mybatis源码配置文件解析之五:解析mappers标签(解析resource和url属性)
在上篇文章中分析了mybatis解析<mappers>标签,《mybatis源码配置文件解析之五:解析mappers标签 》重点分析了如何解析<mappers>标签中的<package>子标签的过程。mybatis解析<mappers>标签主要完成了两个操作,第一个是把对应的接口类,封装成MapperProxyFactory放入kownMappers中;另一个是把要执行的方法封装成MapperStatement。
一、概述
在上篇文章中分析了<mappers>标签,重点分析了<package>子标签,除了可以配置<package>子标签外,在<mappers>标签中还可以配置<mapper>子标签,该子标签可以配置的熟悉有resource、url、class三个属性,解析resource和url的过程大致相同,看解析resource属性的过程。
下面看部分代码,
if (resource != null && url == null && mapperClass == null) { ErrorContext.instance().resource(resource); InputStream inputStream = Resources.getResourceAsStream(resource); XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments()); /** * 处理mapper文件和对应的接口 */ mapperParser.parse(); }
可以看到调用了XMLMapperBuilder的parse方法,
public void parse() { if (!configuration.isResourceLoaded(resource)) { //1、解析mapper文件中的<mapper>标签及其子标签,并设置CurrentNamespace的值,供下面第2步使用 configurationElement(parser.evalNode("/mapper"));
//这里想loadResoures中设置的是XML映射文件的路径 configuration.addLoadedResource(resource); //2、绑定Mapper接口,并解析对应的XML映射文件 bindMapperForNamespace(); } parsePendingResultMaps(); parsePendingCacheRefs(); parsePendingStatements(); }
从上面的代码中可以看出首先解析resource资源说代表的XML映射文件,然后解析XML;映射文件中的namespace配置的接口。
二、详述
通过上面的分析知道,解析resource配置的XML映射文件,分为两步,第一步就是解析XML映射文件的内容;第二步是解析XML映射文件中配置的namespace属性,也就是对于的Mapper接口。
1、解析XML映射文件
看如何解析XML映射文件内容,也就是下面的这行代码,
configurationElement(parser.evalNode("/mapper"));
看具体的实现,
/** * 解析XML映射文件的内容 * @param context */ private void configurationElement(XNode context) { try { //获得namespace属性 String namespace = context.getStringAttribute("namespace"); if (namespace == null || namespace.equals("")) { throw new BuilderException("Mapper's namespace cannot be empty"); } //设置到currentNamespace中 builderAssistant.setCurrentNamespace(namespace); //解析<cache-ref>标签 cacheRefElement(context.evalNode("cache-ref"));
//二级缓存标签 cacheElement(context.evalNode("cache")); parameterMapElement(context.evalNodes("/mapper/parameterMap")); resultMapElements(context.evalNodes("/mapper/resultMap")); sqlElement(context.evalNodes("/mapper/sql")); //解析select、insert、update、delete子标签 buildStatementFromContext(context.evalNodes("select|insert|update|delete")); } catch (Exception e) { throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e); } }
上面方法解析XML映射文件的内容,其中有个和二级缓存相关的配置,即<cache>标签。那么xml映射文件可以配置哪些标签那,看下面,

在XML映射文件中可以配置上面的这些标签,也就是上面方法中解析的内容。重点看解析select、update、delete、select。也就是下面这行代码
//解析select、insert、update、delete子标签 buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
其方法定义如下,
private void buildStatementFromContext(List<XNode> list) { if (configuration.getDatabaseId() != null) { buildStatementFromContext(list, configuration.getDatabaseId()); } buildStatementFromContext(list, null); }
这里会校验databaseId,如果自定义配置了,则使用自定义的,否则使用默认的,看方法buildStatementFromContext方法
