

拓端tecdat| R语言分布滞后线性和非线性模型(DLM和DLNM)建模
原文链接:http://tecdat.cn/?p=18700
前言
本文说明了R语言中实现分布滞后线性和非线性模型(DLM和DLNM)的建模。首先,本文描述了除时间序列数据之外的DLM / DLNM的一般化方法,在Gasparrini [2014]中有更详细的描述。本文中包含的结果并不代表科学发现,而仅出于说明目的进行报告。
数据
主要通过两个示例来说明软件的应用,使用药物数据作为数据对象。数据集分别包含一项关于药物的假设试验和嵌套病例对照研究的模拟数据,两者均包括随时间变化的暴露量度。
让我们看一下数据框的前2个观察样本:
-
> head(data, 2)
-
id out sex day1 day8. day15. day22.
-
1 1 46 M 0 0 40 37
-
2 2 50 F 0 47 55 0
数据集包含来自一项试验的数据,记录了200名随机受试者,每名受试者随机接受四周中两周的药物剂量,每天的剂量每周变化。每周7天间隔报告一次暴露水平。数据集还包含有关在第28天测量的结果和受试者性别的信息。嵌套的第二个数据包括针对300个癌症病例和300个按年龄匹配的对照的每个记录。前2个观察结果是:
-
> head(nested)
-
id case age riskset exp15 exp20 exp25 exp30 exp35 exp40 exp45 exp50 exp55
-
1 1 1 81 240 5 84 34 45 128 81 14 52 11
-
2 2 1 69 129 11 8 25 6 8 12 19 60 16
-
-
exp60
-
1 16
-
2 10
变量病例定义病例/对照状态,而其他变量报告受试者的年龄和他/她所属的风险。随时间变化的职业暴露档案存储在变量exp15–exp60中,对应于15至19岁,20至24岁等最高65岁的平均年暴露量。
暴露历史矩阵
扩展的DLNM框架与标准DLNM框架之间的主要区别是暴露历史矩阵的定义,即对n个观测值的滞后`经历的一系列暴露。根据研究设计和随时间变化的暴露信息,需要以不同的方式将这个n×(L −'0 + 1)矩阵组合在一起。
在第一个示例中,我为数据框药物中的试验数据建立了暴露历史记录矩阵。
每个受试者的接触曲线用于重建接触历史矩阵。在这种情况下,滞后0的暴露量对应于对所有受试者测量结局的第28天的暴露量。其余的暴露历史记录可追溯到滞后27,对应于第一天的暴露。代码,用于将按周存储的暴露资料扩展为每日暴露历史记录的矩阵:每个受试者的接触曲线用于重建接触历史矩阵。
-
-
> drug[1:3,1:14]
-
lag0 lag1 lag2 lag3 lag4 lag5 lag6 lag7 lag8 lag9 lag10 lag11 lag12 lag13
-
1 37 37 37 37 37 37 37 40 40 40 40 40 40 40
-
2 0 0 0 0 0 0 0 55 55 55 55 55 55 55
上面针对前三个主题报告了滞后0-13的接触历史。前七个滞后(0–6)对应于上周的暴露,而滞后7–13对应于第三周,依此类推。在第二个示例中,我使用以5年为间隔的暴露量分布图来嵌套数据框的暴露量历史矩阵。这些数据被扩展为滞后3–40的暴露历史矩阵,滞后单位等于一年。但是,在这种情况下,由于每个对象在不同的年龄进行采样,因此计算更加复杂。具体地,从受检者的年龄开始沿着暴露曲线向后计算暴露历史。此步骤需要一些额外的计算和数据处理。可以得出给定时间的暴露曲线的暴露历史,
-
> nest <- t(apply(nested, 1, function(sub) exphi(repc(0,0,0,sub5:14]),
-
-
-
> nest[1:3,1:11]
-
lag3 lag4 lag5 lag6 lag7 lag8 lag9 lag10 lag11 lag12 lag13
