

拓端tecdat|t-GARCH 模型的贝叶斯推断理论
R语言实例链接:http://tecdat.cn/?p=17494
实际处理中,发现金融数据存在尖峰厚尾现象。所以我们选择扰动项服从 t 分布的 t-GARCH 模型来描述波动性过程。t-GARCH(1,1)模型的表达式如下:

模型的参数向量记为 ( , , , ) v ,则模型参数的似然函数可写为:

假定 2 0 是常数,此时,该模型在 t 时刻的条件波动率为:

且方差方程的参数通过以下限制:
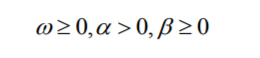
来保证 t h 大于 0。
先验分布
根据Luc和Michel(1998) [28]的工作,对参数 , , 取无信息先验,选取以 0 为中心的柯西 函数的右半部分作为自由度参数v的先验分布:
![]()
后验分布
由贝叶斯公式可知:
![]()
其中,先验密度 ( ) 应该至少满足参数为正的限制和 1 的条件。 (1)假设参数 的先验分布是 (0, ) 90 M1 上的均匀分布,其中 M1 是大于零的常数, 且似然函数的表达式如(2.2)所示,则模型参数 的条件后验分布表达式如下:

(2)假设参数 的先验分布是 (0, ) M2 上的均匀分布,其中 M2 是大于零的常数,且似然 95 函数的表达式如(2.2)所示,则模型参数 的条件后验分布表达式如下:

(3)假设参数 的先验分布是 (0, ) M3 上的均匀分布,其中 M3 是大于零的常数,且 似然函数的表达式如(2.2)所示,则模型参数 的条件后验分布表达式如下:
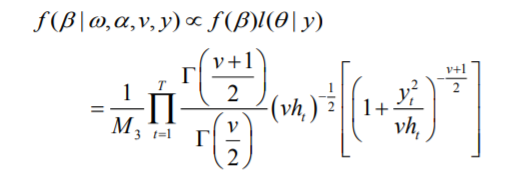
(4)对于参数 v 取半柯西先验(2.5),它是以 0 为中心的柯西函数的右半部分,且似然函数 的表达式如(2.2)所示,所以参数 v 的条件后验分布表达式如下:
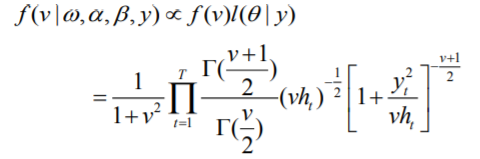
实例分析
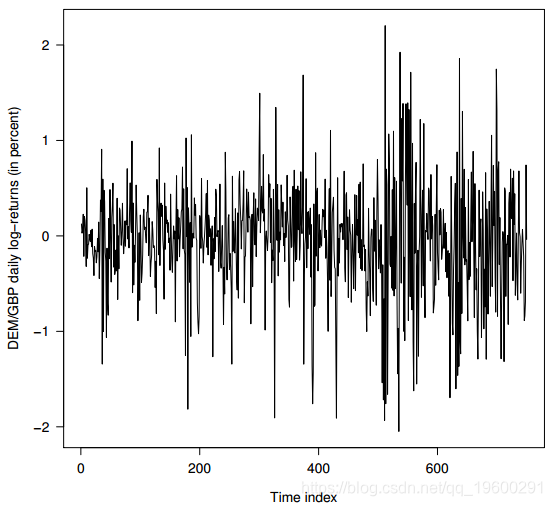
我们将贝叶斯估计方法应用于(DEM / GBP)外汇对数收益率的每日观察值。样本时间为1985年1月3日至1991年12月31日,共1974个观测值。此数据集已被推广为GARCH时间序列软件验证的非正式基准。从这个时间序列中,前750个观测值用于说明贝叶斯方法。我们的数据集中的观察窗口摘录绘制在图1中。
我们对带有Student-t的GARCH(1,1)模型进行了改进,以拟合此观察窗的数据
-
-
function (y, mu.alpha = c(0, 0),
-
Sigma.alpha = 1000 * diag(1,2),
-
mu.beta = 0, Sigma.beta = 1000,
-
lambda = 0.01, delta = 2,
-
control = list())
函数的输入自变量是数据向量,超参数,例如:
• 要生成的MCMC链数;默认值1。
• 每个MCMC链的长度;•start.val:链的起始值的向量;默认值为10000 。
作为贝叶斯估计的先验分布。通过设置控制参数值n.chain = 2和l.chain = 5000,我们为5000次传递生成了两条链。
-
-
> MCMC <- bayg(y, control = list(
-
l.chain = 5000, n.chain = 2))
-
-
chain: 1 iteration: 10
-
parameters: 0.0441 0.212 0.656 115
-
chain: 1 iteration: 20
-
parameters: 0.0346 0.136 0.747 136
-
...
-
chain: 2 iteration: 5000
-
parameters: 0.0288 0.190 0.754 4.67
生成MCMC链的跟踪图(即,迭代与采样值的图)。采样器的收敛(使用Gelman和Rubin(1992)的诊断测试),链中的接受率和自相关可以如下计算:
-
diag
-
-
Point est. 97.5% quantile
-
alpha0 1.02 1.07
-
alpha1 1.01 1.05
-
beta 1.02 1.07
-
nu 1.02 1.06
-
Multivariate psrf
-
1.02
-
-
> 1 - rejectionRate
-
alpha0 alpha1 beta nu
-
0.890 0.890 0.953 1.000
-
>
-
autocorr.diag
-
-
alpha0 alpha1 beta nu
-
Lag 0 1.000 1.000 1.000 1.000
-
Lag 1 0.914 0.872 0.975 0.984
-
Lag 5 0.786 0.719 0.901 0.925
-
Lag 10 0.708 0.644 0.816 0.863
-
Lag 50 0.304 0.299 0.333 0.558
收敛诊断没有显示最后2500次迭代的收敛证据。MCMC采样算法的接受率非常高,从向量a的89%到b的95%不等,这表明分布接近于全部条件。我们丢弃了从MCMC的整体输出中抽样前2500次作为预烧期,仅保留第二次抽样以减少自相关,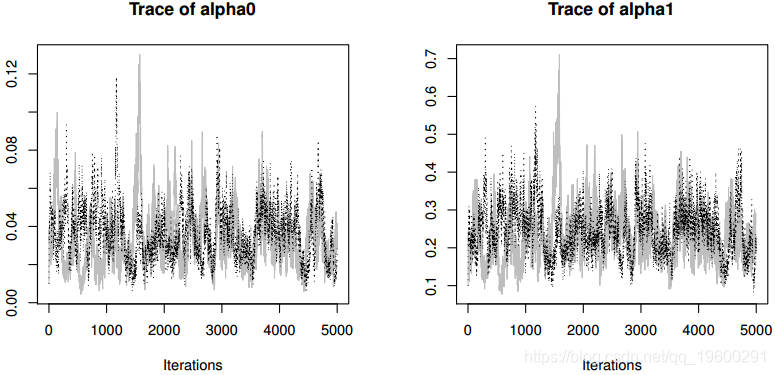
-
> smpl
-
-
n.chain : 2
-
l.chain : 5000
-
l.bi : 2500
-
batch.size: 2
-
smpl size : 2500
基本的后验统计:
-
Iterations = 1:2500
-
