
领域驱动设计
1.什么是领域驱动设计(DDD:Domain Driven Design)
领域驱动设计(DDD)是一种基于模型驱动的软件设计方式。它以领域为核心,分析领域中的问题,通过建立一个领域模型来有效的解决领域中的核心的复杂问题。领域驱动设计提出了一套核心构造块(如聚合、实体、值对象、领域服务、领域工厂、仓储、领域事件,等),这些构造块是对面向对象领域建模的一些核心最佳实践的浓缩。这些构造块可以使得我们的设计更加标准、有序。
什么是领域:领域本质上可以理解为就是一个问题域,只要是同一个领域,那问题域就相同。任何一个系统都会属于某个特定的领域,比如论坛是一个领域,只要你想做一个论坛,那这个论坛的核心业务是确定的,比如都有用户发帖、回帖等核心基本功能。比如电商平台、普通电商系统,这种都属于网上电商领域,只要是这个领域的系统,那都有商品浏览、购物车、下单、减库存、付款交易等核心环节。所以,同一个领域的系统都具有相同的核心业务,因为他们要解决的问题的本质是类似的
什么是驱动:领域驱动领域模型设计,领域模型驱动代码实现。这个就和我们传统的数据库驱动开发的思路形成对比了。DDD中,我们总是以领域为边界,分析领域中的核心问题(核心关注点),然后设计对应的领域模型,再通过领域模型驱动代码实现。而像数据库设计、持久化技术等这些都不是DDD的核心,而是外围的东西。
什么是设计:DDD中的设计主要指领域模型的设计。DDD是一种基于模型驱动开发的软件开发思想,强调领域模型是整个系统的核心,领域模型也是整个系统的核心价值所在。每一个领域,都有一个对应的领域模型,领域模型能够很好的帮我们解决复杂的业务问题。
理解领域:假设你现在打算做一个电商平台,但是你对这个领域没什么了解,那你一定得先去了解下该领域内主流的电商平台,比如淘宝、天猫、京东、亚马逊等。这个了解的过程就是你沉淀领域知识的过程。虽然我们明确了要做一个什么样的系统,该系统主要解决什么问题,但是就这样我们还无法开始进行实际的需求分析和模型设计,我们还必须将我们的问题进行拆分,需求进行细化。要知道一个系统到底该做成什么样子,到底哪些是核心业务关注点,只能靠沉淀领域内的各种知识,别无他法。。
拆分领域:有时一个领域往往太复杂,涉及到的领域概念、业务规则、交互流程太多,导致我们没办法直接针对这个大的领域进行领域建模。所以,我们需要将领域进行拆分,本质上就是把大问题拆分为小问题,然后各个击破的思路。然后既然把一个大的领域划分为了多个小的领域(子域),那最关键的就是要理清每个子域的边界;然后要搞清楚哪些子域是核心子域,哪些是非核心子域,哪些是公共支撑子域;然后,还要思考子域之间的联系是什么。拿经典的电商系统来分析,通常一个电商系统都会包含好几个大块,比如:
- 会员中心:负责用户账号登录、用户信息的管理;
- 商品中心:负责商品的展示、导航、维护;
- 订单中心:负责订单的生成和生命周期管理;
- 交易中心:负责交易相关的业务;
- 库存中心:负责维护商品的库存;
- 促销中心:负责各种促销活动的支持;
上面这些中心看起来很自然,因为大家对电子商务的这个领域都已经非常熟悉了,所以都没什么疑问,好像很自然的样子。之所以我们觉得子域划分很简单,是因为我们对整个大领域非常了解了。如果我们遇到一个冷门的领域,就没办法这么容易的去划分子域了。这就需要我们先去努力理解领域内的知识。子域划分没有什么技巧,这个工作没有任何诀窍可以使用。当我们对整个领域有一定的熟悉了,了解了领域内的相关业务的本质和关系,我们就自然而然的能划分出合理的子域了。不过并不是所有的系统都需要划分子域的,有些系统只是解决一个小问题,这个问题不复杂,可能只有一两个核心概念。所以,这种系统完全不需要再划分子域。
细化子域:了领域里的知识,也对领域进行了子域划分。但这样还不够,凭这些我们还无法进行后续的领域模型设。还必须再进一步细化每个子域,进一步明确每个子域的核心关注点,即需求细化,们需要细化的方面有以下几点:
- 梳理领域概念:梳理出领域内我们关注的概念、概念的关系,并统一交流词汇,形成统一语言;
- 梳理业务规则:梳理出领域内我们关注的各种业务规则,DDD中叫不变性(invariants),比如唯一性规则,余额不能小于零等;
- 梳理业务场景:梳理出领域内的核心业务场景,比如电商平台中的加入购物车、提交订单、发起付款等核心业务场景;
- 梳理业务流程:梳理出领域内的关键业务流程,比如订单处理流程,退款流程等;
从上面这4个方面,我们从领域概念、业务规则、交互场景、业务流程等维度梳理了我们到底要什么,整理了整个系统应该具备的功能。这个工作是一个非常具有创造性和有难度的工作。我们一方面会主观的定义我们想要什么;另一方面,我们还会思考我们要的东西的合理性。
关于领域概念的梳理,我觉得可以采用四色原型分析法,这个分析法通过系统的方法,将概念划分为不同的种类,为不同种类的概念标注不同的颜色。然后将这些概念有机的组合起来,从而让我们可以清晰的分析出概念和概念之间的关系。有兴趣的同学可以在网上搜索下四色原型。
2.DDD中的一些定义:
领域:用户会把软件程序应用于某个主体区域,这个区域就是软件的领域。简单来说,就认为是公司的某块业务好了。如果领域比较大,可以将其拆分为多个子域,子域包含核心域和支撑子域,核心域顾名思义,是最重要的子域,我们应该把关注点集中在它上面;其余的子域都是支撑子域。支撑子域里有一类特殊的用于解决通用问题的子域,称为通用子域,例如用户和权限等。不过这些都是相对而言的,对于消费方来说,他的支撑子域有可能就是你的核心域。个别子域可能会有交集,称为共享内核,目的是减少重复,但是仍保持两个独立的上下文。由于不同子域的开发团队可能会同时修改共享内核,所以需要小心并注意沟通。
限界上下文: 通用语言里,同一个名词在不同的场景里不一定有相同的意思。比如用户,在推荐好友(可能关注年龄、性别、地域)或是浏览商品(可能关注喜好、历史购买记录)的时候有着不同的含义。所谓的不同的场景,其实就是不同的限界上下文。不同的限界上下文之间,通过上下文映射图来进行交互。上下文映射图其实就是一个简单的框图,表示限界上下文之间的的映射关系,这张图就是一个简单的例子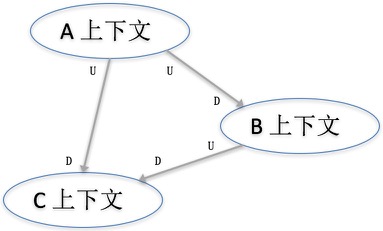 U表示上游被依赖方,D表示下游依赖方。由于上下游的限界上下文模型不同,实现时,可以用RPC、Restful、消息机制等集成方式。下游需要防腐层来将上游的返回内容翻译为下游的领域模型。
U表示上游被依赖方,D表示下游依赖方。由于上下游的限界上下文模型不同,实现时,可以用RPC、Restful、消息机制等集成方式。下游需要防腐层来将上游的返回内容翻译为下游的领域模型。
关于领域、领域模型、限界上下文的关系:
- 领域就是问题域,问题空间;
- 领域模型是一种模型,表达了领域中哪些业务需求以及业务规则必须被满足;
- 每一个领域中的问题,都会有一个对应的领域模型去解决;
- 限界上下文的作用是用来对领域模型进行划分;
- 划分领域就是对问题空间的划分,通俗的理解,就是将大问题拆分为小问题;
- 划分限界上下文就是将一个大的领域模型划分为多个小的领域模型;
- 可以把限界上下文看成是一种解决方案空间,所以,限界上下文也可以理解为是对解决方案空间的划分;
- 理论上,一个领域可能会对应多个限界上下文;同样,一个限界上下文可能也会对应多个领域;所以他们之间没有绝对的关系。主要是他们划分的依据不同,一个是针对领域(问题空间),一个是针对领域模型(解决方案空间);理想情况,一个领域最好对应一个限界上下文;
关于领域、子领域、核心子域、通用子域,以及共享内核的理解:
- 一个领域会拆分为多个子领域;
- 子领域中最核心(最重要)的那个叫核心子域;我们应该讲团队的核心资源用在核心子域上,因为它是产品成败的关键;
- 除了核心子域外,其他的是支撑子域;
