HDU 1247 Hat’s Words(字典树)
题目代号:HDU 1247
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1247
Hat’s Words
Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submission(s): 15950 Accepted Submission(s): 5701
Problem Description
A hat’s word is a word in the dictionary that is the concatenation of exactly two other words in the dictionary.
You are to find all the hat’s words in a dictionary.
You are to find all the hat’s words in a dictionary.
Input
Standard input consists of a number of lowercase words, one per line, in alphabetical order. There will be no more than 50,000 words.
Only one case.
Only one case.
Output
Your output should contain all the hat’s words, one per line, in alphabetical order.
Sample Input
a
ahat
hat
hatword
hziee
word
Sample Output
ahat
hatword
题目大意:给你N个单词,问哪些单词是由另外两个单词拼凑而成的,然后输出所有满足要求的单词。
解题思路:构建字典树,将所有单词插入树中,然后将每个单词分割成所有可能的两个部分然后进行查询即可。
下面是个人根据例题所构建的树的抽象状态:红点代表是某个单词的结尾字母。
自己画的,有点丑别介意。。。
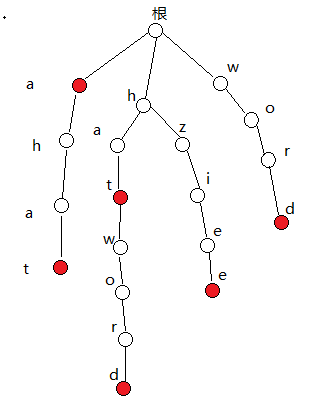
ps:指针方式很容易出错,而且出bug了会非常的难寻找和进行调试
AC代码:
///delet....................................
# include <iostream>
# include <cstring>
# include <cstdlib>
# include <cstdio>
# include <string>
# include <cmath>
# include <ctime>
# include <set>
# include <map>
# include <queue>
# include <stack>
# include <vector>
# include <fstream>
# include <algorithm>
using namespace std;
# define eps 1e-8
# define pb push_back
# define pi acos(-1.0)
# define bug puts("H");
# define mem(a,b) memset(a,b,sizeof(a))
# define IOS ios::sync_with_stdio(false)
# define FO(i,n,a) for(int i=n; i>=a; --i)
# define FOR(i,a,n) for(int i=a; i<=n; ++i)
# define INF 0x3f3f3f3f
# define MOD 1000000007
/// 123456789
//# pragma comment(linker, "/STACK:1024000000,1024000000")
typedef unsigned long long ULL;
typedef long long LL;
inline int Scan(){
int x=0,f=1; char ch=getchar();
while(ch<'0'||ch>'9'){if(ch=='-') f=-1;ch=getchar();}
while(ch>='0'&&ch<='9'){x=x*10+ch-'0';ch=getchar();}
return x*f;
}
///coding...................................
const int MAXM=26;
char a[50005][55];
typedef struct trie_node {
bool word_eof;//代表某个点是否为单词的结尾,如果是则为1否则为0
struct trie_node *next[MAXM];
// trie_node(){word_eof=0;FOR(i,0,25)next[i]=NULL;}//想通过构造函数来对结构体进行初始化但是失败了,无奈之下只能额外初始化
}node;
void init(node *root) {
FOR(i,0,25)root->next[i]=NULL;
root->word_eof=false;
}
void Insert(node *root,char *word) {
node *p=root;
while(*word) {//cout<<p->next[*word-'a']<<endl;
if(p->next[*word-'a']==NULL) {
node *t=(node *)malloc(sizeof(node));
init(t);
p->next[*word-'a']=t;
}
p=p->next[*word-'a'];
++word;
}
p->word_eof=true;
}
bool Search(node *root,char *word) {
node *p=root;
for(int i=0;word[i];++i) {
if(p==NULL||p->next[word[i]-'a']==NULL)return false;
p=p->next[word[i]-'a'];
}
return p->word_eof;
}
void Delete(node *root) {
FOR(i,0,25)if(root->next[i]!=NULL)Delete(root->next[i]);
free(root);
}
int main()
{
IOS;
#ifdef FLAG
freopen("in.txt","r",stdin);
// freopen("out.txt","w",stdout);
#endif /// FLAG
int ans=0;
char t1[55],t2[55];
node *root=(node *)malloc(sizeof(node));
init(root);
while(cin>>a[++ans])Insert(root,a[ans]);
FOR(i,1,ans-1)FOR(j,1,strlen(a[i])-1){
mem(t1,0);
mem(t2,0);
strncpy(t1,a[i],j);//strncpy函数可以对字符串进行切割操作,如不了解建议百度一下用法
strncpy(t2,a[i]+j,strlen(a[i])-j);
if(Search(root,t1)&&Search(root,t2)) {
cout<<a[i]<<endl;
break;
}
}
Delete(root);
return 0;
}
///delete # define FLAG......................

 浙公网安备 33010602011771号
浙公网安备 33010602011771号