
(原创)Stanford Machine Learning (by Andrew NG) --- (week 6) Advice for Applying Machine Learning & Machine Learning System Design
(1) Advice for applying machine learning
Deciding what to try next
现在我们已学习了线性回归、逻辑回归、神经网络等机器学习算法,接下来我们要做的是高效地利用这些算法去解决实际问题,尽量不要把时间浪费在没有多大意义的尝试上,Advice for applying machine learning & Machinelearning system design 这两课介绍的就是在设计机器学习系统的时候,我们该怎么做?
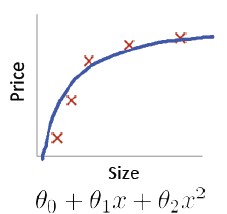
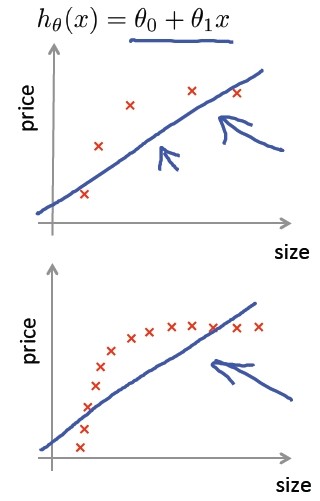
假设我们实现了一个正则化的线性回归算法来预测房价: ![]()
但当使用该模型在测试集上预测房价时,发现预测出来的结果很不准确,那么,接下来我们该怎么做?可选的优化途径有很多,如获取更多的训练样本、尝试更少的样本特征、尝试其它特征、尝试组合特征、尝试增加/减小λ。
但这个时候不能盲目选择,明智的做法是对学习算法进行 diagnose(深入的认识),分析算法的不足,来指导我们如何有效地提高算法性能。
Evaluating a hypothesis
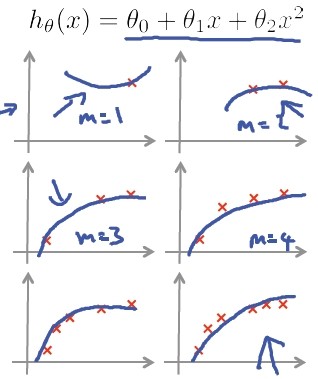
在房价预测问题中,如果 hypothesis 如下:
hθ(x) = θ0 + θ1x + θ2x2 +θ3x3 +θ4x4
定义如下特征:
- x1 = size of house
- x2 = no. of bedrooms
- x3 = no. of floors
- x4 = age of house
- x5 = average income in neiborhood
- x6 = kitchen size
- ...
- x100
同时对训练数据做了很好的拟合:
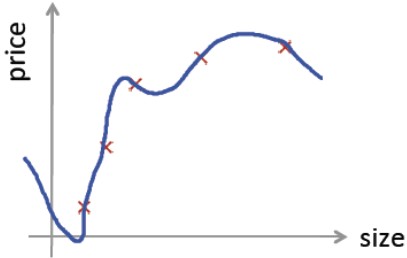
也就是说,在训练集上,损失是最小的,但是在非训练集上的数据预测效果却很差,失去通用性,那我们该如何去评价这个假设呢?
首先,我们对训练集进行切分,一部分(如 70%)作为训练集,另一部分(如30%)作为测试集。
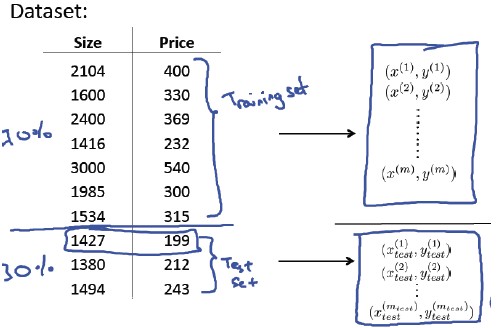
对于线性回归:
-通过最小化训练集的errorJ(θ)来学习参数θ;
-计算测试集的error.
对逻辑回归,与线性回归类似:
-首先从训练集中学习参数θ;
-计算测试集的error;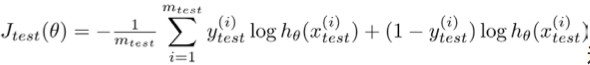
-还可以计算错误分类的比率,对每一个实例计算error,然后对计算结果求平均。

