kafka之二:手把手教你安装kafka2.8.0(绝对实用)
前面分享了kafka的基本知识,下面就要对kafka进行实操,先看如何安装。
kafka需要zookepper的支持,所以要安装kafka需要有zookeeper的环境,zookeeper安装请参见《zookeeper之二:手把手教你安装zookeeper3.7.0(绝对实用)》。这里可以是一个单独的zookepper的环境也可以使用kafka集成的zookeeper环境,建议使用单独的zookeeper环境。本文以单独环境为例,集成环境请留言。
1、下载
kafka的官网地址是:http://kafka.apache.org/
从官网下载最新的kafka的安装包,如下图

这里选择二进制包进行安装,

我这里已经下载好Scala2.12版本的kafka安装包,

2、安装
2.1、单机版
2.1.1、环境
os:在虚拟机环境中的centos7-64进行安装。
zookeeper:zookeeper已经安装好,是3.7的版本。环境在本机:127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184
JDK:JDK环境已安装,是1.8的版本
2.1.2、修改配置文件
kafka的安装包解压后的目录结构如下,

bin目录下存放的是kafka的脚本文件,包括启动、停止、客户端、消费端等;
config目录下存放的是和配置相关的文件,包括客户端、消费端、服务器、zookeeper的配置等;
libs目录存放的是kafka启动用到的文件及依赖;
logs目录存放的是kafka的运行时日志文件;
了解完了kafka的文件目录,下面进行单机版kafka配置文件的修改。要修改的文件是config/server.properties文件,该文件比较长,这里就不贴了,看下几个必要的配置。这里有必要提下kafka的配置文件做的很好,有详细的解释还有例子。
broker.id broker的id或者编号,在集群中该编号必须唯一
# The id of the broker. This must be set to a unique integer for each broker. broker.id=0
listeners kafka服务器监听的端口,该端口也是对外提供服务的端口
# The address the socket server listens on. It will get the value returned from # java.net.InetAddress.getCanonicalHostName() if not configured. # FORMAT: # listeners = listener_name://host_name:port # EXAMPLE: # listeners = PLAINTEXT://your.host.name:9092 listeners=PLAINTEXT://192.168.117.128:9092
num.partitions topic下分区的数量
# The default number of log partitions per topic. More partitions allow greater # parallelism for consumption, but this will also result in more files across # the brokers. num.partitions=1
log.dirs 消息的存放目录,这里看配置是日志的意思,因为kafka把消息使用日志的形式存储,所以这里不要和kafka的运行日志相混淆。
# A comma separated list of directories under which to store log files log.dirs=/home/dev/datas/kafka_2.12-2.8.0/single
log.retentio.hours 消息保存的小时数
# The minimum age of a log file to be eligible for deletion due to age log.retention.hours=168
default.replication.factor 消息的副本数量,这是kafka高可用、数据不丢失的关键
default.replication.factor=3
zookeeper.connect zookeeper的地址
# Zookeeper connection string (see zookeeper docs for details). # This is a comma separated host:port pairs, each corresponding to a zk # server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002". # You can also append an optional chroot string to the urls to specify the # root directory for all kafka znodes. zookeeper.connect=localhost:2182/kafka,localhost:2183/kafka,localhost:2184/kafka
配置完上面的配置项后就可以启动单机版的kafka了
2.1.3、启动
有了上面的配置,现在启动kafka,在kafka的解压目录下执行,
bin/kafka-server-start.sh config/server.properties
执行后看到下面的日志打印,

看到是在前台启动的,有没有办法后台启动那,先停掉kafka,加上-daemon则使用守护线程在后台启动。
bin/kafka-server-start.sh -daemon config/server.properties

2.2、集群版
2.2.1、环境
集群版的环境和单机版的环境是一样的,需要zookeeper和JDK。由于集群版要求必须是2N+1台机器,我部署最少节点的集群,在虚拟机上起3个进程代表3台机器。
| IP | id | 端口 | 日志路径 |
| 本机 | 1 | 9093 |
/home/dev/datas/kafka_2.12-2.8.0/cluster/node1 |
| 本机 | 2 | 9094 |
/home/dev/datas/kafka_2.12-2.8.0/cluster/node2 |
| 本机 | 3 | 9095 |
/home/dev/datas/kafka_2.12-2.8.0/cluster/node3 |
2.2.2、修改配置文件
配置项和单机版的基本相同,选择在config下cluster文件夹,其下放置3个配置文件,

每个文件的内容可参考单机的,这里不再贴出。
关于日志路径也是要事先建好相应的目录。
2.2.3、启动
启动命令和单机的也是相同的,选择在后台启动,每次启动指定不同的配置文件,
[dev@localhost kafka_2.12-2.8.0]$ bin/kafka-server-start.sh -daemon config/cluster/server_node3.properties
3、测试
3.1、单机版测试
参见3.2集群版测试方法
3.2、集群版测试
3.2.1、通过查看进程的方式
使用jps命令查看进程
[dev@localhost kafka_2.12-2.8.0]$ jps
可以看到下面的打印
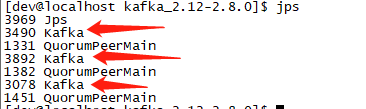
说明启动了三个kafka进程
3.2.2、使用客户端方式
使用kafka自带的客户端来创建一个topic
[dev@localhost kafka_2.12-2.8.0]$ bin/kafka-topics.sh --bootstrap-server 192.168.117.128:9093 --create --topic testKafka
看下图

说明创建成功,现在在另外一个节点上查看
[dev@localhost kafka_2.12-2.8.0]$ bin/kafka-topics.sh --bootstrap-server 192.168.117.128:9095 --list
看下图
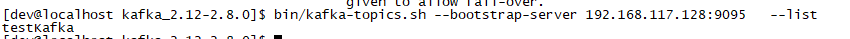
可以看到刚才创建的testKafka这个topic。
有不正之处,欢迎指正。参考:
https://www.cnblogs.com/zhaoshizi/p/12154518.html
https://www.cnblogs.com/sandea/p/12078442.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号