



拓端tecdat|R语言ARIMA集成模型预测时间序列分析
原文链接:http://tecdat.cn/?p=18493
本文我们使用4个时间序列模型对每周的温度序列建模。第一个是通过auto.arima获得的,然后两个是SARIMA模型,最后一个是Buys-Ballot方法。
我们使用以下数据
-
-
k=620
-
n=nrow(elec)
-
futu=(k+1):n
-
y=electricite$Load[1:k]
-
plot(y,type="l")
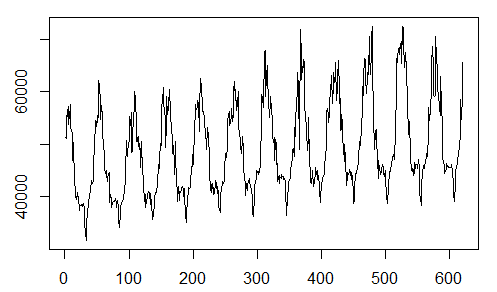
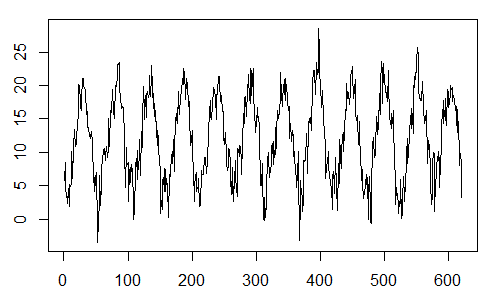
我们开始对温度序列进行建模(温度序列对电力负荷的影响很大)
-
-
y=Temp
-
plot(y,type="l")
-
-
abline(lm(y[ :k]~y[( :k)-52]),col="red")
-
-
-
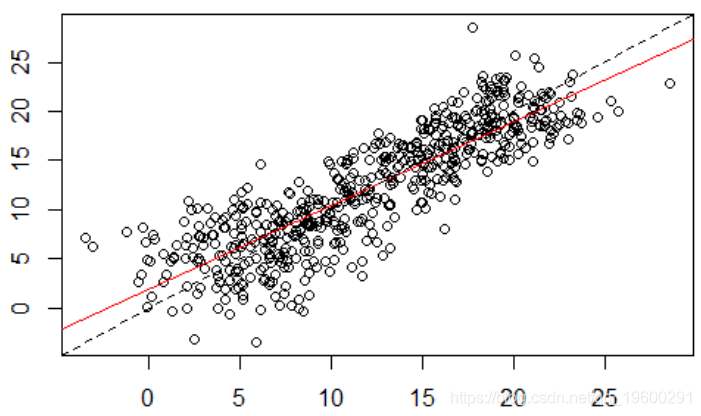
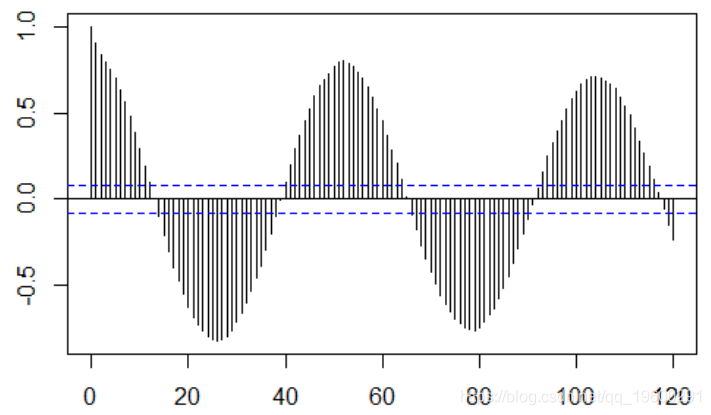
时间序列是自相关的,在52阶
-
-
acf(y,lag=120)
-
-
-
-
model1=auto.arima(Y)
-
acf(residuals(model1),120)
-
-
我们将这个模型保存在工作空间中,然后查看其预测。让我们在这里尝试一下SARIMA
-
-
arima(Y,order = c(0,0,0),
-
seasonal = list(order = c(1,0,0)))
-
-
-
然后让我们尝试使用季节性单位根
-
-
Z=diff(Y,52)
-
arima(Z,order = c(0,0,1),
-
seasonal = list(order = c(0,0,1)))
-
-
然后,我们可以尝试Buys-Ballot模型
-
-
lm(Temp~0+as.factor(NumWeek),
-
-
-
