

拓端tecdat|TensorFlow 2建立神经网络分类模型
原文链接:http://tecdat.cn/?p=15791
本文将利用机器学习的手段来对鸢尾花按照物种进行分类。本教程将利用 TensorFlow 来进行以下操作:
- 构建一个模型,
- 用样例数据集对模型进行训练,以及
- 利用该模型对未知数据进行预测。
TensorFlow 编程
本指南采用了以下高级 TensorFlow 概念:
- 使用 TensorFlow 默认的 eager execution 开发环境,
- 使用 Datasets API 导入数据,
- 使用 TensorFlow 的 Keras API 来构建各层以及整个模型。
本教程的结构同很多 TensorFlow 程序相似:
- 数据集的导入
- 选择模型类型
- 对模型进行训练
- 评估模型效果
- 使用训练过的模型进行预测
环境的搭建
配置导入
导入 TensorFlow 以及其他需要的 Python 库。 默认情况下,TensorFlow 用 eager execution 来实时评估操作。
-
from __future__ import absolute_import, division, print_function, unicode_literals
-
-
import os
-
import matplotlib.pyplot as plt
import tensorflow as tf
-
print("TensorFlow version: {}".format(tf.__version__))
-
print("Eager execution: {}".format(tf.executing_eagerly()))
-
TensorFlow version: 2.0.0
-
Eager execution: True
鸢尾花分类问题
想象一下,您是一名植物学家,正在寻找一种能够对所发现的每株鸢尾花进行自动归类的方法。机器学习可提供多种从统计学上分类花卉的算法。例如,一个复杂的机器学习程序可以根据照片对花卉进行分类。我们将根据鸢尾花花萼和花瓣的长度和宽度对其进行分类。
鸢尾属约有 300 个品种,但我们的程序将仅对下列三个品种进行分类:
- 山鸢尾
- 维吉尼亚鸢尾
- 变色鸢尾

导入和解析训练数据集
下载数据集文件并将其转换为可供此 Python 程序使用的结构。
下载数据集
使用 tf.keras.utils.get_file 函数下载训练数据集文件。该函数会返回下载文件的文件路径:
-
- 0s 0us/step
-
Local copy of the dataset file: /home/kbuilder/.keras/datasets/iris_training.csv
检查数据
数据集 iris_training.csv 是一个纯文本文件,其中存储了逗号分隔值 (CSV) 格式的表格式数据.请使用 head -n5 命令查看前 5 个条目:
!head -n5 {train_dataset_fp}
-
120,4,setosa,versicolor,virginica
-
6.4,2.8,5.6,2.2,2
-
5.0,2.3,3.3,1.0,1
-
4.9,2.5,4.5,1.7,2
-
4.9,3.1,1.5,0.1,0
我们可以从该数据集视图中注意到以下信息:
- 第一行是表头,其中包含数据集信息:
- 共有 120 个样本。每个样本都有四个特征和一个标签名称,标签名称有三种可能。
- 后面的行是数据记录,每个样本各占一行,其中:
我们用代码表示出来:
-
# CSV文件中列的顺序
-
-
-
print("Features: {}".format(feature_names))
-
print("Label: {}".format(label_name))
-
Features: ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
-
Label: species
每个标签都分别与一个字符串名称(例如 “setosa” )相关联,但机器学习通常依赖于数字值。标签编号会映射到一个指定的表示法,例如:
0: 山鸢尾1: 变色鸢尾2: 维吉尼亚鸢尾
创建一个 tf.data.Dataset
TensorFlow的 Dataset API 可处理在向模型加载数据时遇到的许多常见情况。这是一种高阶 API ,用于读取数据并将其转换为可供训练使用的格式。
由于数据集是 CSV 格式的文本文件,请使用 make_csv_dataset 函数将数据解析为合适的格式。由于此函数为训练模型生成数据,默认行为是对数据进行随机处理 (shuffle=True, shuffle_buffer_size=10000),并且无限期重复数据集(num_epochs=None)。 我们还设置了 batch_size 参数:
-
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.6/site-packages/tensorflow_core/python/data/experimental/ops/readers.py:521: parallel_interleave (from tensorflow.python.data.experimental.ops.interleave_ops) is deprecated and will be removed in a future version.
