

拓端数据tecdat|R语言使用多元AR-GARCH模型衡量市场风险
原文链接:http://tecdat.cn/?p=19118
本文分析将用于制定管理客户和供应商关系的策略准则。假设:
- 贵公司拥有用于生产和分销聚戊二酸的设施,聚戊二酸是一种用于多个行业的化合物。
- 制造和分销过程的投入包括各种石油产品和天然气。价格波动可能非常不稳定。
- 营运资金管理一直是一个挑战,最近汇率的走势严重影响了资金。
- 您的CFO使用期货和场外交易(OTC)工具对冲价格风险。
董事会感到关切的是,公司已连续第五个季度未能实现盈利预期。股东不高兴。罪魁祸首似乎是商品销售成本的波动。
示例
- 您应该问有哪些能源定价模式的关键业务问题?
- 您可以使用哪种方法来管理波动率?
这里有一些想法。关键业务问题可能是:
- 哪些输入价格和汇率比其他输入价格和汇率更不稳定?何时?
- 价格走势相关吗?
- 在市场压力时期,它们的走势会有多动荡?
- 是否有我们可以部署的套期工具或可以用来减轻定价风险?
管理波动
- 建立输入监视系统,以了解哪些输入会影响运行制造和分销流程的哪些成本。
- 监控价格走势和特征,并按流程衡量对关键营业收入构成部分的影响的严重性。
- 内置价格无法承受预警指标。
在本文中,我们将
- 使用波动率聚类
- 拟合AR-GARCH模型
- 从AR-GARCH模型模拟波动率
- 衡量风险
ARCH模型
我们已经研究了波动性聚类。ARCH模型是对此进行建模的一种方法。
这些模型对于金融时间序列特别有用,因为金融时间序列显示出较大的收益率变动时期以及相对平稳的价格变化的间歇时期。