Model selection and training/validation/test sets
对于房价过拟合的例子,当基于该模型参数θ确定之后,其计算出的error可能比实际泛化的error要小,显然不是一个合适的模型,所以我们需要考虑一下模型选择(Model Selection)的问题,假设我们有下述十种多项式回归模型:
- hθ(x) = θ0 + θ1x
- hθ(x) = θ0 + θ1x + θ2x2
- hθ(x) = θ0 + θ1x + θ2x2 +θ3x3
- ...
- hθ(x) = θ0 + θ1x +... +θ10x10
怎么去选择呢?
Step1: 基于训练集学习参数,计算测试集的 error,选择测试集 error 最小的多项式模型,假设选择模型:θ0 +...+ θ5x5
step2: 计算模型的泛化能力,在测试集上的 error 基本能代表该模型的泛化能力,但是是否准确呢?我们用训练集来训练参数,用测试集来选择和评估参数,看起来就像模型是针对测试集进行了优化的,为了避免这个问题,引入第三个集合:交叉验证集,使用该数据集来选择参数,然后选择测试集来评估假设。
对于原始的数据集,比较典型的划分方式是 60%的训练集,20%的交叉验证集,20%的测试集。

在这三个数据集上,分别定义各自的 error:
Training error: 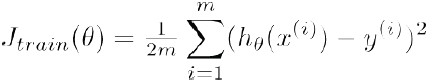
Cross Validation error: 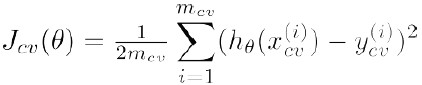
Test error: 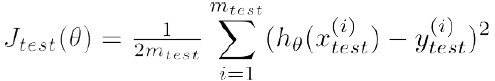
实际使用时,通过训练集学习得到参数,通过验证集计算 error,选择 error最小的模型参数,最后在测试集上估计模型的泛化误差。
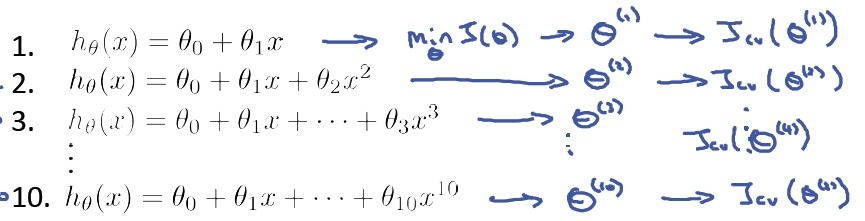
Diagnosing bias vs. variance
课程中提出的偏差/方差,我认为就是低拟合和过拟合的问题:
a) 高偏差(欠拟合):High bias(underfit)
在训练数据中,模型偏离样本真实情况较大。
b)高方差(过拟合):High variance(overfit)
模型过于完美地描述样本。

