行业基本面量化之商业银行
本文总结了商业银行的一些投资要点,对其商业模式的发展趋势进行思考,整理当前市场上的流行定价方法,构建因子体系并给出一个基础估值模型。
本文所指的商业银行,既包括多元银行、区域性银行,也包括“互助储蓄与抵押信贷金融服务”机构。
银行在多数主要金融市场均是重点板块,2020年初,银行股市值占A股比重14.5%,占港股比重17.5%,占纽交所和纳斯达克市场比重分别为9.2%和2.1%。上证50指数中含10支多元银行股,沪深300指数中含有13支多元银行股和11支区域银行股,中证500指数中含7支区域银行股。恒生指数包含7支多元银行股。美国S&P500指数中含有6支多元银行、11支区域性银行和1家互助储蓄机构。
1. 银行的商业模式
银行的商业模式用一句话描述即“吸收存款、发放贷款,提供信用中介服务”。
银行的客户对象包括了零售客户和企业,其业务中“吸收存款”的对象以零售客户为主,对于多元银行和区域性银行,“发放贷款”的对象以企业为主。我们提到了“互助储蓄与抵押信贷金融服务”机构,这类机构的资产端以房屋贷款为主,客户也都主要是零售客户。
几类银行之间的区别如下:
- 多元银行规模庞大,地理位置分布多元化,其业务类型以吸收零售客户存款并面向企业发放贷款为主,同时可经营各类业务。在容许混业经营的国家,多元银行可同时经营投资银行业务。
- 区域性银行如字面意义所示,倾向于在局部区域经营。区域性银行在规模效应、品牌优势等方面相比多元银行有劣势,但在经营区域内有信息优势,并可进行差异化定价。
- 互助储蓄与抵押信贷金融服务(Thrifts & Mortgage Finance)机构,或者可称为储蓄机构,是美国金融体系下的特殊产物。单词"thrift"的含义为“节俭”,因为美国储蓄机构的客户大多是小额资金客户,他们的资金大都是通过节俭攒出来的,所以以节俭命名既反映了这类机构特征,也迎合了小额个人储蓄者的口味。储蓄机构在定位方面即与银行不同。成立于1889年,并于2008年9月倒闭的华盛顿互惠银行(Washington Mutual)曾是美国最大的储蓄银行,在美国商业银行采取收费模式时,华盛顿互惠银行却坚持平民路线,很多服务如核查账目、使用取款机、信用卡交易都是免费的,因此客户喜爱在华盛顿互惠银行存款并乐于接受各种打包产品。华盛顿互惠银行倒闭则是因为其资产端中次级贷款占比过高,因此在2008年金融危机中被一波带走。