可以从z(t)标准正态变量和初始标准波动率开始指定AR + ARCH模型σ(t)2 = z(t)2。然后,我们用方差ε(t)=(sigma2)1 / 2z(t)ε的平方来调节这些变量。然后我们首先为每个日期计算t = 1 ... n,
![]()
使用该条件误差项,我们计算自回归
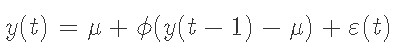
现在我们准备计算新的方差项。
-
n <- 10500
-
z <- rnorm(n) ## 样本标准正态分布变量
-
-
sig2 <- z^2 ##创建波动率序列
-
-
-
omega <- 1 ## 方差
-
-
-
-
mu <- 0.1 ## 平均收益率
-
-
-
omega/(1-alpha)
-
sqrt(omega/(1-alpha))
## [1] 2.222222## [1] 1.490712-
for (t in 2:n) ## 滞后于第二个日期开始
-
-
-
{
-
y[t] <- mu + phi*(y[t-1 -mu) + e[t] ## 收益率
-
-
-
sig2[t+1] <- omega + alpha * e[t ^2 ## 生成新的sigma ^ 2。
-
结果没有指导意义。
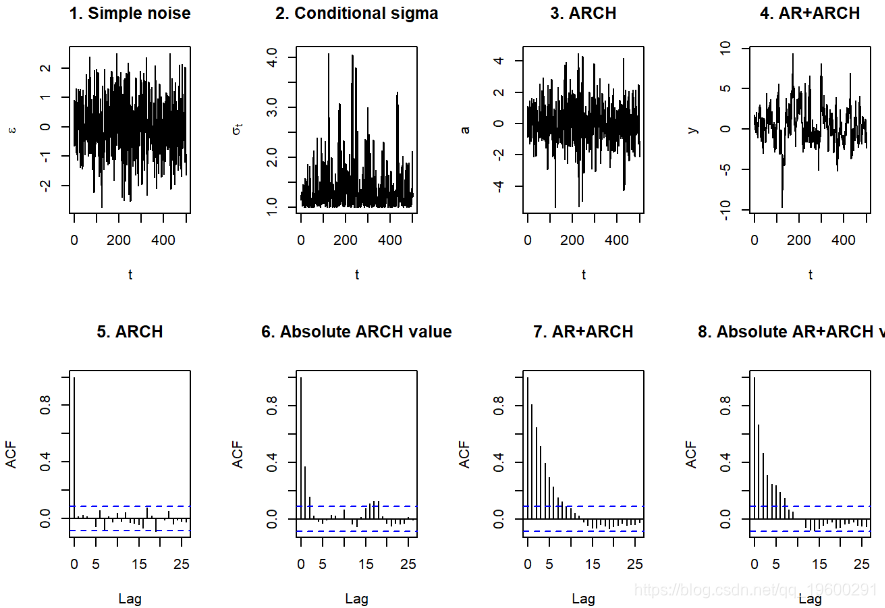
我们可以看到
- 条件标准偏差中较大的孤立峰
- 在ARCH图中也显示
估计
我们有多种方法来估计AR-ARCH过程的参数。首先,让我们加载一些数据。
