


拓端tecdat|R语言代写模拟探索回归的P值
最近关于p值讨论的爆发激发了我进行简短的模拟研究。
特别是,我想说明p值如何随着效果和样本大小的不同而变化。
以下是模拟的详细信息。我模拟![]() 了我的自变量的绘制
了我的自变量的绘制![]() :
:

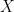
![]()

![]()

对于每一个![]() ,我定义一个
,我定义一个![]() as
as

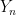
![]()

![]()
![]()


换句话说,对于每个效果大小,![]() 模拟绘制
模拟绘制![]() 并
并![]() 出现一些错误
出现一些错误![]() 。估计以下回归模型并
。估计以下回归模型并![]() 观察p值。
观察p值。
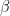
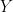

![]()

绘图和回归完成1,000次,因此对于每个效果大小 - 样本大小组合,模拟产生1,000个p值。下面绘制了每种效应大小和样本大小组合的这1,000个p值的平均值。
注意,这些结果是固定的![]() 。较高的采样误差通常会使这些曲线向上移动,这意味着对于每个效应大小,相同的样本将产生较低的信号。
。较高的采样误差通常会使这些曲线向上移动,这意味着对于每个效应大小,相同的样本将产生较低的信号。


![]()
首先,对于给定的样本大小,更容易“检测”更大的效果大小。通过检测,我的意思是使用.05阈值发现具有统计显着性。可以使用相对较小的样本大小(在这种情况下<10)检测较大的效果大小(例如.25)。相反,如果效果大小很小(例如.05),则需要更大的样本来检测效果(> 10)。
其次,这个图说明了一个关于p值的常见警告:总是在样本大小的范围内解释它们。缺乏统计意义并不意味着缺乏效果。可能存在效果,但样本大小可能不足以检测它(或者数据集中的可变性太高)。另一方面,仅仅因为p值表示统计显着性并不意味着该效果实际上是有意义的。考虑效果大小.00000001(实际为0)。根据该图表,随着样本大小的增加,甚至该效应大小的p值趋于0,最终超过统计显着性阈值。
如果您有任何疑问,请在下面发表评论。
大数据部落 -中国专业的第三方数据服务提供商,提供定制化的一站式数据挖掘和统计分析咨询服务
统计分析和数据挖掘咨询服务:y0.cn/teradat(咨询服务请联系官网客服)
![]()
QQ:3025393450
![]() QQ交流群:186388004
QQ交流群:186388004 
【服务场景】
科研项目; 公司项目外包;线上线下一对一培训;数据爬虫采集;学术研究;报告撰写;市场调查。