- 有些支撑子域比较特殊,因为它解决的是一类通用问题,比如账号和权限;这类子域我们叫做通用子域;通常,通用子域对应的限界上下文,会跨域多个子域;
- 多个子领域有时会有相交的部分,我们称作共享内核;体现到代码上,就是同一份代码,在两个领域模型中复用;
实体:实体是有标识的,两个拥有相同属性的实体不是相等的,除非它们的标识相等;而不同实体的标识不能相等。实体有生命周期,实体从被创建后可能会被持久化到数据库,然后某个时候又会被取出来
例如:某人下了两个相同的订单,里面都购买了相同的商品。这两个订单就是有标识(订单号)的两个实体,虽然内容相同,但它们是两个不同的实体。实体作为领域模型的主体,需要拥有自己的方法,方法名来自于通用语言。通过这些方法来保证自己始终是一致的状态,而非被调用者set来set去。例如:people.runTo(x, y),而非people.setX(x);people.setY(y);
值对象:值对象只用于描述或度量一个东西。值对象没有任何标识,只要两个值对象的属性相等,那么它们就是相等的。值对象是不可变的,如果要改变值对象的内容,那就重新创建一个值对象。值对象没有生命周期,因为它只是值而已。例如:金额(含数值和货币单位),颜色(含rgb值)等
聚合及聚合根:聚合表示一组领域对象(包括实体和值对象),用来表述一个完整的领域概念,而每个聚合都有一个根实体,这个根实体又叫做聚合根。举个简单的例子,一个电脑包含硬盘、CPU、内存条等,这一个组合就是一个聚合,而电脑就是这个组合的聚合根。。聚合根是聚合所表述的领域概念的主体,外部对象需要访问聚合内的实体时,只能通过聚合根进行访问,而不能直接访问。关于聚合的划分学问还是挺大的,需要在实践中慢慢积累。同一个实体,在不同的聚合中,它可能是聚合根,也可能不是,需要根据实际的业务决定。
聚合根,实体,值对象区别和联系:GH0R8)%L_N%G8R.png")
聚合有以下一些特点:
- 每个聚合有一个根和一个边界,边界定义了一个聚合内部有哪些实体或值对象,根是聚合内的某个实体;
- 聚合内部的对象之间可以相互引用,但是聚合外部如果要访问聚合内部的对象时,必须通过聚合根开始导航,绝对不能绕过聚合根直接访问聚合内的对象,也就是说聚合根是外部可以保持 对它的引用的唯一元素;
- 聚合内除根以外的其他实体的唯一标识都是本地标识,也就是只要在聚合内部保持唯一即可,因为它们总是从属于这个聚合的;
- 聚合根负责与外部其他对象打交道并维护自己内部的业务规则;
- 基于聚合的以上概念,我们可以推论出从数据库查询时的单元也是以聚合为一个单元,也就是说我们不能直接查询聚合内部的某个非根的对象;
- 聚合内部的对象可以保持对其他聚合根的引用;
- 删除一个聚合根时必须同时删除该聚合内的所有相关对象,因为他们都同属于一个聚合,是一个完整的概念;
如何识别聚合?
这个需要从业务的角度深入分析哪些对象它们的关系是内聚的,即我们会把他们看成是一个整体来考虑的;然后这些对象我们就可以把它们放在一个聚合内。所谓关系是内聚的,是指这些对象之间必须保持一个固定规则,固定规则是指在数据变化时必须保持不变的一致性规则。当我们在修改一个聚合时,我们必须在事务级别确保整个聚合内的所有对象满足这个固定规则。作为一条建议,聚合尽量不要太大,否则即便能够做到在事务级别保持聚合的业务规则完整性,也可能会带来一定的性能问题。有分析报告显示,通常在大部分领域模型中,有70%的聚合通常只有一个实体,即聚合根,该实体内部没有包含其他实体,只包含一些值对象;另外30%的聚合中,基本上也只包含两到三个实体。这意味着大部分的聚合都只是一个实体,该实体同时也是聚合根。
聚合设计的原则:
- 聚合是用来封装真正的不变性,而不是简单的将对象组合在一起;
- 聚合应尽量设计的小;
- 聚合之间的关联通过ID,而不是对象引用;
- 聚合内强一致性,聚合之间最终一致性;
如何识别聚合根?