-
Instructions for updating:
-
Use `tf.data.Dataset.interleave(map_func, cycle_length, block_length, num_parallel_calls=tf.data.experimental.AUTOTUNE)` instead. If sloppy execution is desired, use `tf.data.Options.experimental_determinstic`.
make_csv_dataset 返回一个(features, label) 对构建的 tf.data.Dataset ,其中 features 是一个字典: {'feature_name': value}
这些 Dataset 对象是可迭代的。 我们来看看下面的一些特征:
-
OrderedDict([('sepal_length', <tf.Tensor: id=68, shape=(32,), dtype=float32, numpy=
-
array([6.7, 6.1, 6.6, 6.7, 5.4, 5.5, 5.1, 5.8, 5.2, 6.4, 7.3, 4.9, 6.1,
-
4.6, 4.6, 5.5, 6.7, 6. , 5.7, 6. , 7.7, 5. , 5.8, 5. , 4.5, 5.1,
-
5.3, 5.6, 5.2, 6.4, 6.6, 4.6], dtype=float32)>), ('sepal_width', <tf.Tensor: id=69, shape=(32,), dtype=float32, numpy=
-
array([3. , 2.6, 3. , 3. , 3.4, 2.6, 3.7, 2.7, 2.7, 3.2, 2.9, 2.4, 2.8,
-
3.4, 3.6, 2.4, 3.1, 2.9, 2.8, 2.2, 3.8, 3.3, 2.7, 3.2, 2.3, 2.5,
-
3.7, 2.5, 3.4, 2.8, 2.9, 3.2], dtype=float32)>), ('petal_length', <tf.Tensor: id=66, shape=(32,), dtype=float32, numpy=
-
array([5.2, 5.6, 4.4, 5. , 1.5, 4.4, 1.5, 4.1, 3.9, 5.3, 6.3, 3.3, 4. ,
-
1.4, 1. , 3.7, 5.6, 4.5, 4.5, 5. , 6.7, 1.4, 5.1, 1.2, 1.3, 3. ,
-
1.5, 3.9, 1.4, 5.6, 4.6, 1.4], dtype=float32)>), ('petal_width', <tf.Tensor: id=67, shape=(32,), dtype=float32, numpy=
-
array([2.3, 1.4, 1.4, 1.7, 0.4, 1.2, 0.4, 1. , 1.4, 2.3, 1.8, 1. , 1.3,
-
0.3, 0.2, 1. , 2.4, 1.5, 1.3, 1.5, 2.2, 0.2, 1.9, 0.2, 0.3, 1.1,
-
0.2, 1.1, 0.2, 2.2, 1.3, 0.2], dtype=float32)>)])
注意到具有相似特征的样本会归为一组,即分为一批。更改 batch_size 可以设置存储在这些特征数组中的样本数。
绘制该批次中的几个特征后,就会开始看到一些集群现象:
-
plt.scatter(features['petal_length'],
-
features['sepal_length'],
-
c=labels,
-
cmap='viridis')
-
-
plt.xlabel("Petal length")
-
plt.ylabel("Sepal length")
-
plt.show()
要简化模型构建步骤,请创建一个函数以将特征字典重新打包为形状为 (batch_size, num_features) 的单个数组。
此函数使用 tf.stack 方法,该方法从张量列表中获取值,并创建指定维度的组合张量:
-
def pack_features_vector(features, labels):
-
"""将特征打包到一个数组中"""
-
features = tf.stack(list(features.values()), axis=1)
-
return features, labels
然后使用 tf.data.Dataset.map 方法将每个 (features,label) 对中的 features 打包到训练数据集中:
train_dataset = train_dataset.map(pack_features_vector)
Dataset 的特征元素被构成了形如 (batch_size, num_features) 的数组。
选择模型类型
为何要使用模型?