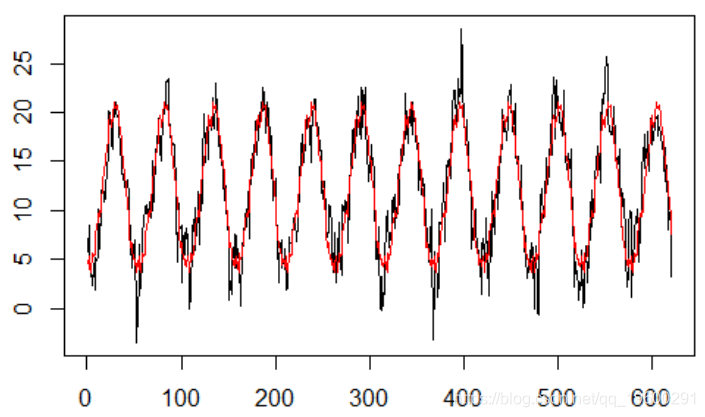
对模型进行预测
-
-
plot(y,type="l",xlim=c(0,n )
-
abline(v=k,col="red")
-
lines(pre4,col="blue")
-
-
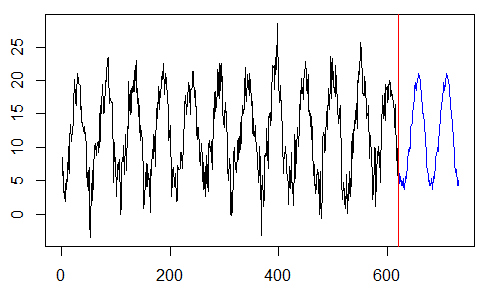
-
-
plot(y,type="l",xlim=c(0,n))
-
abline(v=k,col="red")
-
-

-
-
plot(y,type="l",xlim=c(0,n))
-
-
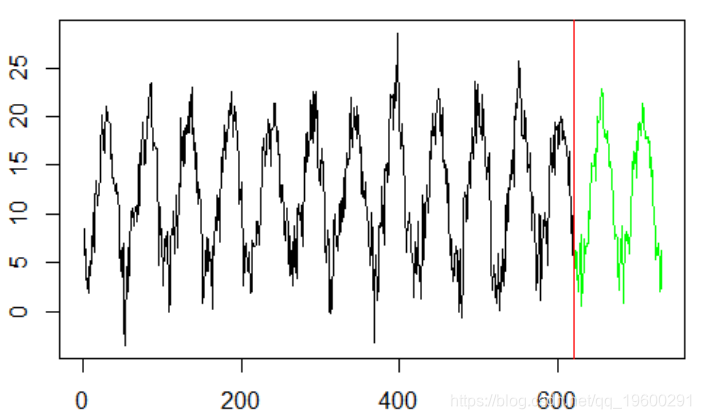
-
-
plot(y,type="l",xlim=c(0,n))
-
abline(v=k,col="red")
-
-
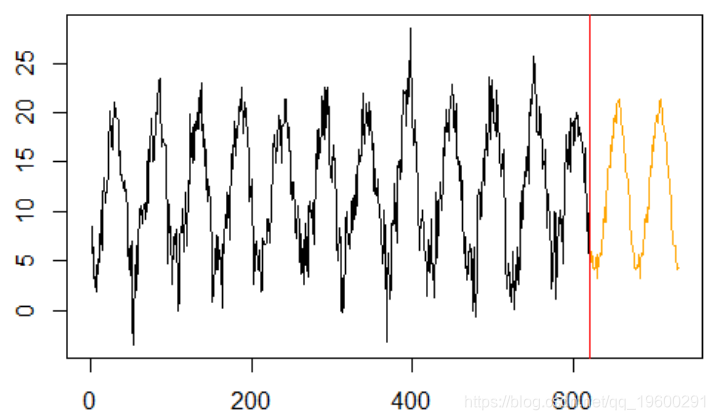
最后比较4个模型的结果
-
-
lines( MODEL$y1,col="
-
lines( MODEL$y2,col="green")
-
lines( MODEL$y3,col="orange")
-
lines( MODEL$y4,col="blue")
-
-
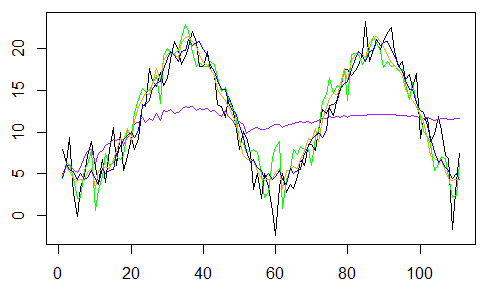
然后,我们可以尝试加权平均值来优化模型,而不是找出四个中的哪一个模型是“最优”,y ^ T = ∑iωiy ^ t(i)其中ω=(ωi),ω1+ ... +ωk= 1。然后,我们想要找到“最佳”权重。我们将在第一个m值上校准我们的四个模型,然后比较下111个值(和真实值)的预测组合,

我们使用前200个值。
然后,我们在这200个值上拟合4个模型
然后我们进行预测
-
-
y1=predict(model1,n.ahead = 111)$pred,
-
y2=predict(model2,n.ahead = 111)$pred,
-
y3=predict(model3,n.ahead = 111)$pred,