- 此外有一类银行在GICS中划归为“多元资本市场机构”,相比多元银行有更为丰富的业务类型,可以视作商业银行和投资银行的混合体。按照GICS的定义,多元资本市场机构的客户以大型机构为主。典型的多元资本市场机构包括德意志银行(现已申请破产)、瑞士信贷、UBS等。这类机构的业务高度交叉且信息不透明,难以充分研究。
资产负债结构
负债端,最大最重要的项目是“吸收存款”,其他几个相对主要的项目包括“向中央银行借款”、“同业和其他金融机构存放贷款”、“拆入资金”、“卖出回购金融资产款”以及“应付债券”,可见银行的主要资金来源是存款储蓄,此外会从央行或从同业机构借钱,或者从资金市场或债券市场融入部分资金。资产端,最重要的项目是“发放贷款及垫款”,其他几个相对重要的项目包括“现金及存放中央银行款项”、“存放同业和其他金融机构款项”、“拆出资金”以及“金融投资”,其中金融投资以固定收益投资为主。
表 代表性银行的资产负债表结构(单位:亿元)
| 招商银行 | 浦发银行 | |||
|---|---|---|---|---|
| 规模 | 占比(%) | 规模 | 占比(%) | |
| 资产: | ||||
| 发放贷款及垫款 | 37499 | 55.59% | 34555 | 51.23% |
| 现金及存放中央银行款项 | 4934 | 7.31% | 4437 | 6.58% |
| 存放同业和其他金融机构款项 | 1002 | 1.49% | 943 | 1.40% |
| 拆出资金 | 3134 | 4.65% | 1423 | 2.11% |
| 金融投资 | 16714 | 24.78% | 19228 | 28.50% |
| 其他资产 | 4174 | 6.19% | 2310 | 3.42% |
| 资产总计: | 67457 | 62896 | ||
| 负债: | ||||
| 吸收存款 | 44276 | 71.39% | 32533 | 52.45% |
