

【大数据部落】R语言代写银行信用数据SOM神经网络聚类实现
原文链接:http://tecdat.cn/?p=3231
在当今社会,“信用”越来越多的人们关注个人或企业,有望获得最高的信用评分,以享受更多的信贷额度,更优惠的利率。 那么我们如何评分信用,并使我们的客户可视化?
自组织地图(SOM)是一种无监督的数据可视化技术,可用于在较低(通常为2)维可视化高维数据集。
我们熟悉支付宝芝麻信用点,它是通过收购个人用户信息,经过处理,计算用户的信用评分,当然代表较高的信用评分越高。
当然,这些信息系统也记录下您所有的下落,即所谓的“数据”。这些数据的存储,清理和处理为客户的信用评级提供了一个健全丰富的信息来源。 基于此,银行分析和计算大数据技术,准确评估客户的信用。

银行客户信用评分数据从银行产生的内部数据或外部数据得出,如下
在本文中我们将从使用R:
对可视化银行客户的信用的人口属性进行som聚类并且进行可视化
通常,与信用等级相关的因素包含客户的学历、工资、年龄、额度使用情况、现金提取次数、还款时间等。
现在使用Kohonen方法训练SOM
som_grid <- somgrid(xdim = 10, ydim=10, topo="hexagonal")
查看训练过程的聚类距离
plot(som_model, type = "changes")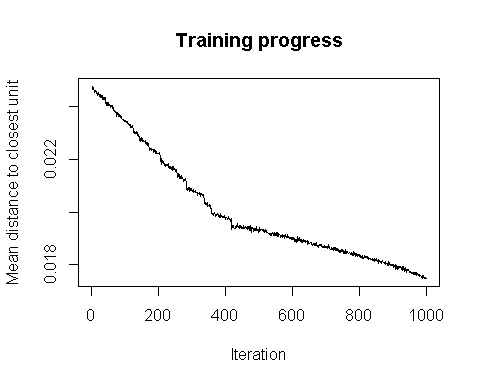
首先对聚类结果的效果进行可视化
不同聚类类别的节点数目
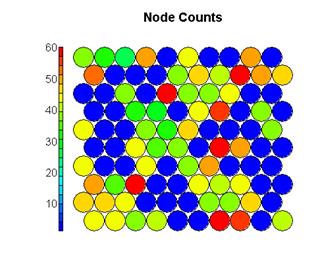
节点质量
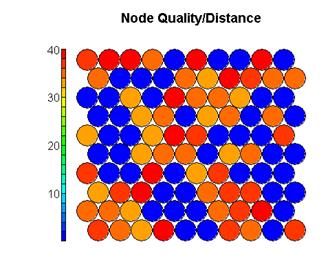
近邻距离
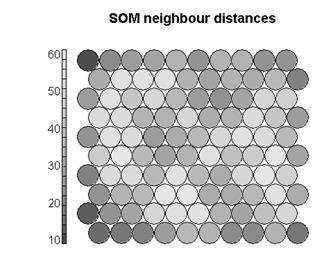
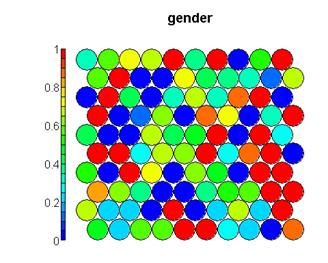
从训练集中绘制性别变量的原始比例热图:
显示针对不同聚类大小的k均值的WCSS度量。
可以作为理想数量聚类的“粗略”指标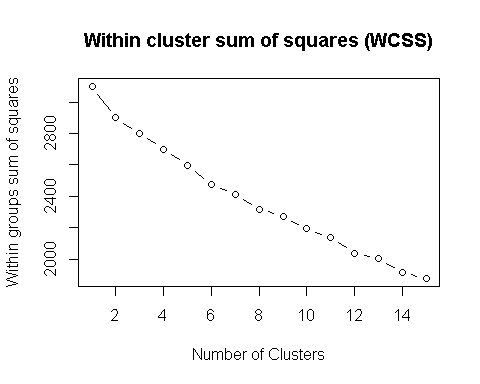
从结果中我们可以看到将数据划分成不同类别后得到的组间距离。
然后我们将数据划分成6个类别,然后查看数据的聚类情况
在网格上形成群集
为每个群集显示不同颜色的地图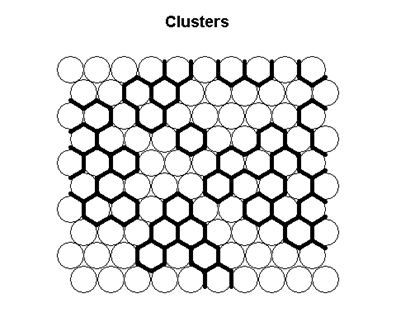
通过对银行客户的信用评分的聚类,我们可以将客户划分成不同的类别,对银行的经营效益有着重要的作用,信用评分模型应用效果,很大程度上也取决于银行的内部管理及信贷政策。技术和管理相结合,双管齐下,一定是控制客户信用风险的最优方案。