-
-
-
-
-
data.1 <- na.omit(merge(EUR_USD, GBP_USD,
-
OIL_Brent))
-
P <- data.1
-
R <- na.omit(diff(log(P)) * 100)
然后,我们绘制数据自相关。
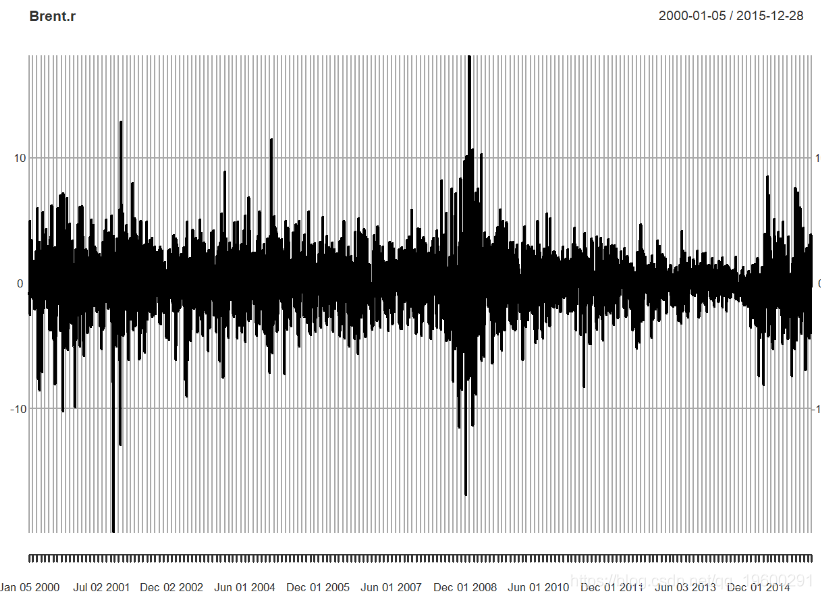
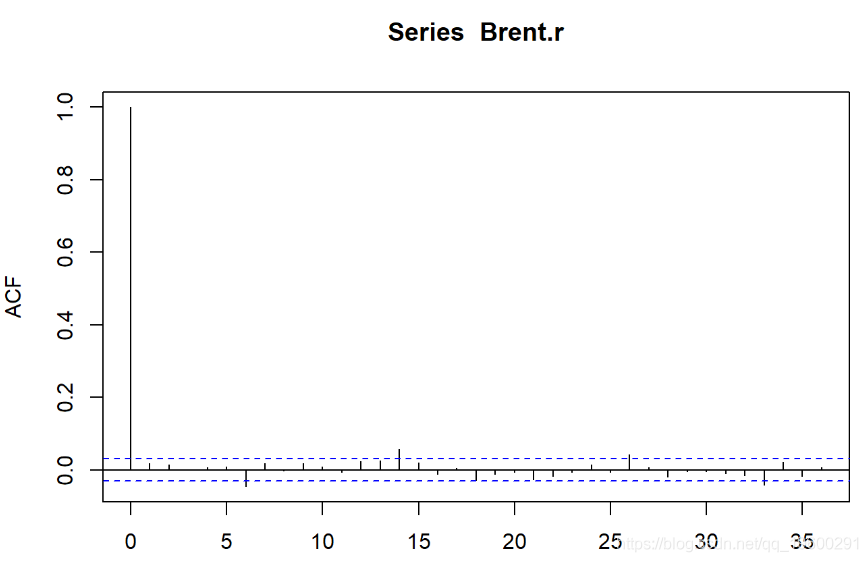
纯随机性检验,p值小于5%,序列为非白噪声
拟合
我们的第一项任务是ARMA-GARCH模型。
- 指定普通
sGarch模型。 garchOrder = c(1,1)表示我们使用残差平方和方差的一期滞后:![]()
- 使用
armaOrder = c(1,0)指定长期平均收益模型![]()
mean如上述方程式中包括 。- 按照
norm正态分布 。我们还将使用赤池信息准则(AIC)将拟合与学生t分布进行比较 。 - 使用将数据拟合到模型
ugarchfit。
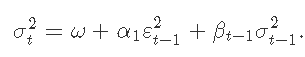
-
ugarchspec(variance.model = list(model = "sGARCH",
-
garchOrder = c(1, 1)), mean.model = list(armaOrder = c(1,
-
0), include.mean = TRUE), distribution.model = "norm")
