



【大数据部落】R语言代写highfrequency高频金融数据导入
原文链接:http://tecdat.cn/?p=5287
R中针对高频数据的添加包highfrequency,用于组织高频数据, 高频数据的清理、整理,高频数据的汇总,使用高频数据建立相关模型 都非常方便。但是其中数据输入的过程中,会使用到包里的函数convert()。该函数支持三类的高频数据:
NYSE TAQ数据库中的.txt文件
WRDS数据库中的.csv文件
Tickdata.com的.asc文件
不易获取,因此,输入数据转换成xts,然后进行时间序列分析的过程中存在困难。
因此对于原始数据,我们可以整理成sample数据的格式,然后使用xts包先将其转换成xts格式。
对于时间序列数据要注意的一点是时间数据不单独作为一列,仅作为行名存在,否则在进行转换的过程中会出现colnames和列的数目不符合的错误。
因此对于数据可以先进行预处理。
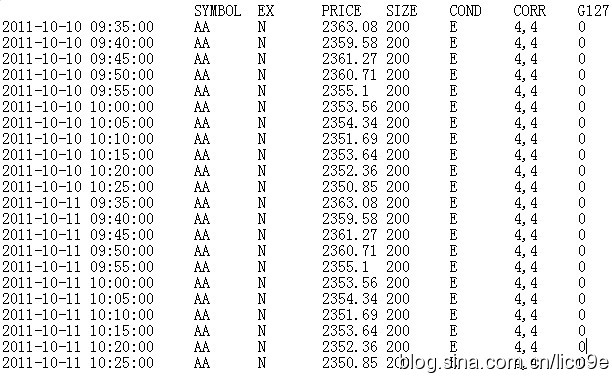
对于列数据间分隔建议使用tab制表符,否则在r读取的过程中会将时间的日期时间识别为两列。
sample_tdataraw=read.table("E:\\AA_trades.txt",header=F,skip = 1,stringsAsFactors=FALSE)
其中读取时要注意跳过第一行,列名和列数不符的错误。
读取后,对列名赋值
colnames(sample_tdataraw)=c(" ","SYMBOL","EX","PRICE","SIZE","COND","CORR","G127")
然后将第一列的时间数据赋给行名
row.names(sample_tdataraw)=sample_tdataraw[,1] sample_tdataraw=sample_tdataraw[,-1]
同时删去第一列。
这样就做好了可以进行转换xts格式的原始数据
library(xts) Data.xts <- as.xts(sample_tdataraw, descr='my new xts object')
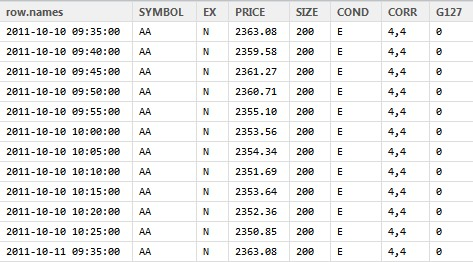
这样xts格式的数据便可以继续使用 highfrequency包中的其他函数进行分析了。
等间隔数据、数据同步
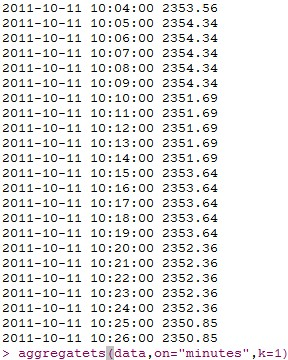
波动率预测
HAR-模型
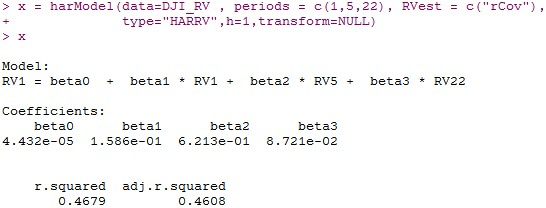
=====================================================
如果您有任何疑问,请在下面发表评论。
▍关注我们
【大数据部落】第三方数据服务提供商,提供全面的统计分析与数据挖掘咨询服务,为客户定制个性化的数据解决方案与行业报告等。
▍咨询链接:http://y0.cn/teradat
▍联系邮箱:3025393450@qq.com

