实战记录:爬大众点评评论区
实战记录:爬大众点评评论区
近日,小伙伴的女票要写论文,需要点数据。
借此机会,我也实战了一把。着实有趣。
迭代日志:
2021-01-09:
- 抓取完一个页面停止 3 秒钟
- 添加自动切换解密方式
- 修正方式 a 解密失败问题
需求:

技术选型
本身我自己是搞 java 的。刚开始想用 java 来搞,后来想想,有此机会,正好看看py功底如何。所以最终选择了 Python
分析:
先打开其中一个地址看看都啥东西
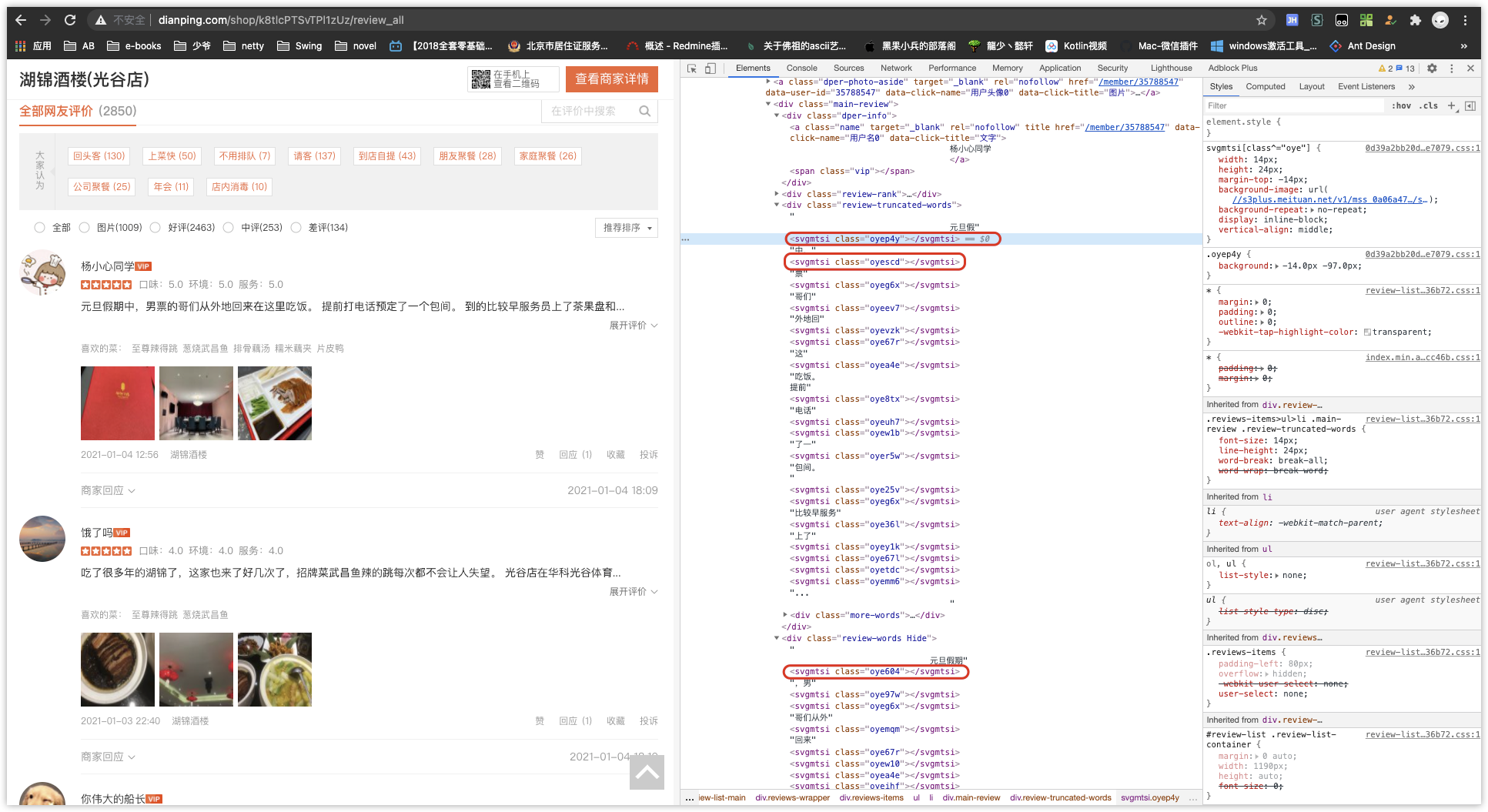
哎我去,这是什么玩意?