让我们看一下该模型中的条件分位数,也称为VaR,设置为99%。
-
## 首先是条件分位数
-
-
-
plot(fit, which = 2)
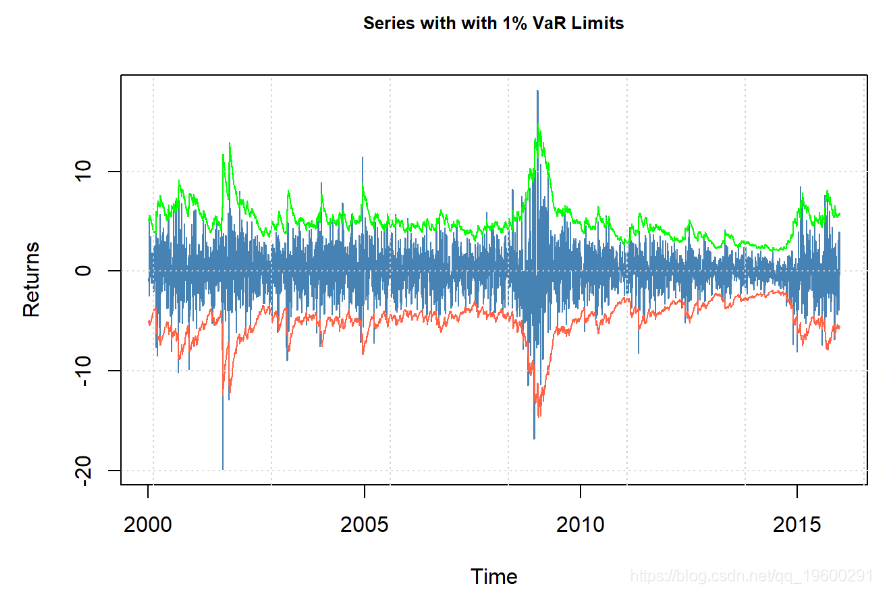
现在,让我们生成一个绘图面板。
-
-
-
plot(fit , which = 6)
-
-
-
-
## 标准化残差的acf
-
-
-
## 平方标准残差的acf
例子
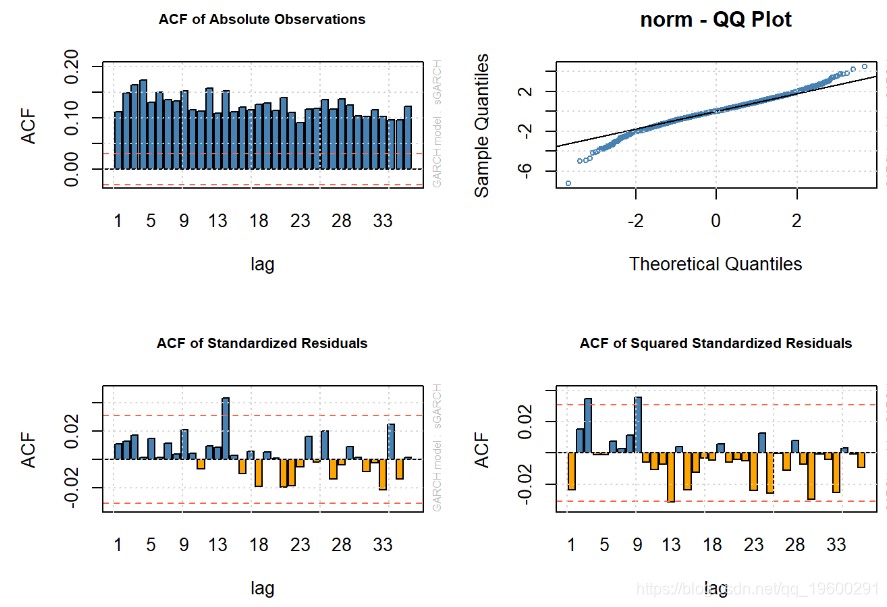
让我们重做GARCH估计,现在使用Student t分布。
-
## 用学生t分布拟合AR(1)-GARCH(1,1)模型
-
-
-
AR.GARCH.spec <- ugarchspec(variance.model = list(model = "sGARCH",
-
garchOrder = c(1, 1)), mean.model = list(armaOrder = c(1,
-
0), include.mean = TRUE), distribution.model = "std")
-
结果
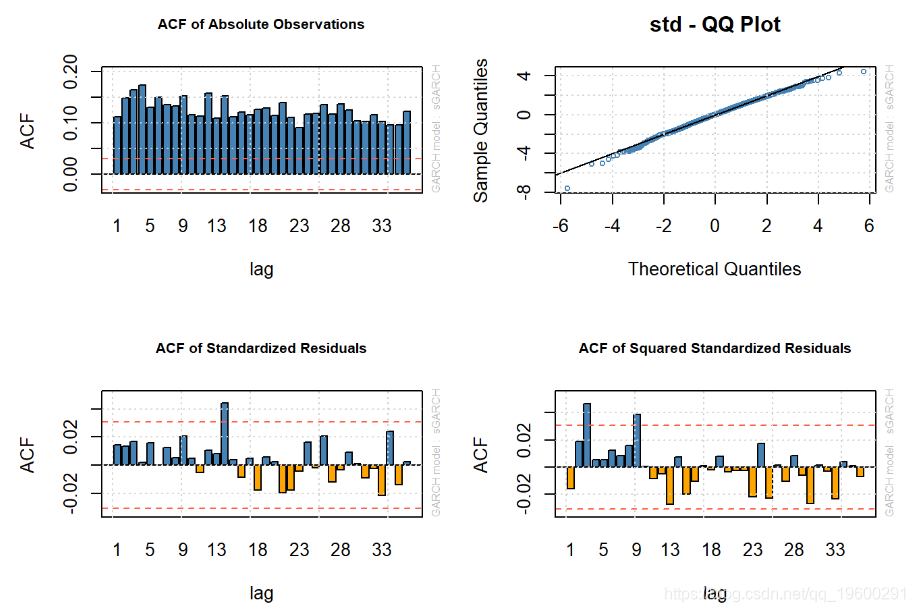
- 绝对观测值的ACF表明存在很大的波动性聚类。
- AR-ARCH估计具有有界的标准化残差(残差/标准误差),从而大大降低了这些误差。
- 看来t分布AR-GARCH解释了原油波动的大部分趋势。
用哪个模型?使用Akaike信息准则(AIC)测量模型中的信息。
