.mean = TRUE))
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
确实,这两个软件包给出了相同的结果。
ARMA模型选择
在先前的实验中,我们假设我们知道ARMA模型的阶数,即p = 1和q = 0。实际上,阶数是未知的,因此必须尝试不同的阶数组合。阶数越高,拟合越好,但这将不可避免地导致过度拟合。已经开发出许多方法来惩罚复杂性的增加以避免过度拟合,例如AIC,BIC,SIC,HQIC等。
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
在这种情况下,由于观察次数T = 1000足够大,因此阶数被正确地检测到。相反,如果尝试使用T = 200,则检测到的阶数为p = 1,q = 3。
ARMA预测
一旦估计了ARMA模型参数ϕi ^ i和θ^j,就可以使用该模型预测未来的值。例如,根据过去的信息对xt的预测是
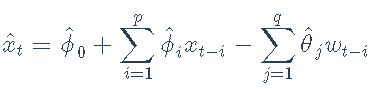
并且预测误差将为xt-x ^ t = wt(假设参数已被估计),其方差为σ2。软件包 rugarch 使对样本外数据的预测变得简单:
-
-
-
-
-
-
-
-
forecast_log_returns <- xts(arma_fore@forecast$seriesFor[
1, ], dates_out_of_sample)
-
-
-
prev_log_price <- head(tail(synth_log_prices, out_of_sample+
1), out_of_sample)
-
-
-
plot(cbind(
"fitted" = fitted(arma_fit),
-
-
-
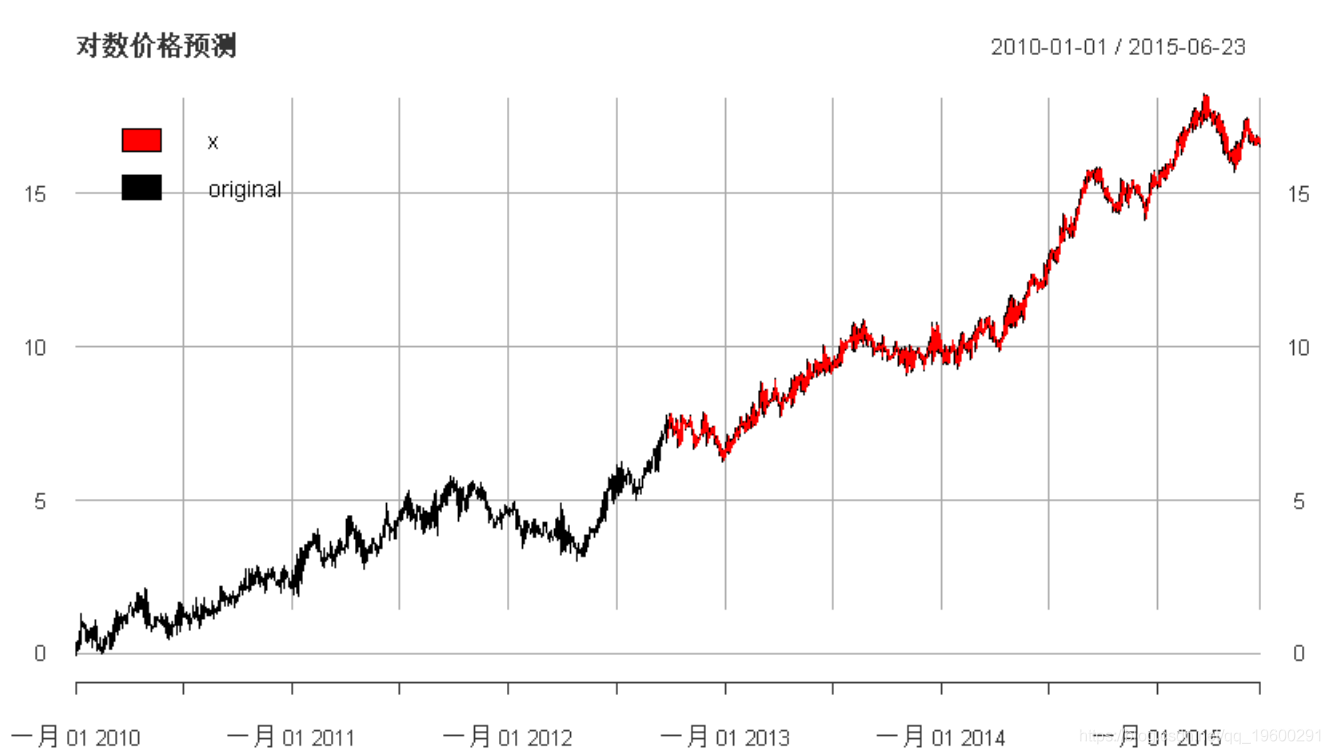
plot(cbind(
"forecast" = forecast_log_prices,
-
-
main =
"对数价格预测", legend.loc = "topleft")

多元VARMA模型
对数收益率xt上的VARMA(p,q)模型是
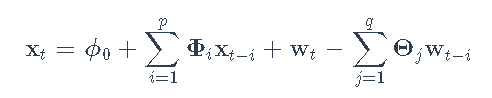
其中wt是具有零均值和协方差矩阵Σw的白噪声序列。该模型的参数是矢量/矩阵系数ϕ0,Φi,Θj和噪声协方差矩阵Σw。
比较
让我们首先加载S&P500:
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
logreturns_trn <- logreturns[
1:T_trn]
-
logreturns_tst <- logreturns[-c(
1:T_trn)]
-
-
-
-
现在,我们使用训练数据(即,对于t = 1,…,Ttrnt = 1,…,Ttrn)来拟合不同的模型(请注意,通过指示排除了样本外数据 out.sample = T_tst)。特别是,我们将考虑iid模型,AR模型,ARMA模型以及一些ARCH和GARCH模型(稍后将对方差建模进行更详细的研究)。
-
-
-
-
-
-
#> 0
.0005712982 0.0073516993
-
-
-
-
-
-
-
-
-
-
#> 0
.0005678014 -0.0220185181 0.0073532716
-
-
-
-
-
#>
mu ar1 ar2 ma1 ma2 sigma
-
#> 0
.0007223304 0.0268612636 0.9095552008 -0.0832923604 -0.9328475211 0.0072573570
-
-
-
-
-
#>
mu ar1 ma1 omega alpha1