| 向中央银行借款 | 4053 | 6.53% | 2210 | 3.56% |
| 同业和其他金融机构存放贷款 | 4708 | 7.59% | 10678 | 17.22% |
| 拆入资金 | 2040 | 3.29% | 1486 | 2.40% |
| 卖出回购金融资产款 | 1408 | 2.27% | 1196 | 1.93% |
| 应付债券 | 4249 | 6.85% | 8414 | 13.57% |
| 其他负债 | 1287 | 2.08% | 1595 | 2.57% |
| 负债总计: | 62021 | 58112 | ||
| 所有者权益: | 5436 | 4784 | ||
| 数据来源:2018年年报 |
在工商银行等银行的资产中,取代“金融投资”项目的是“以摊余成本计量的金融资产”或者“以公允价值且其变动计入其他综合收益的金融资产”,但总之这也属于金融资产投资的范畴。银行资产中的金融资产会在不同项目中来回腾挪。
或许是遵循GAAP会计准则的原因,美国的商业银行的资产负债仅根据资产或负债的形式或性质进行披露,如资产端披露的是“现金及现金等价物”、“抵押担保证券”、“交易性金融资产”等。
我们可以将资产归纳为“贷款投资资产”和“直接投资资产”,将负债归纳为“吸收存款”以及“直接融资负债”,那么银行之间资产负债结构的区别无非是间接和直接之间的比例差异。我国银行中,创新性较强的银行以及区域银行的直接投资资产比重会高一些,整体而言美国商业银行的直接投资资产和直接融资负债比重都比国内高。例如美国银行,其发放贷款占总资产的规模不足40%。或许随着直接投融资市场发展,我国商业银行也会朝着这个方向发生变化。但无论如何,对于商业银行,“吸收存款、发放贷款,提供信用中介服务”才是最核心的。
营业收支结构
营业收入包括“利息净收入”、“手续费及佣金净收入”和投资收益三个主要部分,对于中国银行,利息净收入约占比65%,手续费及佣金收入约占比25%。对于美国的银行,手续费及佣金净收入的占比会更高,甚至接近利息净收入。银行的业务又可以分为“资产业务”、“负债业务”和“中间业务或表外业务”,其中手续费及佣金收入就是中间业务产生的。