-
y4=predict(model4,n.ahead = 111)$pred+
-
-
为了创建预测的线性组合,我们使用
-
-
a=rep(1/4,4)
-
y_pr = as.matrix(DOS[,1:4]) %*% a
-
-
因此,我们可视化这4个预测,它们的线性组合(带有等权重)及其观察值
为了找到权重的“最佳”值,最小化误差平方和,我们使用以下代码
-
-
function(a) sum( DONN[,1:4 %*% a-DONN[,5 )^2
-
-
-
我们得到最优权重
-
-
optim(par=c(0,0,0),erreur2)$par
-
-
-
然后,我们需要确保两种算法的收敛性:SARIMA参数的估计算法和权重参数的研究算法。
-
-
if(inherits(TRY, "try-error") arima(y,order = c(4,0,0)
-
seasonal = list(order = c(1,0,0)),method="CSS")
-
-
-
-
然后,我们查看权重随时间的变化。
获得下图,其中粉红色的是Buys-Ballot,粉红色的是SARIMA模型,绿色是季节性单位根,
-
-
barplot(va,legend = rownames(counts)
-
-
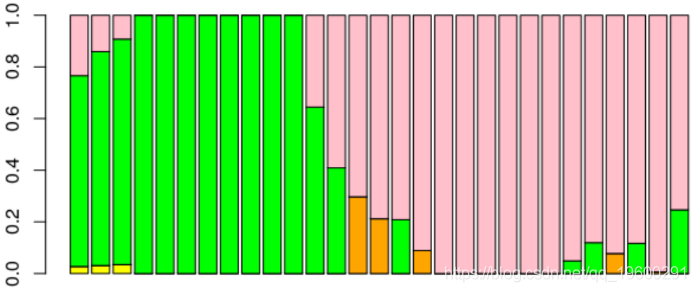
我们发现权重最大的模型是Buys Ballot模型。
可以更改损失函数,例如,我们使用90%的分位数,
-
-
tau=.9
-
function(e) (tau-(e<=0))*e
-
-
在函数中,我们使用
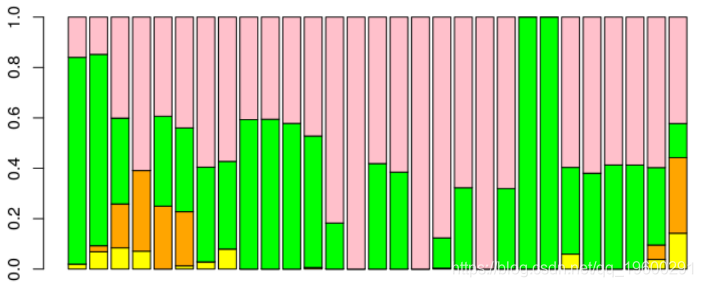
这次,权重最大的两个模型是SARIMA和Buys-Ballot。

最受欢迎的见解
1.在python中使用lstm和pytorch进行时间序列预测
2.python中利用长短期记忆模型lstm进行时间序列预测分析
8.r语言k-shape时间序列聚类方法对股票价格时间序列聚类