-
#> 6
.321441e-04 8.720929e-02 -9.391019e-02 4.898885e-05 9.986975e-02
-
-
-
-
-
#>
mu omega alpha1 alpha2 alpha3 alpha4 alpha5
-
#> 7
.490786e-04 2.452099e-05 6.888561e-02 7.207551e-02 1.419938e-01 1.909541e-02 3.082806e-02
-
#>
alpha6 alpha7 alpha8 alpha9 alpha10
-
#> 4
.026539e-02 3.050040e-07 9.260183e-02 1.150128e-01 1.068426e-06
-
-
# 拟合
ARMA(1,1)+GARCH(1,1)模型
-
-
-
#>
mu ar1 ma1 omega alpha1 beta1
-
#> 6
.660346e-04 9.664597e-01 -1.000000e+00 7.066506e-06 1.257786e-01 7.470725e-01
我们使用不同的模型来预测对数收益率:
-
-
-
-
forecast(iid_fit, n.ahead = 1, n.roll = T_tst - 1)
-
-
-
-
forecast(ar_fit, n.ahead = 1, n.roll = T_tst - 1)
-
-
-
-
forecast(arma_fit, n.ahead = 1, n.roll = T_tst - 1)
-
-
-
-
forecast(arch_fit, n.ahead = 1, n.roll = T_tst - 1)
-
-
-
-
forecast(long_arch_fit, n.ahead = 1, n.roll = T_tst - 1)
-
-
-
-
forecast(garch_fit, n.ahead = 1, n.roll = T_tst - 1)
-
我们可以计算不同模型的预测误差(样本内和样本外):
-
-
-
#>
in-sample out-of-sample
-
#>
iid 5.417266e-05 8.975710e-05
-
#>
AR(1) 5.414645e-05 9.006139e-05
-
#>
ARMA(2,2) 5.265204e-05 1.353213e-04
-
#>
ARMA(1,1) + ARCH(1) 5.415836e-05 8.983266e-05
-
#>
ARCH(10) 5.417266e-05 8.975710e-05
-
#>
ARMA(1,1) + GARCH(1,1) 5.339071e-05 9.244012e-05
我们可以观察到,随着模型复杂度的增加,样本内误差趋于变小(由于拟合数据的自由度更高),尽管差异可以忽略不计。重要的实际上是样本外误差:我们可以看到,增加模型复杂度可能会得出较差的结果。就预测收益的误差而言,似乎最简单的iid模型已经足够了。
最后,让我们展示一些样本外误差的图表:
-
-
-
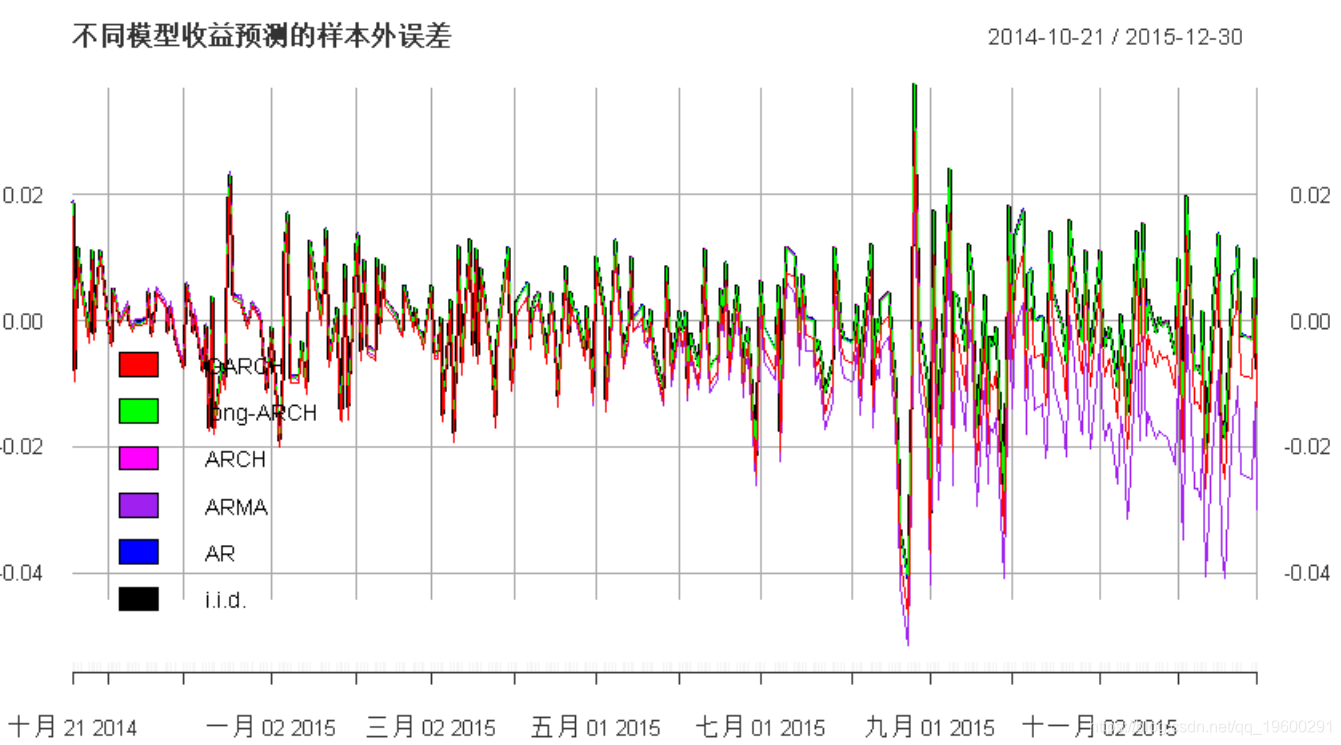
请注意,由于我们没有重新拟合模型,因此随着时间的发展,误差越大(对于ARCH建模尤其明显)。
滚动窗口比较
让我们首先通过一个简单的示例比较静态预测与滚动预测的概念:
-
-
spec <- spec(mean.model = list(armaOrder = c(2,2), include.mean = TRUE))
-
-
-
ar_static_fit <- fit(spec = spec, data = logreturns, out.sample = T_tst)