c) 合适的拟合:Just right
计算上述三个模型的 trainerror&crossvalidationerror:
Training error:
Cross validation error:
发现如下结论:
- 当多项式回归模型的次数 d=1,也就是高偏差(低拟合)时,训练集和验证集的误差都比较大;
- 当 d=4,也就是高方差(过拟合)时,训练集误差会很小(拟合得非常完美),验证集误差却非常大;
- 当d=2,也就是拟合得刚刚好时,无论训练集误差还是验证集误差都刚刚好,介于上述两者之间。
图形表示如下:
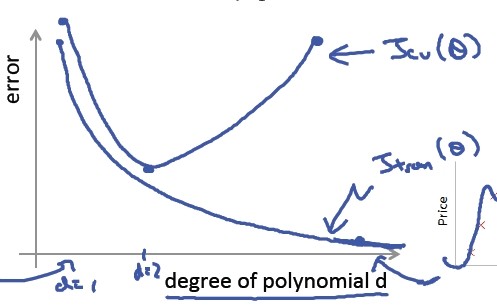
当我们得到一个模型之后,接下来可以诊断是方差还是偏差的问题了,如果两误差值落在上图的“头部”位置,说明是偏差(欠拟合)问题,如果落入“尾部”位置,说明是方差(过拟合)问题,如下图所示:
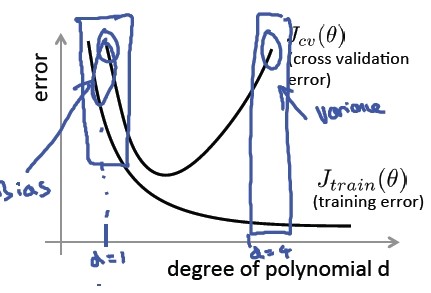
总结一下偏差和方差问题:
Bias (underfit):
Jtrain(θ) will be high Jcv(θ) ≈ Jtrain(θ)
Variance (overfit):
Jtrain(θ) will be low Jcv(θ) >> Jtrain(θ)
Regularization and bias/variance
对于过拟合问题,正则化 Regularization 是一个非常有效的方法,这一小节讲述正则化和偏差/方差的关系。首先看一个正则化的线性回归的例子:
Model: hθ(x) = θ0 + θ1x + θ2x2 +θ3x3 + θ4x4
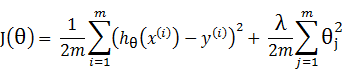
如果正则化参数λ过大,一种极端的情况例如λ=1000,那么除去θ0,所学的其它参数都接近于0,这就导致欠拟合或高偏差的情况:
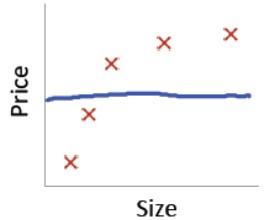
如果λ过小,极端情况是λ=0,等于没有对线性回归模型进行正则化,那么过拟合高方差的问题就很容易出现:
如果λ选择的比较合适,介于上述两者之间,那么我们将得到合适的拟合:
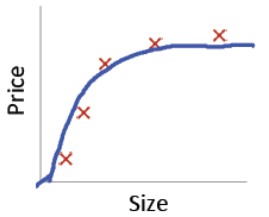
我们通过正则化因子 λ 来解决高偏差/高方差的问题,优化模型,那么,正则化参数 λ 又该如何选择呢?
我们把训练集划分为 3 部分:训练集、验证集、测试集。对于给定的正则化模型,对 λ 从小到大依次取值,然后在训练集上学习模型参数,在交叉验证集上计算验证集误差,选择误差最小的模型,也就是选择使误差最小的 λ,最后在测试集上评估假设。