使用正态分布模型的AIC = 4.2471。使用学生t分布模型的AIC = 4.2062。学生t分布模型更好。
这是我们可以从拟合模型中得出的一些常见结果:
-
## mu ar1 omega alpha1 beta1 shape
-
## 0.04018002 0.01727725 0.01087721 0.03816097 0.96074399 7.03778415
系数包括:
mu是原油的长期平均收益率。ar1是一天后收益对今天收益的影响。omega是长期方差。alpha1滞后平方方差对今天的收益的影响。beta1滞后平方残差对今天收益率的影响。shape是学生t分布的自由度。
让我们来绘制随时间变化的波动性。
-
## mu ar1 omega alpha1 beta1 shape
-
## 0.04018002 0.01727725 0.01087721 0.03816097 0.96074399 7.03778415
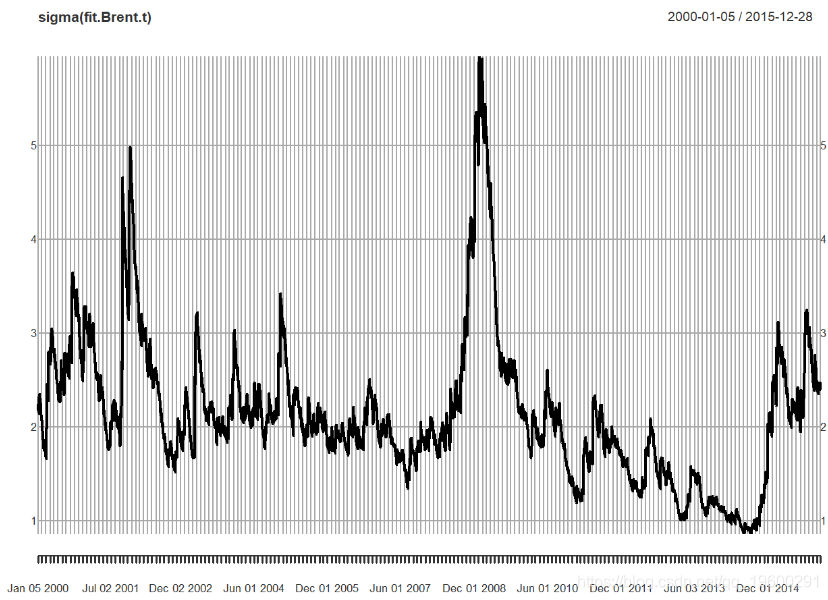
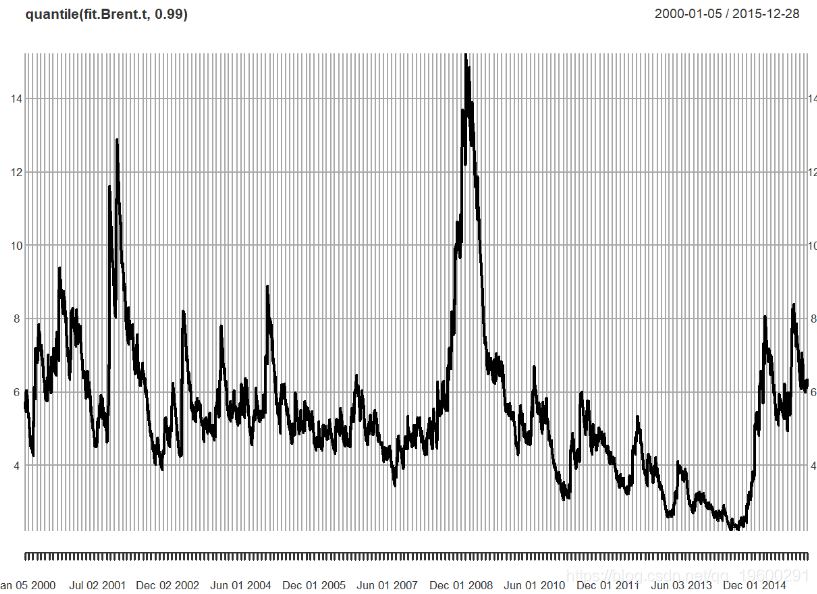
接下来,我们绘制并检验残差:
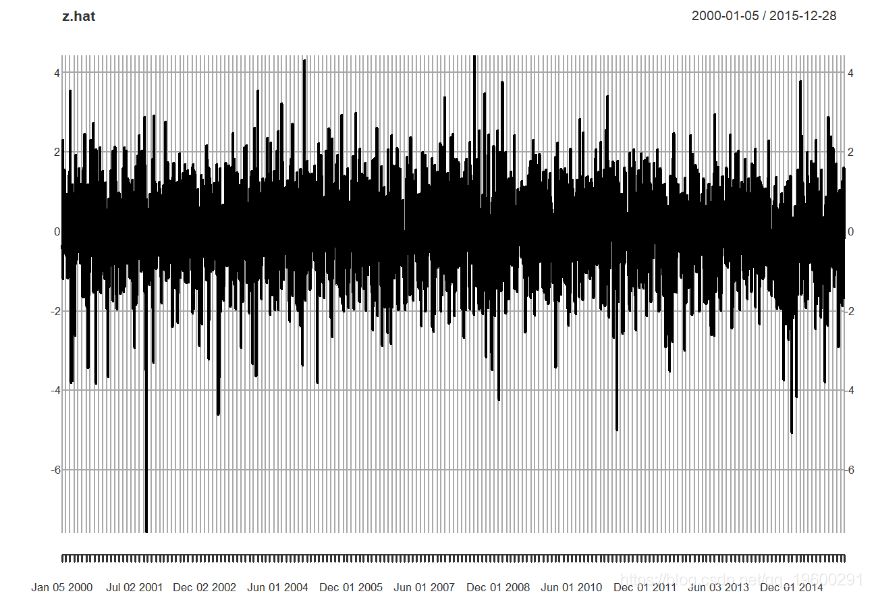
hist(z.hat)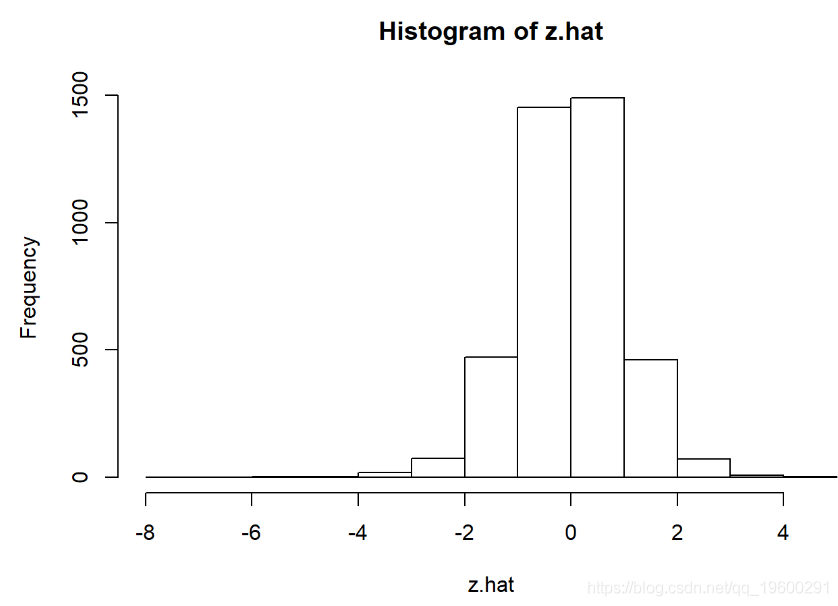
mean(z.hat)## [1] -0.0181139var(z.hat)kurtosis(z.hat)我们看到了什么?