营业支出中最重要的分别是:(1)银行的经营管理费用;(2)提计的坏账准备或“信用减值损失”。
银行业的特征和竞争优势
银行业有四个主要特征:一、提供信用中介服务,发挥间接融资服务实体经济的作用;二、为经济系统输送血液,有特殊的经济地位;三、高杠杆、大规模、顺周期;四、利润前置而风险后置。
以上特征决定了银行业的竞争优势以及价值是由以下方面决定的:
(1)作为间接融资的中介,银行工作的核心作用是匹配,将储蓄者和消费者、融资企业撮合在一起,将相同风险水平的投资者和融资项目撮合在一起,将不同期限水平的资产组合在一起以匹配负债。为了令匹配工作更容易完成,银行需要有足够规模的客户以及项目,这样才能发挥规模效应,以及需要信息优势。
(2)银行的经济角色导致其在一定程度上是受到保护的。虽然银行也存在挤兑破产,但在一般风险情况下,可以借助央行、同业机构和金融市场的帮助渡过难关。
(3)利差、风险和政策决定银行可以使用多少杠杆,利差和杠杆决定银行的利息收入水平,杠杆和规模决定银行的手续费和佣金水平。
(4)与各行业紧密的联系、顺周期特性等都决定了银行价值受宏观因素和央行政策因素驱动。
(5)风险后置特性决定了银行资产质量(坏账率等)和风险应对能力(贷款损失准备充足率等)对价值的重要性。
2. 主流定价方法
最常被使用的银行估值指标是PB,而最常被讨论的估值指标是PE,围绕PB/PE指标还衍生出了PA、PB-ROE、PA-ROA等指标。业内普遍未使用绝对估值法,均是基于相对估值,考察净息差、不良贷款率等指标条件下合理的PB/PE水平,进而进行定价。
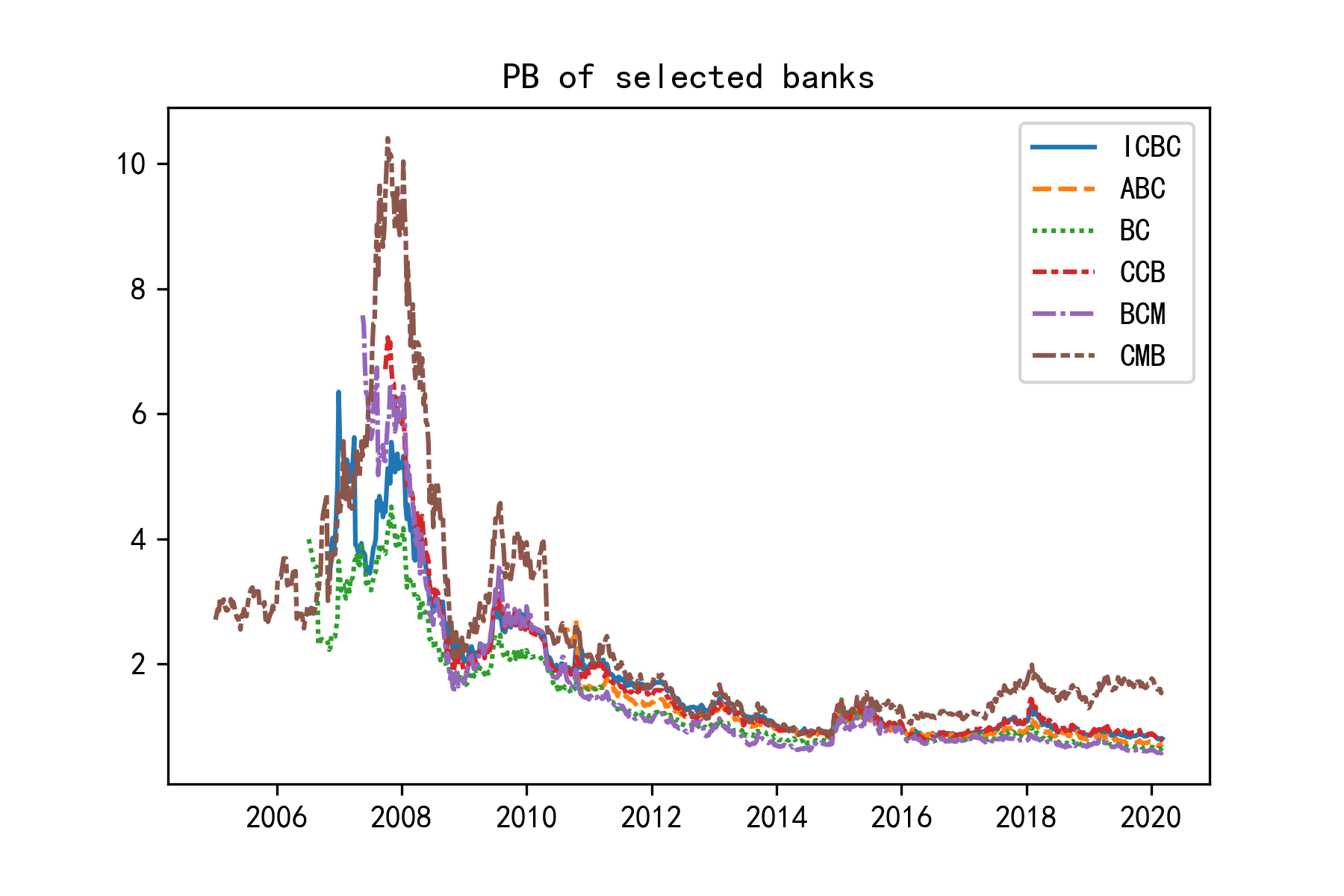
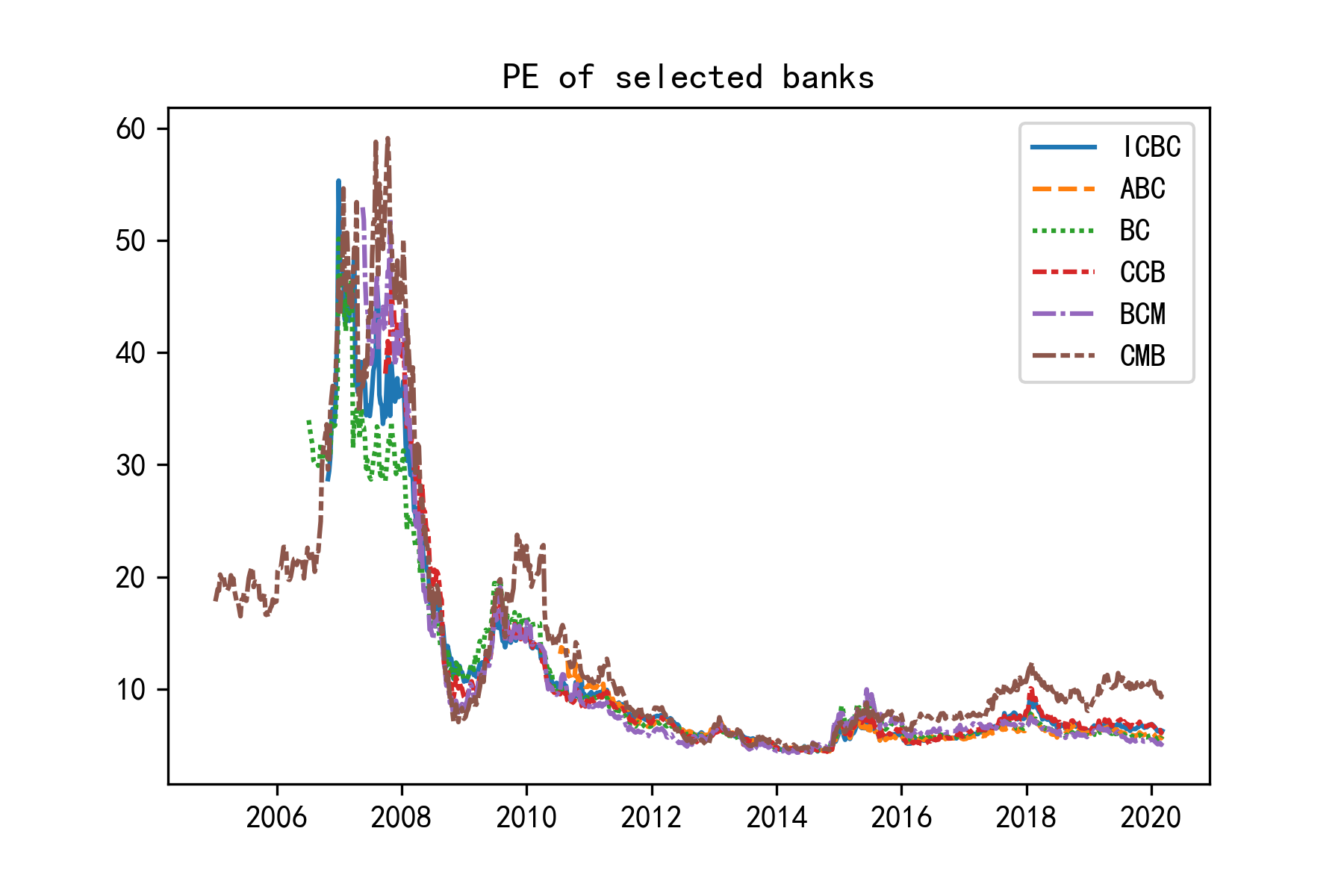
两种估值方法都显示出了行业内的高度一致性,将时序数据标准化后计算横截面标准差的均值,2010年7月到2020年3月得到的PB标准差均值为0.316,PE标准差均值为0.336,2015年1月到2020年3月得到的PB标准差均值为0.554,PE标准差均值为0.566。可见无论用PB估值还是PE估值,银行股的横截面差异都不大。
PB和ROE究竟是正相关还是负相关?