将偏差/误差作为正则化参数λ的函数,画出函数图:
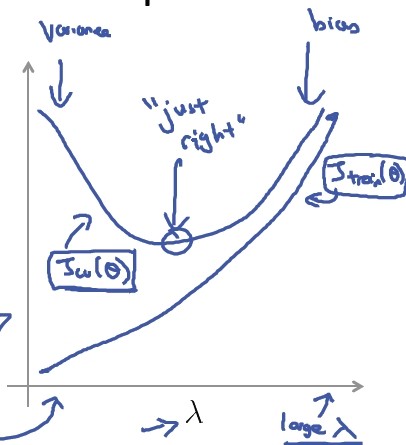
当λ较小时,训练集误差较小(过拟合),交叉验证集误差较大;当λ增加时,训练集误差不断增加(低拟合),而交叉验证集的误差是先减小后增加。以此来评估参数λ的选择范围。
Learning curves
除了λ可以辅助模型的选择外,样本的数目对模型的训练过程会不会有影响呢?以二次项多项式回归为例,如果仅有一个训练样本,那么模型很容易和样本点拟合,训练集误差近似为 0,几乎何以忽略不计,而验证集误差可能很大,如果有 2 个样本,模型也很容易拟合样本点,训练集误差略大,验证集误差稍微好一点,以此类推,当样本点比较多时,模型虽然不能拟合所有的点,但是泛化能力会好一点,也就是说训练集误差会更大一些,验证集误差会小一些,如图所示:
误差和训练样本数目 m 的关系(学习曲线)如下:
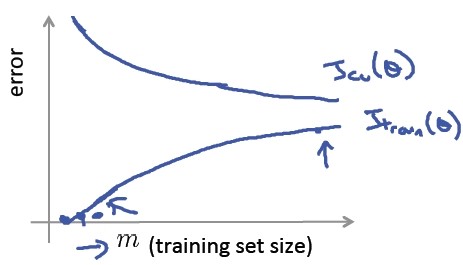
通过学习曲线考虑高偏差和高方差的问题。
a) 高偏差/欠拟合
我们看到,即使增加了训练样本数目,模型拟合得依然不够,还是欠拟合问题,以下是高偏差/欠拟合问题得学习曲线:
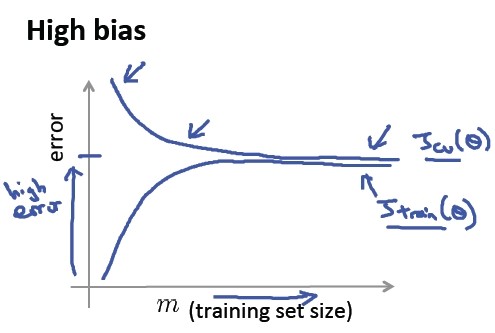
所以,如果一个算法是高偏差/欠拟合的,那么他的训练误差和验证误差在一定样本后都很高,并且随着样本数的增加不会有明显的变化,因此对于高偏差/欠拟合的问题,增加训练样本数目不是一个很好的解决方法。
b) 高方差/ 过拟合

增加样本数目后,模型的泛化能力要好一些,以下是高方差/过拟合问题的学习曲线:

可以看出,与高偏差/低拟合不同,高方差/过拟合的学习算法其训练误差和验证误差在一定的样本数目之后虽然有差异,但是随着样本数的增加,差异会减小,所以对于此类问题,增加训练样本数目是解决方法之一。
Deciding what to try next
分析完偏差/方差的问题,回到最初房价预测模型不准确的问题,下一步该怎么做呢?
- 获取更多的训练样本
- 尝试使用更少的特征的集合
- 尝试获得其他特征
- 尝试添加多项组合特征
- 尝试减小 λ
- 尝试增加 λ
最后看一下神经网络和过拟合问题:
较小的神经网络(参数比较少,容易欠拟合,计算代价小)

较大的神经网络(参数比较多,容易过拟合,计算代价大)
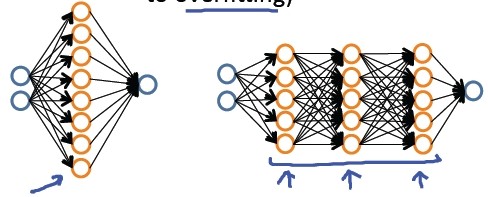
对于神经网络过拟合的问题,可以通过正则化 λ 解决。通常选择较大的神经网络并采用归一化处理会比采用较小的神经网络效果要好。
对于神经网络中的隐藏层的层数的选择,通常从一层开始逐渐增加层数,为了更好地作选择, 可以把数据分为训练集、交叉验证集和测试集,针对不同隐藏层层数的神经网络训练神经网络, 然后选择交叉验证集代价最小的神经网络。
(2) Machine learning system design
Prioritizing what to work on: Spam classification example
首先我们来看一个垃圾邮件分类的问题:
这是一个垃圾邮件,标注为 Spam,用 1 表示;