-
1 0 0 0 0 0 0 0 0 0 0 0
-
2 0 10 10 10 10 10 16 16 16 16 16
上面针对前三个主题报告了滞后0–10的暴露历史。假设第一个对象在81岁时进行采样,则经历了在滞后0处介于80和81之间,在滞后1处介于79和80之间的暴露,依此类推。由于他/她的上一次暴露年龄为65岁,因此将滞后10的暴露历史记录设置为0。在69岁时进行采样的第二个对象的滞后3的暴露历史记录设置为0,对应于暴露事件在66。
这些接触历史与之前显示的接触概况和年龄一致。在这种情况下,使用相同的暴露状况,在每个受试者贡献不同风险集时计算每个受试者的多次暴露历史。通常,此矩阵的计算取决于研究设计,暴露信息,滞后单位和所需的近似水平。
时间序列以外的应用
一个简单的DLM
在第一个示例中,我将dlnm应用于数据集药物,分析了药物日剂量与未指定健康结果之间的时间依赖性。第一步是函数的定义:
crossbasis(drug, lag=27, argvar=list("lin")
结果存储在对象cbdrug中,即具有特殊属性的已转换变量的矩阵。参数argvar和arglag分别定义了暴露反应和滞后反应函数,此处选择它们为简单线性函数和三次样条。通过函数summary获得摘要:
-
CROSSBASIS FUNCTIONS
-
observations: 200
-
range: 0 to 100
-
lag period: 0 27
-
total df: 4
-
BASIS FOR VAR:
-
fun: ns
-
knots: 9 18
cbdrug可以包含在回归模型的公式中,在这种情况下,该模型是假设高斯分布,控制性别影响的简单线性模型。通过函数crosspred()预测来解释估计的滞后关联:
crosspred(cbdrug, mdrug, at=0:20*5)
效果摘要保存在“ crosspred”类的对象pdrug中
-
allfit alllow allhigh
-
30.29 20.12 40.46
上面的代码提取了与50次暴露相关的总体累积效应的估算值,可以进行解释:在28天滞后时间内持续不断地暴露于50次之后的总体结果增加。还包括95%的置信区间。
可以生成图:
-
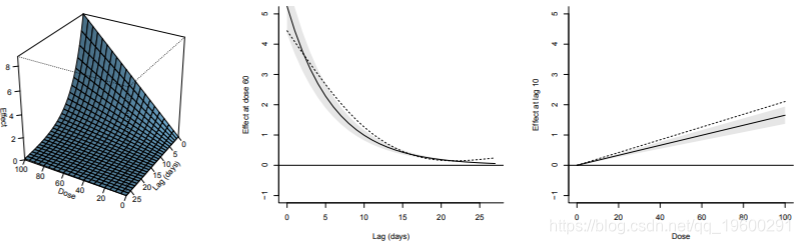
> plot(drug, zlab="Effect", xlab="Dose, ylab="Lag (days")
-
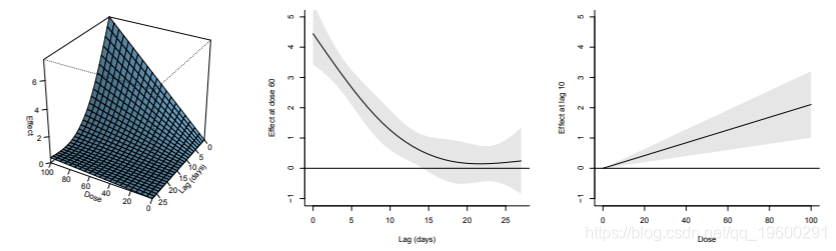
代码的第一行产生图1中的图形,显示效果在剂量和滞后值的范围内如何变化。该图表明,在摄入后的头几天,该剂量的药物作用明显,然后在15-20天后趋于消失。从横截面来看,图分别显示了暴露60的滞后反应曲线和滞后10的暴露-反应曲线。图中的滞后反应曲线表明了效应的指数衰减。
更为复杂的DLNM
在第二个示例中,我使用嵌套的数据集来评估长期暴露于职业病中如何影响癌症发生的风险。分析步骤与说明的步骤相同。最初的假设是,过去三年中持续的暴露(对应于滞后0–2)不会影响发生癌症的风险。
选择的基函数是用于预测变量的二次样条和三次样条。通过clogit()执行条件逻辑回归。然后预测效果摘要。代码是:
-
> library(survival)
-
clogit(case~cbnest+strata(riskset, nested)
图1中显示的相同类型的图可通过以下方式获得:
> plot(est, zlab="OR", xlab="Exposure, ylab=Lag (years")
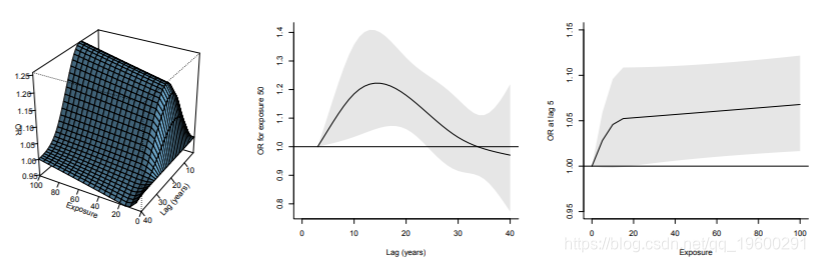
图中的3-D图再次被解释为职业暴露与癌症风险之间的关联。在此示例中,滞后时间段以年为单位表示。该图表明风险的初始增加(以比值比(OR)衡量),然后降低。从横截面来看,图中估计的滞后反应曲线显示了暴露后10至15年的风险峰值,尽管置信区间非常宽泛,但风险在暴露后30年回到基础水平。
