



拓端tecdat|加速R语言代码的策略
原文:http://tecdat.cn/?p=3750
R中的for循环在其未优化的原始形式中可能非常慢,特别是在处理较大的数据集时。有很多方法可以让你的逻辑快速运行,但是你真的会惊讶地发现你的实际速度有多快。本章介绍了许多方法,包括对逻辑设计,并行处理和Rcpp的简单调整,通过几个数量级的订单增加速度,因此您可以轻松处理高达1亿行甚至更多的数据。
让我们尝试提高涉及for循环和条件检查语句(if-else)的逻辑的速度,以创建一个附加到输入数据框(df)的列。下面的代码创建了初始输入数据框。
<span style="color:#333333"><span style="color:#333333"><code><span style="color:#888888"><em># Create the data frame</em></span>
col1 <- <span style="color:#555555"><strong>runif</strong></span> (<span style="color:#40a070">12</span>^<span style="color:#40a070">5</span>, <span style="color:#40a070">0</span>, <span style="color:#40a070">2</span>)
col2 <- <span style="color:#555555"><strong>rnorm</strong></span> (<span style="color:#40a070">12</span>^<span style="color:#40a070">5</span>, <span style="color:#40a070">0</span>, <span style="color:#40a070">2</span>)
col3 <- <span style="color:#555555"><strong>rpois</strong></span> (<span style="color:#40a070">12</span>^<span style="color:#40a070">5</span>, <span style="color:#40a070">3</span>)
col4 <- <span style="color:#555555"><strong>rchisq</strong></span> (<span style="color:#40a070">12</span>^<span style="color:#40a070">5</span>, <span style="color:#40a070">2</span>)
df <- <span style="color:#555555"><strong>data.frame</strong></span> (col1, col2, col3, col4)
df
<span style="color:#888888"><em>#> col1 col2 col3 col4</em></span>
<span style="color:#888888"><em>#> 1 0.6155322 -2.91525449 2 6.12523968</em></span>
<span style="color:#888888"><em>#> 2 0.5153450 -5.81655916 6 2.97873584</em></span>
<span style="color:#888888"><em>#> 3 1.1046449 0.80309503 2 0.07266261</em></span>
<span style="color:#888888"><em>#> 4 0.1127663 -1.48824042 3 2.39918101</em></span>
<span style="color:#888888"><em>#> 5 0.9370986 -1.35786823 0 7.38580513</em></span>
<span style="color:#888888"><em>#> 6 0.9675415 0.05832758 2 1.17428455</em></span></code></span></span>我们即将优化的逻辑:
对于此数据框中的每一行df,检查所有值的总和是否大于4.如果是,则新的第5个变量获取该值greater_than_4,否则,它获得lesser_than_4。
<span style="color:#333333"><span style="color:#333333"><code><span style="color:#888888"><em># Original R code: Before vectorization and pre-allocation</em></span>
<span style="color:#555555"><strong>system.time</strong></span>({
for (i in <span style="color:#40a070">1</span>:<span style="color:#555555"><strong>nrow</strong></span>(df)) { <span style="color:#888888"><em># for every row</em></span>
if ((df[i, <span style="color:#dd1144">'col1'</span>] + df[i, <span style="color:#dd1144">'col2'</span>] + df[i, <span style="color:#dd1144">'col3'</span>] + df[i, <span style="color:#dd1144">'col4'</span>]) > <span style="color:#40a070">4</span>) { <span style="color:#888888"><em># check if > 4</em></span>
df[i, <span style="color:#40a070">5</span>] <-<span style="color:#dd1144"> "greater_than_4"</span> <span style="color:#888888"><em># assign 5th column</em></span>
} else {
df[i, <span style="color:#40a070">5</span>] <-<span style="color:#dd1144"> "lesser_than_4"</span> <span style="color:#888888"><em># assign 5th column</em></span>
}
}
})
<span style="color:#555555"><strong>head</strong></span>(df)
<span style="color:#888888"><em>#> col1 col2 col3 col4 V5</em></span>
<span style="color:#888888"><em>#> 1 0.6155322 -2.91525449 2 6.12523968 greater_than_4</em></span>
<span style="color:#888888"><em>#> 2 0.5153450 -5.81655916 6 2.97873584 lesser_than_4</em></span>
<span style="color:#888888"><em>#> 3 1.1046449 0.80309503 2 0.07266261 lesser_than_4</em></span>
<span style="color:#888888"><em>#> 4 0.1127663 -1.48824042 3 2.39918101 greater_than_4</em></span>
<span style="color:#888888"><em>#> 5 0.9370986 -1.35786823 0 7.38580513 greater_than_4</em></span>
<span style="color:#888888"><em>#> 6 0.9675415 0.05832758 2 1.17428455 greater_than_4</em></span></code></span></span>我们在下面看到的所有方法都重新创建了相同的逻辑,但会更有效地完成。
下面的所有计算(处理时间)都是在具有2.6 Ghz处理器和8GB RAM的MAC OS X上完成的。
1.矢量化和预分配