遇到事情不要慌,先拿出手机发个朋友圈。。
不是,仔细看看。
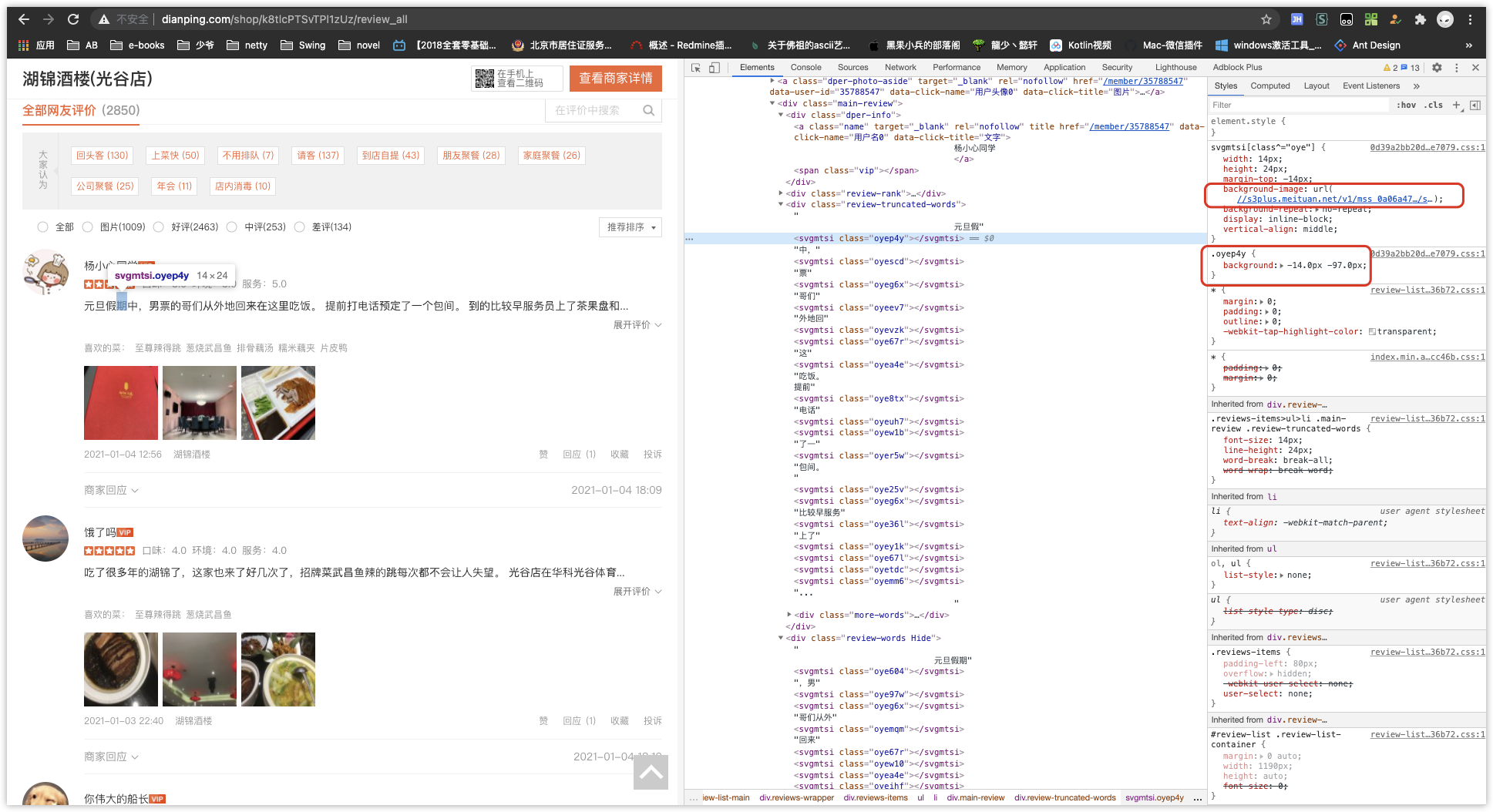
右边藏了个
background-image: url(//s3plus.meituan.net/v1/mss_0a06a47…/svgtextcss/32203aa….svg);
还有个
.oyep4y {
background: -14.0px -97.0px;
}
得,拼成完整 URL 打开看看啥东西吧。
这就有点意思了。
