

拓端tecdat|使用R语言做极大似然估计实例
原文链接:http://tecdat.cn/?p=18970
在普遍的理解中,最大似然估计是使用已知的样本结果信息来反向推断最有可能导致这些样本结果的模型参数值!
换句话说,最大似然估计提供了一种在给定观测数据的情况下评估模型参数的方法,即“模型已确定且参数未知”。
在所有双射函数的意义上,极大似然估计是不变的 ,如果
是
的极大似然估计
。
让 ,
等于
中的似然函数。由于
是的最大似然估计
,
因此, 是
的最大似然估计 。
例如,伯努利分布为 ,
给定样本 ,概率是
则对数似然
与ICI
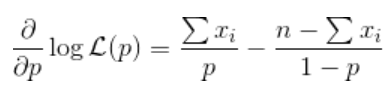
因此,一阶条件
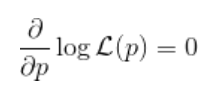
何时满足 。为了说明,考虑以下数据
-
-
> X
-
[1] 0 0 1 1 0 1 1 1 1 0 0 0 1 0 1
(负)对数似然
-
> loglik=function(p){
-
+ -sum(log(dbinom(X,size=1,prob=p)))
-
+ }
我们可以在下面看到
-
-
> plot(u,v,type="l",xlab="",ylab="")
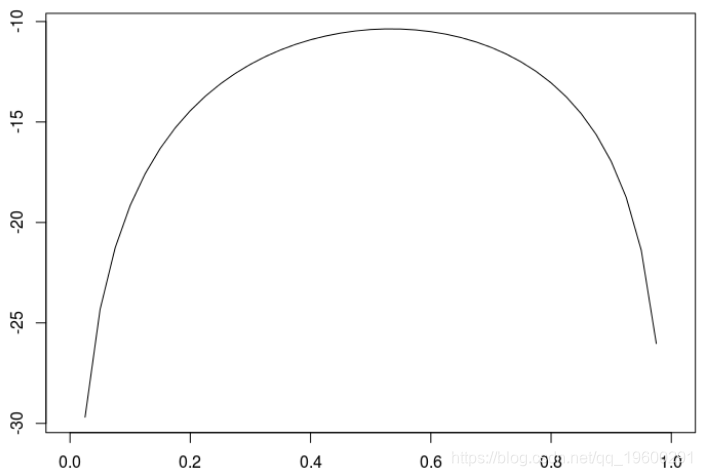
根据以上计算,我们知道的极大似然估计 是
-
> mean(X)
-
[1] 0.53
数值为
-
$par
-
[1] 0.53
-
-
$value
-
[1] 10.36
-
-
$counts
-
function gradient
-
20 NA
-
-
$convergence
-
[1] 0
-
-
$message
-
NULL
我们没有说优化是在区间内 。但是,我们的概率估计值属于
。为了确保最优值在
,我们可以考虑一些约束优化程序
-
ui=matrix(c(1,-1),2,1), ci=c(0,-1)
-
$par
-
[1] 0.53
-
-
$value
-
[1] 10.36
-
-
$counts
-
function gradient
-
20 NA
-
-
$convergence
-
[1] 0
-
-
$message
-
NULL
-
-
$outer.iterations
-
[1] 2
-
-
$barrier.value
-
[1] 6.91e-05
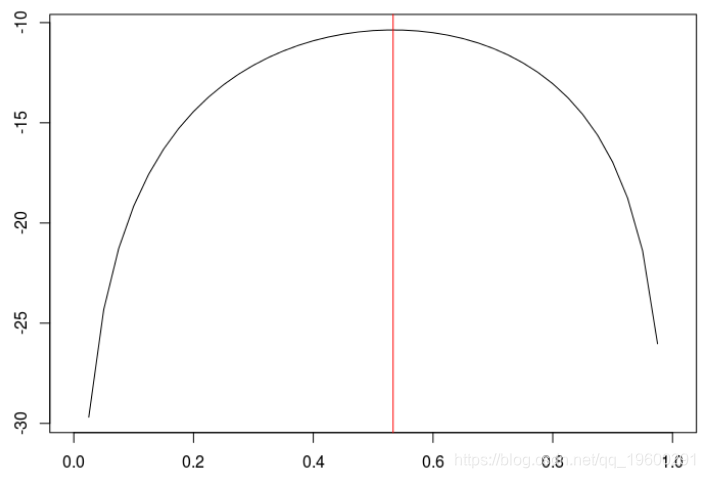
在上一张图中,我们达到了对数似然的最大值
> abline(v=opt$par,col="red")
另一种方法是考虑 (如指数分布)。则对数似然
![]()
这里
因此,一阶条件
满足
即
从数值角度来看,我们有相同的最优值
-
(opt=optim(0,loglik))
-
$par
-
[1] 0.13
-
-
$value
-
[1] 10.36
-
-
$counts
-
function gradient
-
20 NA
-
-
$convergence
-
[1] 0
-
-
$message
-
NULL
-
-
> exp(opt$par)/(1+exp(opt$par))
-
[1] 0.53

最受欢迎的见解
1.Matlab马尔可夫链蒙特卡罗法(MCMC)估计随机波动率(SV,Stochastic Volatility) 模型
3.WinBUGS对多元随机波动率模型:贝叶斯估计与模型比较
4.R语言回归中的hosmer-lemeshow拟合优度检验
5.matlab实现MCMC的马尔可夫切换ARMA – GARCH模型估计
9.R语言如何在生存分析与Cox回归中计算IDI,NRI指标
▍关注我们
【大数据部落】第三方数据服务提供商,提供全面的统计分析与数据挖掘咨询服务,为客户定制个性化的数据解决方案与行业报告等。
▍咨询链接:http://y0.cn/teradat
▍联系邮箱:3025393450@qq.com