始终将数据结构和输出变量初始化为所需的长度和数据类型,然后再将其循环进行计算。尽量不要逐渐增加循环内数据的大小。让我们比较一下矢量化如何在1000到100,000行的数据大小范围内提高速度。
<span style="color:#333333"><span style="color:#333333"><code><span style="color:#888888"><em># After vectorization and pre-allocation</em></span>
output <- <span style="color:#555555"><strong>character</strong></span> (<span style="color:#555555"><strong>nrow</strong></span>(df)) <span style="color:#888888"><em># initialize output vector</em></span>
<span style="color:#555555"><strong>system.time</strong></span>({
for (i in <span style="color:#40a070">1</span>:<span style="color:#555555"><strong>nrow</strong></span>(df)) {
if ((df[i, <span style="color:#dd1144">'col1'</span>] + df[i, <span style="color:#dd1144">'col2'</span>] + df[i, <span style="color:#dd1144">'col3'</span>] + df[i, <span style="color:#dd1144">'col4'</span>]) > <span style="color:#40a070">4</span>) {
output[i] <-<span style="color:#dd1144"> "greater_than_4"</span> <span style="color:#888888"><em># assign to vector </em></span>
} else {
output[i] <-<span style="color:#dd1144"> "lesser_than_4"</span>
}
}
df$output <- output <span style="color:#888888"><em># finally assign to data frame</em></span>
})</code></span></span>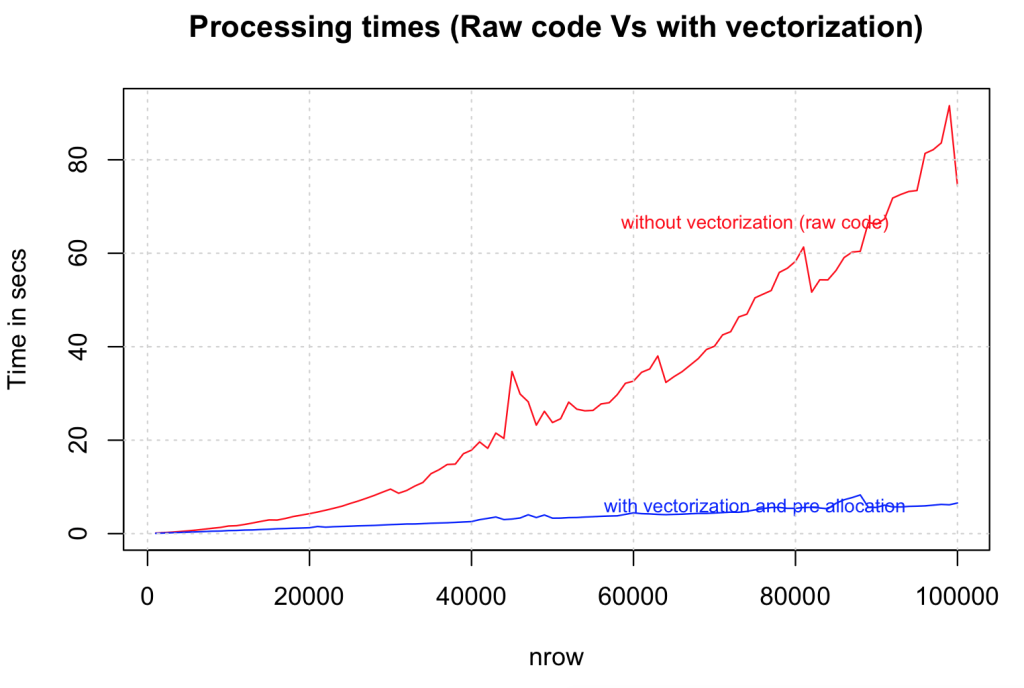
2.使用语句来检查循环外的条件(if语句)
在循环外部进行条件检查,将速度与仅具有矢量化的先前版本进行比较。测试是在数据集大小范围从100,000到1,000,000行进行的。速度的提升再次引人注目。
<span style="color:#333333"><span style="color:#333333"><code><span style="color:#888888"><em># After vectorization and pre-allocation, taking the condition checking outside the loop.</em></span>
output <- <span style="color:#555555"><strong>character</strong></span> (<span style="color:#555555"><strong>nrow</strong></span>(df))
condition <- (df$col1 + df$col2 + df$col3 + df$col4) > <span style="color:#40a070">4</span> <span style="color:#888888"><em># condition check outside the loop</em></span>
<span style="color:#555555"><strong>system.time</strong></span>({