这个是非垃圾邮件,标注 Non-Spam,用 0 表示。

如果我们有一些标注好的垃圾和非垃圾邮件样本,如何训练一个垃圾邮件分类器呢?很明显这是一个有监督的学习问题,假设我们选择逻辑回归算法来训练这个分类器,定义:
- x = 邮件的特征;
- y = 垃圾邮件(1)或非垃圾邮件(0)
样本是否为垃圾邮件可以人工标注,那邮件的特征如何选择呢?我们可以选择100个典型的词汇集合来代表邮件是垃圾还是非垃圾,deal/buy/discount/Andrew/now 等,将其按字母进行排序,对于已经标注好的邮件训练样本,如果 100个词汇中单词 j 在样本中出现,就用 1 代表特征向量 x中的 xj,否则用 0 表示,这样训练样本就被取值为 0/1 的特征向量 x 代替:

那么,如何高效地训练一个垃圾邮件分类器使其准确率较高,错误率较小呢?
- 首先很自然的考虑到收集较多的数据,例如"honeypot" project,一个专门收集垃圾邮件服务器ip和垃圾邮件内容的项目;
- 但是数据并不是越多越好,所以可以考虑设计其他复杂的特征,例如利用邮件的发送信息,这通常隐藏在垃圾邮件的顶部;
- 还可以考虑设计基于邮件主体内容的特征,例如是否将"discount"和"discounts"看作是同一个词?同理如何处理"deal"和"Dealer"? 还有是否将标点作为特征?
- 最后可以考虑使用复杂的算法来侦测错误的拼写(垃圾邮件会故意将单词拼写错误以逃避垃圾邮件过滤器,例如m0rtgage, med1cine, w4tches)
在这些选择里,非常难决定应该在哪一项上花费时间和精力,做出明智的选择比随着感觉走要更好。
Error analysis
误差分析可以帮助我们系统化地选择应该做什么。
在我们使用机器学习的算法解决实际问题时,建议:
- 从一个简单的算法入手快速实现,并且在交叉验证集上测试
- 画学习曲线决定是需要更多数据,还是更多特征或其它选择
- 错误分析:在交叉验证集上人工检查预测错误的例子,看到能否找到一些产生错误的原因,这些错误样例里是否有一些系统化的趋势,例如某一类原因产生的错误比例较大
假设验证集上有 500 个邮件样本,100 个错误分类,人工 check 这 100个badcase,并且按照如下方式进行分类:
1. 邮件能否按类分组。例如医药品垃圾邮件,仿冒品垃圾邮件或者秘密窃取邮件等。然后看分类器对哪一组邮件的预测误差最大,并着手优化。
2. 思考怎样改进分类器。例如,发现是否缺少某些特征,记下这些特征出现的次数。例如记录错误拼写出现了多少次,异常邮件的路由情况出现了几次等等,然后从错误次数最多的情况进行优化。
在对 badcase 进行分析后,我们可能会考虑如下的方法:
- 对于discount/discounts/discounted/discounting 将它们看作是同一个词
- 使用“词干化”的工具包来取单词的词干
- 设计算法检测并还原拼写错误
- 增加典型的垃圾邮件词汇到样本特征集合
错误分析不能决定上述方法是否有效,它只是提供了一种解决问题的思路和参考,只有在实际的尝试后才能看出这些方法是否有效。所以我们需要对算法进行数值评估(例如交叉验证集误差),来看看使用或不使用某种方法时的算法效果,用数值对模型进行评估,例如:
- (不对单词提前词干:5%错误率)vs(对单词提取词干:3%错误率)
- 对大小写进行区分(Mom / mom):3.2%错误率
Error metrics for skewed classes
类偏斜情况表现为我们的训练集中有非常多的同一种类的实例,只有很少或没有其它类的实例。
以癌症预测或者分类为例,我们训练了一个逻辑回归模型hθ(x). 如果是癌症,y = 1, 否则y = 0。 在测试集上发现这个模型的错误率仅为1%(99%都分正确了),貌似是一个非常好的结果? 但事实上,仅有0.5%的病人得了癌症,如果我们不用任何学习算法,对于测试集中的所有人都预测y = 0,即没有癌症:
function y = predictCancer(x)
y = 0; %ignore x!
return
那么这个预测方法的错误率仅为0.5%,比我们费力训练的逻辑回归模型的结果还要好。这就是一个不对称分类的例子,对于这样的例子,仅仅考虑错误率是有风险的。
现在我们就来考虑一种标准的衡量方法:Precision/Recall(精确度和召回率),也叫查准率/查全率。
首先对正例和负例做如下的定义:
| Actual class | |||
| predicted class | 1 | 0 | |
| 1 | True Positive | False Positive | |
| 0 | False negtive | True negtive | |
其中:
- True Positive(真正例, TP):预测为真,实际为真
- True Negative(真负例 , TN):预测为假,实际为假
- False Positive(假正例, FP):预测为真,实际为假
- False Negative(假负例 , FN):预测为假,实际为真
那么对于癌症预测这个例子我们可以定义:
Precision为预测中实际得癌症的病人数量(真正例)除以我们预测的得癌症的病人数量,提高准确率就是保证在预测为得癌症的时候,尽量保证这个结果是可信的,越高越好。

