
拓端tecdat|R语言辅导ROC曲线下的面积 - 评估逻辑回归中的歧视
原文链接:http://tecdat.cn/?p=6310
在讨论ROC曲线之前,首先让我们在逻辑回归的背景下考虑校准和区分之间的区别。
良好的校准是不够的
对于模型协变量的给定值,我们可以获得预测的概率。如果观察到的风险与预测的风险(概率)相匹配,则称该模型已被很好地校准。也就是说,如果我们要分配一组值的大量观察结果,这些观察结果的比例应该接近20%。如果观察到的比例是80%,我们可能会同意该模型表现不佳 - 这低估了这些观察的风险。 我们是否应满足于使用模型,只要它经过良好校准?不幸的是。为了了解原因,假设我们为我们的结果拟合了一个模型但没有任何协变量,即模型: 对数几率,使得预测值将与数据集中的观察的比例相同。 这个(相当无用的)模型为每个观察分配相同的预测概率。它将具有良好的校准 - 在未来的样品中,观察到的比例将接近我们的估计概率。然而,该模型并不真正有用,因为它不区分高风险观察和低风险观察。这种情况类似于天气预报员,他每天都说明天下雨的几率为10%。这个预测可能已经过很好的校准,但它没有告诉人们在某一天下雨的可能性是否更大或更低,因此实际上并不是一个有用的预测!
在R中绘制ROC曲线
set.seed(63126)
n < - 1000
x < - rnorm(n)
pr < - exp(x)/(1 + exp(x))
y < - 1 *(runif(n)<pr)
mod < - glm(y~x,family =“binomial”)接下来,我们从拟合的模型对象中提取拟合概率的向量:
predpr < - predict(mod,type = c(“response”))
我们现在加载pROC包,并使用roc函数生成一个roc对象。基本语法是指定回归类型方程,左侧是响应y,右侧是包含拟合概率的对象:
roccurve < - roc(y~preppr)
然后可以使用绘制roc对象


这给了我们ROC图(见前面的图)。请注意,这里因为我们的逻辑回归模型只包含一个协变量,如果我们使用roc(y~x),ROC曲线看起来完全相同,即我们不需要拟合逻辑回归模型。这是因为只有一个协变量,拟合概率是唯一协变量的单调函数。然而,一般而言(即模型中有一个以上的协变量),情况并非如此。
以前我们说过一个具有良好辨别能力的模型,ROC曲线将接近左上角。要通过模拟检查这一点,我们将重新模拟数据,将日志优势比从1增加到5:
set.seed(63126)
n < - 1000
x < - rnorm(n)
pr < - exp(5 * x)/(1 + exp(5 * x))
y < - 1 *(runif(n)<pr)
mod < - glm(y~x,family =“binomial”)
predpr < - predict(mod,type = c(“response”))
roccurve < - roc(y~preppr)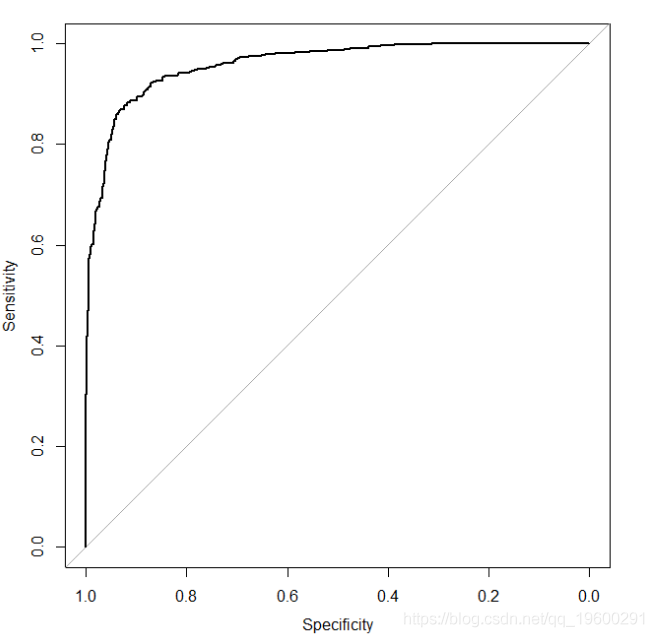
![]()
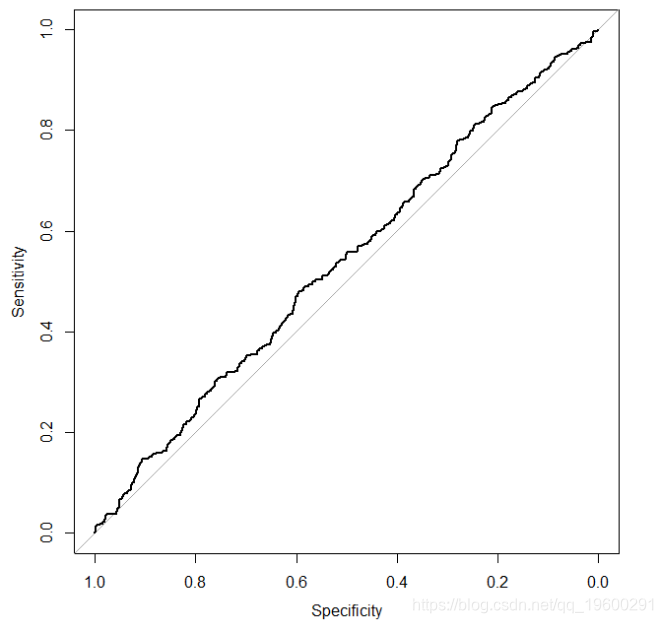
现在让我们再次运行模拟,但变量x实际上与y无关。为此,我们只需修改生成概率向量pr的行
pr < - exp(0 * x)/(1 + exp(0 * x))
它给出了以下ROC曲线
![]()
ROC曲线,其中预测因子与结果无关
ROC曲线下面积
总结模型辨别能力的一种流行方式是报告ROC曲线下的面积。我们已经看到具有辨别能力的模型具有更接近图的左上角的ROC曲线,而没有辨别能力的模型具有接近45度线的ROC曲线。因此,曲线下面积从1(对应于完美辨别)到0.5(对应于没有辨别能力的模型)。ROC曲线下面积有时也称为c统计量(c表示一致性)。