扩展预测
之前获得的预测结果是在直接指定的曝露和滞后值的网格上计算的。
我们也可以计算新的效果摘要,在给定暴露曲线的情况下生成暴露历史矩阵。例如,我们可以使用嵌套病例对照分析来计算,假设受试者暴露于暴露10年达5年,然后未暴露于5年,再暴露于13年达10年的总体累计OR。从此暴露量配置中,我们可以计算出暴露时间结束时的暴露历史,并预测。
-
-
> hist
-
lag3 lag4 lag5 lag6 lag7 lag8 lag9 lag10 lag11 lag12 lag13 lag14 lag15 lag16
-
20 13 13 13 13 13 13 13 0 0 0 0 0 10 10
产生时间3到40的滞后时间的暴露历史。通过自变量时间设置特定时间,在这种情况下,该时间对应于暴露时间的结束时间(以指数表示)。包括最近的21次暴露至0,以完成长达40年的暴露历史。现在,我们可以使用hist作为crosspred()的参数来预测总体累积效果。注意,滞后周期必须与估计中使用的一致。
-
> with(pnestt, allRfit,aRRlow,allRRigh)
-
20 20 20
-
3.5031.2409.900
与在整个滞后期间没有暴露的受试者相比,估计的OR为3.5(95%CI:1.2–9.9)。可以使用相同的方法来获取特定暴露量分布随时间的动态预测。这个思想是基于假定的暴露-滞后-反应关联,在给定随时间变化的暴露历史的情况下,及时地动态预测风险。实际上,对于每个给定的时间,随着特定的暴露事件涉及不同的滞后时间,暴露历史会发生变化。举例来说,我展示了如何使用试验数据分析来估算特定药物处方后的动态预测效果。
假设某位患者接受10剂量的治疗,持续2周,然后他/她增加至50,持续1周,然后停药1周,然后以20的剂量重新开始治疗2周。首先,我创建每日暴露资料:
> expdrug <- rep(c(10,50,0,20),c(2,1,1,2)*7)
现在可以沿暴露曲线顺序来创建所有时间点的暴露历史矩阵:
> nhist <- exphi(expdr, lag=27)
现在可以在crosspred()中使用此矩阵来获取动态预测。
现在可以使用该对象绘制动态预测:
-
> plot(drug,"overall", ylab="Effect xlab="Time (days", ylim=c(-10,27)
-
> axis(2, at=-1:5*5)
-
> par(new=TRUE)
-
> axis(4, at=0:6*10, cex.axis=0.8)
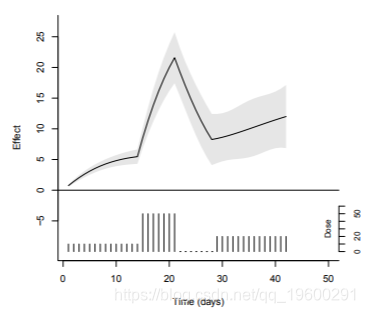
在图中绘制了整体累积关联。此图显示了与上面详细介绍的药物处方相关的基线结果的变化。正如预期的那样,效果会随剂量动态变化,但会出现滞后。
应用改进函数
对于第一个示例,我们可以修改先前分析。图2建议在高暴露量下可能会减弱效果。这个事实和暴露分布的偏斜度可以通过对数变换来解决。首先,让我们定义一个新的函数:
log <- function(x) log(x+1)
现在可以建模暴露-反应曲线:
-
nest2 <- crossbasis(est, lag=c(3,40), argvar=list("log"),
-
-
CROSSBASIS FUNCTIONS
-
-
observations: 600
-
range: 0 to 1064
-
lag period: 3 40
-
total df: 3
-
BASIS FOR VAR:
-
fun: mylog
-
BASIS FOR LAG:
-
fun: ns
-
knots: 10 30
-
intercept: FALSE
-
Boundary.knots: 3 40
替换新创建的对象:
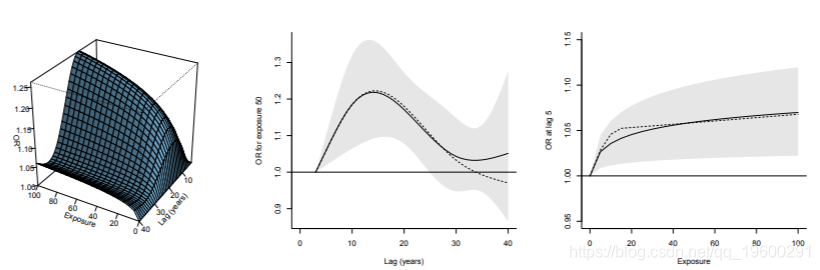
