



拓端tecdat|用Rapidminer编程指导做文本挖掘的应用:情感分析
情感分析或观点挖掘是文本分析的一种应用,用于识别和提取源数据中的主观信息。
情感分析的基本任务是将文档,句子或实体特征中表达的观点分类为肯定或否定。本教程介绍了Rapidminer中情感分析的用法。此处提供的示例给出了电影列表及其评论,例如“ 正面” 或“ 负面”。该程序实现了Precision and Recall方法。 精度 是(随机选择的)检索文档相关的概率。 召回 是在搜索中检索到(随机选择的)相关文档的概率。高 召回率 意味着算法返回了大多数相关结果。精度高 表示算法返回的相关结果多于不相关的结果。
首先,对某部电影进行正面和负面评论。然后,单词以不同的极性(正负)存储。矢量单词表和模型均已创建。然后,将所需的电影列表作为输入。模型将给定电影列表中的每个单词与先前存储的具有不同极性的单词进行比较。电影评论是根据极性下出现的大多数单词来估算的。例如,当查看Django Unchained时,会将评论与开头创建的矢量单词表进行比较。最多的单词属于正极性。因此结果是肯定的。负面结果也是如此。
进行此分析的第一步是从数据中处理文档,即提取电影的正面和负面评论并将其以不同极性存储。该模型如图1所示。
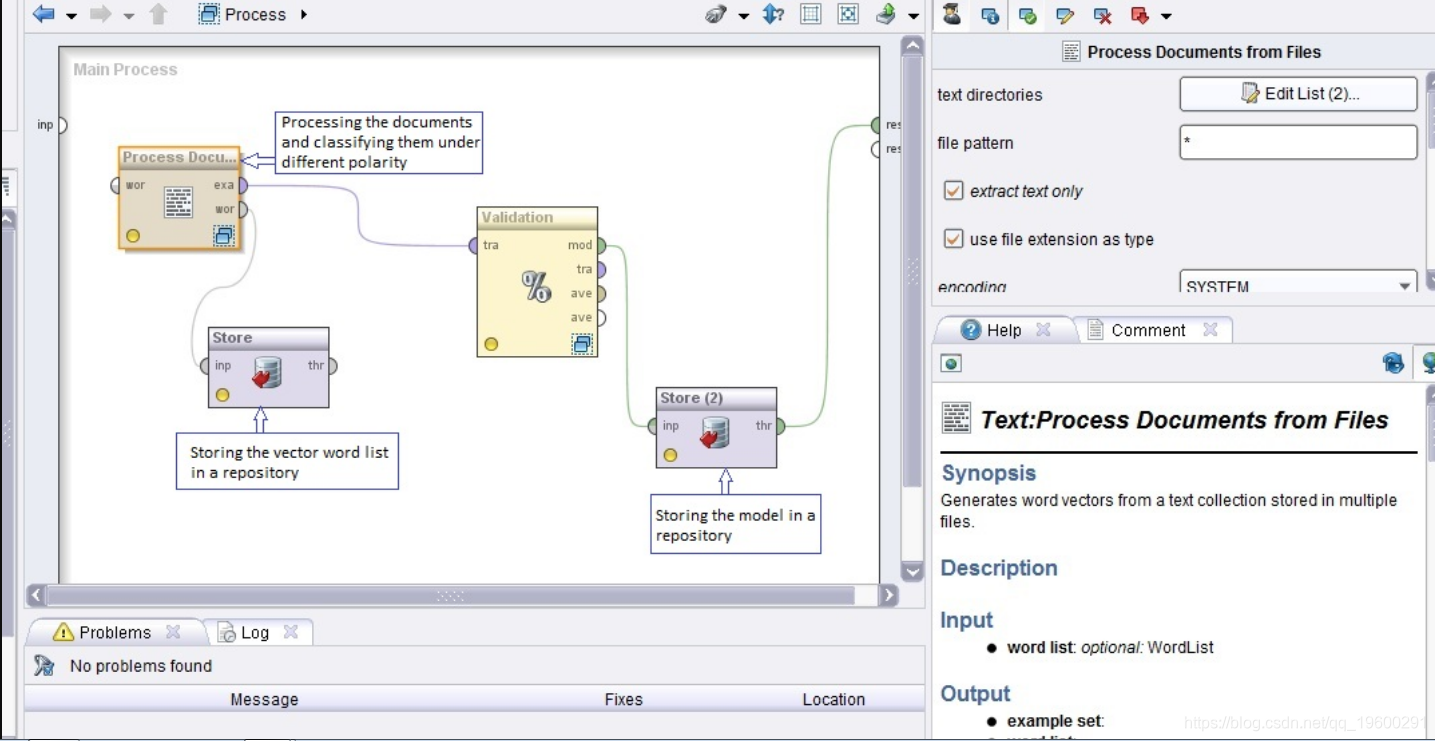
图1
在“处理文档”下,单击右侧的“编辑列表”。在不同的类名称“ Positive”和“ Negative”下加载肯定和否定评论。
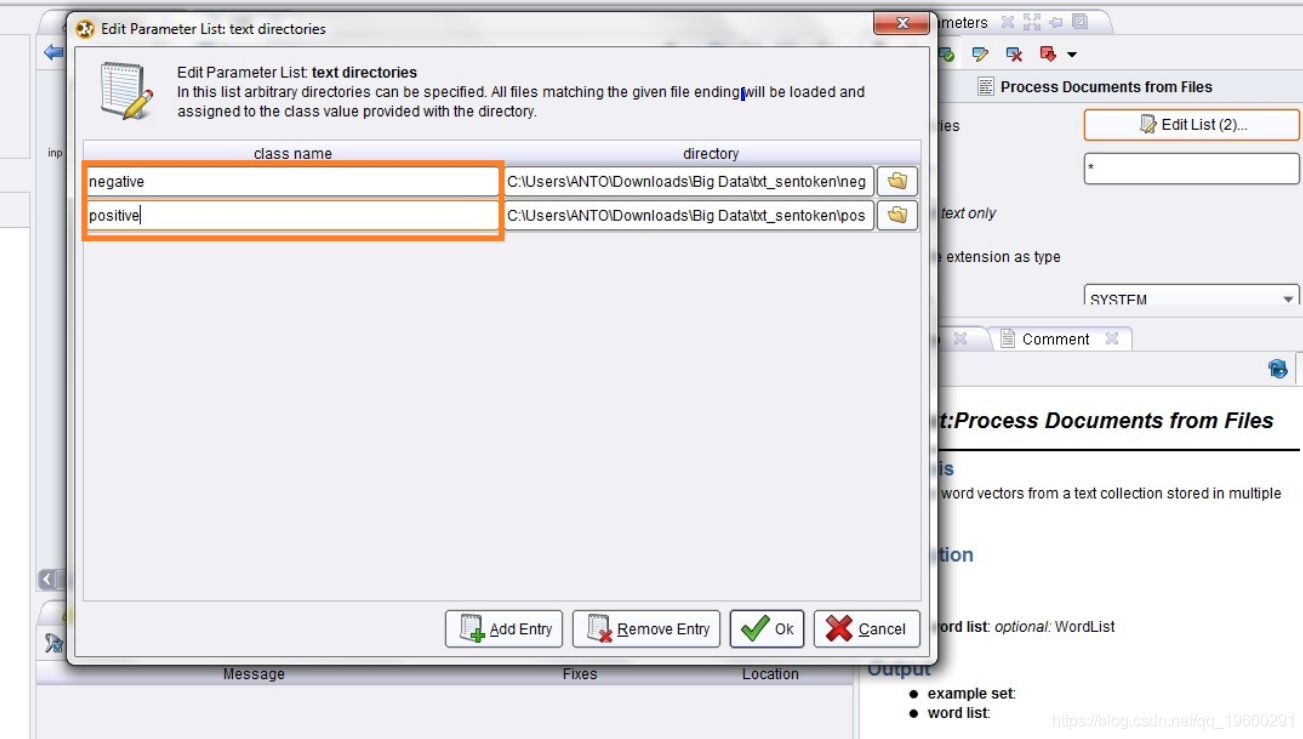
图2
在Process Document运算符下,发生嵌套操作,例如对单词进行标记,过滤停止单词。