-
-
-
modelroll <- aroll(spec = spec, data = logreturns, n.ahead = 1,
-
-
-
-
plot(cbind("static forecast" = ar_static_fore_logreturns,
-
main =
"使用ARMA(2,2)模型进行预测", legend.loc = "topleft")
-
-
-
-
plot(error_logreturns, col = c("black", "red"), lwd = 2,
-
main =
"ARMA(2,2)模型的预测误差", legend.loc = "topleft")
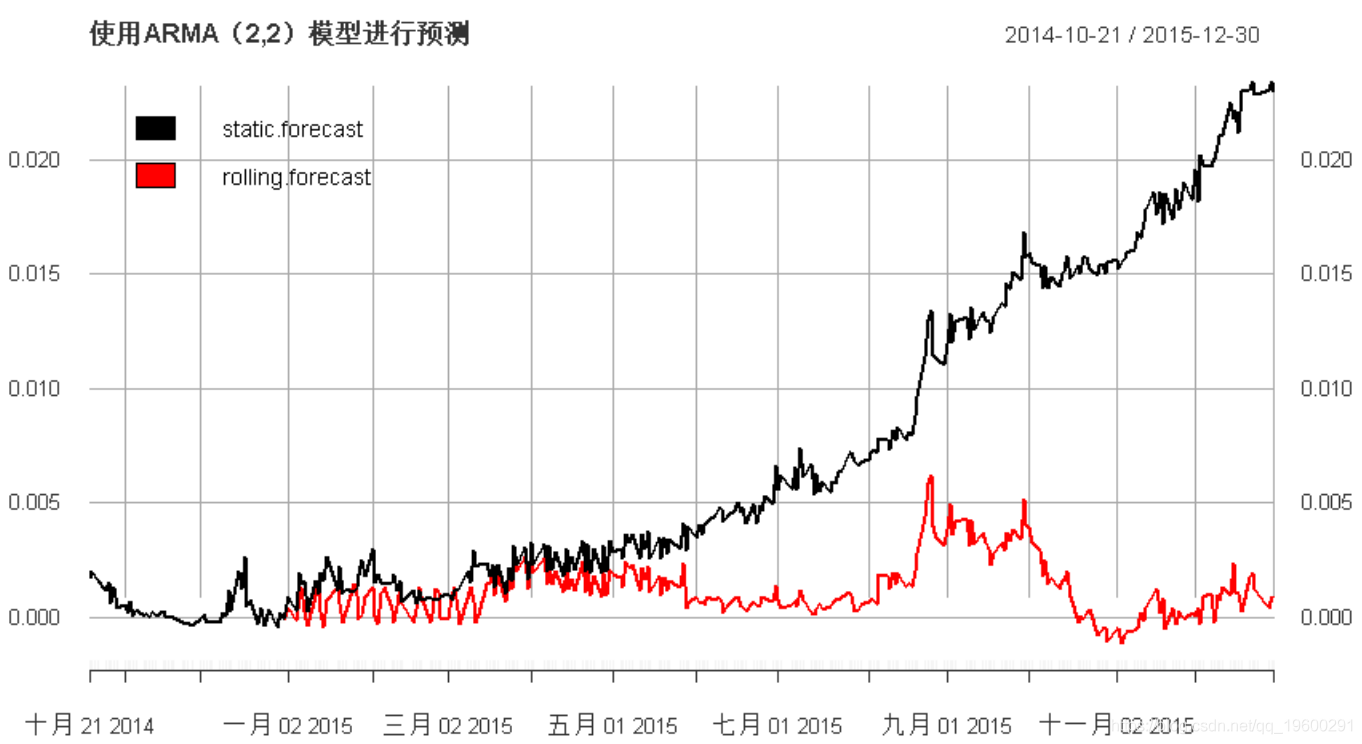
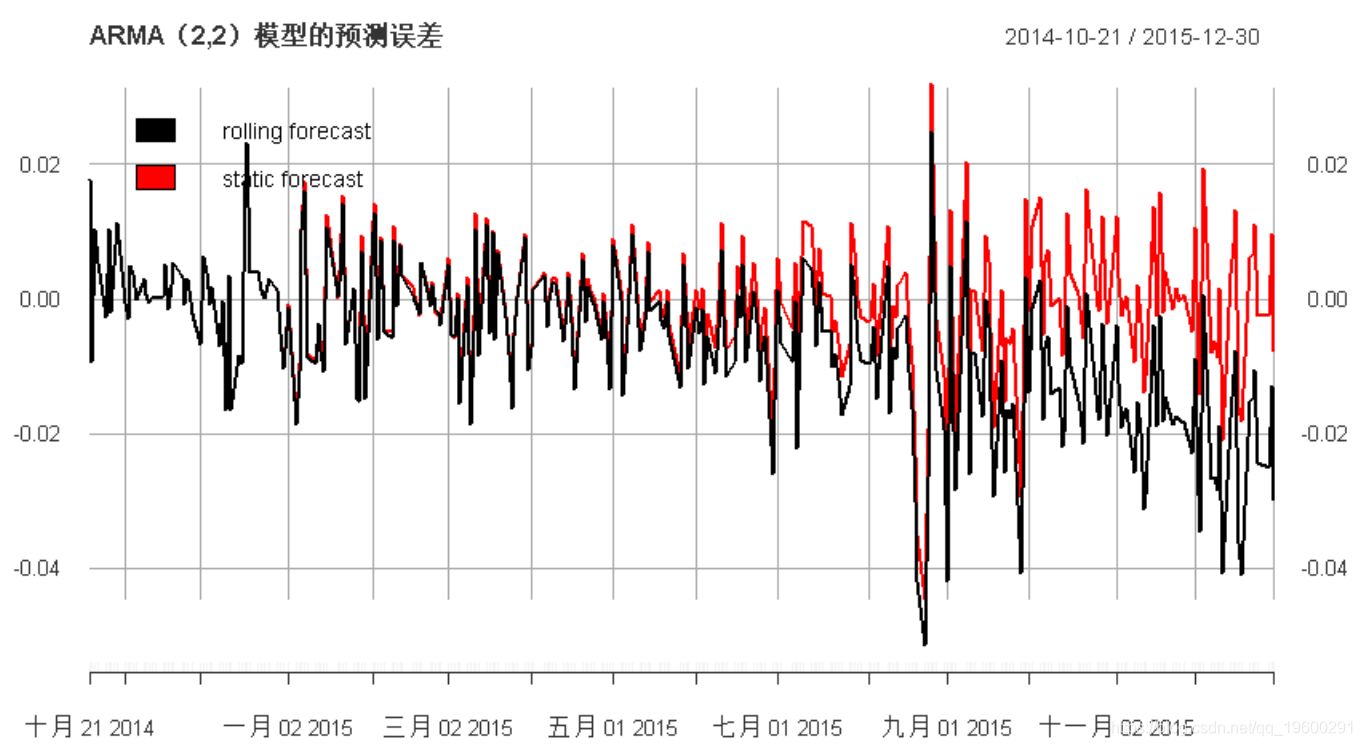
我们可以清楚地观察到滚动窗口过程对时间序列的影响。
现在,我们可以在滚动窗口的基础上重做所有模型的所有预测:
-
-
roll(iid_spec, data = logreturns, n.ahead = 1, forecast.length = T_t
-
-
-
roll(ar_spec, data = logreturns, n.ahead = 1, forecast.length = T_tst,
-
-
-
roll(arma_spec, data = logreturns, n.ahead = 1, forecast.length = T_tst,
-
-
# ARMA(1,1)+ ARCH(1)模型的滚动预测
-
roll(arch_spec, data = logreturns, n.ahead = 1, forecast.length = T_tst,
-
refit.every =
50, refit.win
-
-
# ARMA(0,0)+ ARCH(10)模型的滚动预测
-
roll(long_arch_spec, data = logreturns, n.ahead = 1, forecast.length = T_tst,
-
-
-
# ARMA(1,1)+ GARCH(1,1)模型的滚动预测
-
roll(garch_spec, data = logreturns, n.ahead = 1, forecast.length = T_tst,
-
refit.every =
50, refit.window
让我们看看滚动基准情况下的预测误差:
-
-
-
#>
in-sample out-of-sample
-
#>
iid 5.417266e-05 8.974166e-05
-
#>
AR(1) 5.414645e-05 9.038057e-05
-
#>
ARMA(2,2) 5.265204e-05 8.924223e-05
-
#>
ARMA(1,1) + ARCH(1) 5.415836e-05 8.991902e-05
-
#>
ARCH(10) 5.417266e-05 8.976736e-05
-
#>
ARMA(1,1) + GARCH(1,1) 5.339071e-05 8.895682e-05
和一些图表:
-
-
-
main =
"不同模型的滚动预测误差", legend.loc = "topleft"
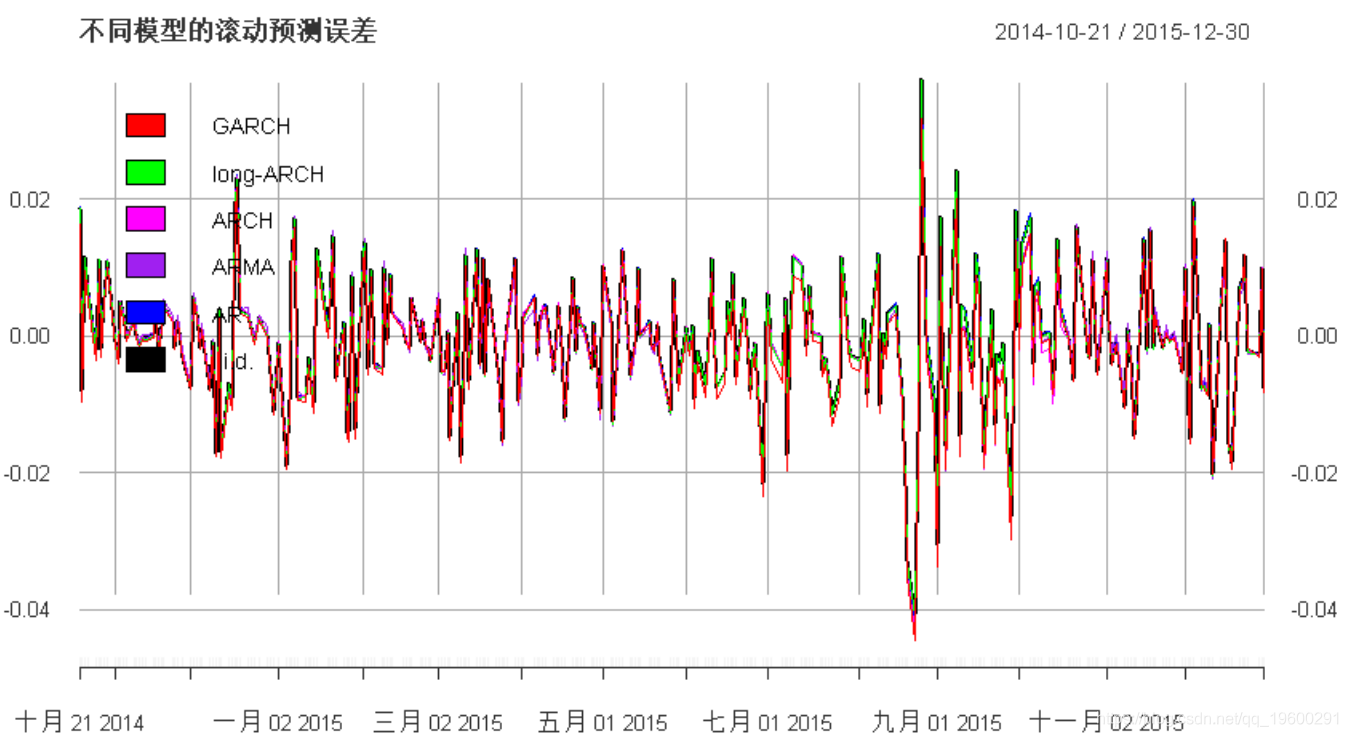
我们看到,现在所有模型都拟合了时间序列。此外,我们在模型之间没有发现任何显着差异。
我们最终可以比较静态误差和滚动误差:
-
barplot(
rbind(error_var[, "out-of-sample"], rolling_error_var[, "out-of-sample"])
