
团队作业三:确定分工
一、修改规格说明书
初稿:

初稿存在的不足:
-
表述简明扼要:有些句子可以更加简洁明了,避免过度复杂的措辞,以提高可读性。
-
段落分隔:将原文分成几个段落,以便更好地组织和突出重点。
-
具体性:有些地方可以提供更具体的例子或情景,以便读者更好地理解系统的功能和特性。
-
结构和流程:在描述背景时,考虑了按照逻辑顺序来组织句子和段落,以确保介绍的流畅自然。
修改后:
初稿:

初稿存在的不足之处:
-
更具体的示例或场景:在描述高级隐蔽通信、公文加密传输等功能时,可以举例说明具体的应用场景,让读者更好地理解这些功能的实际应用。
-
可能的使用限制:在介绍功能时,可以提及一些可能的限制或特定环境下的注意事项,以帮助用户了解系统的使用范围。
-
功能之间的关联:可以描述一些功能之间的互相配合和影响,以便读者了解它们之间的关联性。
-
用户体验和界面设计:可以简要介绍一下用户界面的设计原则和用户体验考虑,以确保用户能够轻松上手。
-
安全性和稳定性保证:可以提及一些系统内置的安全措施和稳定性保证,让用户对系统的可靠性有更高的信心。
修改后:

初稿:

初稿存在的不足:
-
更具体的测试用例:对于每个测试项目,可以考虑提供更具体的测试用例,以便清晰地说明如何进行测试。
-
测试环境的说明:可以考虑在每个测试项目后面添加一个说明,描述进行该项测试时所需的具体环境或条件。
-
异常情况的测试:在故障处理与监控部分,可以进一步明确模拟的故障情况,并描述系统如何应对这些异常情况。
-
详细的性能测试方案:对于系统性能与稳定性测试,可以提供更详细的测试方案,包括如何模拟高并发场景和大数据量情况。
-
更强调用户体验:可以在通知与提醒功能部分,强调系统在提醒时的用户友好性和及时性。
修改后:



二、代码规范部分
(一)、代码规范
代码规范可以分成两个部分:
1.代码风格规范,主要是文字上的规定;
2.代码设计规范,牵涉到程序设计、模块之间的关系、设计模式等方方面面的通用原则。
(二)、代码风格规范
1.代码风格的原则是:简明、易读、无二义性。
2.缩进、括号和分行
缩进:将Tab键扩展定义为4个空格。不直接使用tab键的原因是它在不同的情况下会显示不同的长度。4个空格可读性高;
行宽:行宽必须限制,建议100字符;
括号:在复杂的条件表达式中,用括号清楚地表示逻辑优先级;
3.断行与空白的{}行:
4.分行:不要把多中不同的操作放在同一行(书中建议“不要把多个变量定义在一行”,可能会使代码不够简洁);
5.命名:“匈牙利命名法”;
