

拓端tecdat|Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
原文链接:http://tecdat.cn/?p=17748
在数据科学学习之旅中,我经常处理日常工作中的时间序列数据集,并据此做出预测。
我将通过以下步骤:
探索性数据分析(EDA)
- 问题定义(我们要解决什么)
- 变量识别(我们拥有什么数据)
- 单变量分析(了解数据集中的每个字段)
- 多元分析(了解不同领域和目标之间的相互作用)
- 缺失值处理
- 离群值处理
- 变量转换
预测建模
- LSTM
- XGBoost
问题定义
我们在两个不同的表中提供了商店的以下信息:
- 商店:每个商店的ID
- 销售:特定日期的营业额(我们的目标变量)
- 客户:特定日期的客户数量
- StateHoliday:假日
- SchoolHoliday:学校假期
- StoreType:4个不同的商店:a,b,c,d
- CompetitionDistance:到最近的竞争对手商店的距离(以米为单位)
- CompetitionOpenSince [月/年]:提供最近的竞争对手开放的大致年份和月份
- 促销:当天促销与否
- Promo2:Promo2是某些商店的连续和连续促销:0 =商店不参与,1 =商店正在参与
- PromoInterval:描述促销启动的连续区间,并指定重新开始促销的月份。
利用所有这些信息,我们预测未来6周的销售量。
-
# 让我们导入EDA所需的库:
-
-
import numpy as np # 线性代数
-
import pandas as pd # 数据处理,CSV文件I / O导入(例如pd.read_csv)
-
import matplotlib.pyplot as plt
-
import seaborn as sns
-
from datetime import datetime
-
plt.style.use("ggplot") # 绘图
-
-
-
#导入训练和测试文件:
-
train_df = pd.read_csv("../Data/train.csv")
-
test_df = pd.read_csv("../Data/test.csv")
-
-
-
#文件中有多少数据:
-
print("在训练集中,我们有", train_df.shape[0], "个观察值和", train_df.shape[1], 列/变量。")
-
print("在测试集中,我们有", test_df.shape[0], "个观察值和", test_df.shape[1], "列/变量。")
-
print("在商店集中,我们有", store_df.shape[0], "个观察值和", store_df.shape[1], "列/变量。")