for (i in <span style="color:#40a070">1</span>:<span style="color:#555555"><strong>nrow</strong></span>(df)) {
if (condition[i]) {
output[i] <-<span style="color:#dd1144"> "greater_than_4"</span>
} else {
output[i] <-<span style="color:#dd1144"> "lesser_than_4"</span>
}
}
df$output <- output
})</code></span></span>
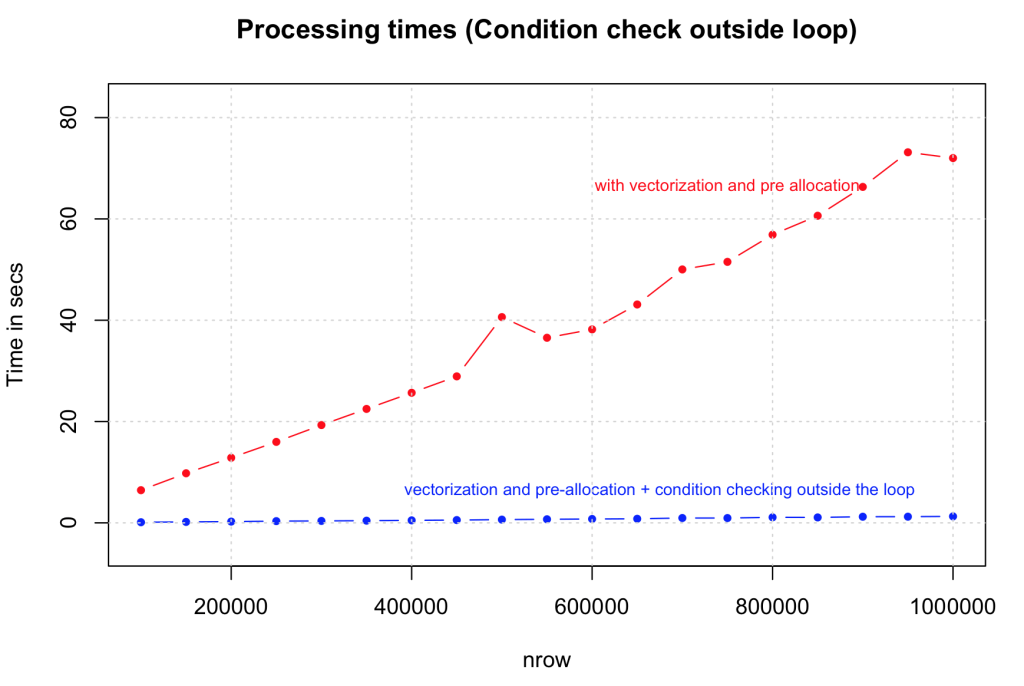
3.仅针对True条件运行循环
我们在这里可以做的另一个优化是仅通过将输出向量的默认值初始化(预分配)为'False'状态来为“True”的条件情况运行循环。这里的速度提升很大程度上取决于数据中“真实”案例的比例。测试将此性能与之前的情况(2)进行了比较,数据大小范围为1,000,000到10,000,000行。请注意,我们在这里增加了一个'0'。正如预期的那样,有一个相当大的改进。
<span style="color:#333333"><span style="color:#333333"><code>output <- <span style="color:#555555"><strong>character</strong></span>(<span style="color:#555555"><strong>nrow</strong></span>(df))
condition <- (df$col1 + df$col2 + df$col3 + df$col4) > <span style="color:#40a070">4</span>
<span style="color:#555555"><strong>system.time</strong></span>({
for (i in (<span style="color:#40a070">1</span>:<span style="color:#555555"><strong>nrow</strong></span>(df))[condition]) { <span style="color:#888888"><em># run loop only for true conditions</em></span>
if (condition[i]) {
output[i] <-<span style="color:#dd1144"> "greater_than_4"</span>
} else {
output[i] <-<span style="color:#dd1144"> "lesser_than_4"</span>
}
}
df$output })</code></span></span>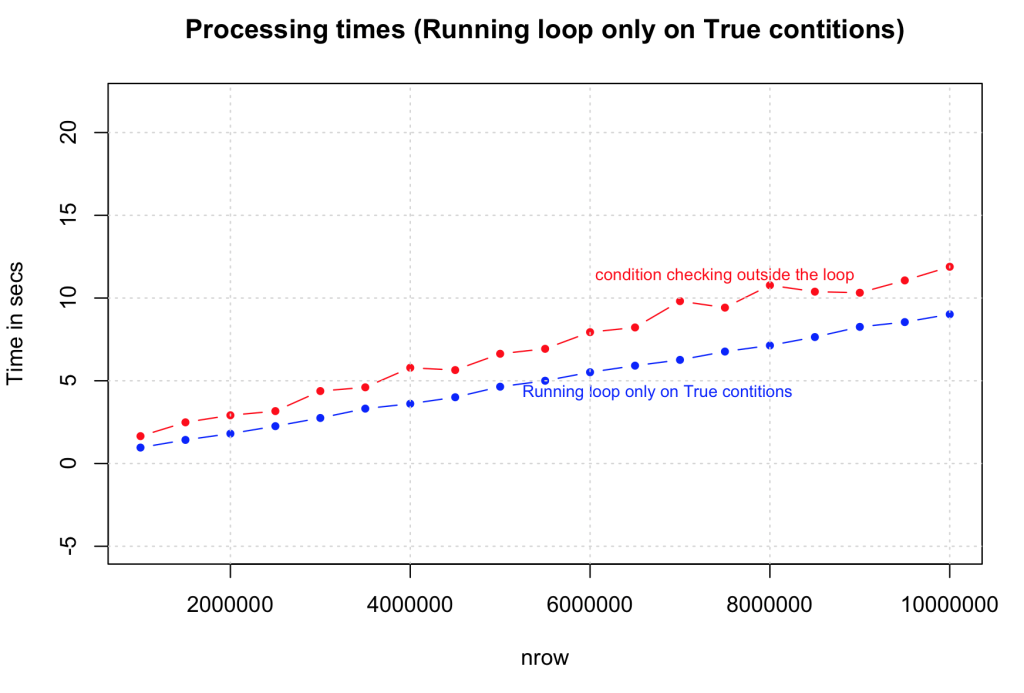
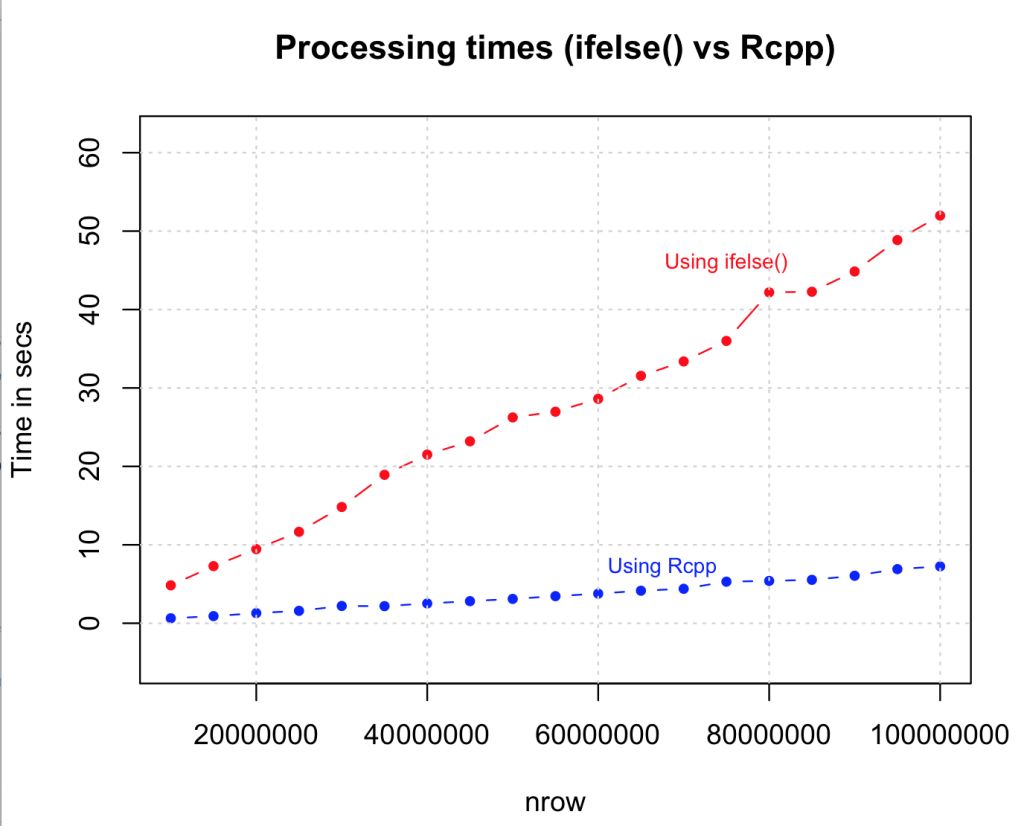
4.尽可能使用ifelse()
您可以使用ifelse()语句使此逻辑更简单,更快捷。语法类似于MS Excel中的“if”函数,但速度增加是惊人的,特别是考虑到这里没有向量预分配,并且在每种情况下都检查条件。看起来这将成为加速简单循环的首选方案。
<span style="color:#333333"><span style="color:#333333"><code><span style="color:#555555"><strong>system.time</strong></span>({
output <- <span style="color:#555555"><strong>ifelse</strong></span> ((df$col1 + df$col2 + df$col3 + df$col4) > <span style="color:#40a070">4</span>, <span style="color:#dd1144">"greater_than_4"</span>, <span style="color:#dd1144">"lesser_than_4"</span>)
df$output <- output
})</code></span></span>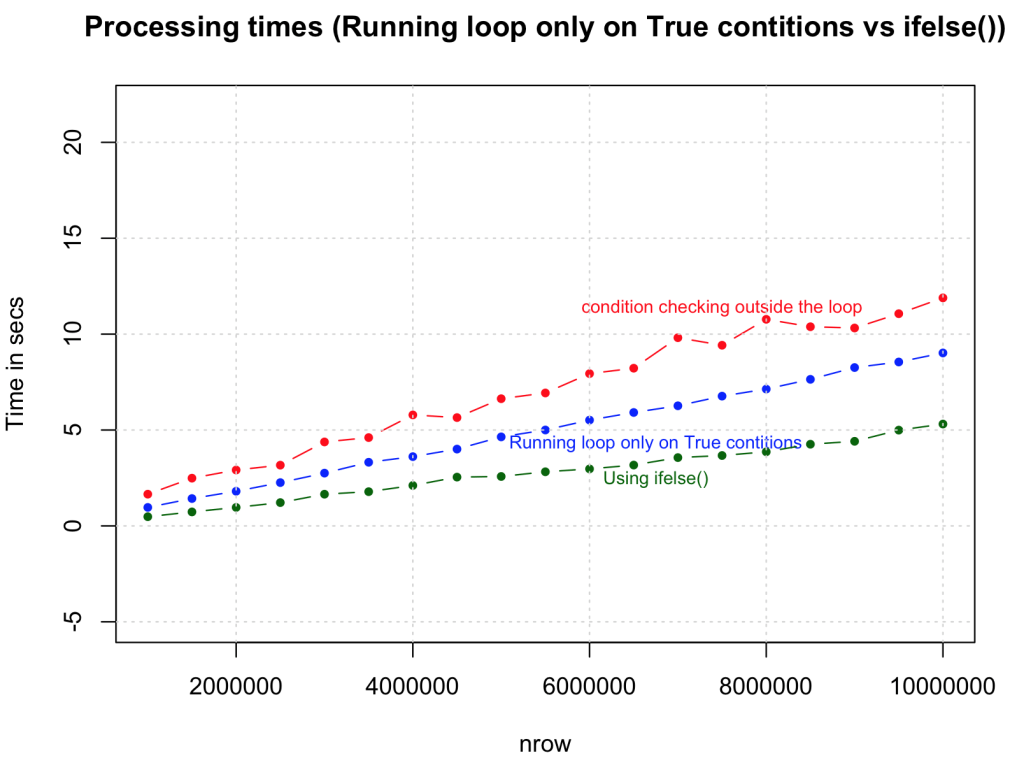