Recall-预测中实际得癌症的病人数量(真正例)除以实际得癌症的病人数量,提高召回就是保证尽量使得癌症的样例被发现,越高越好。

Trading off precision and recall
假设我们的分类器使用了逻辑回归模型,预测值在0到1之间:0≤hθ(x)≤1,一种通常的判断正负例的方法是设置一个阈值,例如0.5:
如果 h θ(x)≥0.5 ,则预测为1,正例;
如果 h θ(x)<0.5 , 则预测为0,负例;
这个时候,我们就可以计算这个分类器的precision and recall(精确度和召回率):

这个时候,不同的阈值回导致不同的精确度和召回率,那么如何来权衡这二值?对于癌症预测这个例子:
假设我们非常有把握时才预测病人得癌症(y=1), 这个时候,我们常常将阈值设置的很高,这会导致高精确度,低召回率(Higher precision, lower recall);
假设我们不希望将太多的癌症例子错分(避免假负例,本身得了癌症,确被分类为没有得癌症), 这个时候,阈值就可以设置的低一些,这又会导致高召回
率,低精确度(Higher recall, lower precision);
这些问题,可以归结到一张Precision Recall曲线,简称PR-Curve,曲线的形状根据数据的不同而不同:
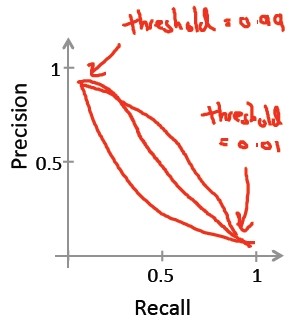
那么如何来比较不同的Precison/Recall值呢?例如,对于下表:
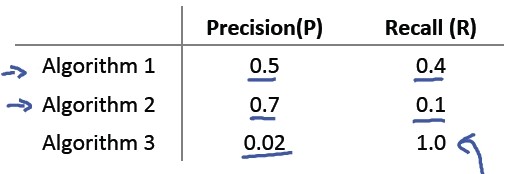
通常我们会考虑用它们的均值来做比较,但是这会引入一个问题,例如上面三组Precision和Recall的均值分别是:0.45, 0.4, 0.51,最后一组最好,但是最后一组真的好吗?如果我们将阈值定的很低,甚至为0, 那么对于所有的测试集,我们的预测都是y = 1, 那么recall 就是1.0,我们根本就不需要什么复杂的机器学习算法,直接预测y = 1就得了,所以,用Precison和Recall的均值不是一个好办法。现在我们引入标准的F值或者F1-score:
![]()
F值是对精确度和召回率的一个很好的权衡,两种极端的情况也能很好的平衡。
Data for machine learning
在设计一个高准确率的机器学习系统时,数据具有多大的意义?2001年的时候,Bank和Brill曾做了一个实验,对易混淆的单词进行分类,也就是在一个句
子的上下文环境中选择一个合适的单词,例如:For breakfast I ate ___ eggs,给定{to, two, too},选择一个合适的单词。 他们用了如下几种机器学习算
法:
- Perceptron(Logistic regression)
- Winnow
- Memory-based
- Naïve Bayes
根据训练集的不同规模记录这几种算法的准确率,并且做了如下的图:
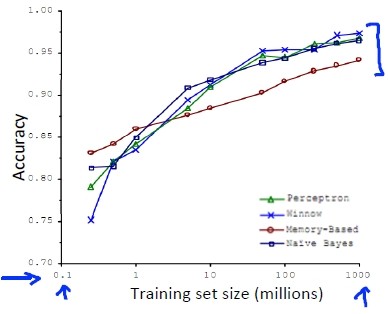
最终得到的结论是:
“It's not who has the best algorithm that wins. It's whohas the most data."
数据量非常大时,这些算法的效果都很好,那么什么时候需要多提供数据,什么时候需要修改算法呢?
通常情况下,首先思考这样一个问题,“在这些特征面前,一个真人专家是否能有信心地预测结果?”如果回答是肯定的,我们需要再思考我们的模型是怎样的。如果算法是高方差的,且代价函数很小,那么增加训练集的数据量不太可能导致过拟合,反而可使得交叉验证误差和训练误差之间差距更小。这种情况下,考虑获得更多数据。
也可以这样来认识,我们希望我们的算法低偏差,低方差,我们通过选择更多的特征来降低偏差,再通过增加数据量来降低方差。
