java面试一日一题:rabbitMQ如何保证消息不丢失
问题:请讲下rabbitMQ如何保证消息不丢失
分析:该问题属于概念题,同时也是一个设计方面的题,牵扯到部分设计层面的东西;
回答要点:
主要从以下几点去考虑,
1、rabbitMQ在保证消息不丢失方面是怎么做的?
2、在硬盘坏掉的情况下如何保证消息不丢失?

如上图,在使用中大体都是这样的形式,要保证消息的不丢失,需要从上图中三个方面去考虑
生成者
保证生成者发送的消息成功到达rabbitMQ,在这里可以使用rabbitMQ的API中提供的cofirm/callback和confirm/rollback机制,即在rabbitMQ成功接收到消息后回回调该方法,只要成功了那么生成方就可以认为消息发送成功;
rabbitMQ
要保证rabbitMQ不丢失消息,那么就需要开启rabbitMQ的持久化机制,即把消息持久化到硬盘上,这样即使rabbitMQ挂掉在重启后仍然可以从硬盘读取消息;第二点,延申下如果rabbitMQ单点故障怎么办,这种情况倒不会造成消息丢失,这里就要提到rabbitMQ的3种安装模式,单机模式、普通集群模式、镜像集群模式,这里要保证rabbitMQ的高可用就要配合HAPROXY做镜像集群模式;第三点如果硬盘坏掉怎么保证消息不丢失,这个放到下面讲;
消费者
消费者要保证消息不丢失,就是rabbitMQ要知道消费者是否成功消费消息了,只有在成功消费后rabbitMQ才会删除该消息,这里要开启rabbit的手动确认机制,即只有在消费者消费完成后给rabbitMQ一个确认,这样才证明该消息是成功消费的;
在系统中引入了rabbitMQ的目的是为了异步、削峰、解耦,但从上面可以看到引入rabbitMQ后系统复杂度反而升高了。
下面说如果rabbitMQ所在的硬盘坏了怎么保证消息不丢失
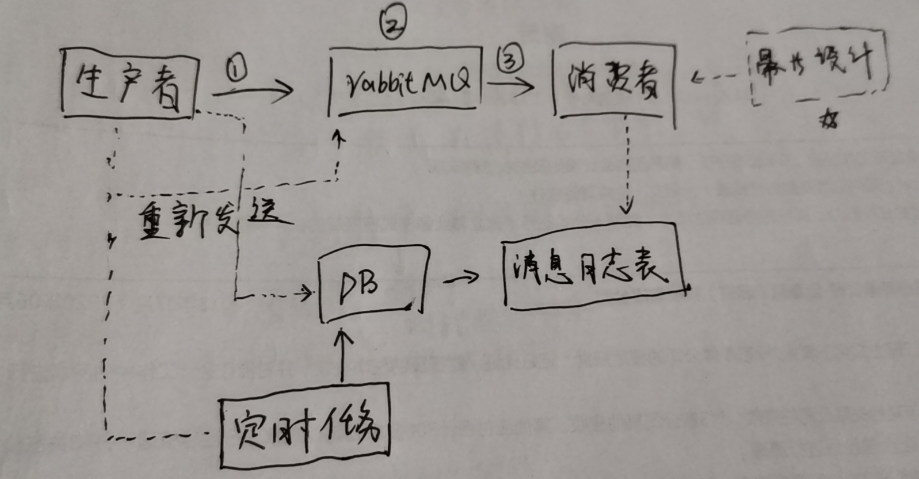
如上图,
1、生产者向mq发送消息的同时,再异步的把消息写入本地的数据库中,在数据库中记录每条消息的消息及状态;
2、消费者成功消费后更新“消息日志表”中相应消息的状态;
3、另起一个定时任务去扫描“日志消息表”,把那些未成功消费的消息,再向rabbitMQ重发;
4、由于做了重发操作,所以要做好消费者接口的幂等设计;
不过这会带来另外的问题,在生产者大量产生消息的时刻,写DB会是一个瓶颈,同时怎么保证写入db的消息和发送给MQ的消息是一致的。欢迎大家踊跃留言,感谢


 浙公网安备 33010602011771号
浙公网安备 33010602011771号