然后使用两个运算符,例如Store和Validation运算符,如图1所示。Store运算符用于将字向量输出到我们选择的文件和目录中。验证算子(交叉验证)是评估统计模型准确性和有效性的一种标准方法。我们的数据集分为两个部分,一个训练集和一个测试集。仅在训练集上训练模型,并在测试集上评估模型的准确性。重复n次。双击验证运算符。将有两个面板-培训和测试。在“训练”面板下,使用了线性支持向量机(SVM),这是一种流行的分类器集,因为该函数是所有输入变量的线性组合。为了测试模型,我们使用“应用模型”运算符将训练集应用于我们的测试集。为了测量模型的准确性,我们使用“ Performance”运算符。
然后运行模型。类召回率%和精度%的结果如图5所示。模型和向量单词表存储在存储库中。
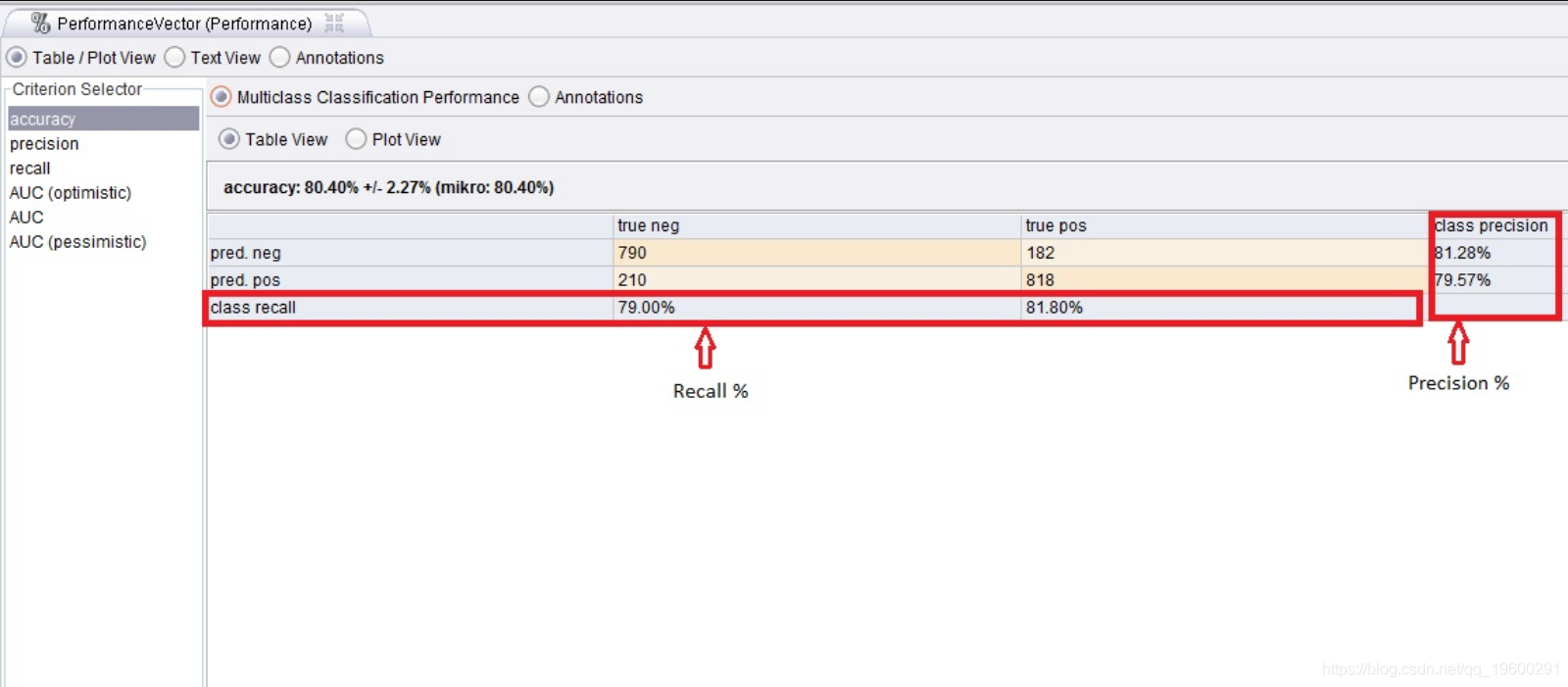
图5
然后从之前存储的存储库中检索模型和矢量单词表。然后从检索单词列表连接到图6所示的流程文档操作符。