- 左偏。
- 厚尾。
- 两种标准检验均表明拒绝该序列为正态分布的零假设。
模拟
- 使用fit 结果中的参数指定AR-GARCH。
- 生成2000条模拟路径。
-
-
GARCHspec
-
## 生成长度为2000的两个路径
-
-
ugarchpath(GARCHspec, n.sim = 2000,
-
n.start = 50, m.sim = 2)
提取波动率
head(vol)-
## [,1] [,2]
-
## T+1 2.950497 5.018346
-
## T+2 2.893878 4.927087
-
## T+3 2.848404 4.849797
-
## T+4 2.802098 4.819258
-
## T+5 2.880778 4.768916
-
## T+6 2.826746 4.675612
-
## 实际的模拟数据
-
X <- series$seriesSim
-
head(X)
-
## [,1] [,2]
-
## [1,] 0.1509418 1.4608335
-
## [2,] 1.2644849 -2.1509425
-
## [3,] -1.0397785 4.0248510
-
## [4,] 4.4369130 3.4214660
-
## [5,] -0.3076812 -0.1104726
-
## [6,] 0.4798977 2.7440751
示例
模拟的序列是否符合事实?
-
X1 <- X[, 1]
-
acf(X1)
-
acf(abs(X1))
-
qqnorm(X1)
-
qqline(X1, col = 2)
-
shapiro.test(X1)
这是结果
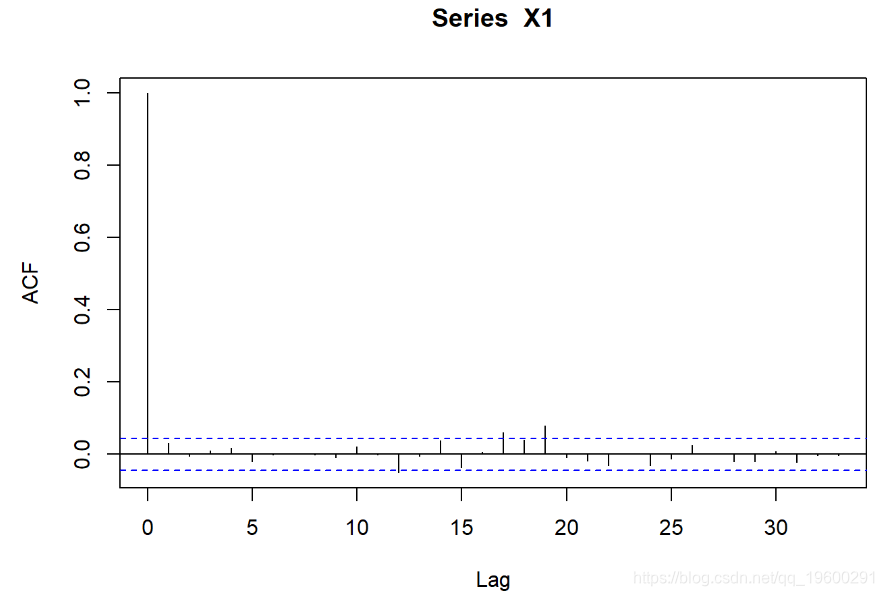