-
在训练集中,我们有1017209个观察值和9列/变量。
在测试集中,我们有41088个观测值和8列/变量。
在商店集中,我们有1115个观察值和10列/变量。
首先让我们清理 训练数据集。
-
#查看数据
-
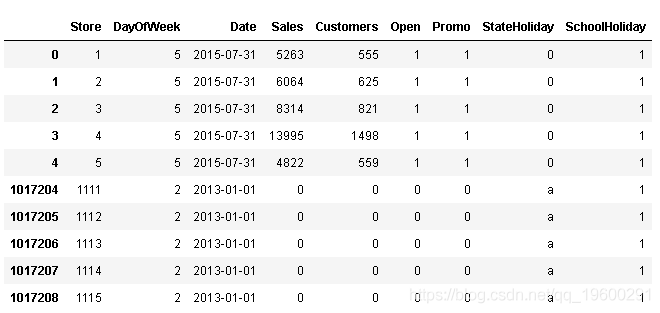
train_df.head().append(train_df.tail()) #显示前5行。
-
train_df.isnull().all()
-
Out[5]:
-
-
Store False
-
DayOfWeek False
-
Date False
-
Sales False
-
Customers False
-
Open False
-
Promo False
-
StateHoliday False
-
SchoolHoliday False
-
dtype: bool
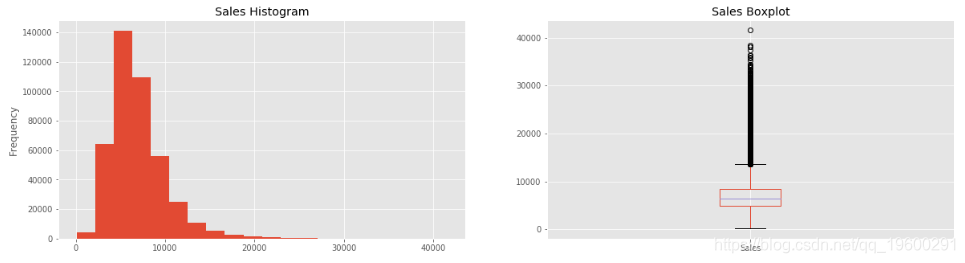
让我们从第一个变量开始-> 销售量
-
-
-
opened_sales = (train_df[(train_df.Open == 1) #如果商店开业
-
opened_sales.Sales.describe()
-
Out[6]:
-
-
count 422307.000000
-
mean 6951.782199
-
std 3101.768685
-
min 133.000000
-
25% 4853.000000
-
50% 6367.000000
-
75% 8355.000000
-
max 41551.000000
-
Name: Sales, dtype: float64
-
-
-
<matplotlib.axes._subplots.AxesSubplot at 0x7f7c38fa6588>
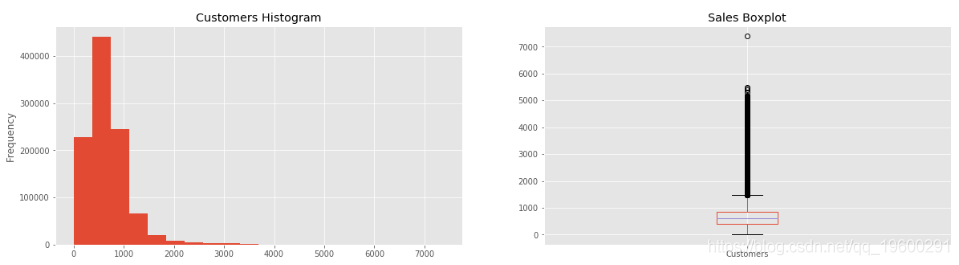
看一下顾客变量
-
In [9]:
-
-
train_df.Customers.describe()
-
Out[9]:
-
-
count 1.017209e+06
-
mean 6.331459e+02
-
std 4.644117e+02
-
min 0.000000e+00
-
25% 4.050000e+02
-
50% 6.090000e+02
-
75% 8.370000e+02
-
max 7.388000e+03
-
Name: Customers, dtype: float64
-
-
<matplotlib.axes._subplots.AxesSubplot at 0x7f7c3565d240>