-
col = c(
"darkblue", "darkgoldenrod"),
-
legend = c(
"静态预测", "滚动预测"),
-
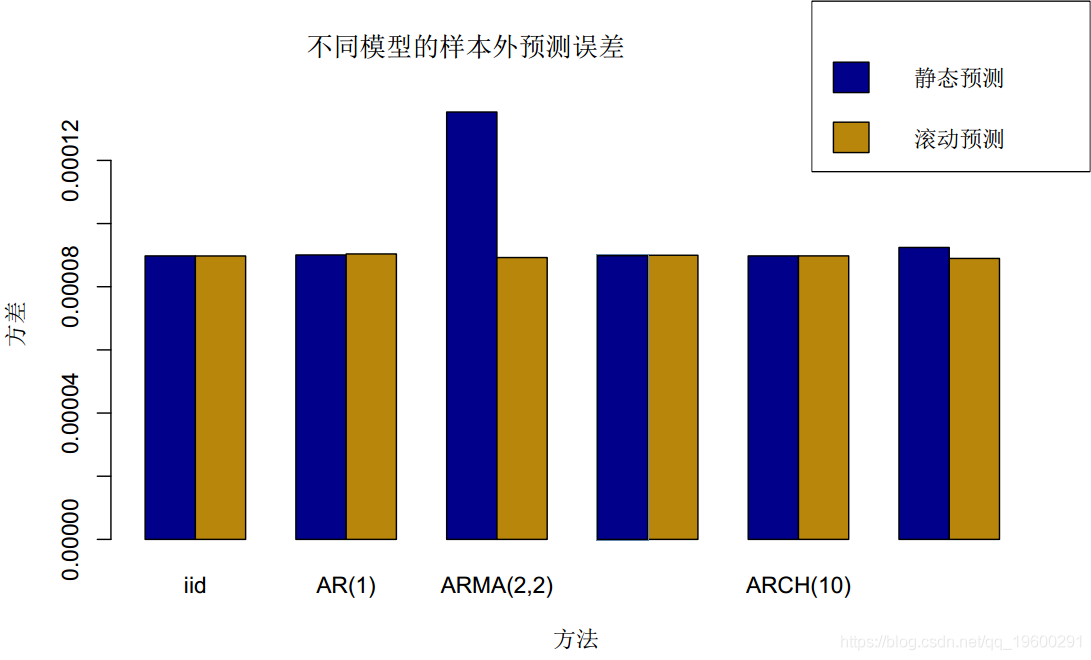
我们可以看到,滚动预测在某些情况下是必须的。因此,实际上,我们需要定期进行滚动预测改进。
方差模型
ARCH和GARCH模型
对数收益率残差wt的ARCH(m)模型为
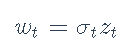
其中zt是具有零均值和恒定方差的白噪声序列,而条件方差σ2t建模为
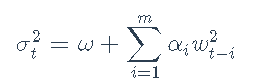
其中,m为模型阶数,ω> 0,αi≥0为参数。
GARCH(m,s)模型使用σ2t上的递归项扩展了ARCH模型:
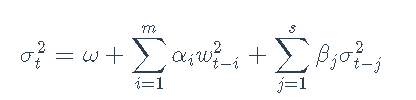
其中参数ω> 0,αi≥0,βj≥0需要满足∑mi =1αi+ ∑sj = 1βj≤1的稳定性。
rugarch生成数据
首先,我们需要定义模型:
-
-
-
-
-
#> *---------------------------------*
-
-
#> *---------------------------------*
-
-
#> Conditional Variance Dynamics
-
#> ------------------------------------
-
#> GARCH Model : sGARCH(1,1)
-
#> Variance Targeting : FALSE
-
-
#> Conditional Mean Dynamics
-
#> ------------------------------------
-
#> Mean Model : ARFIMA(1,0,0)
-
-
-
-
#> Conditional Distribution
-
#> ------------------------------------
-
-
-
#> Includes Shape : FALSE
-
#> Includes Lambda : FALSE
-
-
#> Level Fixed Include Estimate LB UB
-
-
#> ar1 -0.900 1 1 0 NA NA
-
-
#> arfima 0.000 0 0 0 NA NA
-
#> archm 0.000 0 0 0 NA NA
-
#> mxreg 0.000 0 0 0 NA NA
-
#> omega 0.001 1 1 0 NA NA
-
#> alpha1 0.300 1 1 0 NA NA
-
#> beta1 0.650 1 1 0 NA NA
-
#> gamma 0.000 0 0 0 NA NA
-
#> eta1 0.000 0 0 0 NA NA
-
#> eta2 0.000 0 0 0 NA NA
-
#> delta 0.000 0 0 0 NA NA
-
#> lambda 0.000 0 0 0 NA NA
-
#> vxreg 0.000 0 0 0 NA NA
-
#> skew 0.000 0 0 0 NA NA
-
#> shape 0.000 0 0 0 NA NA
-
#> ghlambda 0.000 0 0 0 NA NA
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
#> mu ar1 omega alpha1 beta1
-
#> 0.005 -0.900 0.001 0.300 0.650