可以将图中显示的结果与最初显示的结果进行比较。该比较表明对数的假设使精度大大提高。
对图的检查表明,滞后反应曲线遵循指数衰减轨迹。应用衰减函数而不是三次样条曲线可能是合理的。衰减函数可以定义为:
-
decay <- function(x,scale=5)
-
basis <- exp(-x/scale)
-
attributes(basis)$scale <- scale
-
参数(默认值为5)用于控制衰减程度。同样,我们可以使用此新函数来获得变换:
-
> cbdrug2 <- crossbasis(Qdrug, lag=27,
-
arglag=list(fun="fdecay")
-
-
CROSSBASIS FUNCTIONS
-
observations: 200
-
range: 0 to 100
-
lag period: 0 27
-
total df: 1
-
BASIS FOR VAR:
-
fun: lin
-
intercept: FALSE
-
BASIS FOR LAG:
-
fun: fdecay
-
scale: 6
同样,可以重复使用计算步骤以执行修改后的分析:
-
-
> lines(drug, var=60, lty=2)
-
> lines(drug, lag=10, lty=2)
结果报告在图中。与之前的结果进行比较(以虚线表示)显示了精度的显着提高。
回归分析的通用工具
软件包dlnm中的功能也可以用作回归分析的通用工具。第一个示例演示了如何使用带有回归函数lm()的回归样条来评估30-39岁的女性样本中平均身高和体重之间的关系。
-
> library(splines)
-
> oneheight <- onebasis(women$height, "ns" df=5)
-
> mwomen <- lm(weight ~ oneheight data=women)
使用一个简单的代码来获取预测和绘图:
-
> with(pwomen, cbind(fit, low, high)["70",)
-
allfit alllow allhigh
-
18.92287 18.46545 19.38030
可以简单地查看带有置信区间的估计关联,绘制关联。
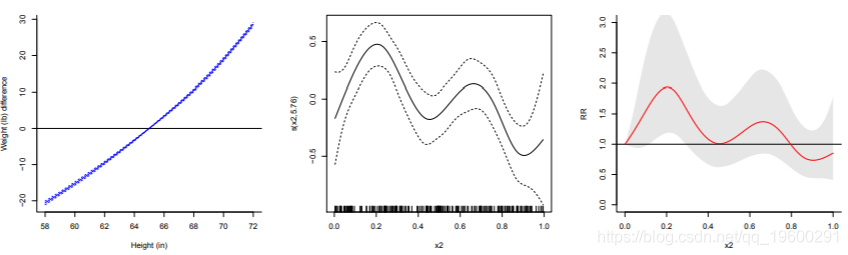
第二个示例使用惩罚样条对平滑关联进行分析。
-
> library(mgcv)
-
-
> b2 <- gam(y ~ s(x0,bs="cr") + s(x1,bs="cr") + s(x2,bs="cr") + s(x3,bs="cr"),
-
family=poisson, data=datmethod="REML")
-
> plot(b2, select=3)
该代码使用通过函数s()的回归样条,对带有多个变量的模拟数据执行GAM估计平滑关系。也可以使用dlnm获得预测和绘图,其中:
-
-
allRRfit allRRlow allRRhigh
-
1.3405415 0.8309798 2.1625694
-
> plot(gam, ylim=c(0,3)col=2)
参考文献
A. Gasparrini. Modeling exposure-lag-response associations with distributed lag non-linear models. Statistics in Medicine, 33(5):881–899, 2014.

最受欢迎的见解
2.R语言线性判别分析(LDA),二次判别分析(QDA)和正则判别分析(RDA)
5.在r语言中使用GAM(广义相加模型)进行电力负荷时间序列分析
6.使用SAS,Stata,HLM,R,SPSS和Mplus的分层线性模型HLM
7.R语言中的岭回归、套索回归、主成分回归:线性模型选择和正则化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号