选择大数据的理由?
假设我们的特征x∈Rn+1:
有很多的信息来准确的预测y, 例如,上面的易混淆词分类的例子,它有整个句子的上下文可以利用;反过来,例如预测房价的时候,如果仅有房屋大小这个特征,没有其他的特征,能预测准确吗?
对于这样的问题,一种简单的测试方法是给定这样的特征,一个人类专家能否准确的预测出y?所以我们在给特征的时候,要符合人类的思维逻辑,看给定的特征能否让我们人为去做决策,如果可以,则将特征给计算机,让其从这些特征中去学习。
如果一个学习算法有很多的参数,例如逻辑回归/线性回归就有很多的特征,神经网络有很多隐藏的单元,那么它的训练集误差将会很小,但容易陷入过拟合;如果再使用很大的训练数据,那么它将很难过拟合,它的训练集误差和测试集误差将会近似相等,并且很小。所以大数据对于机器学习还是非常重要的。
HOMEWORK
好了,既然看完了视频课程,就来做一下作业吧,下面是Advice for Applying Machine Learning & Machine Learning System Design部分作业,在此仅列出核心代码:
1.linearRegCostFunction.m
h = X*theta; J = 1/(2*m)*sum((h-y).^2); tp_theta = theta(2:end,:); J = J + lambda/(2*m)*sum(tp_theta.^2); grad(1) = 1/m*(X(:,1)'*(h-y)); grad(2:end) = 1/m*(X(:,2:end)'*(h-y)) + lambda/m*tp_theta;
2.linearRegCostFunction.m
h = X*theta; J = 1/(2*m)*sum((h-y).^2); tp_theta = theta(2:end); J = J + lambda/(2*m)*sum(theta.^2); grad(1) = 1/m*(X(:,1)'*(h-y)); grad(2:end) = 1/m*(X(:,2:end)'*(h-y)) + lambda/m*tp_theta;
3.learningCurve.m
for i=1:m x_train = X(1:i,:); y_train = y(1:i); x_val = Xval(1:i,:); y_val = yval(1:i); theta = trainLinearReg(x_train ,y_train ,lambda); [J_train,grad_train] = linearRegCostFunction(x_train,y_train,theta,0); [J_val,grad_val] = linearRegCostFunction(Xval,yval,theta,0); error_train(i) = J_train; error_val(i) = J_val; end
4.polyFeatures.m
for d = 1:p X_poly(:,d) = X(:,1).^d; end
5.validationCurve.m
for i = 1:length(lambda_vec) lambda = lambda_vec(i); theta = trainLinearReg(X,y,lambda); [J_train,grad_train] = linearRegCostFunction(X,y,theta,0); [J_val,grad_val] = linearRegCostFunction(Xval,yval,theta,0); error_train(i) = J_train; error_val(i) = J_val; end

 浙公网安备 33010602011771号
浙公网安备 33010602011771号