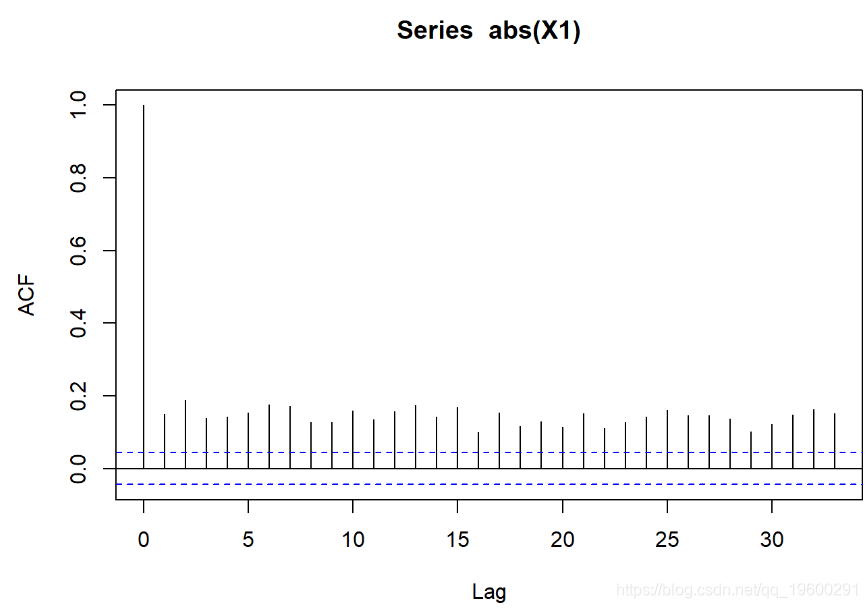
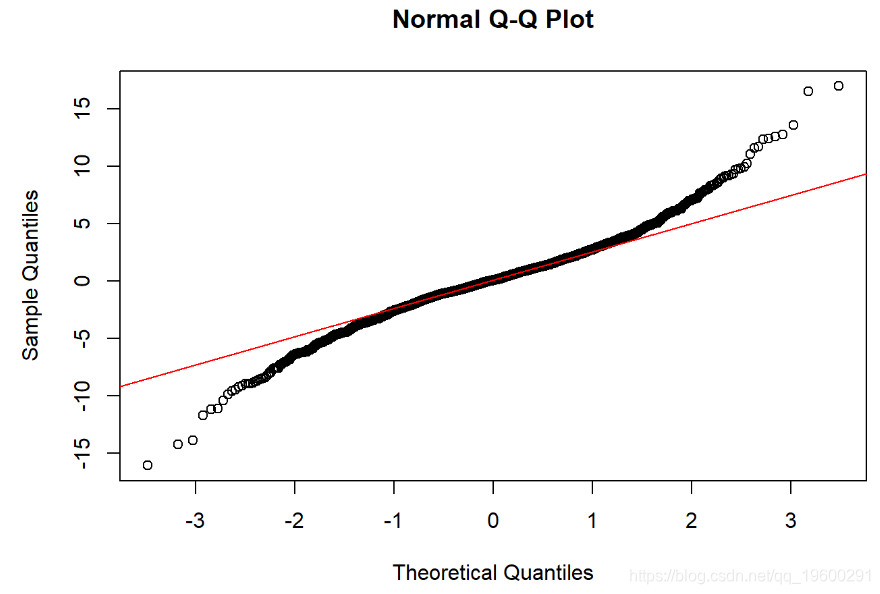
Shapiro-Wilk检验-零假设:正态分布。如果p值足够小,则拒绝原假设。-必须使用QQ图进行验证。
多元GARCH
从单变量GARCH到多元GARCH
- 动态条件相关。
- 具有随时间变化的波动性。
- 如何使资产收益之间的相关性也随时间变化。
为什么?-如果我们拥有投资组合(例如应收账款,可能会面临汇率和原油价格变动的情况),该怎么办?-我们需要了解这三个因素的联合波动性和依赖性,因为它们会影响应收账款的整体波动性。我们将使用这些条件方差来模拟管理货币和商品风险的工具的期权价格。
dcc.garch11.spec现在进行拟合
现在让我们得到一些结果:
- 联合条件协方差参数显着不同于零。
现在,使用来自拟合的所有信息,我们进行预测。我们用来模拟套期工具或投资组合VaR或ES,让我们先绘制随时间变化的sigma。
示例
鉴于条件波动性和相关性,请查看VaR和ES的三个风险因素。
这是一些结果。首先,计算,然后绘图。
-
## 1% 5% 50% 95% 99%
-
## -6.137269958 -3.677130793 -0.004439644 3.391312753 5.896992710
-
## 1% 5% 50% 95% 99%
-
## -1.3393119939 -0.8235076255 -0.0003271163 0.7659725631 1.2465945013
-
## 1% 5% 50% 95% 99%
-
## -1.520666396 -0.980794376 0.006889539 0.904772045 1.493169076
我们看到:
- 在分布的负数部分权重更大。
