



拓端tecdat|WEKA代写文本挖掘分析垃圾邮件分类模型
业务背景
电子邮件的应用变的十分广泛,它给人们的生活带来了极大的方便,然而,作为其发展的副产品——垃圾邮件,却给广大用户、网络管理员和ISP(Internet服务提供者)带来了大量的麻烦。垃圾邮件问题日益严重,受到研究人员的广泛关注。 垃圾邮件通常是指未经用户许可,但却被强行塞入用户邮箱的电子邮件。对于采用群发等技术的垃圾邮件,必须借助一定的技术手段进行反垃圾邮件工作。目前,反垃圾邮件技术主要包括:垃圾邮件过滤技术、邮件服务器的安全管理以及对简单邮件通信协议(SMTP)的改进研究等。
WEKA文本分词预处理
首先对于训练集文件夹中的两类邮件文档进行分析,可从不同角度自动化分析两类文件特征,编写算法,构建分类模型。
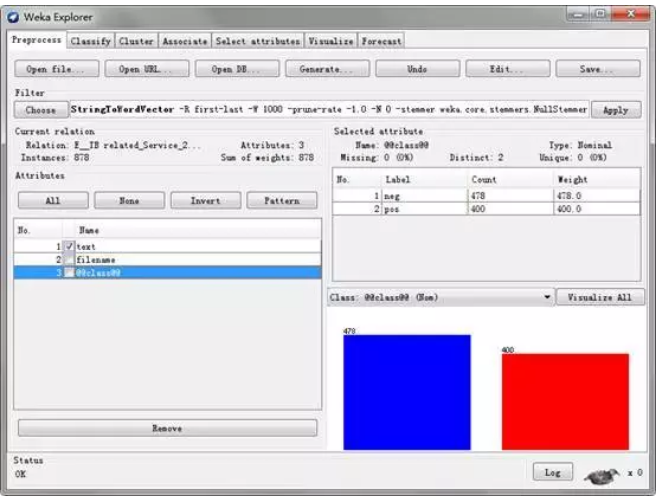
首先设置工作目录,并且读取分类后的文本文件
可以看到垃圾邮件和非垃圾邮件的频数直方图

![]()

然后对得到的原始语料进行分词处理 得到词频矩阵文件

![]()
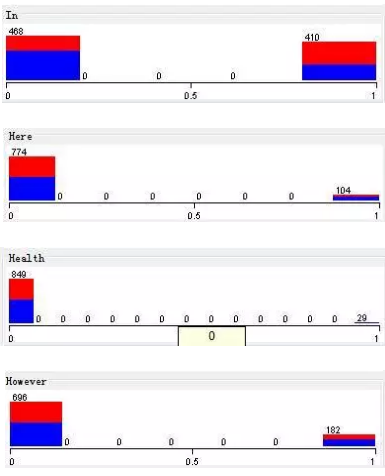
得到各个词频的分类直方图

![]()
得到词频矩阵后 对数据进行分类器的建模
2. 对corpus中的attribute进行分析,找出对于分类有贡献的attribute(即那些词只出现在positive中,那些词只出现在negative中,哪些词在两个类别里都出现)

![]()

![]()

![]()

![]()
3. 找出区分positive和negative的分类规则(即哪些词在一起出现的时候会导致分类器判断的结果为positive,哪些词在一起出现的时候会导致分类器判断的结果为negative)

![]()

从结果可以看出cell efficiengcy however breast rates 和cell这些词对最后的分类结果有较大的影响 如有however的一般为负面词 。
WEKA文本分词结果比较
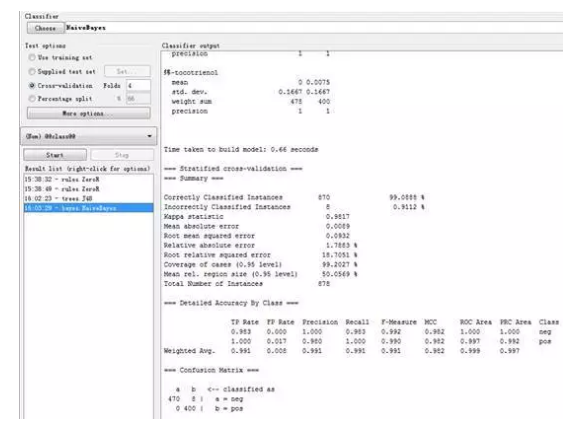
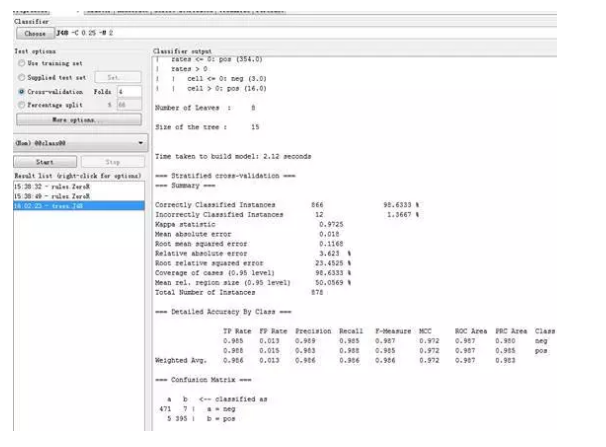
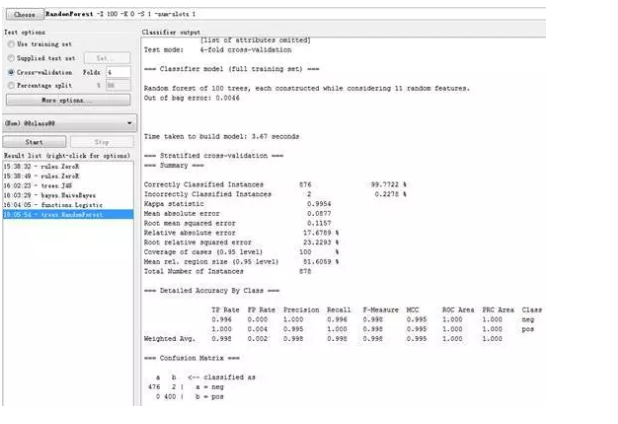
下面得到每个分类器的准确度和混淆矩阵:
|
NaiveBayes |
|
|
|
Logistic
|
|
J48
|
|
RandomForest
|
|
SVM
|
|
OneR
|









结语
基于判别方法的垃圾邮件过滤在现代研究中引起比较少的关注 ,结果很清楚地表明,基于随机森林、SVM模型的分类方法相对于传统的方法,在垃圾邮件的过滤方面,可以有效地提高正确率和准确率。