train_df[(train_df.Customers > 6000)]
我们看一下假期 变量。
train_df.StateHoliday.value_counts()
-
0 855087
-
0 131072
-
a 20260
-
b 6690
-
c 4100
-
Name: StateHoliday, dtype: int64
train_df.StateHoliday_cat.count()
1017209
train_df.tail()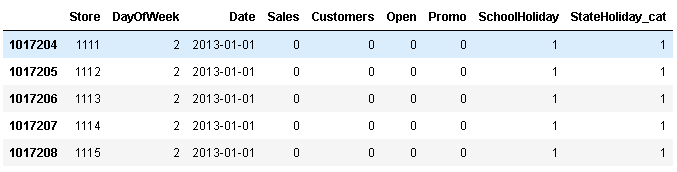
-
-
train_df.isnull().all() #检查缺失
-
Out[18]:
-
-
Store False
-
DayOfWeek False
-
Date False
-
Sales False
-
Customers False
-
Open False
-
Promo False
-
SchoolHoliday False
-
StateHoliday_cat False
-
dtype: bool
让我们继续进行商店分析
store_df.head().append(store_df.tail())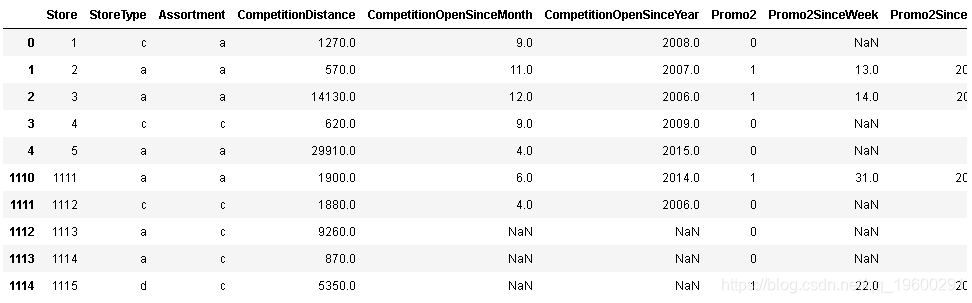
-
#缺失数据:
-
-
-
Store 0.000000
-
StoreType 0.000000
-
Assortment 0.000000
-
CompetitionDistance 0.269058
-
CompetitionOpenSinceMonth 31.748879
-
CompetitionOpenSinceYear 31.748879
-
Promo2 0.000000
-
Promo2SinceWeek 48.789238
-
Promo2SinceYear 48.789238
-
PromoInterval 48.789238
-
dtype: float64
-
In [21]:
-
让我们从缺失的数据开始。第一个是 CompetitionDistance
-
-
store_df.CompetitionDistance.plot.box()
让我看看异常值,因此我们可以在均值和中位数之间进行选择来填充NaN
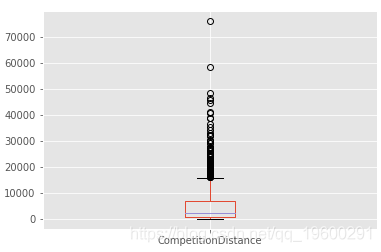
缺少数据,因为商店没有竞争。 因此,我建议用零填充缺失的值。
-
-
store_df["CompetitionOpenSinceMonth"].fillna(0, inplace = True)
让我们看一下促销活动。
store_df.groupby(by = "Promo2", axis = 0).count() 