然后,我们可以生成收益率时间序列:
-
-
-
hpath(garch_spec, n.sim =
T)
-
-
-
-
-
-
{ plot(synth_log_returns, main =
"GARCH模型的对数收益", lwd = 1.5)
-
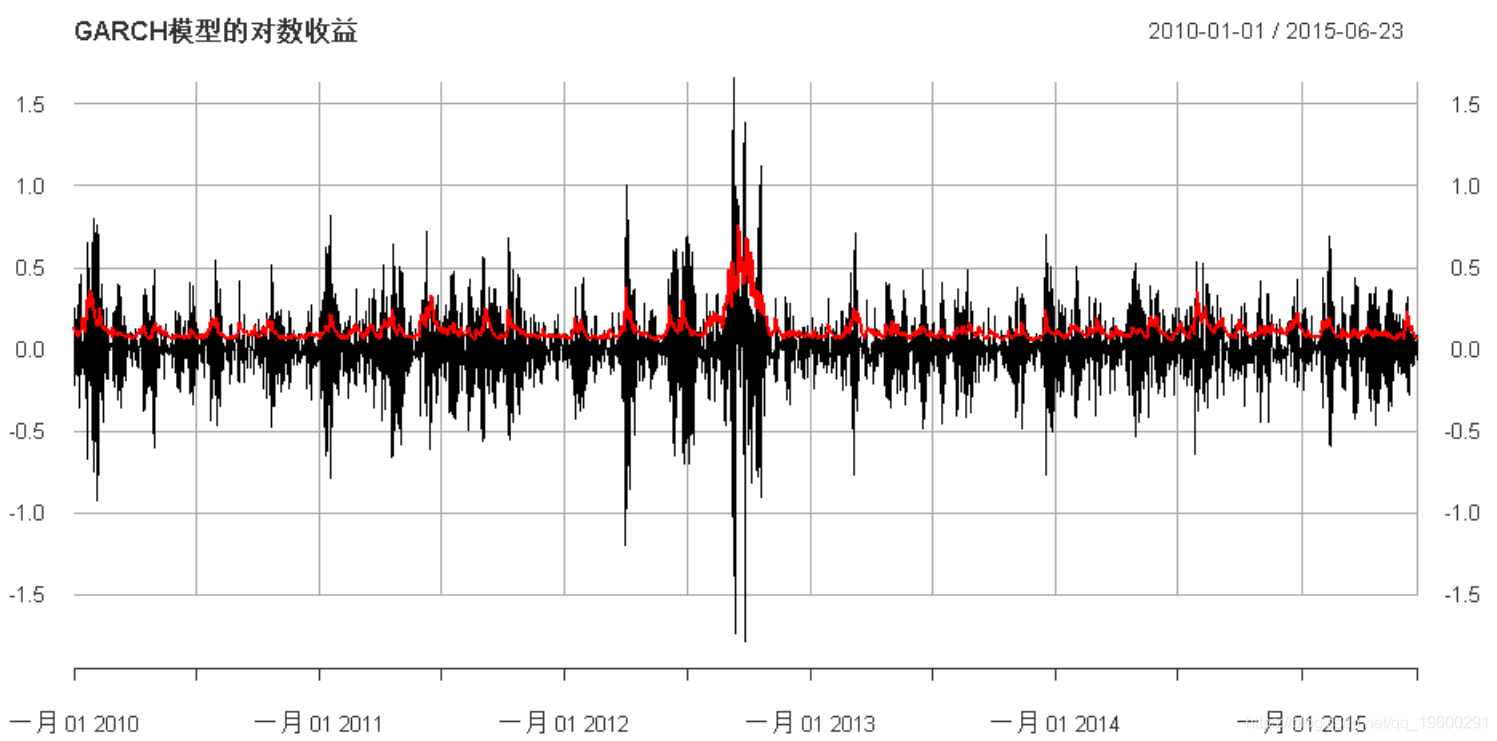
GARCH
现在,我们可以估计参数:
-
-
ugarchspec(mean.model = list(armaOrder = c(1,0)
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
我们还可以研究样本数量T对参数估计误差的影响:
-
-
-
-
-
error_coeffs_vs_T <- rbind(error_coeffs_vs_T, abs((coef(garch_fit) - true_params)/true_params))
-
estim_coeffs_vs_T <- rbind(estim_coeffs_vs_T, coef(garch_fit))
-
-
-
-
matplot(T_sweep, 100*error_coeffs_vs_T,
-
main = "估计GARCH系数的相对误差", xlab = "T", ylab = "误差 (%)",
-
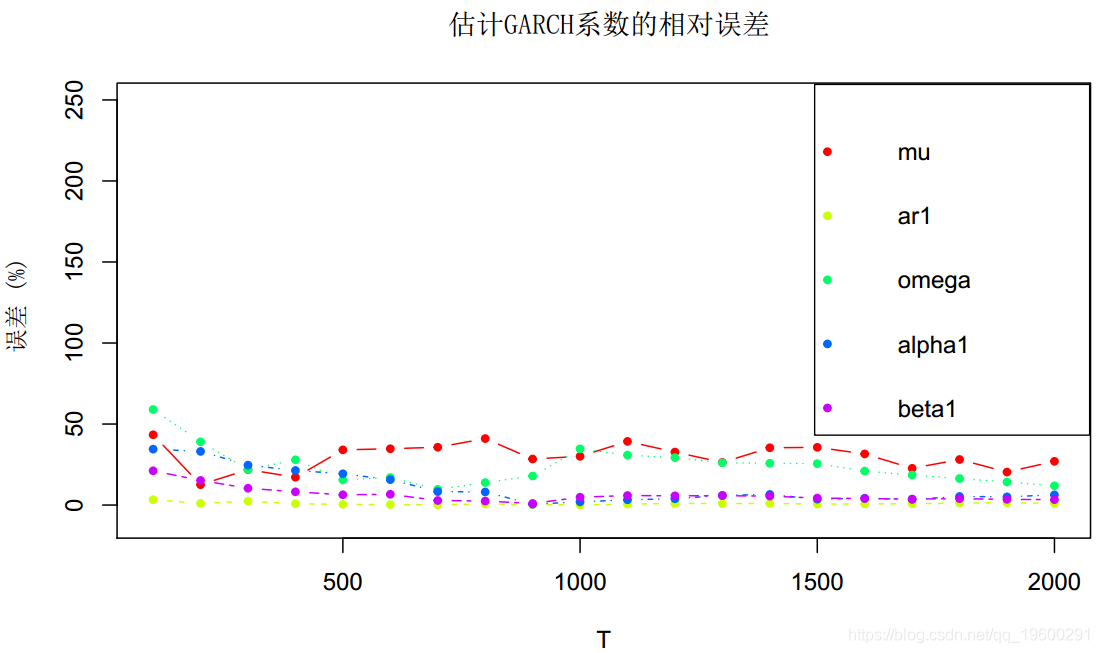
真实的ω几乎为零,因此误差非常不稳定。至于其他系数,就像在ARMA情况下一样,μ的估计确实很差(相对误差超过50%),而其他系数似乎在T = 800个样本后得到了很好的估计。
GARCH结果比较
作为健全性检查,我们现在将比较两个软件包 fGarch 和 rugarch的结果:
-
-
# 指定具有特定参数值的ARMA(0,0)-GARCH(1,1)作为数据生成过程
-
-
-
-
-
path(garch_fixed_spec, n.sim = 1000)@path$
-
-
-
-
rugarch_fit <- ugarchfit(spec = garch_spec, data = x)
-
-
-
garchFit(formula = ~ garch(1, 1), data = x, trace = FALSE)
-
-
-
-
#> 0.09749904 0.01395109 0.13510445 0.73938595
-
-
#> 0.09750394 0.01392648 0.13527024 0.73971658
-
-
-
-
#> [1] 0.3513549 0.3254788 0.3037747 0.2869034 0.2735266 0.2708994
-
-
#> [1] 0.3538569 0.3275037 0.3053974 0.2881853 0.2745264 0.2716555
确实,这两个软件包给出了相同的结果。
使用rugarch包进行GARCH预测
一旦估计出GARCH模型的参数,就可以使用该模型预测未来的值。例如,基于过去的信息对条件方差的单步预测为
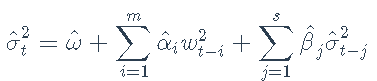
给定ω^ /(1-∑mi =1α^ i-∑sj =1β^ j)。软件包 rugarch 使对样本外数据的预测变得简单:
-
-
-
-
-
-
-
-
-
-
-
garch_fore
@forecast$sigmaFor[1, ]
-
-
-
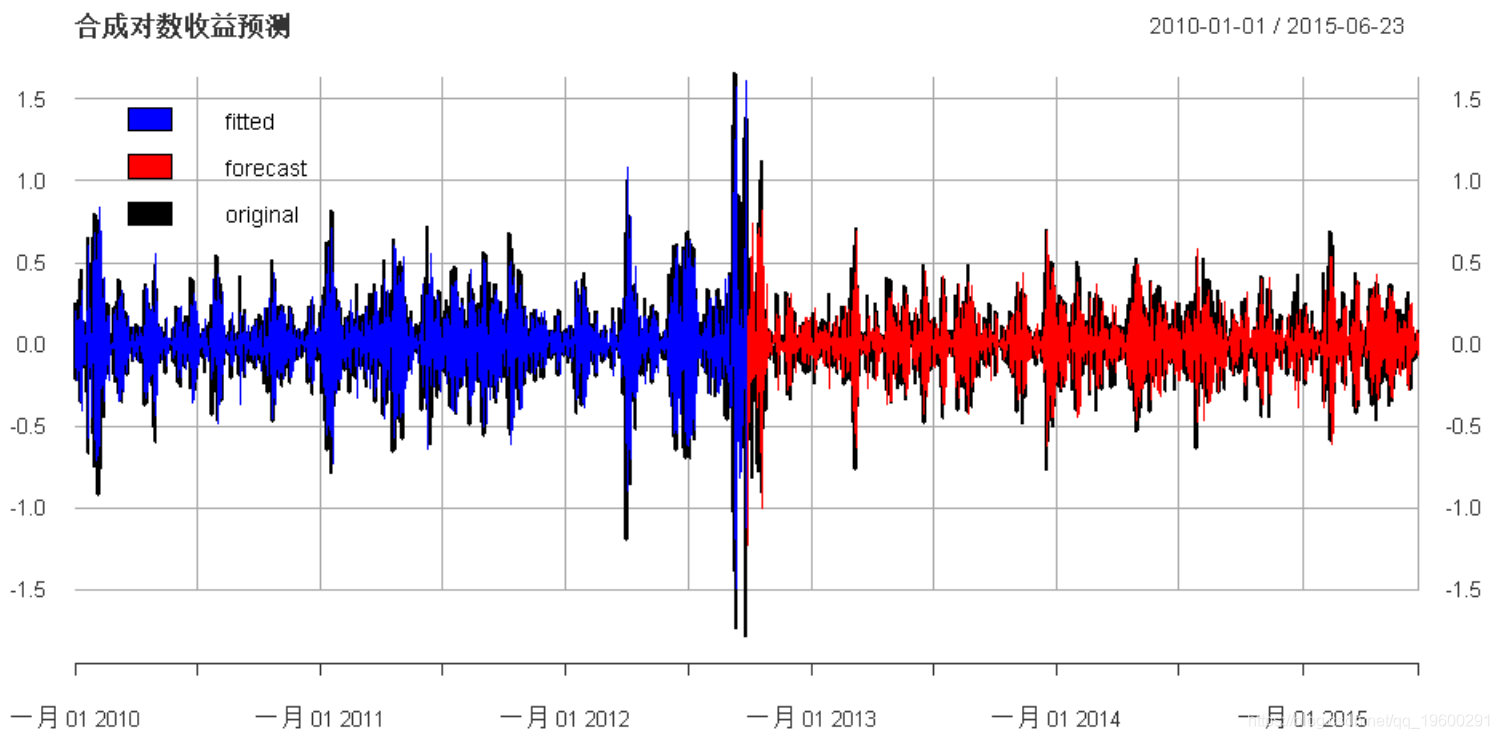
plot(cbind(
"fitted" = fitted(garch_fit),
-
main =