5.使用which()
通过使用which()命令选择行,我们能够达到Rcpp速度的三分之一。
<span style="color:#333333"><span style="color:#333333"><code><span style="color:#555555"><strong>system.time</strong></span>({
want = <span style="color:#555555"><strong>which</strong></span>(<span style="color:#555555"><strong>rowSums</strong></span>(df) > <span style="color:#40a070">4</span>)
output = <span style="color:#555555"><strong>rep</strong></span>(<span style="color:#dd1144">"less than 4"</span>, <span style="color:#902000">times =</span> <span style="color:#555555"><strong>nrow</strong></span>(df))
output[want] =<span style="color:#dd1144"> "greater than 4"</span>
})
<span style="color:#888888"><em># nrow = 3 Million rows (approx)</em></span>
<span style="color:#888888"><em>#> user system elapsed </em></span>
<span style="color:#888888"><em>#> 0.396 0.074 0.481 </em></span></code></span></span>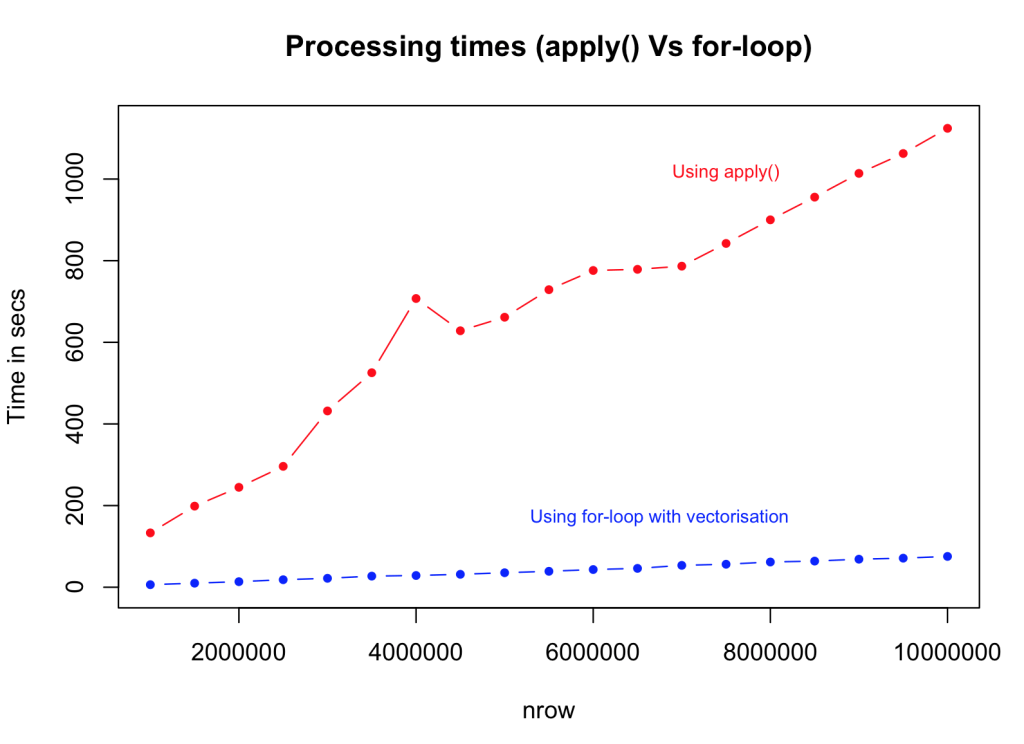
6.使用apply系列函数代替for循环。
使用apply()函数计算相同的逻辑并将其与矢量化的for循环进行比较。结果再次以大小的顺序更快但比ifelse()在循环外进行条件检查的版本慢。这可能非常有用,但在处理复杂逻辑时您需要有点狡猾。
<span style="color:#333333"><span style="color:#333333"><code><span style="color:#888888"><em># apply family</em></span>
<span style="color:#555555"><strong>system.time</strong></span>({
myfunc <- function(x) {
if ((x[<span style="color:#dd1144">'col1'</span>] + x[<span style="color:#dd1144">'col2'</span>] + x[<span style="color:#dd1144">'col3'</span>] + x[<span style="color:#dd1144">'col4'</span>]) > <span style="color:#40a070">4</span>) {
<span style="color:#dd1144">"greater_than_4"</span>
} else {
<span style="color:#dd1144">"lesser_than_4"</span>
}
}
output <- <span style="color:#555555"><strong>apply</strong></span>(df[, <span style="color:#555555"><strong>c</strong></span>(<span style="color:#40a070">1</span>:<span style="color:#40a070">4</span>)], <span style="color:#40a070">1</span>, <span style="color:#902000">FUN=</span>myfunc) <span style="color:#888888"><em># apply 'myfunc' on every row</em></span>