模型是指特征与标签之间的关系。对于鸢尾花分类问题,模型定义了花萼和花瓣测量值与预测的鸢尾花品种之间的关系。一些简单的模型可以用几行代数进行描述,但复杂的机器学习模型拥有大量难以汇总的参数。
您能否在不使用机器学习的情况下确定四个特征与鸢尾花品种之间的关系?也就是说,您能否使用传统编程技巧(例如大量条件语句)创建模型?也许能,前提是反复分析该数据集,并最终确定花瓣和花萼测量值与特定品种的关系。对于更复杂的数据集来说,这会变得非常困难,或许根本就做不到。一个好的机器学习方法可为您确定模型。如果您将足够多的代表性样本馈送到正确类型的机器学习模型中,该程序便会为您找出相应的关系。
选择模型
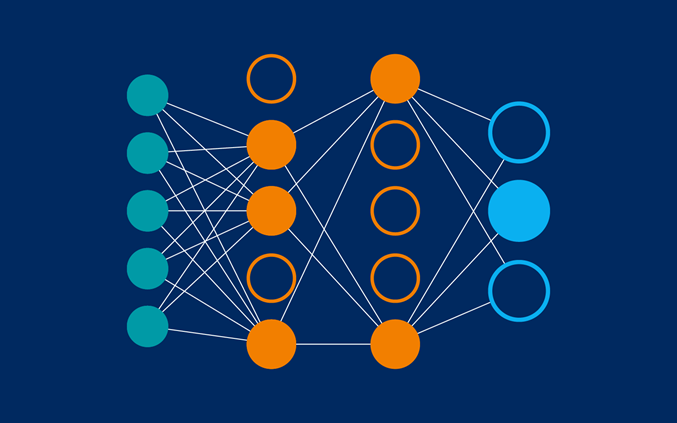
我们需要选择要进行训练的模型类型。模型具有许多类型,挑选合适的类型需要一定的经验。本教程使用神经网络来解决鸢尾花分类问题。神经网络可以发现特征与标签之间的复杂关系。神经网络是一个高度结构化的图,其中包含一个或多个隐含层。每个隐含层都包含一个或多个神经元。 神经网络有多种类别,该程序使用的是密集型神经网络,也称为全连接神经网络 : 一个层中的神经元将从上一层中的每个神经元获取输入连接。例如,图 2 显示了一个密集型神经网络,其中包含 1 个输入层、2 个隐藏层以及 1 个输出层:
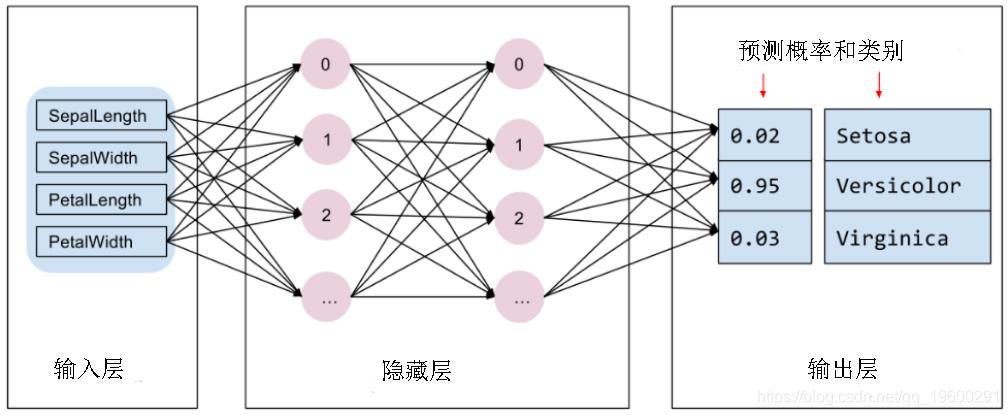
当图 2 中的模型经过训练并获得无标签样本后,它会产生 3 个预测结果:相应鸢尾花属于指定品种的可能性。这种预测称为推理。对于该示例,输出预测结果的总和是 1.0。在图 2 中,该预测结果分解如下:山鸢尾为 0.02,变色鸢尾为 0.95,维吉尼亚鸢尾为 0.03。这意味着该模型预测某个无标签鸢尾花样本是变色鸢尾的概率为 95%。
使用 Keras 创建模型
TensorFlow tf.keras API 是创建模型和层的首选方式。通过该 API,您可以轻松地构建模型并进行实验,而将所有部分连接在一起的复杂工作则由 Keras 处理。
tf.keras.Sequential 模型是层的线性堆叠。该模型的构造函数会采用一系列层实例;在本示例中,采用的是 2 个密集层(各自包含10个节点),以及 1 个输出层(包含 3 个代表标签预测的节点。第一个层的 input_shape 参数对应该数据集中的特征数量,它是一项必需参数:
-
model = tf.keras.Sequential([
-
tf.keras.layers.Dense(10, activation=tf.nn.relu, input_shape=(4,)), # 需要给出输入的形式
-
tf.keras.layers.Dense(10, activation=tf.nn.relu),
-
tf.keras.layers.Dense(3)
-
])
激活函数可决定层中每个节点的输出形式。 这些非线性关系很重要,如果没有它们,模型将等同于单个层。激活函数有很多种,但隐藏层通常使用 ReLU。
隐藏层和神经元的理想数量取决于问题和数据集。与机器学习的多个方面一样,选择最佳的神经网络形状需要一定的知识水平和实验基础。一般来说,增加隐藏层和神经元的数量通常会产生更强大的模型,而这需要更多数据才能有效地进行训练。
使用模型
我们快速了解一下此模型如何处理一批特征:
-
<tf.Tensor: id=231, shape=(5, 3), dtype=float32, numpy=
-
array([[-0.40338838, 0.01194552, -1.964499 ],
-
[-0.5877474 , 0.02103703, -2.9969394 ],
-
[-0.40222907, 0.35343137, -0.7817157 ],
-
[-0.4376807 , 0.40464264, -0.8379218 ],
-
[-0.39644662, 0.31841943, -0.8436158 ]], dtype=float32)>
在此示例中,每个样本针对每个类别返回一个 logit。
要将这些对数转换为每个类别的概率:
-
<tf.Tensor: id=236, shape=(5, 3), dtype=float32, numpy=
-
array([[0.36700222, 0.55596304, 0.07703481],
-
[0.3415203 , 0.62778115, 0.03069854],
-
[0.2622449 , 0.55832386, 0.17943124],
-
[0.25050646, 0.58161455, 0.167879 ],
-
[0.27149206, 0.5549062 , 0.17360175]], dtype=float32)>
对每个类别执行 tf.argmax 运算可得出预测的类别索引。不过,该模型尚未接受训练,因此这些预测并不理想。
-
print("Prediction: {}".format(tf.argmax(predictions, axis=1)))
-
print(" Labels: {}".format(labels))
-