6.下划线:分隔变量名字中的作用域标注的变量的语义;
7.大小写:全部大写、小写会导致不易读,所有的类型/类/函数名用 Pascal 形式(每个单词首字母大写),所有变量都用 Camel (第一个单词小写,后面用 Pascal );
8.注释:解释程序做什么,为什么这样做。复杂的注释放在函数头,解释参数,要不断更新(书中建议使用ASCII码以增强可移植性,但实际操作复杂,我们不做这方面的要求);
(三)、代码设计规范
1.函数:只做一件事,做好一件事;
2.goto:
可使用goto实现函数的单一出口(但也要尽量少使用),
助于程序逻辑的清晰体现
3.错误处理:
参数处理、断言。
在Debug版本中,所有参数都要验证其正确性,在正式版本中,对外部转递就俩的参数要验证其正确性;
4、运算符:
一般情况下不需要自定义操作符,运算符不要做标准语义以外的任何动作。运算符的实现必须非常有效率,如有复杂的操作,应定义一个单独的函数;
3.1 单一职责原则 Single Responsibility Principle
一个类或者一个接口,最好只负责一项职责。
遵循单一职责原则。分别建立新的类来对应相应的职责;这样就能避免修改类时影响到其他的职责;
3.2 里氏替换原则 Liskov Substitution Principle
在使用基类的地方可以任意使用其子类,能保证子类完美替换基类;这一种精神其实是对继承机制约束规范的体现。在父类和子类的具体实现中,严格控制继承层次中的关系特征,以保证用子类替换基类时,程序行为不发生问题,且能正常进行下去。
对于继承来说,父类定义了一系列的规范和契约,虽然不强制所有的子类必须遵从,但是如果子类对这些非抽象方法任意修改,就会对整个继承体系造成破环。
3.3依赖倒置原则 Dependence Inversion Principle
高层模块不应该依赖低层模块,二者都应该依赖其抽象;抽象不应该依赖细节;细节应该依赖抽象,其核心思想是依赖于抽象;
问题由来:类A直接依赖类B,假如要将类A改为依赖类C,则必须通过修改类A的代码来完成;这种场景下,类A一般是高层模块,负责复杂的业务逻辑;类B和类C是低层模块,负责基本的原则操作;假如修改类A,会给程序带来不必要的风险。
在实际中,我们一般需要做到以下三点:
低层模块尽量都要有抽象类或者接口,或者两者都有;
变量的声明类型尽量是抽象类或者接口;
使用继承时遵循里氏替换原则;
解决方案:将类A修改为依赖接口I,类B和类C各自实现接口I,类A通过接口I来间接与类B和类C发生联系,则会降低修改类A的几率;