由于PE=PB×ROE,我们仅考察影响PB水平的因素。通过简单的回归模型可以知道,PB和ROE有很强的相关性。
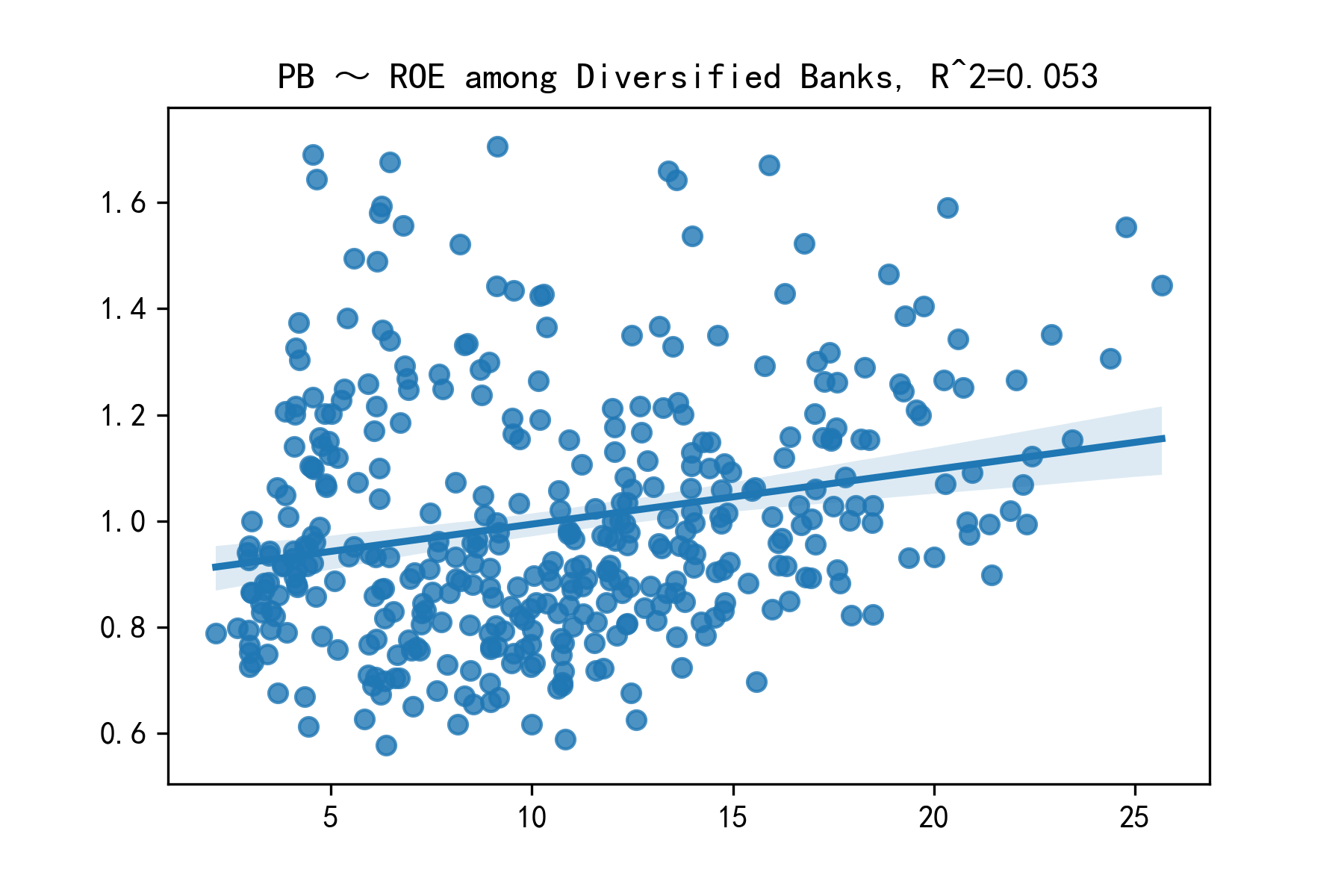
以上是2012年一季度至2019年三季度用多元银行的混合数据做得回归,回归系数0.0103,R方0.053。然而对于区域性银行,虽然F检验显著,解释能力也高,但ROE的系数显著为负。这种负相关可能的原因包括且不限于:样本差异过大导致混合数据有问题;优质区域性银行在样本期内被低估;ROE与风险不相匹配,高ROE的银行有更高水平的折现率。
调整拨备因素对ROE的影响
有人提出了“拨备正常化ROE”的概念,认为由于银行经常通过控制拨备金来调整其报表利润,因此应当反向计算排除这种调整带来的作用。具体计算方式如下:
(1)首先计算拨备正常化的净利润:
其中200%是用以起到对齐作用的一个标准拨备覆盖率,高于标准的银行就调回一些利润,低于标准则调出一些利润,25%是假设的所得税率。
(2)利用拨备正常化净利润可计算得出“拨备正常化ROE”:
实际检验看来,PB对拨备正常化ROE回归结果的解释能力的确有所提高,对于多元化银行,R方从0.81提升至0.125。以上公式可以作为参考,如果使用非线性模型进行估值的话,完全可以将ROE和拨备覆盖率作为不同因素输入。
ROE的杜邦分解
进一步来看银行ROE的决定因素。由于其商业模式的特殊性,ROE的杜邦分解也有所不同,可按照如下公式进行:
以上分解指标与银行资本充足率管理、行业息差水平、资产结构、中间业务发展、运营成本、资产质量等方面息息相关。
3. 商业银行因子体系
初步构建的银行因子体系结构如下:
企业肖像:
市场地位:Deposit/M2
银行类型:多元银行或区域性银行,以1或0标识
资产负债结构:Asset/BookValue, Deposit/BookValue, Deposit/Loan
营收结构:ROE, InterestsInc/Loan, FeeInc/BookValue, Cost/Income
存贷业务条件:NIM(Net Interest Margin), NPLratio
资产质量与风控管理:BadDebtProvCoverage
价格表现:
价格指标,由OHLC和交易额组成,用收盘价计算对数收益率作为解释因子和预测的主要目标。
估值指标:PE, PB
中国市场因素:
由沪深300指数的收盘价、成交额以及对数收益率组成
境外市场因素:
用SP500指数(SPX.GI)的收盘价及对数收益率组成,用以考察美国市场对我国的影响。
用VIX指数(VIX.GI)作为全球金融市场情绪的代理变量。
用恒生金融指数(HSFSI.HI)的收盘价以及对数收益率组成,考察香港市场与我国市场之间的紧密关系。
中国宏观因子:
参考在《机器学习与宏观基本面方法在债券定价中的应用》中构建的宏观因子体系。
美国宏观因子:
由于境外宏观因素对我国银行业的影响是相对较弱且间接的,我们只采用联邦政策利率(DFF)和十年期美国国债收益率(DGS10)两个高频变量。黄金、原油等商品因素纳入了中国宏观因子范围。美国非农就业、CPI、社会零售增长等因素则已经通过黄金、利率和股票市场等体现在因子体系之中了。
以上因子体系中,“企业肖像”是一组通过企业季报信息生成的结构性指标,用以描绘企业的特征。宏观数据以月度和日度数据为主,商品价格、市场价格等信息均为日度数据。
4. 商业银行估值模型
通过以上因子体系构造的实际上是一个面板数据集,许多时间上同时存在着多家银行的数据。因此虽然我们构建的数据集的样本时间是2010年8月到2020年2月,总计不到3500个时间点,但数据集的条数是47000多个。对于股票数据集很麻烦一点的是,由于公司陆续上市,面板数据均是非均衡的。
进行模型训练时,均采用到2018年12月的数据为训练集,之后的数据为测试集。
我们以1-5天、22天、65天为预测窗口,分别使用随机森林、LightGBM和神经网络进行了训练和预测。经过模型计算和对比,主要发现如下:
(1)还记得在进行债券预测时,随机森林在各个预测窗口上均取得了最佳成绩,而这对于我们的银行股数据集则有所不同。LightGBM是整体表现最优的模型,不仅预测结果的RMSE最小,且R2是最高的,大约有3.5%。随机森林的RMSE尚可,但R2均为负数。神经网络在短时间上的表现效果最差,但在65天窗口的预测却是表现最好的。笔者思考(胡乱猜测)背后的原因,认为股票的走势具有一定的“补偿”性质,一段时间内如果某种外生冲击未反映在价格走势中,则股价更有可能做出反应,因此boosting模型比bagging更能够捕捉这种机制。