df$output <- output
})</code></span></span>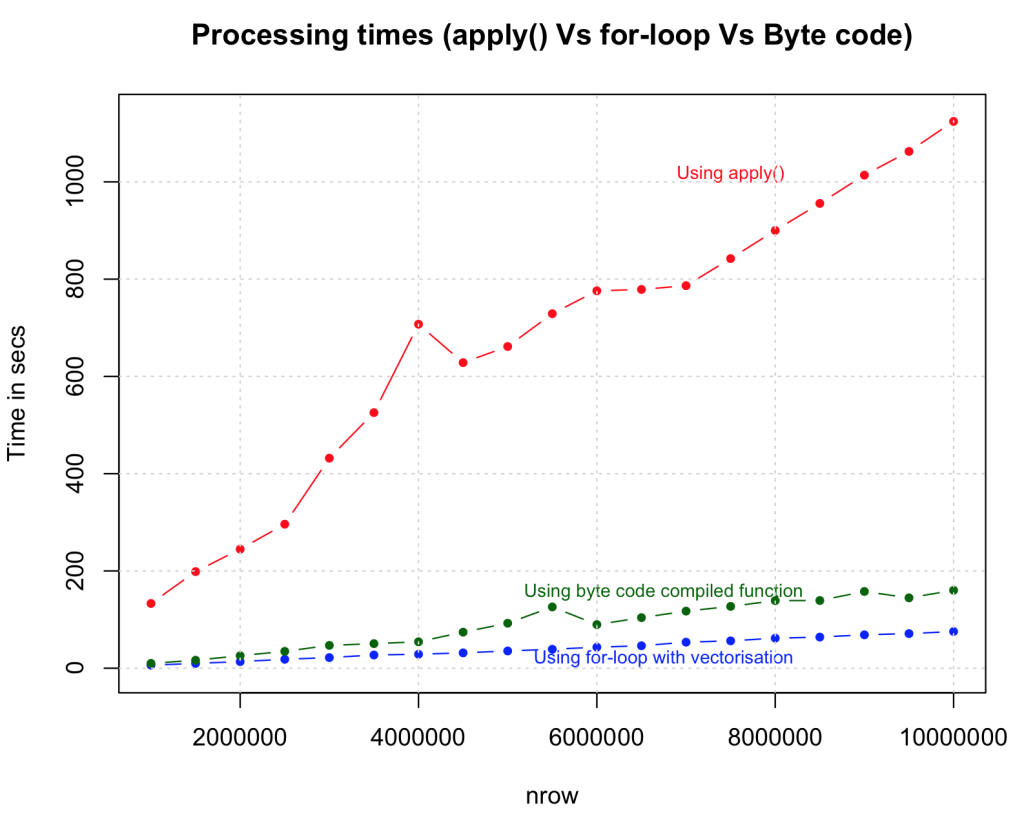
7.对cmpfun()编译器包中的函数使用字节代码编译,而不是实际的函数本身。
这可能不是说明字节代码编译有效性的最好例子,因为所花费的时间略高于常规形式。但是,对于更复杂的函数,已知字节码编译执行得更快。所以你一定要试一试。
<span style="color:#333333"><span style="color:#333333"><code><span style="color:#888888"><em># byte code compilation</em></span>
<span style="color:#555555"><strong>library</strong></span>(compiler)
myFuncCmp <- <span style="color:#555555"><strong>cmpfun</strong></span>(myfunc)
<span style="color:#555555"><strong>system.time</strong></span>({
output <- <span style="color:#555555"><strong>apply</strong></span>(df[, <span style="color:#555555"><strong>c</strong></span> (<span style="color:#40a070">1</span>:<span style="color:#40a070">4</span>)], <span style="color:#40a070">1</span>, <span style="color:#902000">FUN=</span>myFuncCmp)
})</code></span></span>
8.使用Rcpp
让我们把它变成一个档次。到目前为止,我们通过各种策略获得了速度和容量,并使用ifelse()语句找到了最优的策略。如果再添加一个零怎么办?下面我们执行相同的逻辑,但使用Rcpp,并且数据大小增加到1亿行。我们将比较Rcpp与ifelse()方法的速度。
<span style="color:#333333"><span style="color:#333333"><code><span style="color:#555555"><strong>library</strong></span>(Rcpp)
<span style="color:#555555"><strong>sourceCpp</strong></span>(<span style="color:#dd1144">"MyFunc.cpp"</span>)
<span style="color:#555555"><strong>system.time</strong></span> (output <- <span style="color:#555555"><strong>myFunc</strong></span>(df)) <span style="color:#888888"><em># see Rcpp function below</em></span></code></span></span>下面是使用Rcpp包在C ++代码中执行的相同逻辑。将以下代码保存为R会话工作目录中的“MyFunc.cpp”(否则您只需从完整文件路径中获取sourceCpp)。注意:// [[Rcpp::export]]注释是必需的,必须放在要从R执行的函数之前。
<span style="color:#333333"><span style="color:#333333"><code>/<span style="color:#a61717">/</span> Source for MyFunc.cpp
<span style="color:#888888"><em>#include <Rcpp.h></em></span>
using namespace Rcpp;
/<span style="color:#a61717">/</span> [[Rcpp::export]]