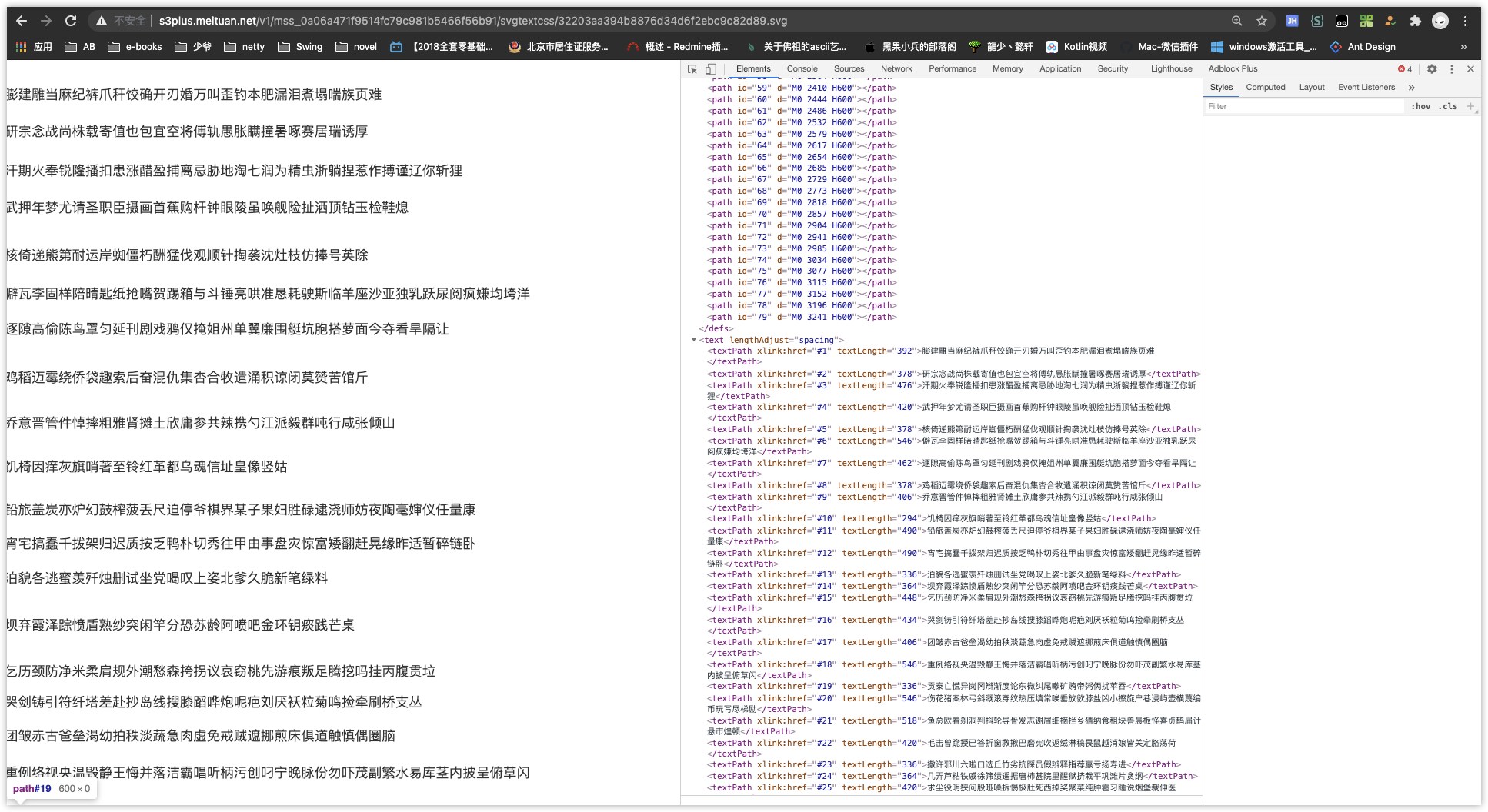
经过我两个夜晚的熬战,啧啧。终于通晓了其中奥秘。
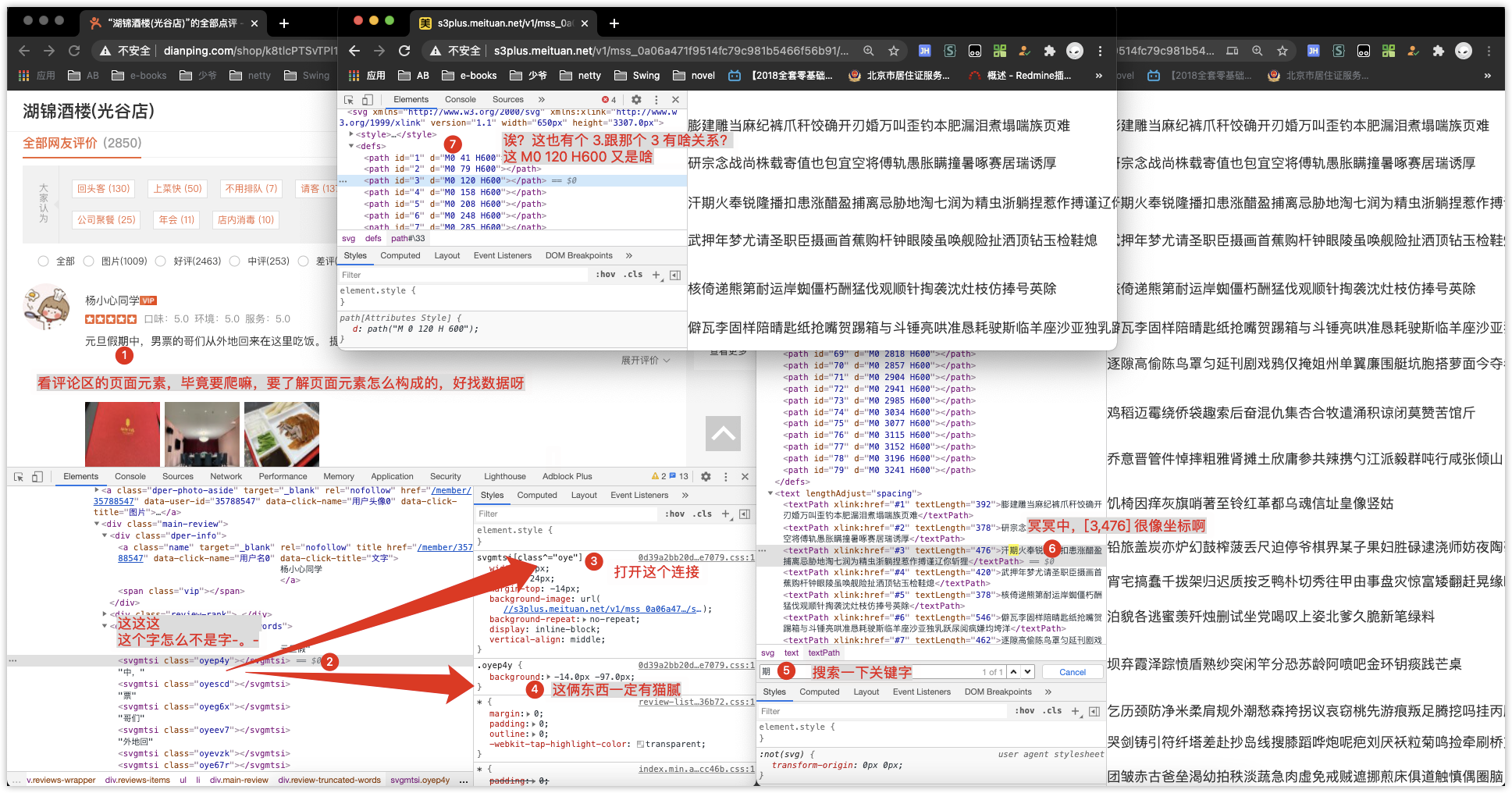
分析其中关系
经过几轮数据测试。最终发现,少了一个元素,文治就是隐藏在 style 里的font-size。
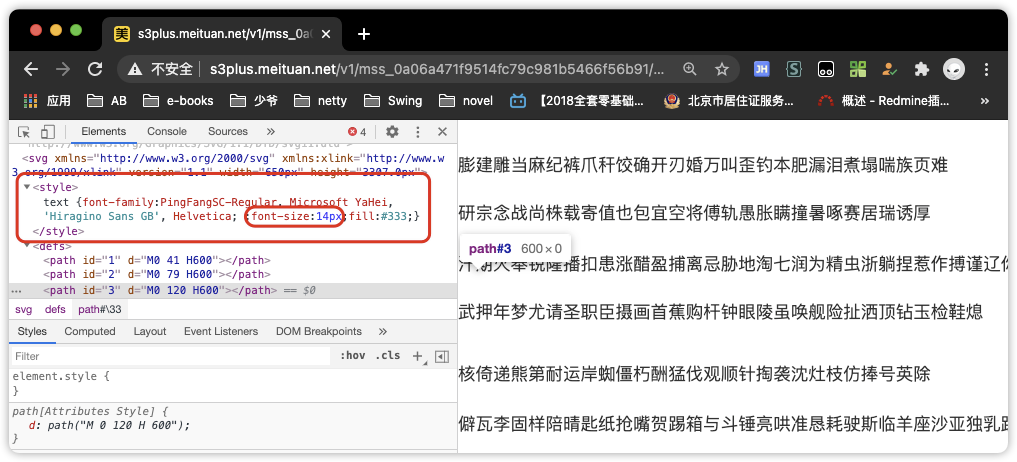
不要问我为啥知道,经验使然,其实就是瞎猜-v-列方程去哈哈
又搞了几轮测试,基本上确定了。
.oyep4y {
background: -apx -bpx;