3.4接口隔离原则 Interface Segregation Principle
客户端不应该依赖它不需要的接口;一个类对另一个类的依赖应该建立在最小的接口上,否则将会造成接口污染;类A通过接口I依赖类B,类C通过接口I依赖类D,如果接口I对于类A和类B来说不是最小接口,则类B和类D必须去实现它们不需要的方法;
原则的含义是:建立单一接口,不要建立庞大臃肿的接口,尽量细化接口,接口中的方法尽量少;就是说,我们要为每个类建立专用的接口,而不要试图去建立一个庞大的接口供所有依赖它的类去调用;
如何实施接口隔离,主要有两种方法:
委托分离,通过增加一个新的接口类型来委托客户的请求,隔离客户和接口的直接依赖,注意这同时也会增加系统的开销;
多重继承分离,通过接口的多重继承来实现客户的需求;
3.5迪米特法则
一个对象应该对其他对象保持最少的了解,其核心精神就是:不和陌生人说话,通俗之意就是一个对象对自己需要耦合关联调用的类应该知道的少;这会导致类之间的耦合度降低,每个类都尽量减少对其他类的依赖。
3.6合成复用原则
原则是尽量使用合成/聚合的方式,而不是使用继承;
3.7开闭原则
一个软件实体如类、模版和函数应该对扩展,对修改关闭;
解决方案:当软件需要变化时,尽量通过扩展软件实体的行为来实现变化,而不是修改已有的代码来实现变化;
单一职责原则:实现类要职责单一;
里氏替换原则:不要破坏继承体系;
依赖倒置原则:面向接口编程;
接口隔离原则:设计接口的时候要精简单一;
迪米特法则:降低耦合;
开闭原则:总纲,对扩展开放,对修改关闭;
3.8命名规范
函数命名规范:使用驼峰法,其基本原则为:动作+(关联)+内容 例如:getUserName(获取用户名字)。
变量命名:采用匈牙利命名法,其基本原则是:变量名=属性+类型+对象描述。
命名大小写规范:所有函数名使用Pascal形式命名,即所有单词的第一个字母都大写。所有类型和变量名使用Camel方式命名,即第一个单词使用小写开头,后面都用大写字母开头。 ##注释要求
必须的注释:注释用于解释程序做什么(what)、为什么(why)和其他需要注意的地方。函数头写注释,标记本函数的作用。较难理解的部分必须写注释。
不需要注释:不刻意写注释,不需要解释就能读懂的部分不写注释。
(四)、代码复审
形式:
自我复审、同伴复审、团队复审
目的:
找出代码错误、发现逻辑错误、发现算法错误、发现潜在的错误和回归性错误、发现可能需要改进的地方、传授经验
代码复审后把记录整理出来:
更正明显的错误
记录无法很快更正的错误
