



拓端tecdat|R语言时间序列:ARIMA / GARCH模型的交易策略在外汇市场预测应用
原文链接:http://tecdat.cn/?p=17622
最近,我们继续对时间序列建模进行探索,研究时间序列模型的自回归和条件异方差族。我们想了解自回归移动平均值(ARIMA)和广义自回归条件异方差(GARCH)模型。它们在量化金融文献中经常被引用。
接下来是我对这些模型的理解,基于拟合模型的预测的一般拟合程序和简单交易策略的摘要。
这些时间序列分析模型是什么?
拟合ARIMA和GARCH模型是一种发现时间序列中的观测值,噪声和方差影响时间序列的方式。适当地拟合的这种模型将具有一定的预测效用,当然前提是该模型在将来的一段时间内仍非常适合基础过程。
ARMA
ARMA模型是自回归(AR)模型和移动平均(MA)模型的线性组合。AR模型其预测变量是该序列的先前值。MA模型在结构上类似于AR模型,除了预测变量是噪声项。p,q阶的自回归移动平均模型– ARMA(p,q)–是两者的线性组合,可以定义为:
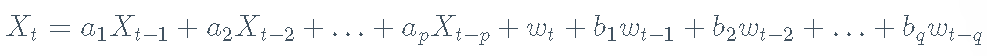
其中 w是白噪声,而a和 b是模型的系数。
ARIMA(p,d,q)模型是ARMA(p,q)模型,它们的差值是d倍-或积分(I)-以产生平稳序列。
GARCH
最后,GARCH模型还试图说明时间序列的异方差行为(即,波动性聚类的特征)以及该序列先前值的序列影响(由AR解释)和噪声项(由MA解释)。GARCH模型使用方差本身的自回归过程,也就是说,它使用方差的历史值来说明方差随时间的变化。
那么我们如何应用这些模型?
有了这种背景,我接下来将ARIMA / GARCH模型拟合到EUR / USD汇率,并将其用作交易系统的基础。使用拟合程序估算每天的模型参数,然后使用该模型预测第二天的收益,并相应保持一个交易日。
在每个交易日结束时,会使用滚动返回窗口来拟合最佳ARIMA / GARCH模型。拟合过程基于对参数的搜索,以最小化Aikake信息准则,但是也可以使用其他方法。例如,我们可以选择最小化贝叶斯信息准则的参数,这可以通过惩罚复杂模型(即具有大量参数的模型)来减少过度拟合。
我选择使用1000天的滚动窗口来拟合模型,但这是优化的参数。有一种情况是在滚动窗口中使用尽可能多的数据,但这可能无法足够快地捕获不断变化的模型参数以适应不断变化的市场。
这是代码:
-
### ARIMA / GARCH交易模型
-
-
#获取数据并初始化对象以保存预测
-
EURUSD <- read.csv('EURUSD.csv', header = T)