Thinning interval = 1
-
Number of chains = 1
-
Sample size per chain = 2500
-
1. Empirical mean and standard deviation
-
for each variable, plus standard error
-
of the mean:
-
-
Mean SD Naive SE Time-series SE
-
alpha0 0.0345 0.0138 0.000277 0.00173
-
alpha1 0.2360 0.0647 0.001293 0.00760
-
beta 0.6832 0.0835 0.001671 0.01156
-
nu 6.4019 1.5166 0.030333 0.19833
每个变量的分位数:
-
2.5% 25% 50% 75% 97.5%
-
alpha0 0.0126 0.024 0.0328 0.0435 0.0646
-
alpha1 0.1257 0.189 0.2306 0.2764 0.3826
-
beta 0.5203 0.624 0.6866 0.7459 0.8343
-
nu 4.2403 5.297 6.1014 7.2282 10.1204
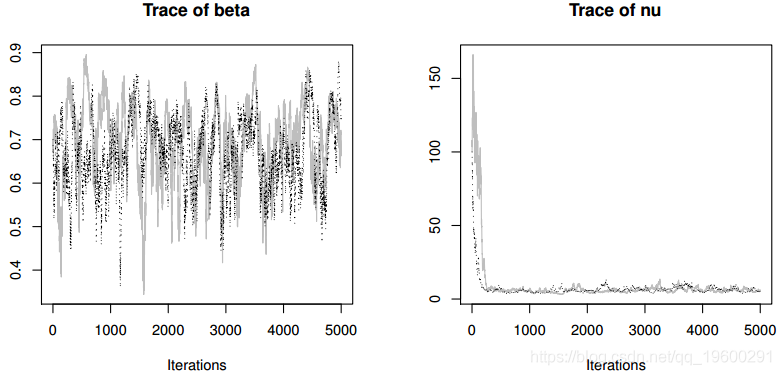
通过首先将输出转换为矩阵,然后使用函数hist,可以获取模型参数的边际分布。
边缘后部密度显示在图3中。我们清楚地注意到直方图的不对称形状。对于参数n尤其如此。后平均值和中位数之间的差异也反映了这一点。这些结果应该警告我们,不要滥用渐近论证。在当前情况下,即使是750次观测也不足以证明参数估计量分布的渐近对称正态近似。
可以通过从联合后验样本中进行仿真来直接获得关于模型参数的非线性函数的概率陈述。
特别是,我们可以测试协方差平稳性条件,并在满足该条件时估计无条件方差的密度。根据GARCH(1,1)规范,如果a1 + b <1,则过程是协方差平稳的。值接近1时,过去的冲击和过去的方差将对未来的条件方差产生更长的影响。
为了推断平方过程的持久性,我们仅使用后验样本,并为后验样本中的每个绘制y [j]生成(a1 [j] + b [j])。持久性的后部密度绘制在图4中。直方图向左倾斜,中值为0.923,最大值为1.050。假设a1 + b <1,则GARCH(1,1)模型的无条件方差为a0 /(1- a1- b)。条件是存在时,后验均值为0.387,90%可信区间为[0.274,1.378 ]。经验方差为0.323。
使用联合后验样本可以获得关于模型参数的其他概率陈述。使用后验样本,我们估计条件峰度存在的后验概率为0.994。在存在条件下,峰度的后均值为8.21,中位数为5.84,对区间的95%置信度为[4.12,15.81],表明尾部比正态分布更重。条件峰度的后验正偏是由几个非常大的值(最大模拟值为404.90)引起的。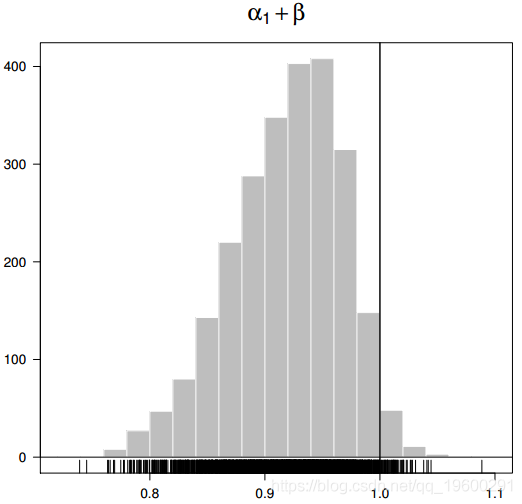
先前的限制和常规改进
控制参数addPriorConditions可用于在估计期间对模型参数y施加任何类型的约束。例如,为了确保估计协方差平稳GARCH(1,1)模型,应将函数定义为
-
p<-function(psi)
-
+ psi[2] + psi[3] < 1
实用建议
该算法中实施的估算策略是全自动的,不需要对MCMC采样器进行任何调整。对于从业者来说,这无疑是一个吸引人的功能。但是,马尔可夫链的生成非常耗时,因此每天在多个数据集上估算模型可能会花费大量时间。在这种情况下,通过在多个处理器上运行单链可以轻松地使算法并行化。例如,可以使用foreach包轻松实现此目标(Revolution Computing,2010)。同样,当估计值在更新的时间序列(即具有最近观测值的时间序列)上重复时,明智的做法是使用在前一个估计步骤获得的参数的后验均值或中值来启动算法。初始值(预烧阶段)的影响可能较小,因此收敛速度更快。最后,请注意,与任何MH算法一样,采样器可能会卡在给定的值上,因此链不再移动。

总结
本说明介绍了Student-t改进对GARCH(1,1)模型的贝叶斯估计。我们举例说明了在汇率对数收益率上的实证应用。