"合成对数收益预测", legend.loc = "topleft")
-
-
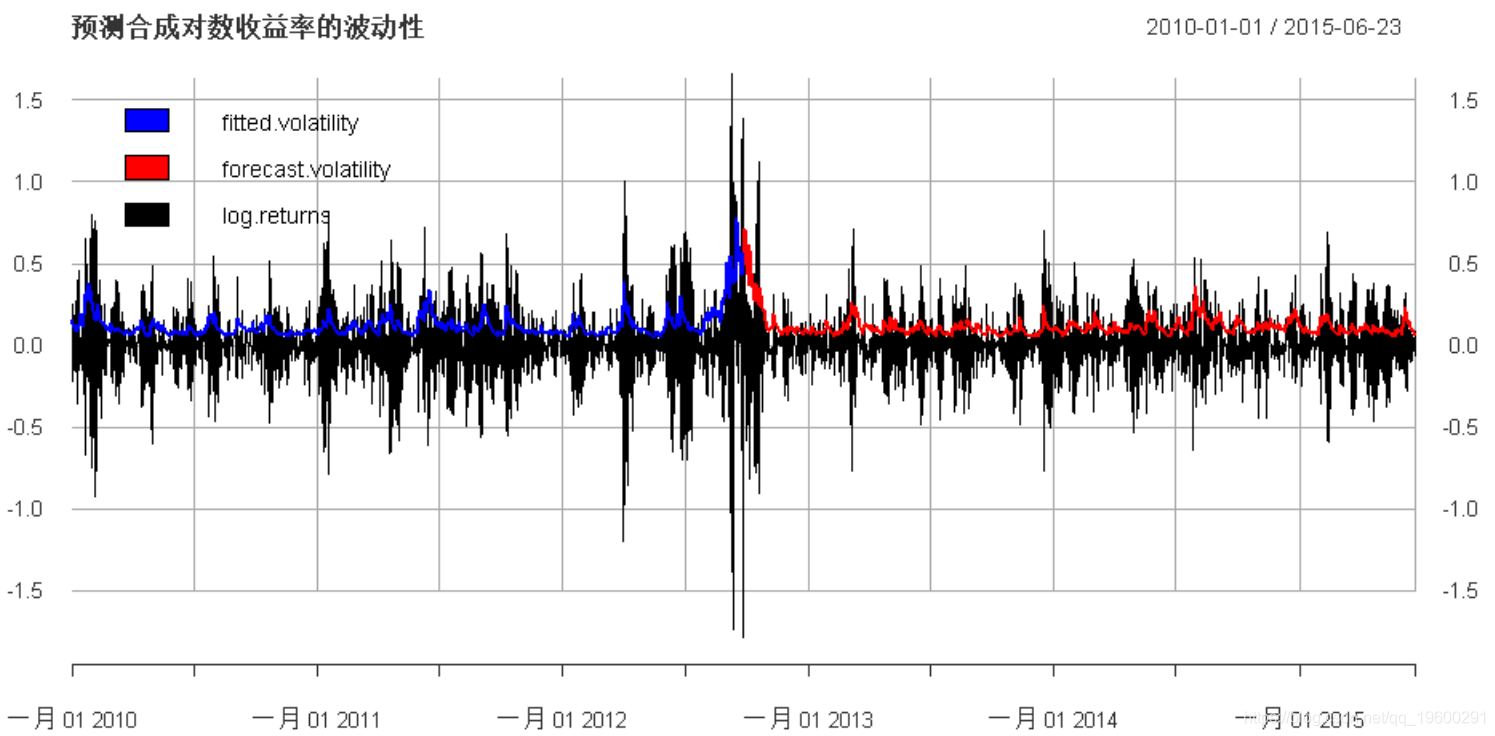
plot(cbind(
"fitted volatility" = sigma(garch_fit),
-
main =
"预测合成对数收益率的波动性", legend.loc = "topleft")
不同方法
让我们首先加载S&P500:
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
addEventLines(xts("训练", in
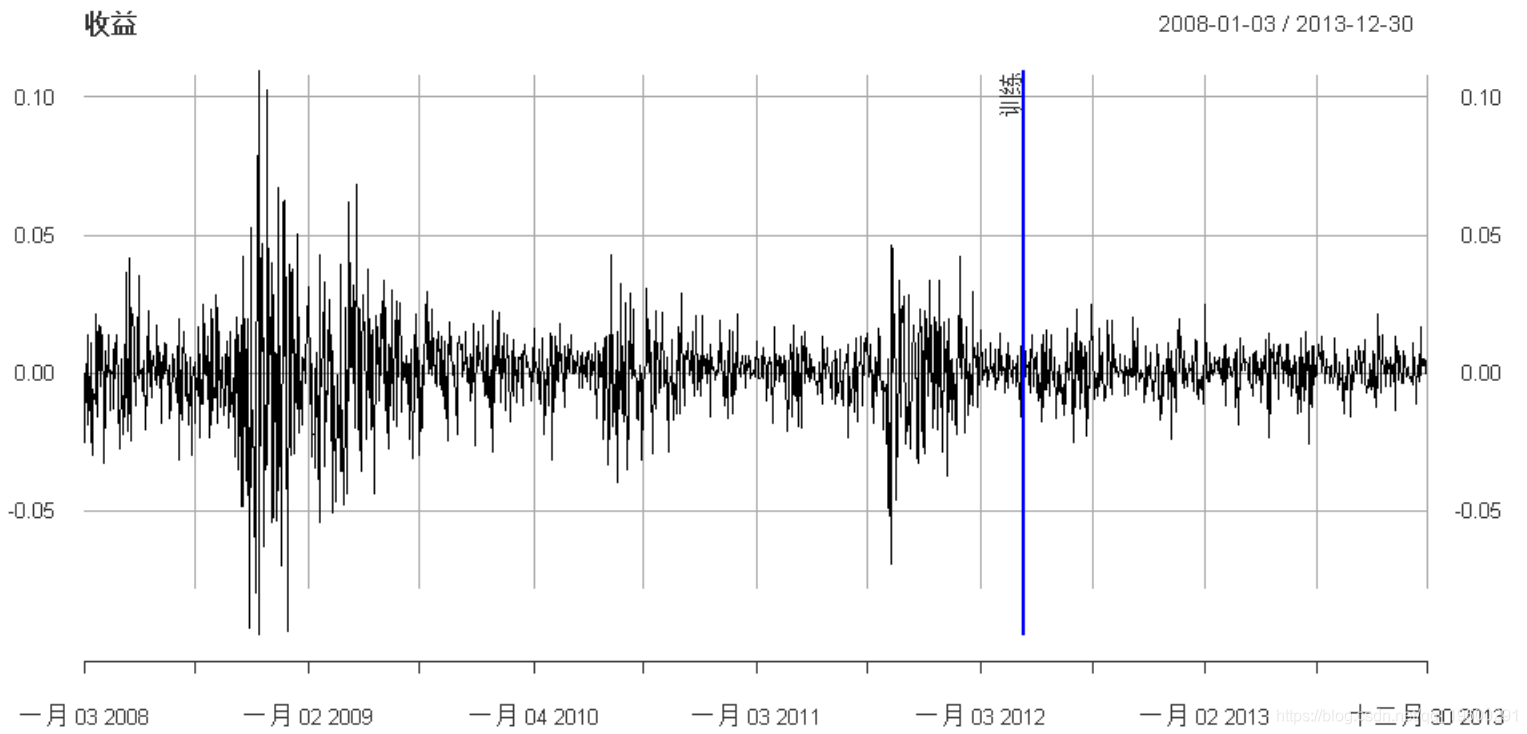
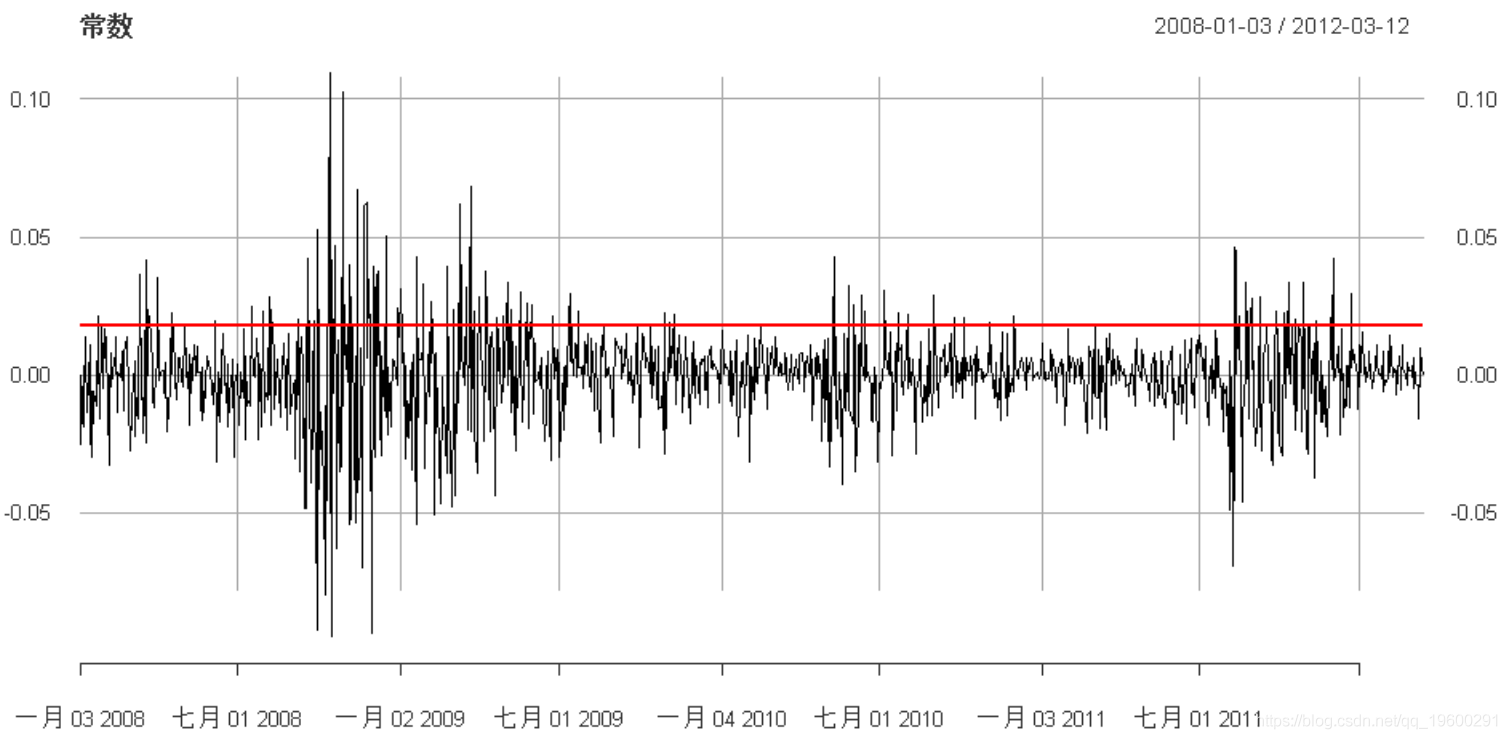
常数
让我们从常数开始:
-
plot(
cbind(sqrt(var_constant), x_trn)
-
移动平均值
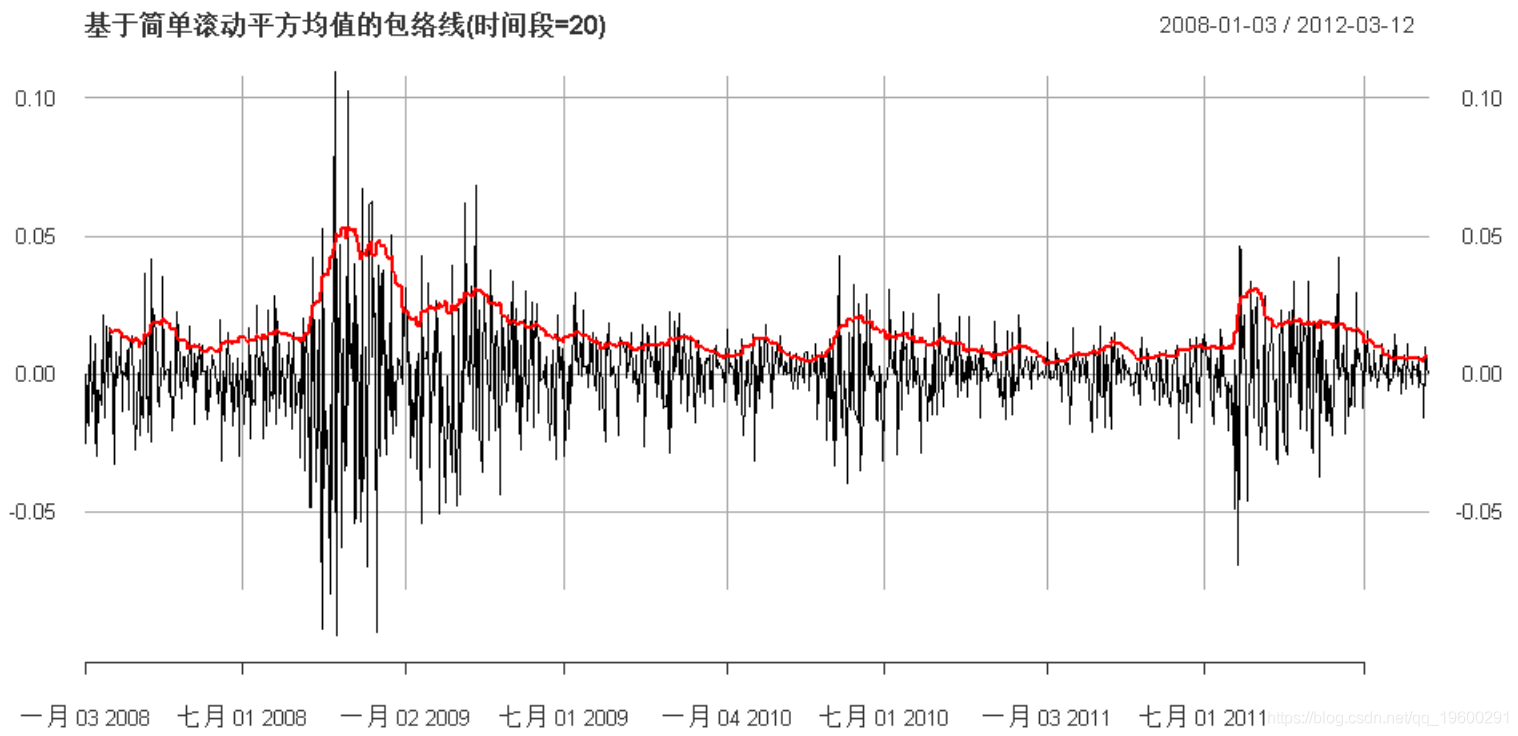
现在,让我们使用平方收益的移动平均值:
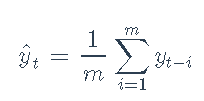
-
-
plot(
cbind(sqrt(var_t), x_trn),
-
main =
"基于简单滚动平方均值的包络线(时间段=20)
-
-
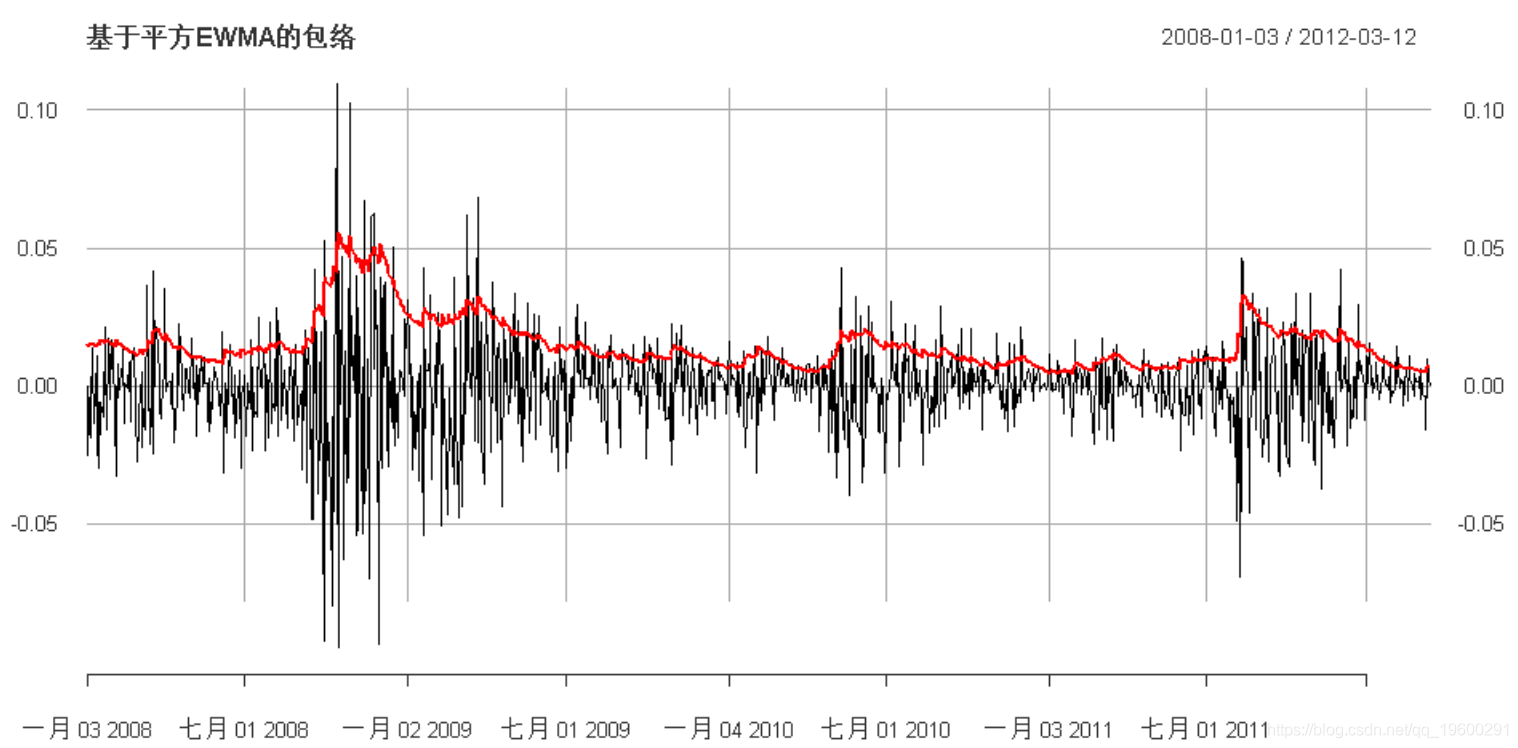
EWMA
指数加权移动平均线(EWMA):
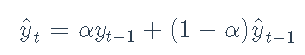
请注意,这也可以建模为ETS(A,N,N)状态空间模型:
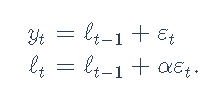
-
-
plot(
cbind(std_t, x_trn),
-
-
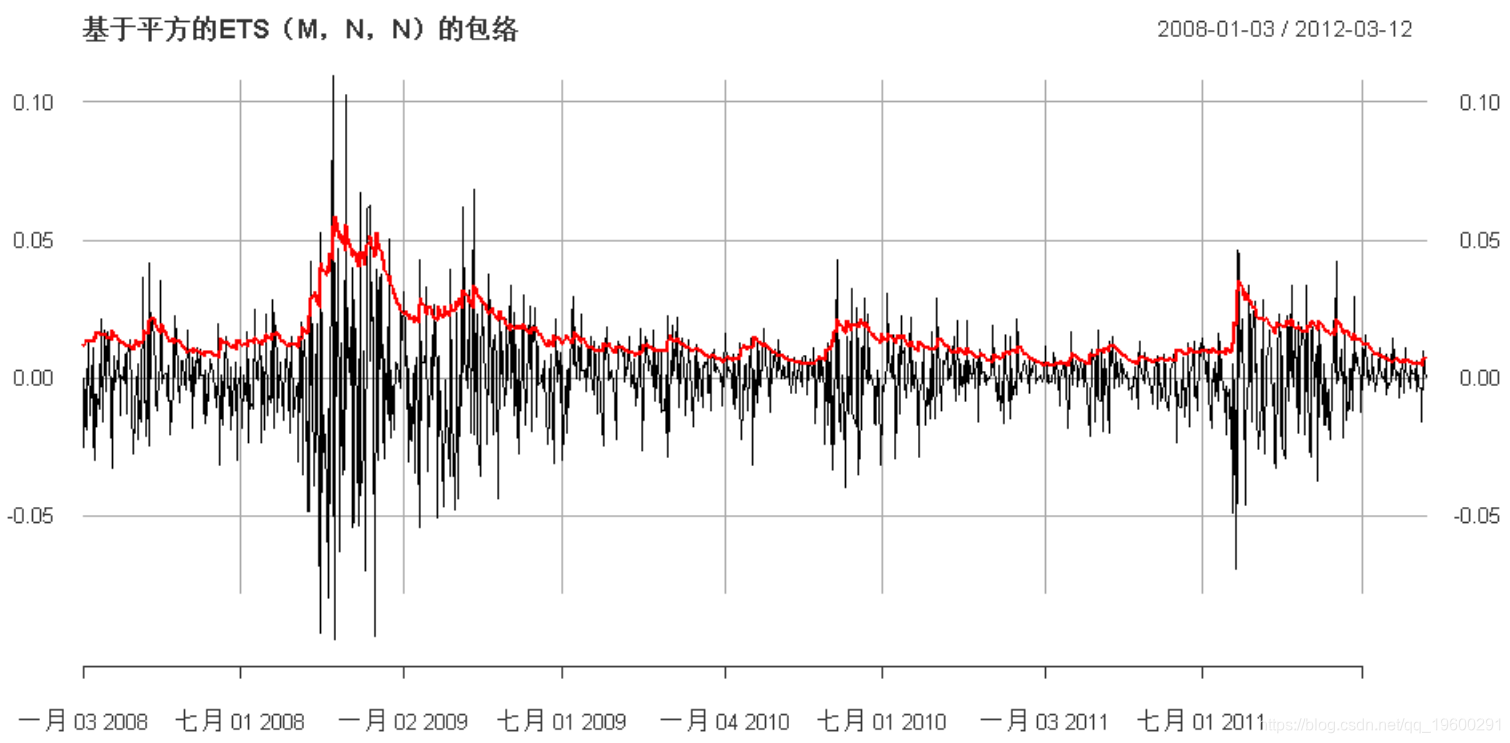
乘法ETS
我们还可以尝试ETS模型的不同变体。例如,具有状态空间模型的乘性噪声版本ETS(M,N,N):
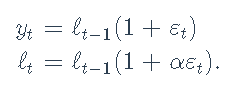
-
-
plot(
cbind(std_t, x_trn), col = c("red", "black")
-
main =
"基于平方的ETS(M,N,N)的包络"
-
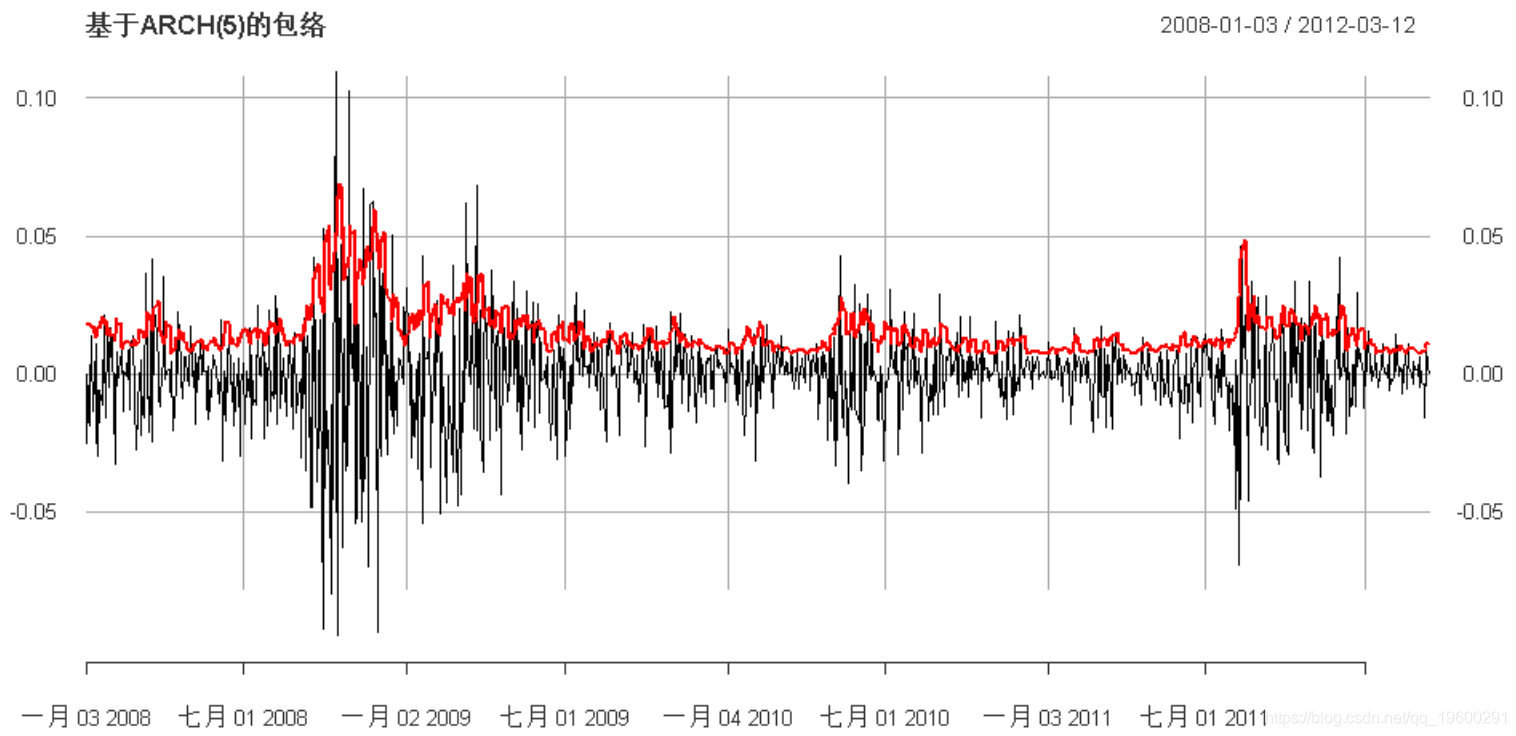
ARCH
现在,我们可以使用更复杂的ARCH建模:
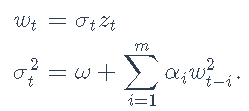
-
-
plot(
cbind(std_t, x_trn), col = c("red", "black")
-
-
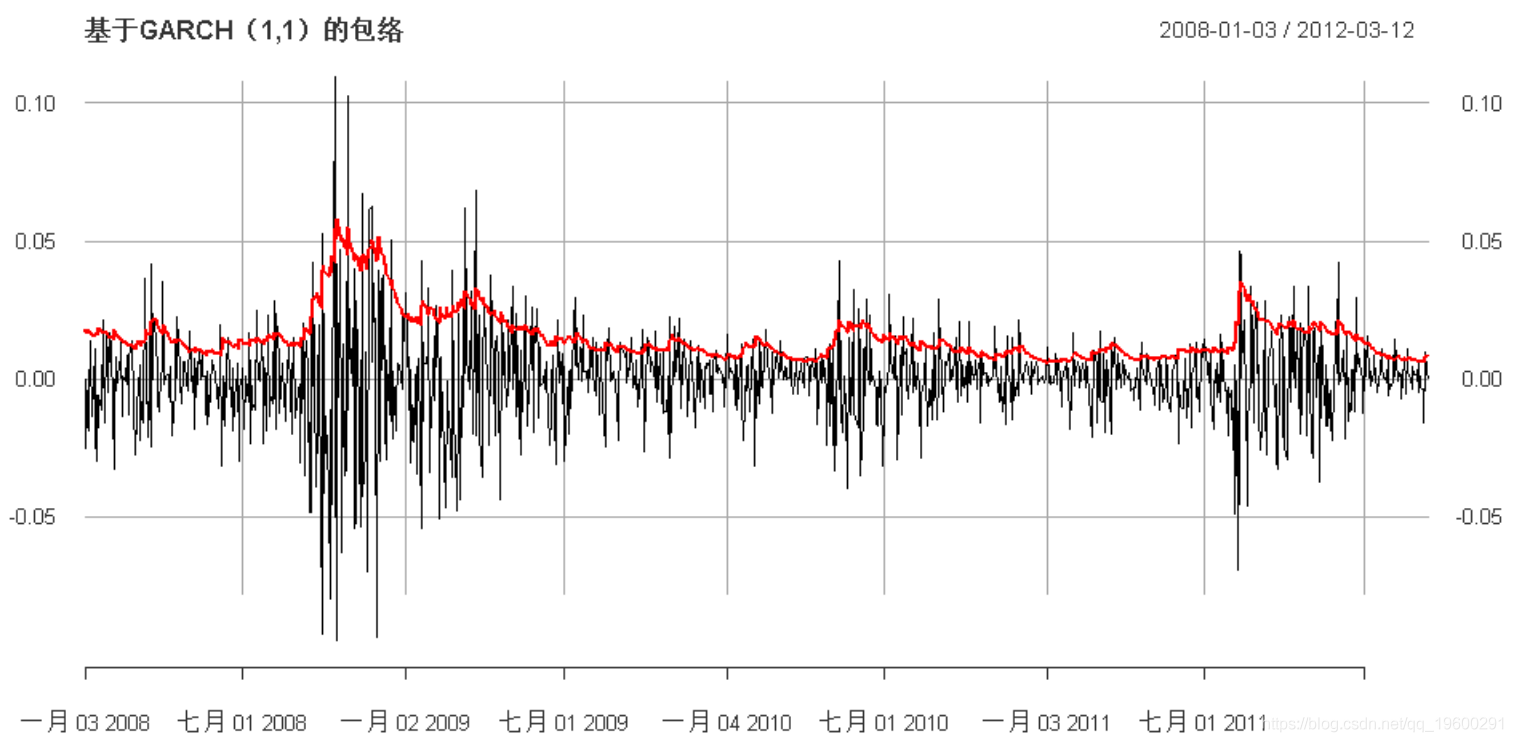
GARCH
我们可以将模型提升到GARCH:
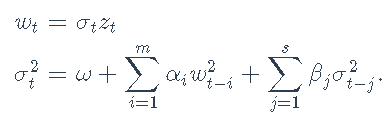
-
-
plot(
cbind(std_t, x_trn), col = c("red", "black")
-
main =
"基于GARCH(1,1)的包络")
-
SV随机波动率
最后,我们可以使用随机波动率建模:
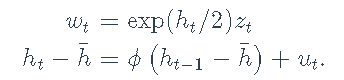
或者,等效地,
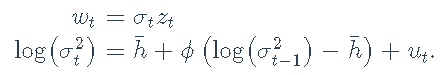
-
-
plot(
cbind(std_t, x_trn), col = c("red", "black"),
-
-
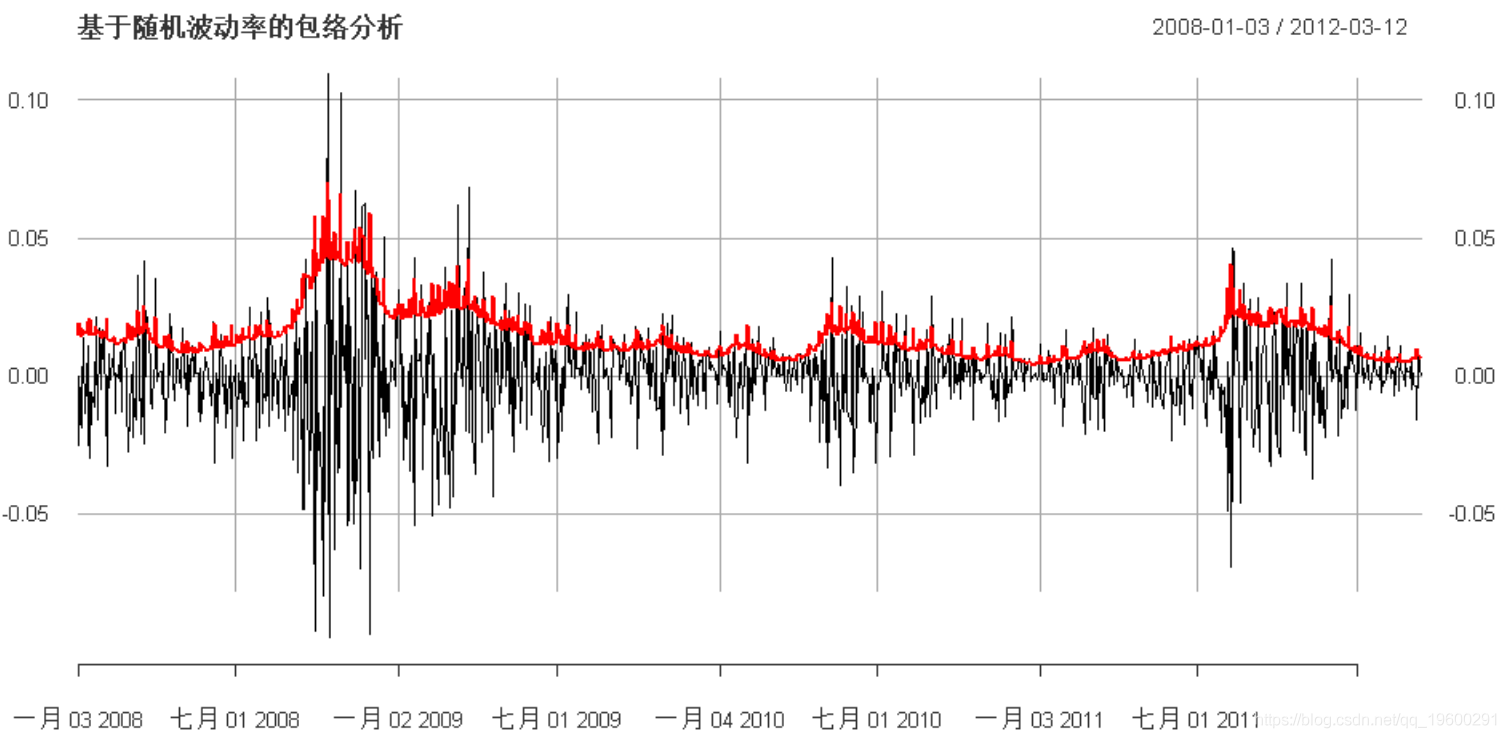
比较
