滑块验证之反反爬
问题
在正常登录时,我们手动划过滑块是可以的,但采用selenium时遇到滑块怎么办呢?
方案
常规的解决方案2种:
1. 下载该图片,采用机器学习识别出缺省的图片特征,记录缺省位置的坐标。再通过selenium的滑动方法滑到指定坐标。
2. 通过手动划过去,遇到滑块时我们在脚本里不管它,直接走划过去之后的流程。
鉴于时间与学习成本,通常我们采用的是第二种方式,即人工划过去。
问题升级
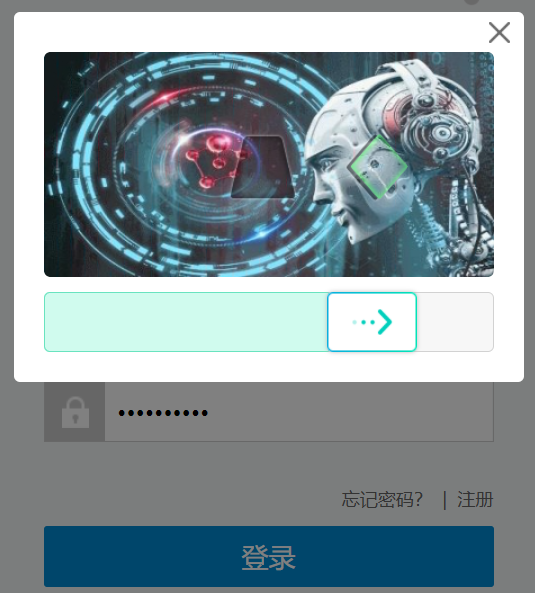
然而理想是好的,如果网站对selenium做了反爬处理,那么手动也划不过去。
也就是说,我们正常登录网站没问题,但是用selenium登录就过不去啦。
该怎么办呢?
方案升级
1. 通过中间人代理-mitmproxy,可惜该方法也是有一定几率通不过的。
from mitmproxy import ctx def response(flow): """修改应答数据 """ if '/libs/greenseer.' in flow.request.url: # 屏蔽selenium检测 for webdriver_key in [ 'webdriver', '__driver_evaluate', '__webdriver_evaluate', '__selenium_evaluate', '__fxdriver_evaluate', '__driver_unwrapped', '__webdriver_unwrapped', '__selenium_unwrapped', '__fxdriver_unwrapped', '_Selenium_IDE_Recorder', '_selenium', 'calledSelenium', '_WEBDRIVER_ELEM_CACHE', 'ChromeDriverw', 'driver-evaluate', 'webdriver-evaluate', 'selenium-evaluate', 'webdriverCommand', 'webdriver-evaluate-response', '__webdriverFunc', '__webdriver_script_fn', '__$webdriverAsyncExecutor', '__lastWatirAlert', '__lastWatirConfirm', '__lastWatirPrompt', '$chrome_asyncScriptInfo', '$cdc_asdjflasutopfhvcZLmcfl_' ]: ctx.log.info('Remove "{}" from {}.'.format(webdriver_key, flow.request.url)) flow.response.text = flow.response.text.replace('"{}"'.format(webdriver_key), '"NO-SUCH-ATTR"') flow.response.text = flow.response.text.replace('t.webdriver', 'false') flow.response.text = flow.response.text.replace('ChromeDriver', '')
2. 构造cookie
假如你之前没有过cookie登录该网站的先例,那么下面的忽略。如果有,可以继续往下看。
众所周知,selenium支持添加cookie的方法,我们需要构造出cookie文件。
如果之前用cookie登录过而且cookie没过期,那么可以直接用。如果cookie过期了,观察之前的cookie文件特征,需要修改过期的关键字expiry对应的值,以及与session对应的关键字的值,具体还需要哪些值得根据cookie文件的特征来,这就需要我们敏锐的判断力了。
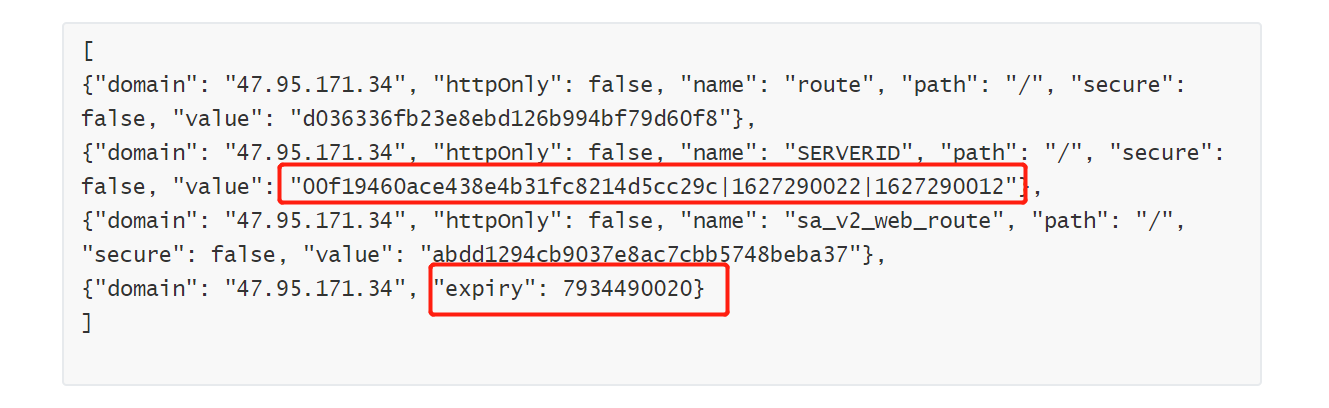
总之,每一次对抗升级,爬虫工程师免不了死大量脑细胞。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号