CharacterVector <span style="color:#555555"><strong>myFunc</strong></span>(DataFrame x) {
NumericVector col1 = as<NumericVector>(x[<span style="color:#dd1144">"col1"</span>]);
NumericVector col2 = as<NumericVector>(x[<span style="color:#dd1144">"col2"</span>]);
NumericVector col3 = as<NumericVector>(x[<span style="color:#dd1144">"col3"</span>]);
NumericVector col4 = as<NumericVector>(x[<span style="color:#dd1144">"col4"</span>]);
int n = <span style="color:#555555"><strong>col1.size</strong></span>();
CharacterVector <span style="color:#555555"><strong>out</strong></span>(n);
for (int <span style="color:#902000">i=</span><span style="color:#40a070">0</span>; i<n; i++) {
double tempOut = col1[i] + col2[i] + col3[i] + col4[i];
if (tempOut > <span style="color:#40a070">4</span>){
out[i] =<span style="color:#dd1144"> "greater_than_4"</span>;
} else {
out[i] =<span style="color:#dd1144"> "lesser_than_4"</span>;
}
}
return out;
}</code></span></span>
9.如果您有多核机器,请使用并行处理。
<span style="color:#333333"><span style="color:#333333"><code><span style="color:#888888"><em># parallel processing</em></span>
<span style="color:#555555"><strong>library</strong></span>(foreach)
<span style="color:#555555"><strong>library</strong></span>(doSNOW)
cl <- <span style="color:#555555"><strong>makeCluster</strong></span>(<span style="color:#40a070">4</span>, <span style="color:#902000">type=</span><span style="color:#dd1144">"SOCK"</span>) <span style="color:#888888"><em># for 4 cores machine</em></span>
<span style="color:#555555"><strong>registerDoSNOW</strong></span> (cl)
condition <- (df$col1 + df$col2 + df$col3 + df$col4) > <span style="color:#40a070">4</span>
<span style="color:#888888"><em># parallelization with vectorization</em></span>
<span style="color:#555555"><strong>system.time</strong></span>({
output <- <span style="color:#555555"><strong>foreach</strong></span>(<span style="color:#902000">i =</span> <span style="color:#40a070">1</span>:<span style="color:#555555"><strong>nrow</strong></span>(df), <span style="color:#902000">.combine=</span>c) %dopar% {