(2)我们用股价对数收益率的标准差作为baseline,预测模型虽然具有一定预测提升效果,即预测方差有所降低,但这种效果提升作用并不强。以3日预测为例,测试数据集中股价对数收益率的标准差是0.0328247,LightGBM预测的RMSE是0.0320718。如果将预测目的转化为预测涨跌的话,预测数据集样本条数9387,其中上涨概率48.95%,下跌概率51%,预测正确即预测方向与实际数据方向一致的概率是55.875%,比瞎猜的成功率要高一些,不过也不算很好。
(3)通过LightGBM中的feature_importance属性来看哪些因子是对模型比较重要的。首先模型完全未使用关于银行类型的标签,或许表明多元银行和区域银行适用同样的模型。几大模块中比较重要的因素包括:市场指数走势、市场的交易量,境外市场的交易量、VIX指数、恒生指数等,国债、城投债、Shibor1W等固收市场和资金市场的价格,原油和黄金价格,宏观指标有作用但不明显,仅M2比较突出,出乎意料的是美国十年期国债利率还蛮重要的。
对于目前所尝试的因子体系以及模型,笔者进行了一些反思:
(1)关于因子体系。目前使用的因子是基于“一手”数据的,比方说考察M2的影响,就将M2的规模或增长率直接作为模型输入。这种做法有个严重的劣势,就是不可避免地使用低频数据和混频数据。低频数据本身的信息量问题且不说,笔者一直在考虑使用LSTM等时序模型,但低频数据作为输入就没有了意义——比方说将一个月的时间窗口作为时序模型的输入时序长度,但能捕捉到什么新的信息呢?实际应用中低频数据还导致了模型使用过程一致性的问题,比如现在已经是2020年3月了,但模型中多数“企业肖像”的因子数据还停留在2019年三季度。笔者一直考虑向传统计量技巧靠拢,将“因子暴露”作为因子使用。使用因子暴露的好处,一是本身信息含量高,二是因子暴露与价格之间的联系更为直接,三是“因子暴露因子”本身即具有时序信息,或许可免去建立时序模型的麻烦?
(2)关于模型。笔者想多使用一些时序的模型,但是对于非均衡面板数据一时想不好如何处理。不论是计算因子暴露还是构造动量因子,时间窗口的选择以及具体指标计算方法总有些说不上来道理。同时一股脑将时序数据作为输入也没有道理,还大大加重了特征灾难问题。对于神经网络模型,一方面目前没看到相对树模型有明显的优势,另一方面模型结构和超参究竟如何设计总是没有道理,在进一步使用LSTM、Attention等网络之前,或许应该先想想神经网络的可解释性问题。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号