Prediction: [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
-
Labels: [1 2 0 0 0 2 0 1 0 2 0 0 2 2 2 2 1 2 2 1 2 0 2 1 0 2 2 1 1 1 2 2]
训练模型
训练 是一个机器学习阶段,在此阶段中,模型会逐渐得到优化,也就是说,模型会了解数据集。目标是充分了解训练数据集的结构,以便对测试数据进行预测。如果您从训练数据集中获得了过多的信息,预测便会仅适用于模型见过的数据,但是无法泛化。此问题被称之为过拟合—就好比将答案死记硬背下来,而不去理解问题的解决方式。
鸢尾花分类问题是监督式机器学习的一个示例: 模型通过包含标签的样本加以训练。 而在非监督式机器学习中,样本不包含标签。相反,模型通常会在特征中发现一些规律。
定义损失和梯度函数
在训练和评估阶段,我们都需要计算模型的损失。 这样可以衡量模型的预测结果与预期标签有多大偏差,也就是说,模型的效果有多差。我们希望尽可能减小或优化这个值。
我们的模型会使用 tf.keras.losses.SparseCategoricalCrossentropy 函数计算其损失,此函数会接受模型的类别概率预测结果和预期标签,然后返回样本的平均损失。
Loss test: 2.1644210815429688
使用 tf.GradientTape 的前后关系来计算梯度以优化你的模型。
创建优化器
优化器 会将计算出的梯度应用于模型的变量,以使 loss 函数最小化。您可以将损失函数想象为一个曲面,我们希望通过到处走动找到该曲面的最低点。梯度指向最高速上升的方向,因此我们将沿相反的方向向下移动。我们以迭代方式计算每个批次的损失和梯度,以在训练过程中调整模型。模型会逐渐找到权重和偏差的最佳组合,从而将损失降至最低。损失越低,模型的预测效果就越好。
TensorFlow有许多可用于训练的优化算法。learning_rate 被用于设置每次迭代(向下行走)的步长。 这是一个 超参数 ,您通常需要调整此参数以获得更好的结果。
我们来设置优化器:
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
我们将使用它来计算单个优化步骤:
-
Step: 0, Initial Loss: 2.1644210815429688
-
Step: 1, Loss: 1.8952136039733887
训练循环
一切准备就绪后,就可以开始训练模型了!训练循环会将数据集样本馈送到模型中,以帮助模型做出更好的预测。以下代码块可设置这些训练步骤:
- 迭代每个周期。通过一次数据集即为一个周期。
- 在一个周期中,遍历训练
Dataset中的每个样本,并获取样本的特征(x)和标签(y)。 - 根据样本的特征进行预测,并比较预测结果和标签。衡量预测结果的不准确性,并使用所得的值计算模型的损失和梯度。
- 使用
optimizer更新模型的变量。 - 跟踪一些统计信息以进行可视化。
- 对每个周期重复执行以上步骤。
num_epochs 变量是遍历数据集集合的次数。与直觉恰恰相反的是,训练模型的时间越长,并不能保证模型就越好。num_epochs 是一个可以调整的超参数。选择正确的次数通常需要一定的经验和实验基础。
-
## Note: 使用相同的模型变量重新运行此单元
-
-
# 保留结果用于绘制
-
train_loss_results = []
-
train_accuracy_results = []
-
-
num_epochs = 201
-
-
for x, y in train_dataset:
-
# 优化模型
-
loss_value, grads = grad(model, x, y)
-
optimizer.apply_gradients(zip(grads, model.trainable_variables))
-
-
# 追踪进度
-
epoch_loss_avg(loss_value) # 添加当前的 batch loss
-
# 比较预测标签与真实标签
-
epoch_accuracy(y, model(x))
-
-
# 循环结束
-
train_loss_results.append(epoch_loss_avg.result())
-
train_accuracy_results.append(epoch_accuracy.result())
-
-
-
Epoch 000: Loss: 1.435, Accuracy: 30.000%
-
Epoch 050: Loss: 0.091, Accuracy: 97.500%
-
Epoch 100: Loss: 0.062, Accuracy: 97.500%
-
Epoch 150: Loss: 0.052, Accuracy: 98.333%
-
Epoch 200: Loss: 0.055, Accuracy: 99.167%
可视化损失函数随时间推移而变化的情况
虽然输出模型的训练过程有帮助,但查看这一过程往往更有帮助。
看到损失下降且准确率上升。
-
-
plt.show()
评估模型的效果
模型已经过训练,现在我们可以获取一些关于其效果的统计信息了。