if (condition[i]) {
<span style="color:#555555"><strong>return</strong></span>(<span style="color:#dd1144">"greater_than_4"</span>)
} else {
<span style="color:#555555"><strong>return</strong></span>(<span style="color:#dd1144">"lesser_than_4"</span>)
}
}
})
df$output <- output</code></span></span>10.尽早删除变量并刷新内存。
rm()在代码中尽早删除不再需要的对象,尤其是在进行冗长的循环操作之前。有时,gc()在每次迭代结束时使用循环进行刷新可能会有所帮助。
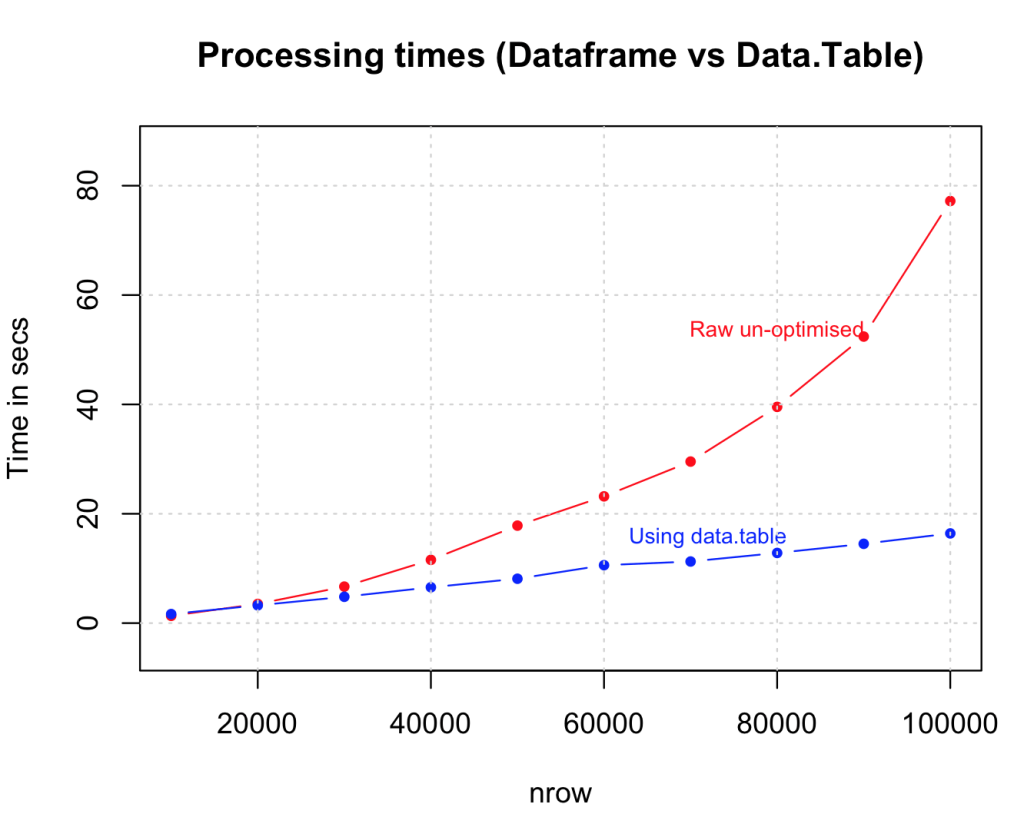
11.使用消耗较少内存的数据结构
data.table() 是一个很好的例子,因为它减少了内存过载,有助于加快合并数据等操作。
<span style="color:#333333"><span style="color:#333333"><code>dt <- <span style="color:#555555"><strong>data.table</strong></span>(df) <span style="color:#888888"><em># create the data.table</em></span>
<span style="color:#555555"><strong>system.time</strong></span>({
for (i in <span style="color:#40a070">1</span>:<span style="color:#555555"><strong>nrow</strong></span> (dt)) {
if ((dt[i, col1] + dt[i, col2] + dt[i, col3] + dt[i, col4]) > <span style="color:#40a070">4</span>) {
dt[i, col5:<span style="color:#a61717">=</span><span style="color:#dd1144">"greater_than_4"</span>] <span style="color:#888888"><em># assign the output as 5th column</em></span>
} else {
dt[i, col5:<span style="color:#a61717">=</span><span style="color:#dd1144">"lesser_than_4"</span>] <span style="color:#888888"><em># assign the output as 5th column</em></span>
}
}
})</code></span></span>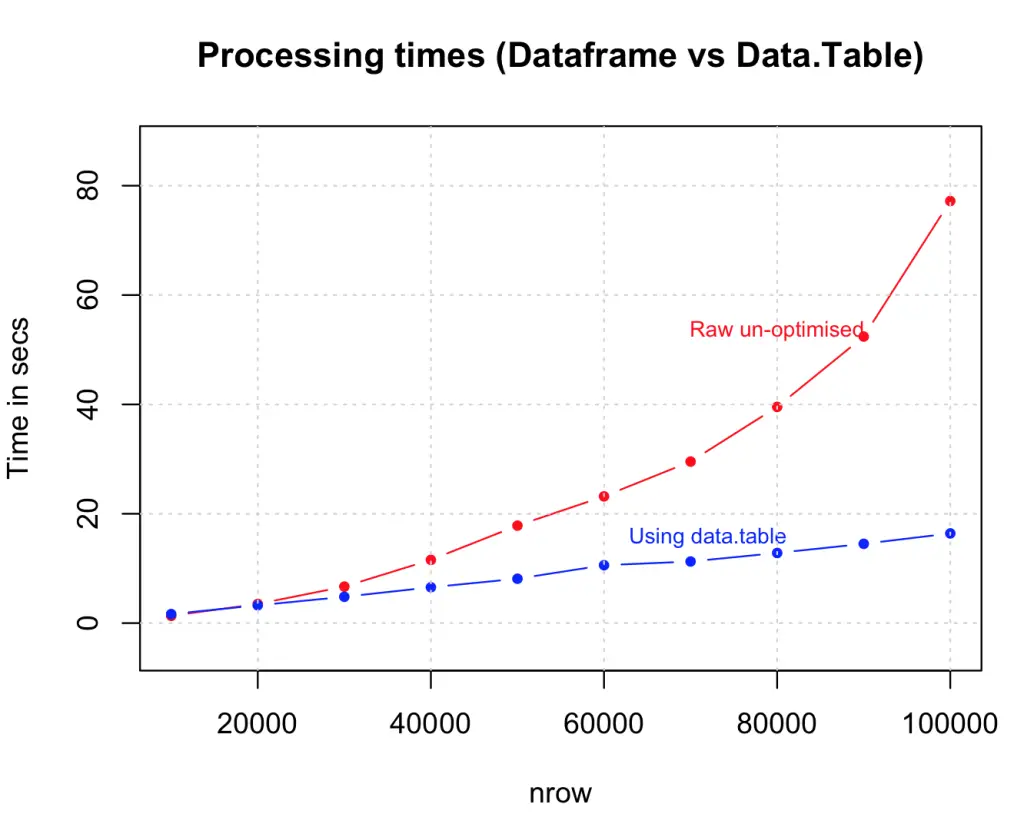
摘要
| 方法 | 速度 | nrow(df)/ time_taken = 每秒n行 |
|---|---|---|
| 原始 | 1X | 120000 / 140.15 =每秒856.2255行(标准化为1) |
| 矢量化 | 738X | 120000 / 0.19 =每秒631578.9行 |
| 只有真实条件 | 1002X | 120000 / 0.14 =每秒857142.9行 |
| ifelse | 1752X | 1200000 / 0.78 =每秒1500000行 |
| which | 8806X | 2985984 / 0.396 =每秒7540364行 |
| RCPP | 13476X | 1200000 / 0.09 =每秒11538462行 |
以上数字是近似值,基于任意运行。结果不是针对data.table(),字节代码编译和并行化方法计算的,因为它们会根据具体情况而有所不同,具体取决于您如何应用它。