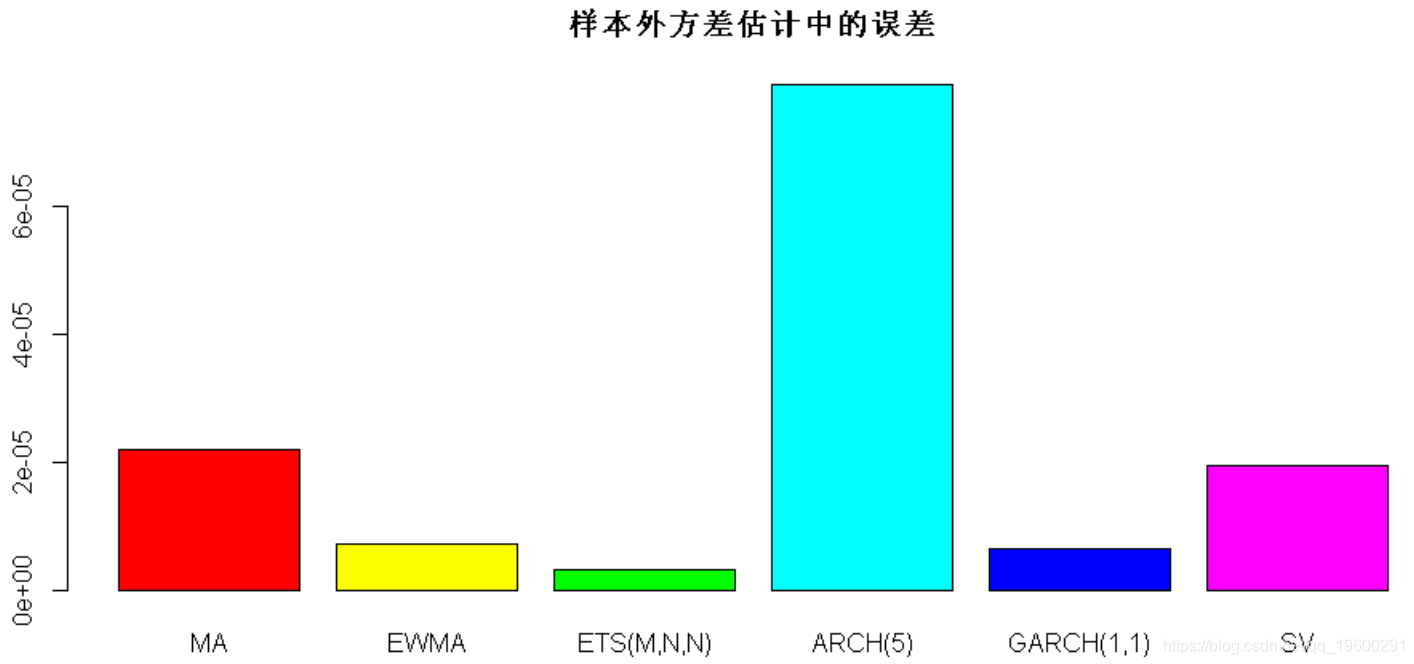
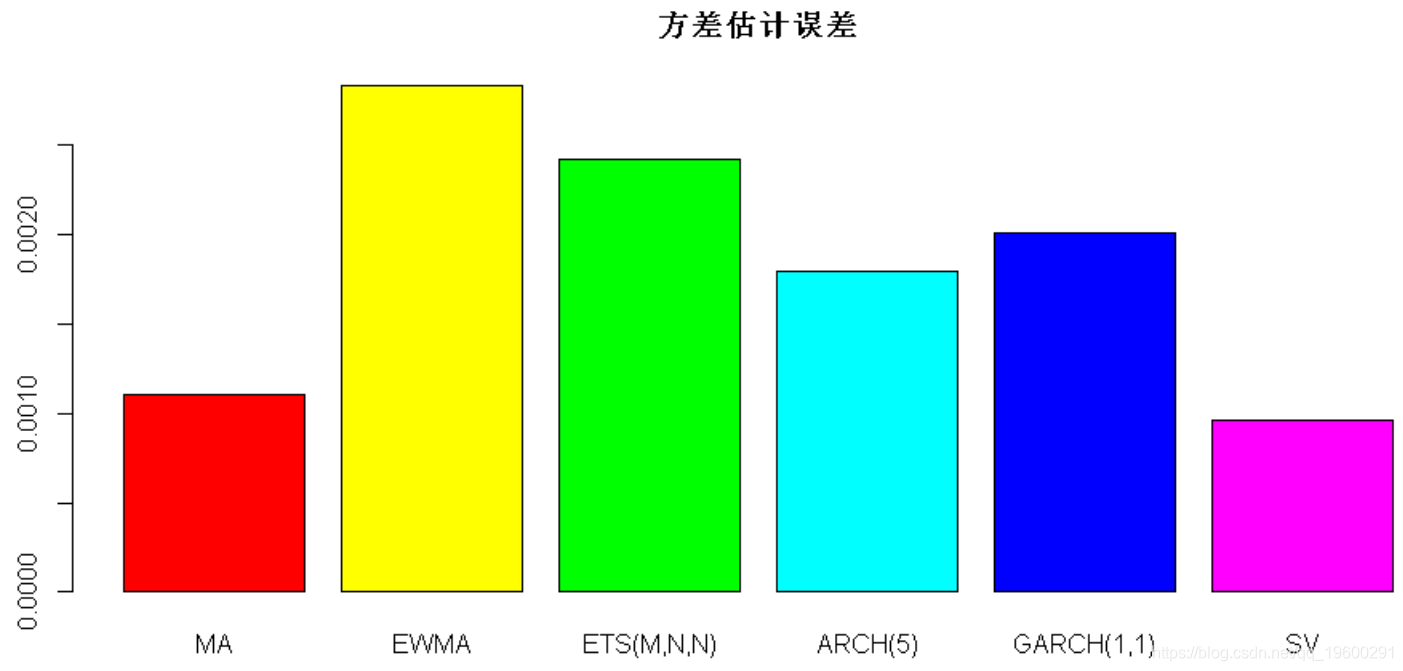
现在,我们可以比较每种方法在样本外期间的方差估计中的误差:
-
-
#> MA EWMA ETS(
M,N,N) ARCH(5) GARCH(1,1) SV
-
#>
2.204965e-05 7.226188e-06 3.284057e-06 7.879039e-05 6.496545e-06 6.705059e-06
-
barplot(
error_all, main = "样本外方差估计中的误差"
滚动窗口比较
六种方法的滚动窗口比较:MA,EWMA,ETS(MNN),ARCH(5),GARCH(1,1)和SV。
-
-
-
-
-
for (i in seq(lookback, T-len_tst, by = len_tst)) {
-
-
-
var_t <- roll_meanr(x_trn^
2, n = 20, fill = NA)
-
var_fore <- var(x_trn/
sqrt(var_t), na.rm = TRUE) * tail(var_t, 1)
-
error_ma <- c(error_ma,
abs(var_fore - var_tst))
-
-
-
-
error_ewma <- c(error_ewma,
abs(var_fore - var_tst))
-
-
-
-
error_ets_mnn <- c(error_ets_mnn,
abs(var_fore - var_tst))
-
-
-
-
error_arch <- c(error_arch,
abs(var_fore - var_tst))
-
-
-
-
error_garch <- c(error_garch,
abs(var_fore - var_tst))
-
-
-
-
error_sv <- c(error_sv,
abs(var_fore - var_tst))
-
-
-
-
barplot(error_all, main =
"方差估计误差",
多元GARCH模型
出于说明目的,我们将仅考虑恒定条件相关(CCC)和动态条件相关(DCC)模型,因为它们是最受欢迎的模型。对数收益率残差wt建模为
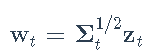
其中zt是具有零均值和恒定协方差矩阵II的iid白噪声序列。条件协方差矩阵Σt建模为
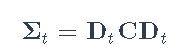
其中Dt = Diag(σ1,t,...,σN,t)是标准化噪声向量C,协方差矩阵ηt=C-1wt(即,它包含等于1的对角线元素)。
基本上,使用此模型,对角矩阵Dt包含一组单变量GARCH模型,然后矩阵C包含序列之间的一些相关性。该模型的主要缺点是矩阵C是恒定的。为了克服这个问题,DCC被提议为
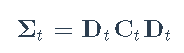
其中Ct包含等于1的对角元素。要强制等于1的对角元素,Engle将其建模为
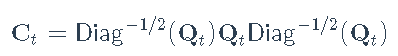
Qt具有任意对角线元素并遵循模型
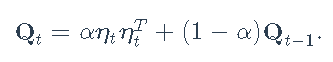
我们将生成数据,估计参数和预测。
从加载多元ETF数据开始:
- SPDR S&P 500 ETF
- 20年以上国债ETF
- IEF:7-10年期国债ETF
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
main =