-
-
returns <- diff(log(EURUSD$C)) ## ROC也可以使用:默认情况下计算对数
-
-
-
#遍历每个交易日,从滚动窗口中估计最佳模型参数
-
#并预测第二天的收益
-
for (i in 0:forecasts.length) {
-
roll.returns <- returns[(1+i):(window.length + i)] #创建滚动窗口
-
-
-
# 估计最佳ARIMA模型
-
for (p in 0:5) for (q in 0:5) { #将可能的阶限制为p,q <= 5
-
if (p == 0 && q == 0) next #将可能的阶限制为p,q <= 5
-
-
-
current.aic <- AIC(arimaFit)
-
if (current.aic < final.aic) { #如果AIC降低则保留阶数
-
final.aic <- current.aic
-
final.order <- c(p,0,q)
-
final.arima <- arima(roll.returns, order = final.order)
-
}
-
}
-
else next
-
}
-
# 指定并拟合GARCH模型
-
spec = ugarchspec(
-
-
# 指定并拟合GARCH模型
-
# 模型并不总是收敛-在这种情况下,将0值分配给预测值和p.val
-
if (is(fit, "warning")) {
-
forecasts[i+1] <- 0
-
-
-
directions[i+1] <- ifelse(x[1] > 0, 1, -1) #仅定向预测
-
forecasts[i+1] <- x[1] # 预测的实际值
-
print(forecasts[i])
-
# 残差分析
-
resid <- as.numeric(residuals(fit, standardize = TRUE))
-
-
-
}
-
-
-
forecasts.ts <- xts(forecasts, dates[(window.length):length(returns)])
-
# 创建滞后的序列预测
-
-
-
ag.direction <- ifelse(ag.forecasts > 0, 1, ifelse(ag.forecasts < 0, -1, 0))
-
# 创建滞后的序列预测
-
ag.direction.returns <- ag.direction * returns[(window.length):length(returns)]