如果一个聚合只有一个实体,那么这个实体就是聚合根;如果有多个实体,那么我们可以思考聚合内哪个对象有独立存在的意义并且可以和外部直接进行交互。
聚合根、实体、值对象对象之间如何建立关联?
聚合根到聚合根:通过ID关联;聚合根到其内部的实体,直接对象引用;聚合根到值对象,直接对象引用;
实体对其他对象的引用规则:1)能引用其所属聚合内的聚合根、实体、值对象;2)能引用外部聚合根,但推荐以ID的方式关联,另外也可以关联某个外部聚合内的实体,但必须是ID关联,否则就出现同一个实体的引用被两个聚合根持有,这是不允许的,一个实体的引用只能被其所属的聚合根持有;
值对象对其他对象的引用规则:只需确保值对象是只读的即可,推荐值对象的所有属性都尽量是值对象;
例子分析:帖子与回复的模型
不 变性分析:帖子和回复之间有不变性规则吗?似乎我们只知道一点是肯定的,那就是帖子和回复之间的关系,1:N的关系;除了这个之外,我们看不到任何其他的 不变性规则。那么这个1:N的对象关系是一种不变性规则吗?不是!首先,一个帖子可以没有任何回复,帖子也不对它的回复有任何规则约束,它甚至都不知道自 己有多少个回复;再次,发表了一个回复和帖子也没有任何关系;其次,发表回复对帖子没有任何改变;从业务场景的角度去分析,我们有发表帖子的场景,有发表 回复的场景。当在发表回复的时候,是以回复为主体的,帖子只是这个回复里所包含的必要信息,用于说明这个回复是对哪个帖子的回复。这些都说明帖子和回复之 间找不出任何不变性约束的规则;因为帖子和回复都有各自独立的业务场景的需要,所以可以很容易理解它们都是独立的聚合根;那也很容易知道该如何建立他们之 间的关联了,但是我们要尽量减少关联,所以只保留回复对帖子的关联即可;帖子没有任何必要去保存一个回复的ID的列表;那么你可能会说,当我删除一个帖子 后,回复应该是没有存在的意义的呀?不对,不是没有存在的意义,而是删除了帖子后导致了回复对帖子的关联信息的缺失,导致数据不一致。这是因为帖子和回复 之间有一种必然的联系(1:N),回复一定会有一个对应的帖子;但是回复有其自己的生命周期,不应该随着帖子的删除而级联删除。这种情况下,如果你删除了 帖子,就导致回复也成为了一条无效的数据;所以,我们绝对不允许删除任何聚合根,因为一旦你删除了聚合根,那就意味着与该聚合根相关的其他任何聚合根都会 有外键引用缺失的问题,会导致整个领域模型数据的不一致;所以,永远都不要删除聚合根;
领域服务:领域模型主张富领域模式,也就是说把领域逻辑尽量写在领域实体里面,也就是常说的“充血模式”,而对于业务逻辑,最好是以服务的形式提供。至于领域逻辑和业务逻辑的界定,这个要根据实际情况来定。如果通用语言里面出现了名词,那一般就是实体或值对象;如果里面出现了动词,那通常就意味着领域服务。例如:支付,这是一个比较明显的业务操作。另外,如果有什么操作会让实体变得臃肿,也可以使用领域服务来解决。但是不能把所有的东西都堆到领域服务里,过度使用领域服务会导致贫血对象的产生。良好的领域服务具有以下三个特征:
- 操作不是实体/值对象的一个自然的部分
- 接口根据领域模型的其它元素定义
- 操作无状态
还需要注意的是,不要把领域服务和应用服务混起来了。我们在领域服务里处理业务逻辑,而并不在应用服务里处理。应用服务是领域模型的直接客户,负责处理事务、安全等操作。