private void buildStatementFromContext(List<XNode> list, String requiredDatabaseId) { for (XNode context : list) { final XMLStatementBuilder statementParser = new XMLStatementBuilder(configuration, builderAssistant, context, requiredDatabaseId); try { statementParser.parseStatementNode(); } catch (IncompleteElementException e) { configuration.addIncompleteStatement(statementParser); } } }
调用XMLStatementBuilder的parseStatementNode方法
/** * 解析select、update、delete、insert标签 */ public void parseStatementNode() { String id = context.getStringAttribute("id"); String databaseId = context.getStringAttribute("databaseId"); if (!databaseIdMatchesCurrent(id, databaseId, this.requiredDatabaseId)) { return; } Integer fetchSize = context.getIntAttribute("fetchSize"); Integer timeout = context.getIntAttribute("timeout"); String parameterMap = context.getStringAttribute("parameterMap"); String parameterType = context.getStringAttribute("parameterType"); Class<?> parameterTypeClass = resolveClass(parameterType); String resultMap = context.getStringAttribute("resultMap"); String resultType = context.getStringAttribute("resultType"); String lang = context.getStringAttribute("lang"); LanguageDriver langDriver = getLanguageDriver(lang); Class<?> resultTypeClass = resolveClass(resultType); String resultSetType = context.getStringAttribute("resultSetType"); StatementType statementType = StatementType.valueOf(context.getStringAttribute("statementType", StatementType.PREPARED.toString())); ResultSetType resultSetTypeEnum = resolveResultSetType(resultSetType); String nodeName = context.getNode().getNodeName(); SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH)); boolean isSelect = sqlCommandType == SqlCommandType.SELECT; boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect); //查询语句默认开启一级缓存,这里默认是true boolean useCache = context.getBooleanAttribute("useCache", isSelect); boolean resultOrdered = context.getBooleanAttribute("resultOrdered", false); // Include Fragments before parsing XMLIncludeTransformer includeParser = new XMLIncludeTransformer(configuration, builderAssistant); includeParser.applyIncludes(context.getNode()); // Parse selectKey after includes and remove them. processSelectKeyNodes(id, parameterTypeClass, langDriver); // Parse the SQL (pre: <selectKey> and <include> were parsed and removed) //生成SqlSource,这里分两种,DynamicSqlSource和RawSqlSource SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass); String resultSets = context.getStringAttribute("resultSets"); String keyProperty = context.getStringAttribute("keyProperty"); String keyColumn = context.getStringAttribute("keyColumn"); KeyGenerator keyGenerator; //例,id="selectUser" //这里的keyStatementId=selectUser!selectKey String keyStatementId = id + SelectKeyGenerator.SELECT_KEY_SUFFIX; //keyStatementId=cn.com.dao.userMapper.selectUser!selectKey keyStatementId = builderAssistant.applyCurrentNamespace(keyStatementId, true); if (configuration.hasKeyGenerator(keyStatementId)) { keyGenerator = configuration.getKeyGenerator(keyStatementId); } else { keyGenerator = context.getBooleanAttribute("useGeneratedKeys", configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType)) ? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE; } builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType, fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass, resultSetTypeEnum, flushCache, useCache, resultOrdered, keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets); }
上面的代码主要是解析标签中的各种属性,那么标签中可以配置哪些属性那,下面看select标签的属性,详情可参见https://www.w3cschool.cn/mybatis/f4uw1ilx.html
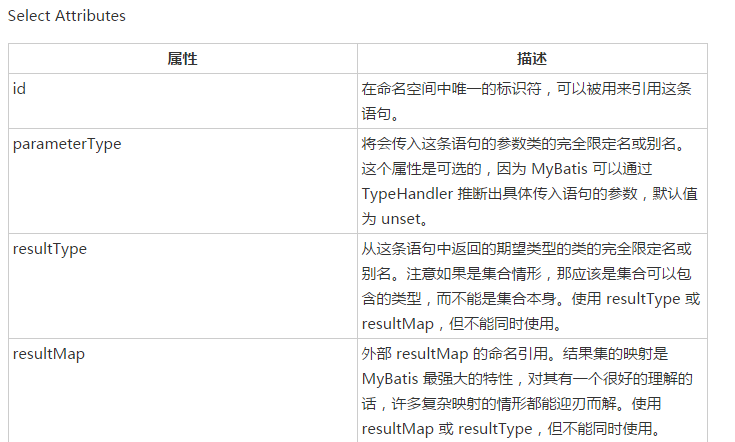
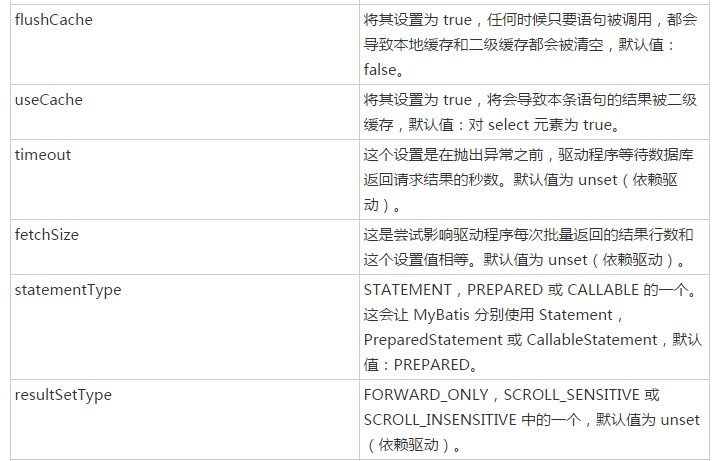
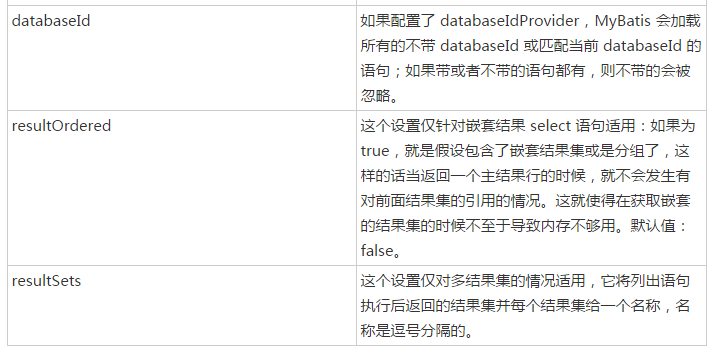
上面是select标签中可以配置的属性列表。
上面的代码重点看以下重点
二级缓存
下面看和缓存相关的
boolean isSelect = sqlCommandType == SqlCommandType.SELECT; boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect); //查询语句默认开启一级缓存,这里默认是true boolean useCache = context.getBooleanAttribute("useCache", isSelect);
这里仅针对select查询语句使用缓存,这里的默认不会刷新缓存flushCache为false,默认开启缓存useCache为ture,这里的缓存指的是一级缓存,经常说的mybatis一级缓存,一级缓存是sqlSession级别的。
看完了一级缓存,下面看SqlSource的内容
SqlSource
下面是SqlSource相关的,
//生成SqlSource,这里分两种,DynamicSqlSource和RawSqlSource SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
上面是生成SqlSource的过程,
@Override public SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType) { XMLScriptBuilder builder = new XMLScriptBuilder(configuration, script, parameterType); return builder.parseScriptNode(); }
看parseScriptNode方法
public SqlSource parseScriptNode() { MixedSqlNode rootSqlNode = parseDynamicTags(context); SqlSource sqlSource = null; if (isDynamic) { //含义${}符合的为DynamicSqlSource sqlSource = new DynamicSqlSource(configuration, rootSqlNode); } else { //不含有${}的为rawSqlSource sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType); } return sqlSource; }
从上面的代码可以看到在映射文件中根据参数占位符的标识符(${}、#{})分为DynamicSqlSource和RawSqlSource。具体如何判断,后面详细分析。
addMappedStatement
最后看builderAssistant.addMappedStatement方法,
public MappedStatement addMappedStatement( String id, SqlSource sqlSource, StatementType statementType, SqlCommandType sqlCommandType, Integer fetchSize, Integer timeout, String parameterMap, Class<?> parameterType, String resultMap, Class<?> resultType, ResultSetType resultSetType, boolean flushCache, boolean useCache, boolean resultOrdered, KeyGenerator keyGenerator, String keyProperty, String keyColumn, String databaseId, LanguageDriver lang, String resultSets) { if (unresolvedCacheRef) { throw new IncompleteElementException("Cache-ref not yet resolved"); } //cn.com.dao.UserMapper.selectUser id = applyCurrentNamespace(id, false); boolean isSelect = sqlCommandType == SqlCommandType.SELECT; MappedStatement.Builder statementBuilder = new