评估 指的是确定模型做出预测的效果。要确定模型在鸢尾花分类方面的效果,请将一些花萼和花瓣测量值传递给模型,并要求模型预测它们所代表的鸢尾花品种。然后,将模型的预测结果与实际标签进行比较。例如,如果模型对一半输入样本的品种预测正确,则 准确率 为 0.5 。 图 显示的是一个效果更好一些的模型,该模型做出 5 次预测,其中有 4 次正确,准确率为 80%:
| 样本特征 | 标签 | 模型预测 | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0.5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| 图 . 准确率为 80% 的鸢尾花分类器 |
建立测试数据集
评估模型与训练模型相似。最大的区别在于,样本来自一个单独的测试集,而不是训练集。为了公正地评估模型的效果,用于评估模型的样本务必与用于训练模型的样本不同。
测试 Dataset 的建立与训练 Dataset 相似。下载 CSV 文本文件并解析相应的值,然后对数据稍加随机化处理:
-
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/iris_test.csv
-
8192/573 [============================================================================================================================================================================================================================================================================================================================================================================================================================================] - 0s 0us/step
根据测试数据集评估模型
在以下代码单元格中,我们会遍历测试集中的每个样本,然后将模型的预测结果与实际标签进行比较。这是为了衡量模型在整个测试集中的准确率。
-
-
print("Test set accuracy: {:.3%}".format(test_accuracy.result()))
Test set accuracy: 96.667%
例如,我们可以看到对于最后一批数据,该模型通常预测正确:
-
<tf.Tensor: id=115075, shape=(30, 2), dtype=int32, numpy=
-
array([[1, 1],
-
[2, 2],
-
[0, 0],
-
[1, 1],
-
[1, 1],
-
[1, 1],
-
[0, 0],
-
[2, 1],
-
[1, 1],
-
[2, 2],
-
[2, 2],
-
[0, 0],
-
[2, 2],
-
[1, 1],
-
[1, 1],
-
[0, 0],
-
[1, 1],
-
[0, 0],
-
[0, 0],
-
[2, 2],
-
[0, 0],
-
[1, 1],
-
[2, 2],
-
[1, 1],
-
[1, 1],
-
[1, 1],
-
[0, 0],
-
[1, 1],
-
[2, 2],
-
[1, 1]], dtype=int32)>
使用经过训练的模型进行预测
我们已经训练了一个模型并“证明”它是有效的,但在对鸢尾花品种进行分类方面,这还不够。现在,我们使用经过训练的模型对 无标签样本(即包含特征但不包含标签的样本)进行一些预测。
在现实生活中,无标签样本可能来自很多不同的来源,包括应用、CSV 文件和数据。暂时我们将手动提供三个无标签样本以预测其标签。回想一下,标签编号映射表示法:
0: 山鸢尾1: 变色鸢尾2: 维吉尼亚鸢尾
-
-
for i, logits in enumerate(predictions):
-
class_idx = tf.argmax(logits).numpy()
-
p = tf.nn.softmax(logits)[class_idx]
-
name = class_names[class_idx]
-
print("Example {} prediction: {} ({:4.1f}%)".format(i, name, 100*p))
-
Example 0 prediction: Iris setosa (99.9%)
-
Example 1 prediction: Iris versicolor (100.0%)
-
Example 2 prediction: Iris virginica (96.2%)
参考文献
1.r语言用神经网络改进nelson-siegel模型拟合收益率曲线分析
3.python用遗传算法-神经网络-模糊逻辑控制算法对乐透分析
4.用于nlp的python:使用keras的多标签文本lstm神经网络分类