然后单击“流程文档”运算符,然后单击右侧的编辑列表。这次,我从网站添加了5条电影评论的列表,并将其存储在目录中。为类名称分配未标记的名称,如图7所示。
Apply Model运算符从Retrieve运算符中获取一个模型,并从Process文档中获取未标记的数据作为输入,然后将所应用的模型输出到“实验室”端口,因此将其连接到“ res”(结果)端口。结果如下所示。当您查看《悲惨世界》时,有86.4%的人认为它是正面的,而13.6%的人认为是负面的,这是因为评论与正极性词表的匹配度高于负面。
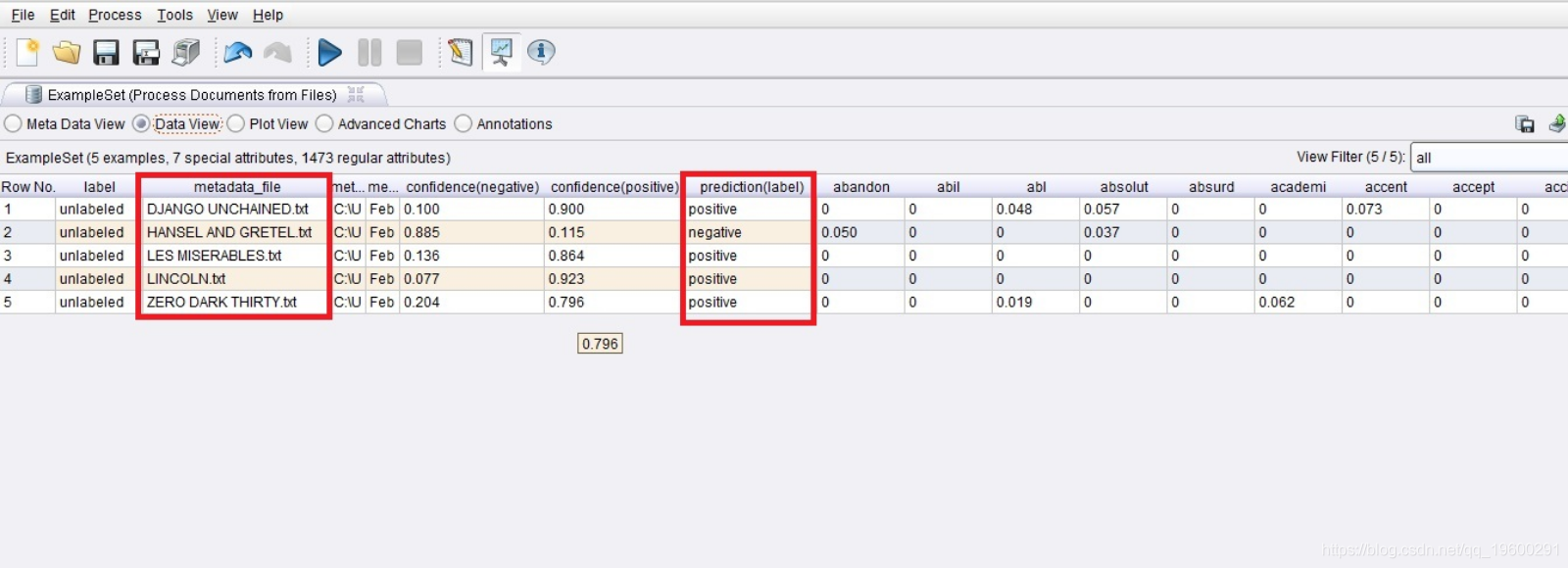
图8

▍关注我们
【大数据部落】第三方数据服务提供商,提供全面的统计分析与数据挖掘咨询服务,为客户定制个性化的数据解决方案与行业报告等。
▍咨询链接:http://y0.cn/teradat
▍联系邮箱:3025393450@qq.com