-
ag.direction.returns[1] <- 0 # remove NA
-
# 创建ARIMA / GARCH买入持有的回测
-
ag.curve <- cumsum( ag.direction.returns)
-
-
-
-
-
# 绘制两条曲线:策略收益和累积收益
-
-
-
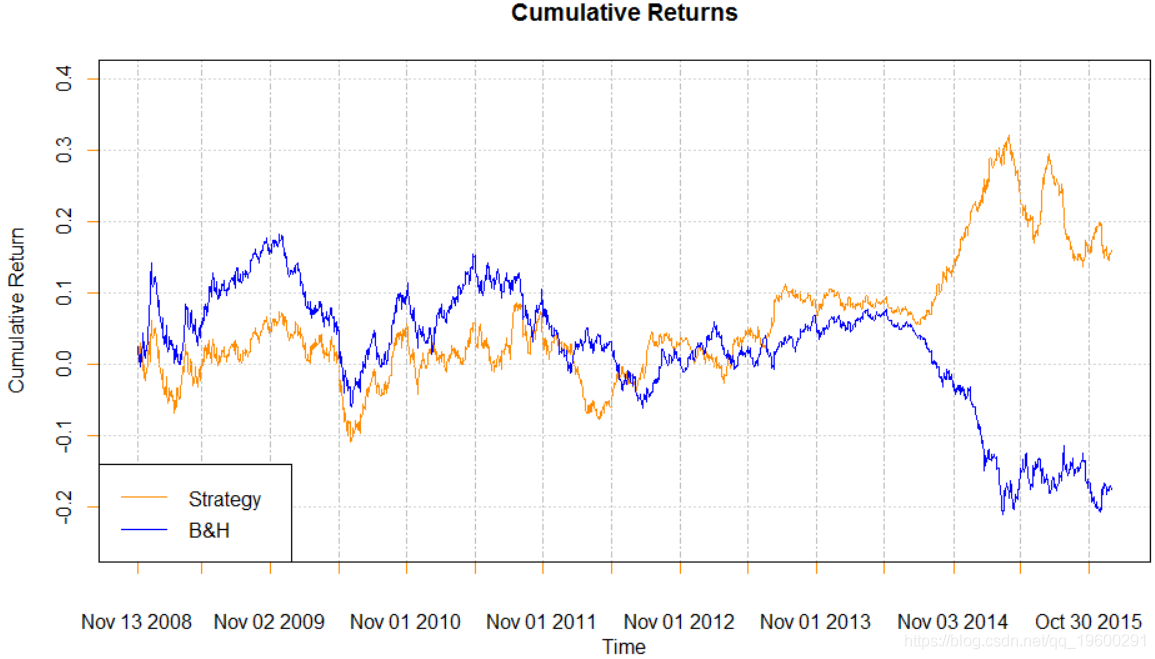
plot(x = both.curves[,"Strategy returns"], xl
首先,仅是方向性预测:在预测正收益时购买,在预测负收益时出售。这种方法的结果如下所示(不包含交易费用): 在上面的模型拟合过程中,我保留了实际的预测收益值以及预测收益的方向。我想研究预测返回值的大小的预测能力。具体来说,当预测回报的幅度低于某个阈值时进行过滤交易会改善策略的性能吗?下面的代码以较小的返回阈值执行此分析。为简单起见,我将预测对数收益率转换为简单收益率,以便能够控制预测的信号并易于实现。
-
# 仅在预测超过阈值幅度时测试进入交易
-
simp.forecasts <- exp(ag.forecasts) - 1
-
-
-
ag.threshold.returns[1] <- 0 # 删除缺失
-
ag.threshold.curve <- cumsum(ag.threshold.returns))
-
-
-
# 绘制两条曲线:策略收益和累积收益
-
plot(x = both.curves[,"Strategy returns"], xlab = "Time", y
结果覆盖了原始策略: 在我看来,我们拟合某段时间的ARIMA / GARCH模型可能比其他时间更好或更糟地表示了基础过程。当我们对模型缺乏信心时,过滤交易可能会改善性能。这种方法要求评估每天模型拟合的统计显着性,并且仅在显着性超过特定阈值时才输入交易。有许多方法可以实现这一点。首先,我们可以检查模型残差的相关图,并在此基础上判断拟合优度。理想情况下,残差的相关图类似于白噪声过程,没有序列相关性。残差的相关图可以在R中构造如下:

-
acf(fit@fit$residuals, main = 'ACF of Model Residuals')
-
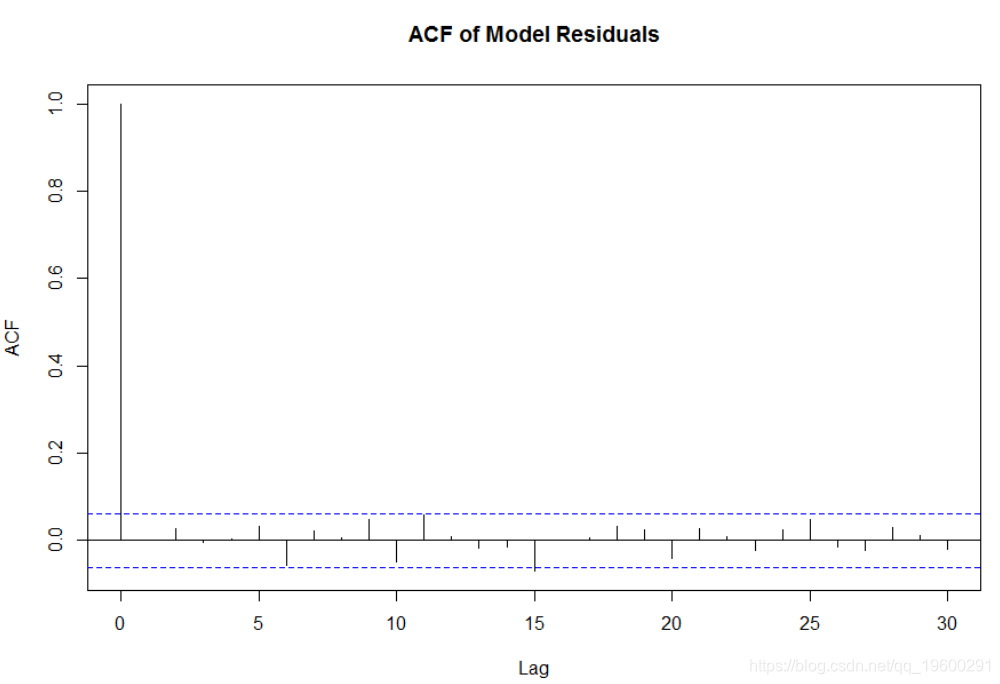