MappedStatement.Builder(configuration, id, sqlSource, sqlCommandType) .resource(resource) .fetchSize(fetchSize) .timeout(timeout) .statementType(statementType) .keyGenerator(keyGenerator) .keyProperty(keyProperty) .keyColumn(keyColumn) .databaseId(databaseId) .lang(lang) .resultOrdered(resultOrdered) .resultSets(resultSets) .resultMaps(getStatementResultMaps(resultMap, resultType, id)) .resultSetType(resultSetType) .flushCacheRequired(valueOrDefault(flushCache, !isSelect)) .useCache(valueOrDefault(useCache, isSelect)) .cache(currentCache); ParameterMap statementParameterMap = getStatementParameterMap(parameterMap, parameterType, id); if (statementParameterMap != null) { statementBuilder.parameterMap(statementParameterMap); } MappedStatement statement = statementBuilder.build(); /*向mappedStatements字段中加入MappedStatement,这里会加入两个key * cn.com.dao.UserMapper.selectUser statement * selectUser statement * 每次都会插入上面的两种key,两种key对应的value都是同一个statement * */ configuration.addMappedStatement(statement); return statement; }
该方法主要完成的功能是生成MappedStatement,且放入configuration中。
2、解析namespace属性
上面分析了解析XML映射文件的内容的过程,最后的结果是把XML映射文件中的select、update、insert、delete标签的内容解析为MappedStatement。下面看解析XML映射文件中的namespace属性,
//2、绑定Mapper接口,并解析对应的XML映射文件 bindMapperForNamespace();
上面我给的注释是绑定接口并解析对应的XML映射文件,这个方法没有参数,怎么绑定具体的接口并解析对应的映射文件那,
private void bindMapperForNamespace() { String namespace = builderAssistant.getCurrentNamespace(); if (namespace != null) { Class<?> boundType = null; try { //加载类,这里加载的是mapper文件中配置的namespace配置的接口 boundType = Resources.classForName(namespace); } catch (ClassNotFoundException e) { //ignore, bound type is not required } if (boundType != null) { if (!configuration.hasMapper(boundType)) {//判断该接口是否被加载过,在mapperRegistry中的knowsMapper中判断 // Spring may not know the real resource name so we set a flag // to prevent loading again this resource from the mapper interface // look at MapperAnnotationBuilder#loadXmlResource //把该Mapper接口作为已加载的资源存放到loadedResources中,loadedResources存放的是已加载的mapper接口的路径,和第一步设置的XML映射文件路径不是同一个值。 configuration.addLoadedResource("namespace:" + namespace); //把该接口放到mapperRegistry中的knowsMapper中,并解析该接口,根据loadedResources判定是否需要解析该Mapper接口 configuration.addMapper(boundType); } } } }
获得builderAssistant.getCurrentNamespace(),在解析XML映射文件时,第一步便是设置该属性,这里用到的便是上一步中设置的那个XML映射文件中的namespace属性值。获得该接口的名称,判断是否生成过MapperProxyFactory,即放入过knownMappers中,看configuration.hasMapper方法,
public boolean hasMapper(Class<?> type) { return mapperRegistry.hasMapper(type); }
public <T> boolean hasMapper(Class<T> type) { return knownMappers.containsKey(type); }
如果在knownMappers中,则不进行解析,如果不在才进行下面的逻辑处理,调用configuration.addLoadedResource方法,放入loadedResources中,标识在第一步已经解析过对应的XML映射文件;调用configuration.addMapper方法,解析该接口,这个过程和在<mapper>标签中配置class属性的过程是一样的,后面详细分析。
三、总结
本文分析了mappers标签中mapper子标签中resource和url属性的解析过程,首先解析对应的XML映射文件,解析的结果为MappedStatement对象,然后解析其namespace对应的接口,解析的结果为MapperProxyFactory对象。

有不当之处,欢迎指正,感谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号