把所有的错误记在自己的一个“我常犯的错误”表中,作为以后自我复审的第一步
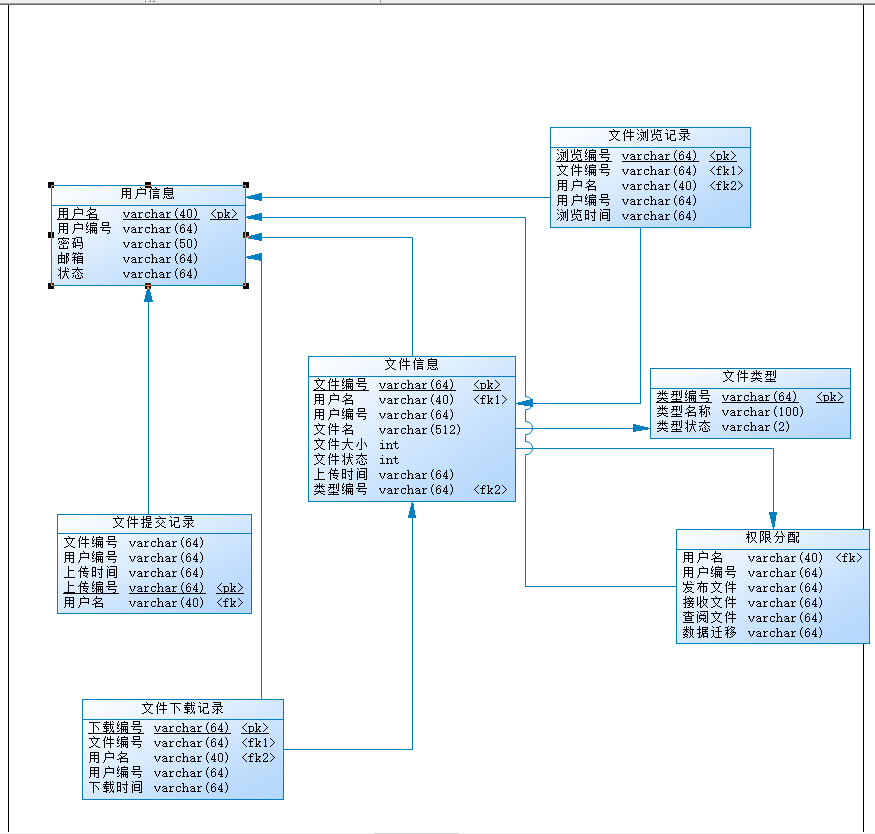
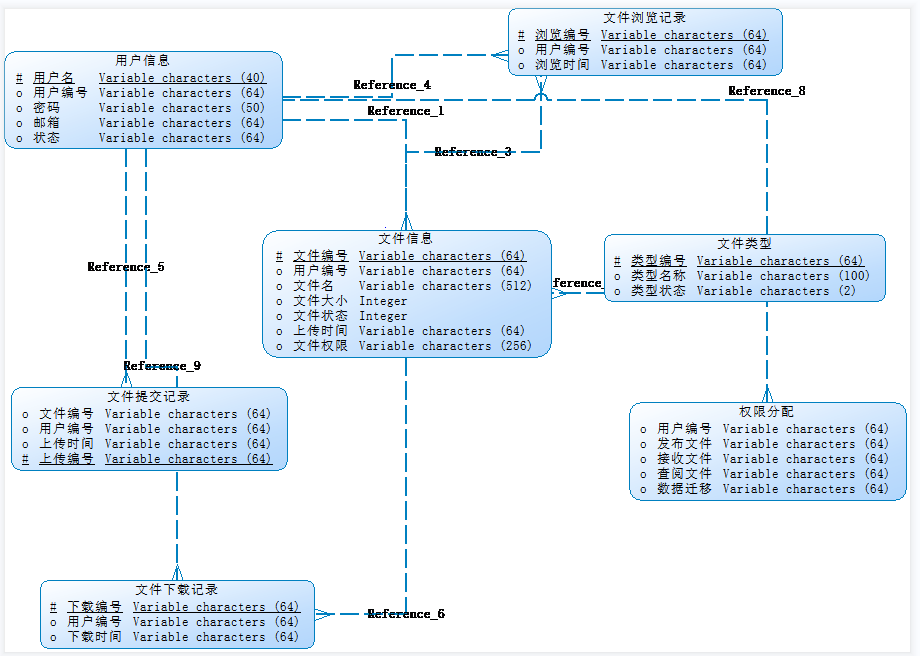
三、ER图


四、后端架构设计
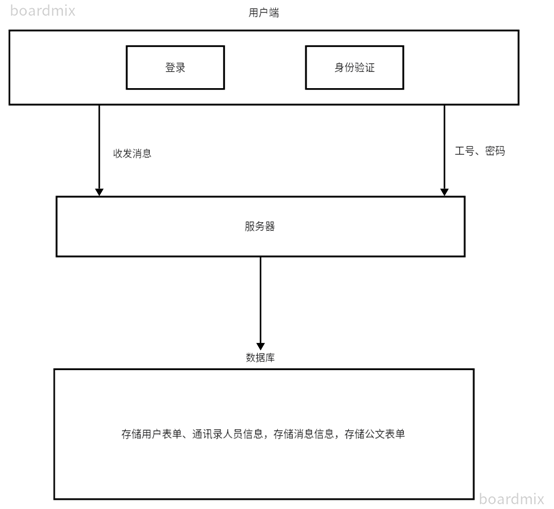
用户表:
CREATE TABLE users (
user_id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50) NOT NULL,
password_hash VARCHAR(100) NOT NULL,
email VARCHAR(100) NOT NULL,
department VARCHAR(100),
role VARCHAR(50),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
user_id: 用户的唯一标识符。
username: 用户名,是一个必填字段。
password_hash: 密码的散列值,通常存储经过加密的密码。
email: 用户的电子邮件地址,也是一个必填字段。
role: 用户的角色,例如管理员、普通用户等。
created_at: 用户记录的创建时间戳,设置默认值为当前时间。
updated_at: 用户记录的最后更新时间戳,设置默认值为当前时间,并在更新时自动更新。
公文表:
CREATE TABLE documents (
document_id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(100) NOT NULL,
content TEXT NOT NULL,
author_id INT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
document_id: 公文的唯一标识符。
title: 公文的标题,是一个必填字段。
content: 公文的内容,可以是文本字段。
author_id: 公文的作者的唯一标识符,是一个必填字段,通常是对应到用户表格中的 user_id。
sender_id: 用于存储发送者的唯一标识符,通常是对应到用户表格中的 user_id。
recipient_id: 用于存储接收者的唯一标识符,也对应到用户表格中的 user_id。