尽管此相关图表明模型拟合良好,但显然它不是一种很好的方法,因为它依赖于主观判断,更不用说人类有能力审查每天的模型。更好的方法是检查Ljung-Box统计量是否适合模型拟合。Ljung-Box是用于评估拟合模型残差的自相关是否与零显着不同的假设检验。在该检验中,零假设是残差的自相关为零;另一种是我们的时间序列分析具有序列相关性。否定空值并确认替代值将意味着该模型不是很好的拟合,因为残差中存在无法解释的结构。Ljung-Box统计量在R中的计算方式如下:
-
-
-
Box-Ljung test
-
data: resid
-
X-squared = 23.099, df = 20, p-value = 0.284
在这种情况下,p值可以证明残差是独立的,并且该特定模型非常合适。作为解释,为了增加残差的自相关,Ljung-Box测试统计量(在上面的代码输出中为X平方)变得更大。p值是在原假设下获得大于或大于检验统计量的值的概率。因此,在这种情况下,高p值是残差独立性的证据。
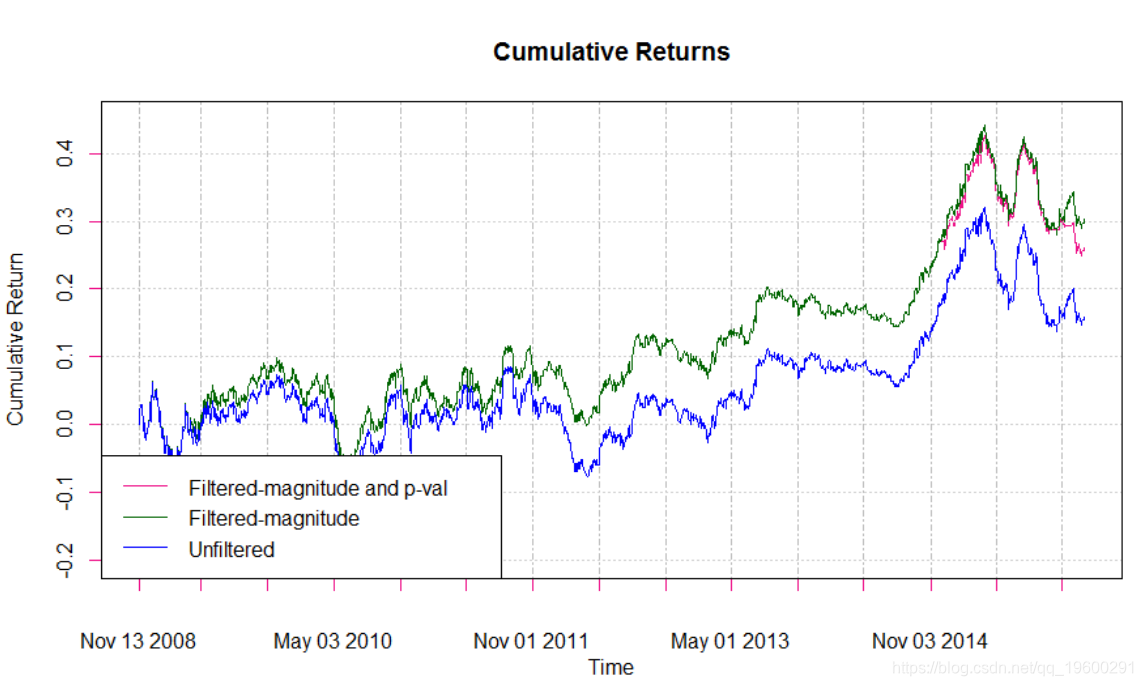
将Ljung-Box检验应用于每天的模型拟合可发现很少几天独立残差的零假设被拒绝,因此将策略扩展为过滤模型拟合不太可能增加太多价值:
时间序列分析结论和未来工作
在回溯测试期间,ARIMA / GARCH策略的表现优于欧元/美元汇率的买入和持有策略,但是,该表现并不出色。似乎可以通过过滤诸如预测幅度和模型拟合优度之类的特征来提高策略的性能,尽管后者在此特定示例中并没有增加太多价值。另一个过滤选项是为每天的预测计算95%的置信区间,并且仅在每个信号相同时才输入交易,尽管这会大大减少实际进行的交易数量。
GARCH模型还有许多其他种类,例如指数,积分,二次,阈值和转换等。与本示例中使用的简单GARCH(1,1)模型相比,这些方法可能会或可能不会更好地表示基础过程。
我最近发现非常有趣的一个研究领域是通过不同模型的智能组合对时间序列进行预测。例如,通过取几个模型的单个预测的平均值,或对预测的信号进行多数表决。要借用一些机器学习的术语,这种“集合”模型通常会比任何组合模型产生更准确的预测。也许有用的方法是使用经过适当训练的人工神经网络或其他统计学习方法来对此处提出的ARIMA / GARCH模型进行预测。也许我们可以期望ARIMA / GARCH模型能够捕获时间序列的任何线性特征,而神经网络可能非常适合非线性特征。
如果您有任何想法可以改善时间序列分析模型的预测准确性,欢迎在下方评论或联系我们。

最受欢迎的见解
1.HAR-RV-J与递归神经网络(RNN)混合模型预测和交易大型股票指数的高频波动率
2.R语言中基于混合数据抽样(MIDAS)回归的HAR-RV模型预测GDP增长
4.R语言ARMA-EGARCH模型、集成预测算法对SPX实际波动率进行预测

