

拓端tecdat|R语言中广义线性模型(GLM)中的分布和连接函数分析
原文链接:http://tecdat.cn/?p=14874

通常,GLM的连接函数可能比分布更重要。为了说明,考虑以下数据集,其中包含5个观察值
-
x = c(1,2,3,4,5)
-
y = c(1,2,4,2,6)
-
base = data.frame(x,y)
然后考虑具有不同分布的几个模型,以及一个链接
-
regNId = glm(y~x,family=gaussian(link="identity"),data=base)
-
regNlog = glm(y~x,family=gaussian(link="log"),data=base)
-
regPId = glm(y~x,family=poisson(link="identity"),data=base)
-
regPlog = glm(y~x,family=poisson(link="log"),data=base)
-
regGId = glm(y~x,family=Gamma(link="identity"),data=base)
-
regGlog = glm(y~x,family=Gamma(link="log"),data=base)
-
regIGId = glm(y~x,family=inverse.gaussian(link="identity"),data=base)
-
regIGlog = glm(y~x,family=inverse.gaussian(link="log"),data=base
还可以考虑一些Tweedie分布,甚至更一般
考虑使用线性链接函数在第一种情况下获得的预测
-
-
plot(x,y,pch=19)
-
abline(regNId,col=darkcols[1])
-
abline(regPId,col=darkcols[2])
-
abline(regGId,col=darkcols[3])
-
abline(regIGId,col=darkcols[4])
-
abline(regTwId,lty=2)
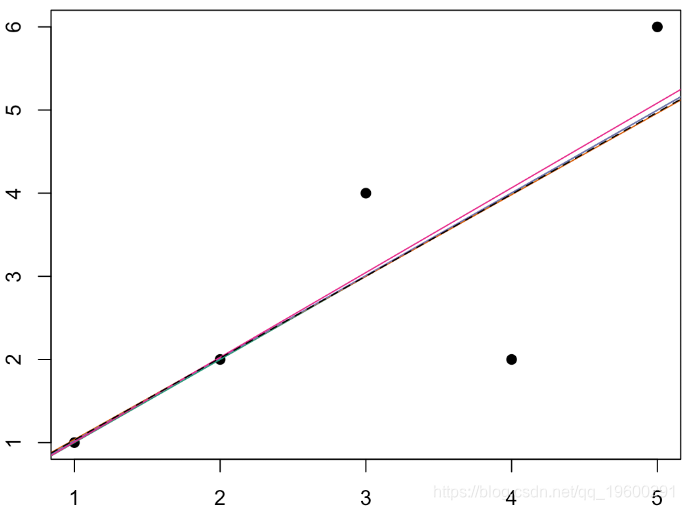
这些预测非常接近。在指数预测的情况下,我们获得

我们实际上可以近距离看。例如,在线性情况下,考虑使用Tweedie模型获得的斜率(实际上将包括此处提到的所有参数famile)
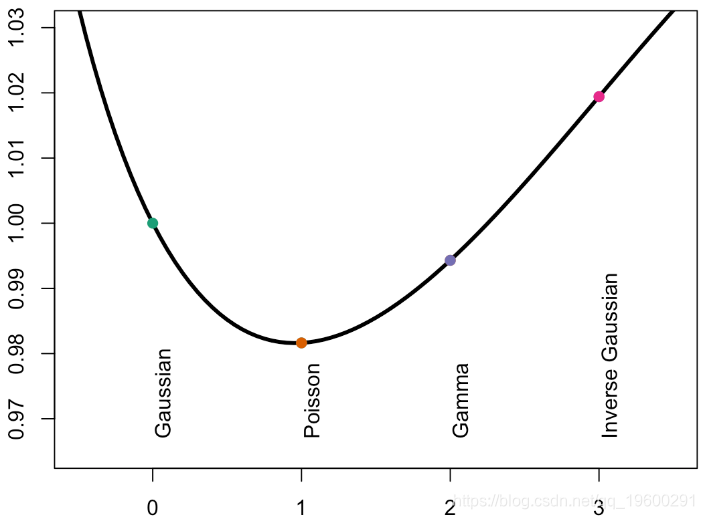
这里的坡度总是非常接近,如果我们添加一个置信区间,则
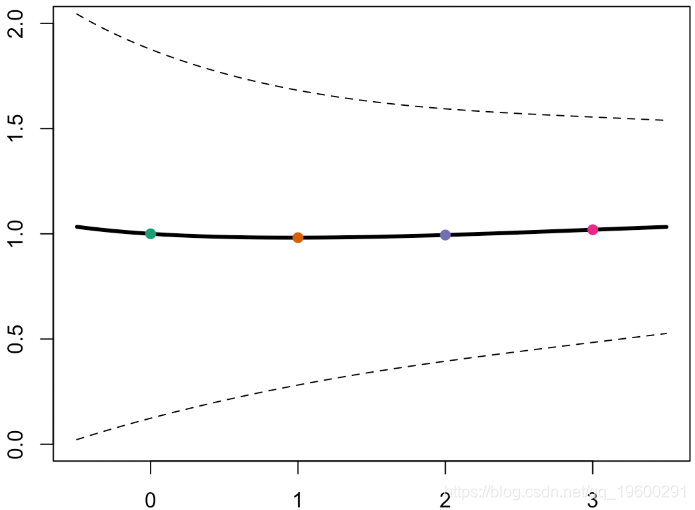
对于Gamma回归或高斯逆回归,由于方差是预测的幂,因此,如果预测较小,则方差应该较小。因此,在图的左侧,误差应该较小,并且方差函数的功效更高。
-
-
-
-
-
plot(Vgamma,Verreur,type="l",lwd=3,ylim=c(-.1,.04),xlab="power",ylab="error")
-
abline(h=0,lty=2)
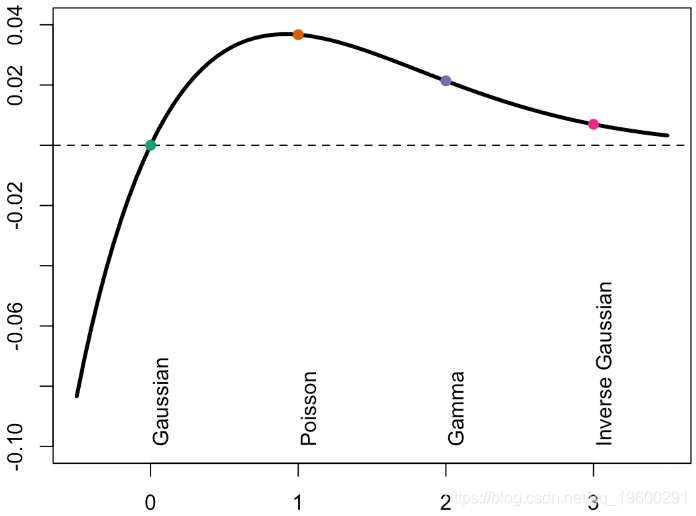
当然,我们可以对指数模型做同样的事情
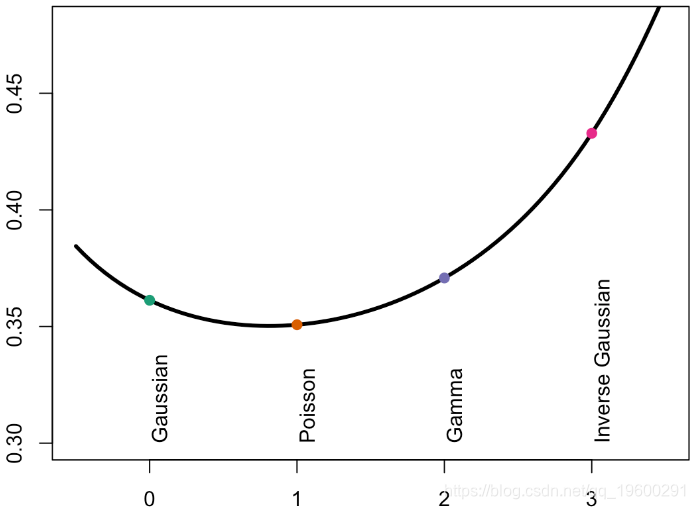
或者,如果我们添加置信区间,我们将获得
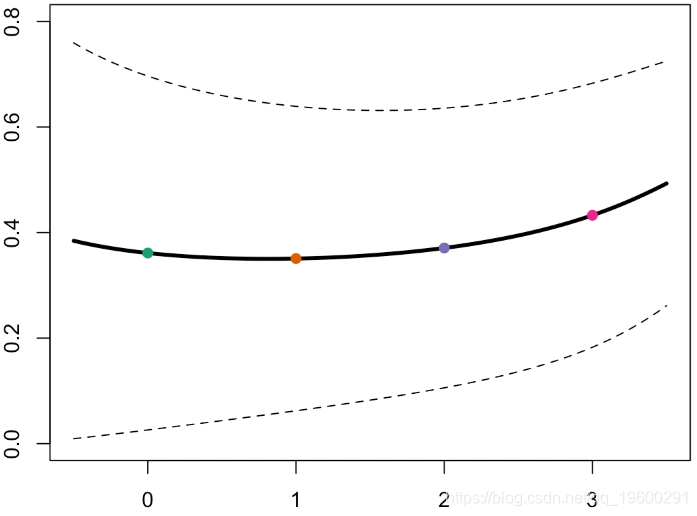