"三个ETF的对数价格", legend.loc = "topleft")

首先,我们定义模型:
-
-
-
-
-
-
spec( multispec(replicate(spec, n = 3))
-
接下来,我们拟合模型:
-
-
-
-
#> *---------------------------------*
-
-
#> *---------------------------------*
-
-
-
-
-
#> [VAR GARCH DCC UncQ] : [30+9+2+3]
-
-
-
#> Log-Likelihood : 12198.4
-
#> Av.Log-Likelihood : 12.11
-
-
-
#> -----------------------------------
-
#> Estimate Std. Error t value Pr(>|t|)
-
#> [SPY].omega 0.000004 0.000000 11.71585 0.000000
-
#> [SPY].alpha1 0.050124 0.005307 9.44472 0.000000
-
#> [SPY].beta1 0.870051 0.011160 77.96041 0.000000
-
#> [TLT].omega 0.000001 0.000001 0.93156 0.351563
-
#> [TLT].alpha1 0.019716 0.010126 1.94707 0.051527
-
#> [TLT].beta1 0.963760 0.006434 149.79210 0.000000
-
#> [IEF].omega 0.000000 0.000001 0.46913 0.638979
-
#> [IEF].alpha1 0.031741 0.023152 1.37097 0.170385
-
#> [IEF].beta1 0.937777 0.016498 56.84336 0.000000
-
#> [Joint]dcca1 0.033573 0.014918 2.25044 0.024421
-
#> [Joint]dccb1 0.859787 0.079589 10.80278 0.000000
-
-
-
-
-
-
-
-
-
-
-
#> Elapsed time : 0.8804049
我们可以绘制时变相关性:
-
-
-
-
-
-
-
-
main =
"时变相关", legend.loc = "left")
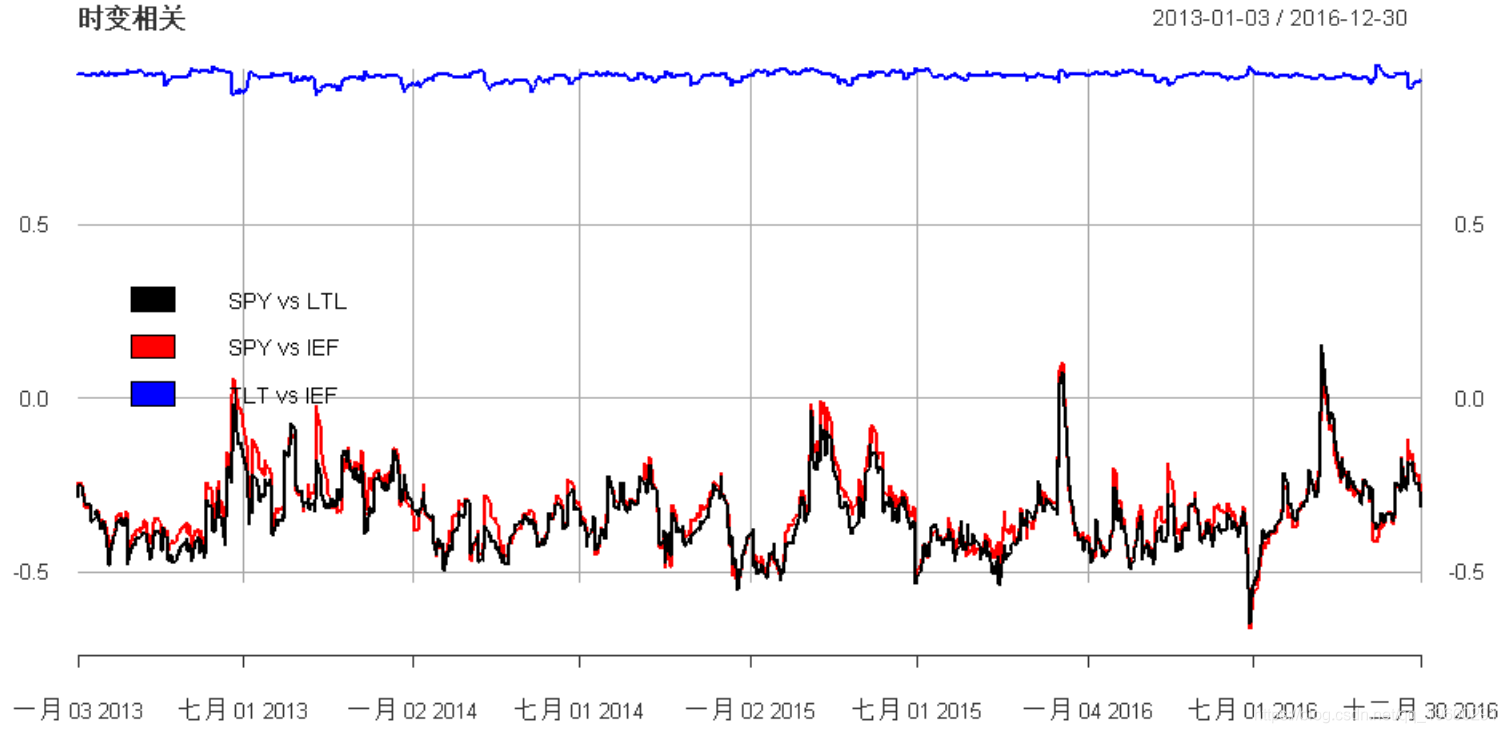
我们看到两个收益ETF之间的相关性非常高且相当稳定。与SPY的相关性较小,在小于0的区间波动。

最受欢迎的见解
1.HAR-RV-J与递归神经网络(RNN)混合模型预测和交易大型股票指数的高频波动率
2.R语言中基于混合数据抽样(MIDAS)回归的HAR-RV模型预测GDP增长
3.波动率的实现:ARCH模型与HAR-RV模型
4.R语言ARMA-EGARCH模型、集成预测算法对SPX实际波动率进行预测
5.GARCH(1,1),MA以及历史模拟法的VaR比较
6.R语言多元COPULA GARCH 模型时间序列预测
7.R语言基于ARMA-GARCH过程的VAR拟合和预测
8.matlab预测ARMA-GARCH 条件均值和方差模型
9.R语言对S&P500股票指数进行ARIMA + GARCH交易策略
▍关注我们
【大数据部落】第三方数据服务提供商,提供全面的统计分析与数据挖掘咨询服务,为客户定制个性化的数据解决方案与行业报告等。
▍咨询链接:http://y0.cn/teradat
▍联系邮箱:3025393450@qq.com