当创建新的公文时,可以将发送者的 user_id 存储在 sender_id 中,将接收者的 user_id 存储在 recipient_id 中
created_at: 公文创建时间戳,设置默认值为当前时间。
updated_at: 公文的最后更新时间戳,设置默认值为当前时间,并在更新时自动更新。
发送者和接收者:
日志表:
CREATE TABLE logs (
log_id INT AUTO_INCREMENT PRIMARY KEY,
user_id INT NOT NULL,
action VARCHAR(255) NOT NULL,
timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
details TEXT
);
log_id: 日志记录的唯一标识符。
user_id: 执行操作的用户的唯一标识符,通常是对应到用户表中的 user_id。
action: 记录用户执行的操作,例如 "创建文档"、"更新用户信息" 等。
timestamp: 记录操作的时间戳,设置默认值为当前时间。
details: 记录有关操作的详细信息,可以是文本字段,用于存储额外的上下文或描述信息。
五、确定团队分工
1.优先级划分与WBS图
利用象限法确定各个核心需求的优先级,依据需求优先级确定团队Alpha 版本需要实现的功能,在博客中叙述并给出相应的WBS图。
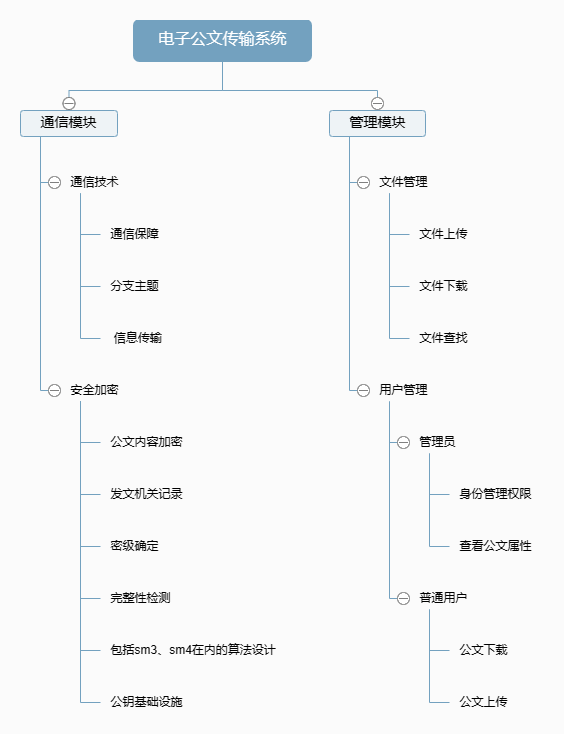
我们将整个系统分为两大模块,一部分为面向内部的技术——通信模块,另一部分为表面可以看到的——管理模块。其中通信模块中包含通信技术和安全加密两部分,管理模块包含文件管理和用户管理两部分。
2.确定工作量
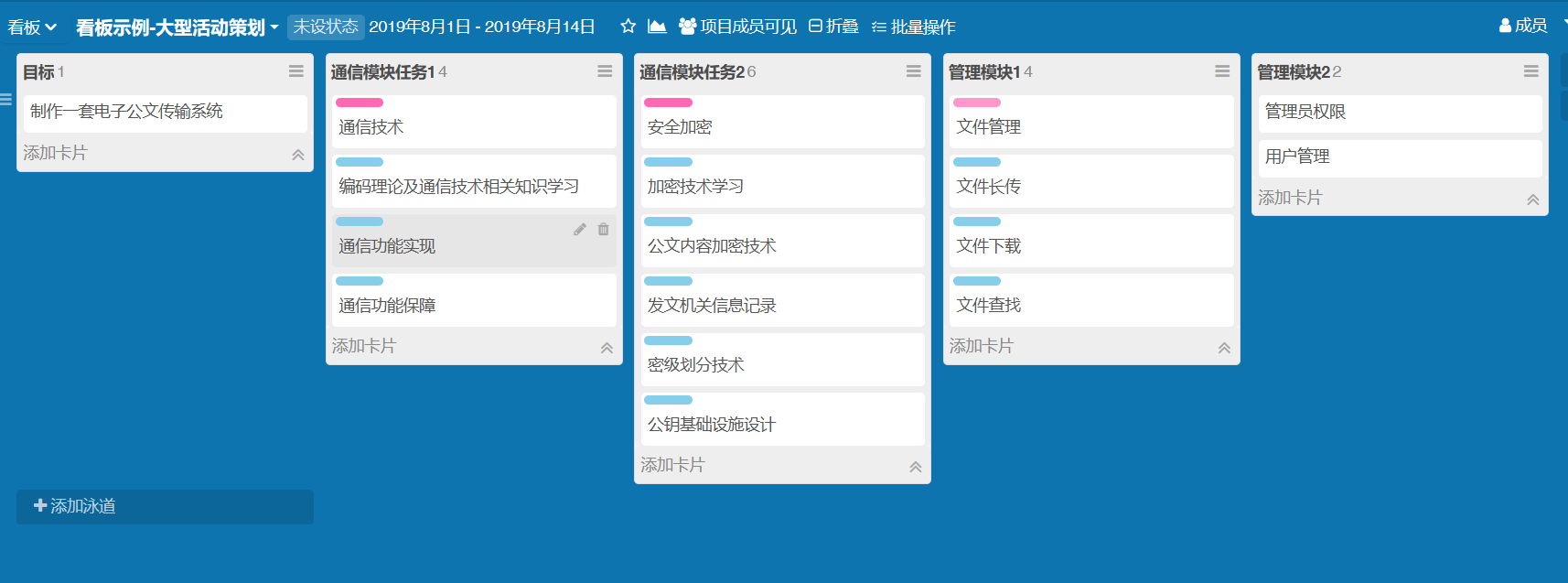
在团队管理软件中(比如Github的Issue,Leangoo等)将各个叶子结点的功能加入,并确定每个子功能的工作量,在博客中给出分配后的截图。值得注意的是,与学习技术相关的任务也需要考虑在工作量中,开发需要检验产出,学习同样要有结果。PM可以用小Demo演示或学习心得博客作为学习任务的检验。
3.燃尽图
六、分工和工作量
| 成员 | 分工 | 比例 |
|---|---|---|
| 邹雪梅 | ER图设计 | 20% |
| 杨云泰 | 修改说明书与制定编码规范 | 20% |
| 王艺达 | 修改说明书与制定编码规范 | 20% |
| 李天赐 | 确定团队分工 | 20% |
| 魏子俊 | 后端架构设计 | 20% |