因此,这里的“斜率”也非常相似...如果我们看一下在图表左侧产生的误差,可以得出
-
-
plot(Vgamma,Verreur,type="l",lwd=3,ylim=c(.001,.32),xlab="power",ylab="error")
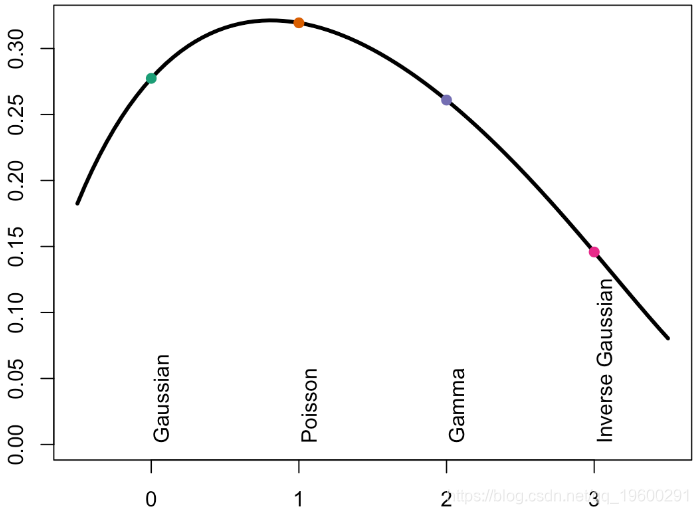
因此,分布通常也不是GLM上最重要的一点。
▍关注我们
【大数据部落】第三方数据服务提供商,提供全面的统计分析与数据挖掘咨询服务,为客户定制个性化的数据解决方案与行业报告等。
▍咨询链接:http://y0.cn/teradat
▍联系邮箱:3025393450@qq.com


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 没有源码,如何修改代码逻辑?
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· [.NET]调用本地 Deepseek 模型
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· .NET Core 托管堆内存泄露/CPU异常的常见思路
· DeepSeek “源神”启动!「GitHub 热点速览」
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· C# 集成 DeepSeek 模型实现 AI 私有化(本地部署与 API 调用教程)
· DeepSeek R1 简明指南:架构、训练、本地部署及硬件要求
· 2 本地部署DeepSeek模型构建本地知识库+联网搜索详细步骤