工厂:工厂是生命周期的开始阶段,它可以用来创建复杂的对象或是一整个聚合。复杂对象的创建是领域层的职责,但它并不属于被创建的对象自身的职责。实体和值对象的工厂不太一样,因为值对象是不可变的,所以需要工厂一次性创建一个完整的值对象出来。而实体工厂则可以选择创建之后再补充一些细节。工厂的作用是将创建对象的细节隐藏起来。客户传递给工厂一些简单的参数,然后工厂可以在内部创建出一个复杂的领域对象然后返回给客户。领域模型中其他元素都不适合做这个事情,所以需要引入这个新的模式,工厂。工厂在创建一个复杂的领域对象时,通常会知道该满足什么业务规则(它知道先怎样实例化一个对象,然后在对这个对象做哪些初始化操作,这些知识就是创建对象的细节),如果传递进来的参数符合创建对象的业务规则,则可以顺利创建相应的对象;但是如果由于参数无效等原因不能创建出期望的对象时,应该抛出一个异常,以确保不会创建出一个错误的对象。当然我们也并不总是需要通过工厂来创建对象,事实上大部分情况下领域对象的创建都不会太复杂,所以我们只需要简单的使用构造函数创建对象就可以了。隐藏创建对象的好处是显而易见的,这样可以不会让领域层的业务逻辑泄露到应用层,同时也减轻了应用层的负担,它只需要简单的调用领域工厂创建出期望的对象即可
资源库:资源库是生命周期的结束,它封装了基础设施以提供查询和持久化聚合的操作。这样能够让我们始终聚焦于模型,而把对象的存储和访问都委托给资源库来完成。以订单和订单明细的聚合为例,因为一定是通过订单这个聚合根来获取订单明细,所以可以有订单的资源库,但是不能有订单明细的资源库。也就是说,只有聚合才拥有资源库。需要注意的是,资源库并不是数据库的封装,而是领域层与基础设施之间的桥梁。DDD关心的是领域内的模型,而并非是数据库的操作。理想的资源库对客户(而非开发者)隐藏了内部的工作细节,委托基础设施层来干那些脏活,到关系型数据库、NOSQL、甚至内存里读取和存储数据。
领域驱动设计的经典分层架构:
用户界面/展现层:负责向用户展现信息以及解释用户命令。更细的方面来讲就是:
- 请求应用层以获取用户所需要展现的数据;
- 发送命令给应用层要求其执行某个用户命令;
应用层:很薄的一层,定义软件要完成的所有任务。对外为展现层提供各种应用功能(包括查询或命令),对内调用领域层(领域对象或领域服务)完成各种业务逻辑,应用层不包含业务逻辑。
领域层:负责表达业务概念,业务状态信息以及业务规则,领域模型处于这一层,是业务软件的核心
基础设施层:本层为其他层提供通用的技术能力;提供了层间的通信;为领域层实现持久化机制;总之,基础设施层可以通过架构和框架来支持其他层的技术需求;
3.设计DDD的一般步骤:
- 根据需求建立一个初步的领域模型,识别出一些明显的领域概念以及它们的关联,关联可以暂时没有方向但需要有(1:1,1:N,M:N)这些关系;可以用文字精确的没有歧义的描述出每个领域概念的涵义以及包含的主要信息;
- 分析主要的软件应用程序功能,识别出主要的应用层的类;这样有助于及早发现哪些是应用层的职责,哪些是领域层的职责;
- 进一步分析领域模型,识别出哪些是实体,哪些是值对象,哪些是领域服务;
- 分析关联,通过对业务的更深入分析以及各种软件设计原则及性能方面的权衡,明确关联的方向或者去掉一些不需要的关联;
- 找出聚合边界及聚合根,这是一件很有难度的事情;因为你在分析的过程中往往会碰到很多模棱两可的难以清晰判断的选择问题,所以,需要我们平时一些分析经验的积累才能找出正确的聚合根;
- 为聚合根配备仓储,一般情况下是为一个聚合分配一个仓储,此时只要设计好仓储的接口即可;
- 走查场景,确定我们设计的领域模型能够有效地解决业务需求;
- 考虑如何创建领域实体或值对象,是通过工厂还是直接通过构造函数;
- 停下来重构模型。寻找模型中觉得有些疑问或者是蹩脚的地方,比如思考一些对象应该通过关联导航得到还是应该从仓储获取?聚合设计的是否正确?考虑模型的性能怎样,等等;
4.DDD与传统的 Controller/Service/Dao三层结构模式比较
业务初期,我们的功能大都非常简单,普通的CRUD就能满足,此时系统是清晰的,使用三层结构开发方式,对象只是数据的载体,没有行为。以数据为中心,以数据库ER设计作驱动。三层架构在这种开发模式下,可以理解为是对数据移动、处理和实现的过程。