- 汇率大致相同。
- 如果您在客户和分销过程中使用布伦特原油,则可能会在约1%的时间内遭受600%以上的损失。
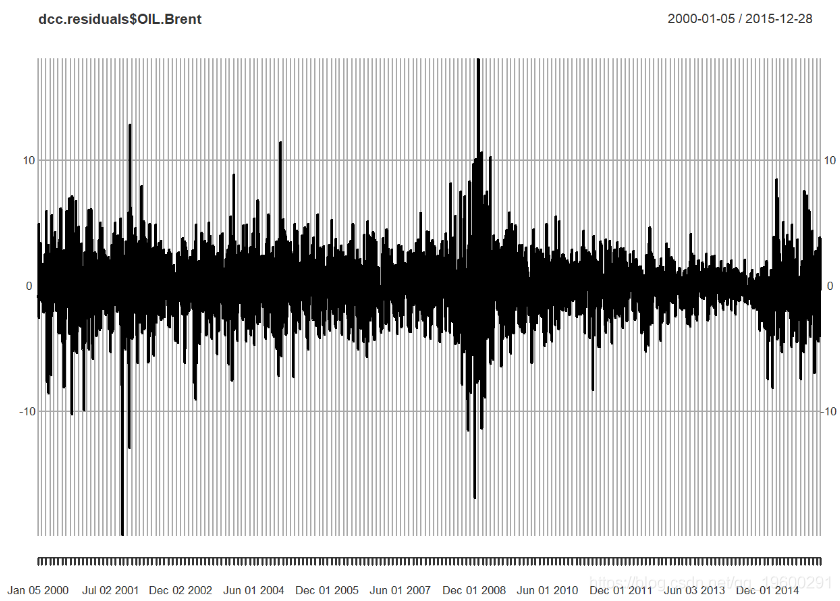
让我们使用新的波动率模型和分布进行调整,以拟合不对称和厚尾。
在这里,我们尝试使用一种新的GARCH模型:gjr代表Glosten,Jagannathan和Runkle(1993)他们提出的一个波动模型:
σ2t=ω+ασ2t-1+β1ε2t-1+β2ε2t-1It-1
拟合此模型。
我们可以使用 tailplot() 函数解释结果。
-
## p quantile sfall
-
## [1,] 0.900 3.478474 5.110320
-
## [2,] 0.950 4.509217 6.293461
-
## [3,] 0.975 5.636221 7.587096
-
## [4,] 0.990 7.289163 9.484430
-
## [5,] 0.999 12.415553 15.368772
quantile 给出我们的风险价值(VaR)和期望损失(ES)
可以看到尾部图。
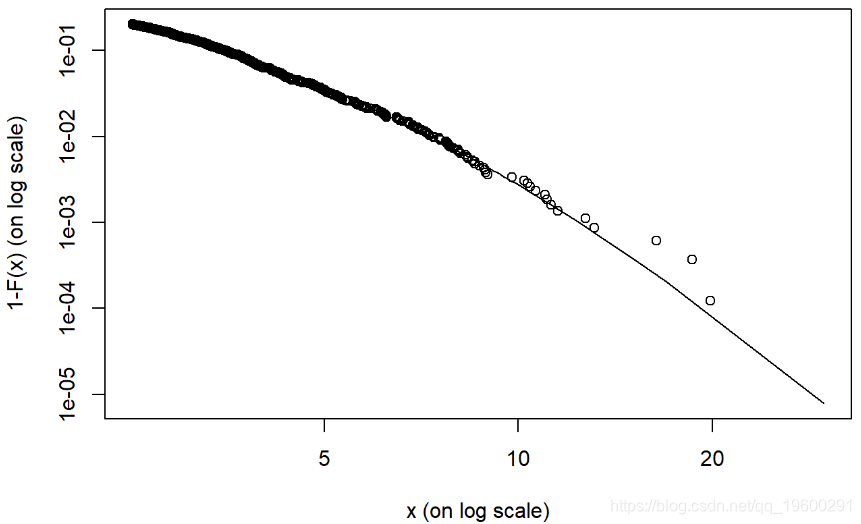
-
结果表明,使用AR-GARCH处理后,尾部更厚。
-
我们可以回到市场和风险部分,了解平均超额价值以及VaR和ES的置信区间。
-
对于应收帐款,缓解策略可能是通过再保险和总收益互换提供超额风险对冲。
-
对客户的信用风险分析至关重要:频繁更新客户将有助于及早发现某些解决方案的问题。

最受欢迎的见解
1.用机器学习识别不断变化的股市状况—隐马尔科夫模型(HMM)的应用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号