如果未进行促销,则应将“促销”中的NaN替换为零
我们合并商店数据和训练集数据,然后继续进行分析。
第一,让我们按销售量、客户等比较商店。
-
f, ax = plt.subplots(2, 3, figsize = (20,10))
-
-
plt.subplots_adjust(hspace = 0.3)
-
plt.show()
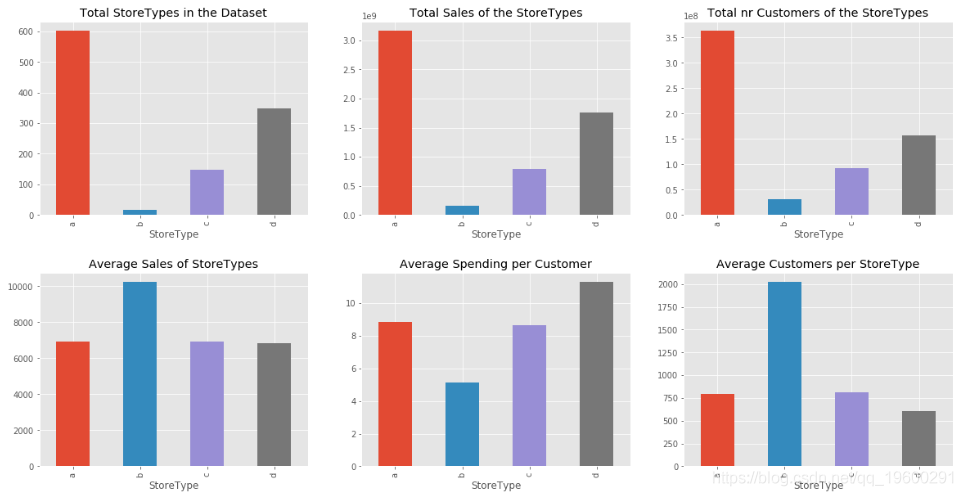
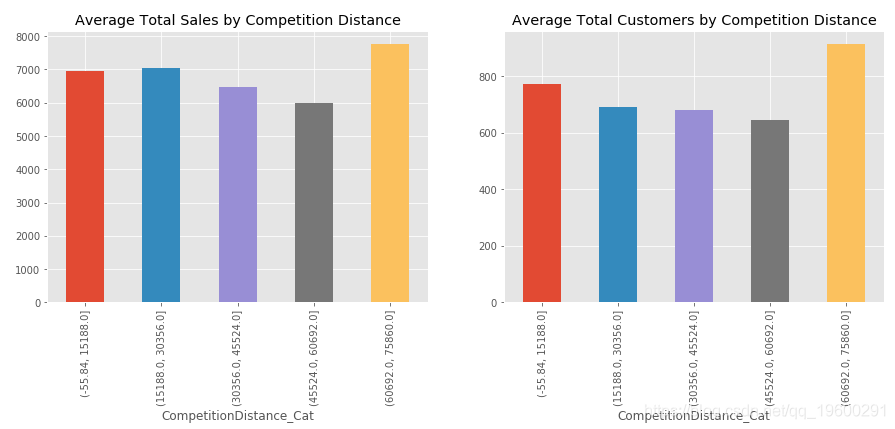
从图中可以看出,StoreType A拥有最多的商店,销售和客户。但是,StoreType D的平均每位客户平均支出最高。只有17家商店的StoreType B拥有最多的平均顾客。
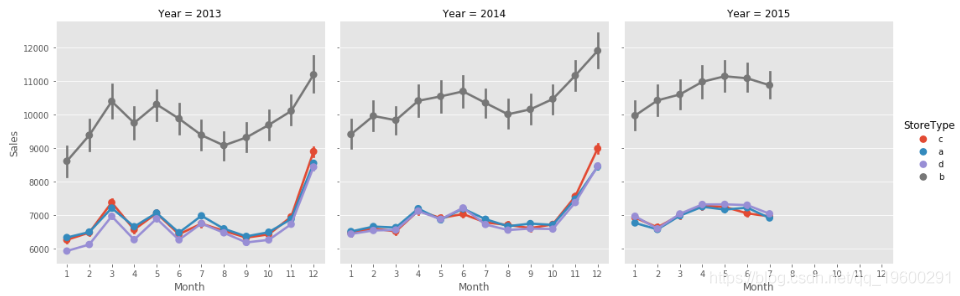
我们逐年查看趋势。
-
sns.factorplot(data = train_store_df,
-
# 我们可以看到季节性,但看不到趋势。 该销售额每年保持不变
-
-
-
<seaborn.axisgrid.FacetGrid at 0x7f7c350e0c50>
我们看一下相关图。
-
"CompetitionOpenSinceMonth", "CompetitionOpenSinceYear", "Promo2
-
-
<matplotlib.axes._subplots.AxesSubplot at 0x7f7c33d79c18>
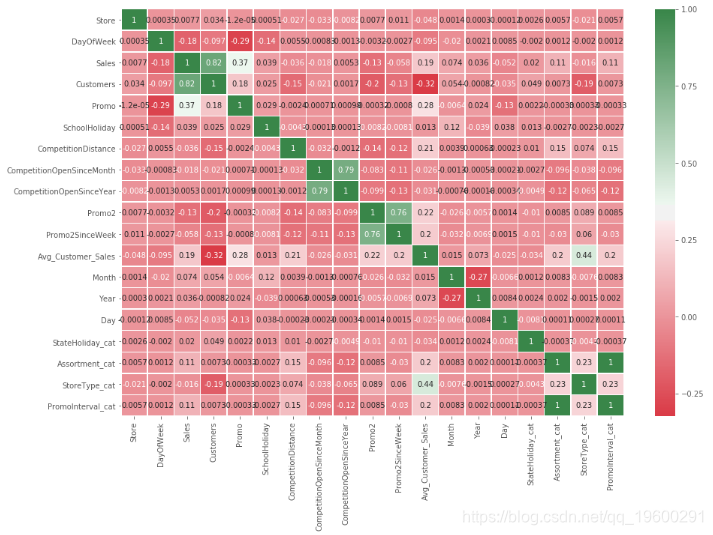
我们可以得到相关性:
- 客户与销售(0.82)
- 促销与销售(0,82)
- 平均顾客销量 vs促销(0,28)
- 商店类别 vs 平均顾客销量 (0,44)
我的分析结论:
- 商店类别 A拥有最多的销售和顾客。
- 商店类别 B的每位客户平均销售额最低。因此,我认为客户只为小商品而来。
- 商店类别 D的购物车数量最多。
- 促销仅在工作日进行。
- 客户倾向于在星期一(促销)和星期日(没有促销)购买更多商品。
- 我看不到任何年度趋势。仅季节性模式。

最受欢迎的见解
1.在python中使用lstm和pytorch进行时间序列预测
2.python中利用长短期记忆模型lstm进行时间序列预测分析
▍关注我们
【大数据部落】第三方数据服务提供商,提供全面的统计分析与数据挖掘咨询服务,为客户定制个性化的数据解决方案与行业报告等。
▍咨询链接:http://y0.cn/teradat
▍联系邮箱:3025393450@qq.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号