但在业务逻辑复杂了,业务逻辑、状态会散落到在大量方法中,原本的代码意图会渐渐不明确,而DDD将数据和行为封装在一起,并与现实世界中的业务对象相映射。各类具备明确的职责划分,将领域逻辑分散到领域对象中,解决了代码高耦合低聚合的问题
DDD试图解决的是软件的复杂性问题,如果软件比较复杂,或者是预期会很复杂,或者是你不知道,那么都可以开始考虑DDD。否则,由于维系领域模型需要实现大量的封装和隔离,DDD会带来较大的成本。但是,DDD并不是一个笨重的开发过程,它能够和敏捷开发很好地结合起来,另外,DDD也倾向于“测试先行,逐步改进”。
5.DDD与微服务
我们创建微服务时,需要创建一个高内聚、低耦合的微服务。而DDD中的限界上下文则完美匹配微服务要求,可以将该限界上下文理解为一个微服务进程。他们的具体关系如下图:

6.简单举例:
需求:举办一个比赛,有两个队参加,比赛在某个时间开始,只能开始一次,比赛结束后,统计积分
作为用户,希望看到:参加比赛的队伍名称,比赛开始时间,比赛结束时间,比赛结束后的分数。
传统方式从上面需求中,根据名词或动词法则,得到下面类:Match比赛,Team队伍,Score分数,MatchService,代码如下:


这是贫血失血模型,对象只有属性,没有自己的行为方法,有的只有setter/getter方法而已。
从需求中,我们会发现有一个聚合词语: Match(比赛)可以涵括需求的大部分。
那么“Match比赛”模型无疑是一个实体,是聚合根。它的重要特点是内部有状态,而且不能向外直接暴露这种状态;通过聚合根实体和外界进行交互,通过实体“Match比赛”模型,可以创建值对象:两个队伍的名称,对象Team值对象,值对象是不可变的,也可以根据一个比赛名称开始一个比赛。我们也可以结束一个比赛,这时有值对象分数Score,也具有不可变性。这样, Match比赛 聚合根实体的代码如下,相当于将原来MatchService的代码移到实体类的方法中,再也没有了服务

在Match类中,我们只有getter方法,只有把不可变的值对象提供外部访问getter的方法,如果也去除了getter方法如何?那么如何产生出给用户看的视图数据呢?
我们从读写两个方面去看待模型:
写模型: 统一语言,显式的事务边界,复杂的业务逻辑。
读模型:专门为读优化(缓存等),有不同的SQL如NoSQL分析,简单的类组成。
下一步,如何让数据满足这些模型,如果说我们已经撑起来骨架,那么数据是领域模型的血液,如何将血液输送到模型中呢? 数据一般会保存在数据库或各种NoSQL中。所以可以使用事件。那么我们在实体模型Match中的方法中增加事件代码如下:

对于聚合根中的字段,我们只需要那些能够改变业务方法行为的字段,其他数据都被归纳入事件对象中,在Match类中,是否结束这种状态对业务行为影响大,因此,代码改变最后如下:
PKD84JS}5.png")
本文只是粗浅介绍了下DDD,demo来源于http://www.jdon.com/44815
文章大部分摘自汤雪华的连载博客共23篇,涵盖了DDD的方方面面,如想深入研究,请参考:http://www.cnblogs.com/netfocus/category/361987.html
其余参考如下:https://tech.meituan.com/DDD%20in%20practice.html
https://www.jianshu.com/p/b6ec06d6b594
https://kb.cnblogs.com/page/576236/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号