}
- 先找到样式中的 b 的值 即 -97 绝对值一下为 97
- 根据
<path xmlns="http://www.w3.org/2000/svg" id="3" d="M0 120 H600"/>中d 的第二个值,找 97 小于的第一个 path.id 即 3 (79 < 97 < 120 ) - 根据 3 找
<textPath xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="#3" textLength="476">汗期火奉锐隆播扣患涨醋盈捕离忌胁地淘七润为精虫浙躺捏惹作搏谨辽你斩狸</textPath>中的 xlink:href=“#3” - 计算 a/fontSize = 1即第二个字(下标从 0 开始- -)。
同理,找一下男票的男,其a = 504 b= 2210 对应的 pathId = 55
504/14=36
<textPath xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="#55" textLength="518">堵随罚穷丽累源嚷型榴汉很似戴陡枣绝了疼那蓄入朱锣式爱毙版她根扇牢凤盆拖酸男</textPath>
查吧。第 36 个字
附上地址。一个 svg 背景中都是字
nice,就是这个规律。找到规律了,就要撸代码了。里面坑还真不少。
坑一:反爬机制导致不间断的报 403-。-
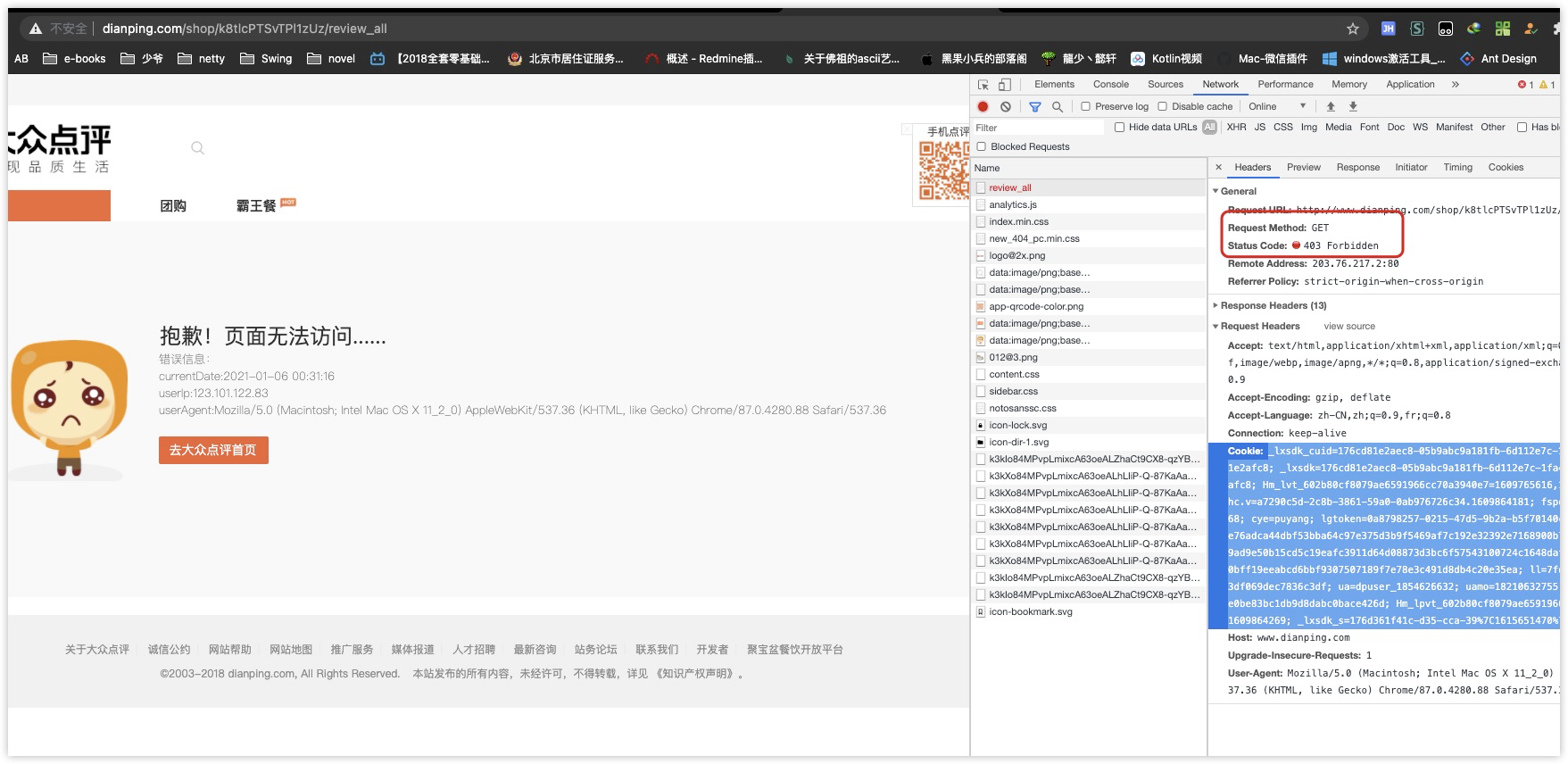
这种行为,不得以让我选择先爬页面,后解析。因为我是边爬边写的代码。。。。
坑二:分析时是这样的,爬下来的不是
这个怎么说呢。就是上面的分析是对的,但是爬下来的页面不是这样的。而是这样的
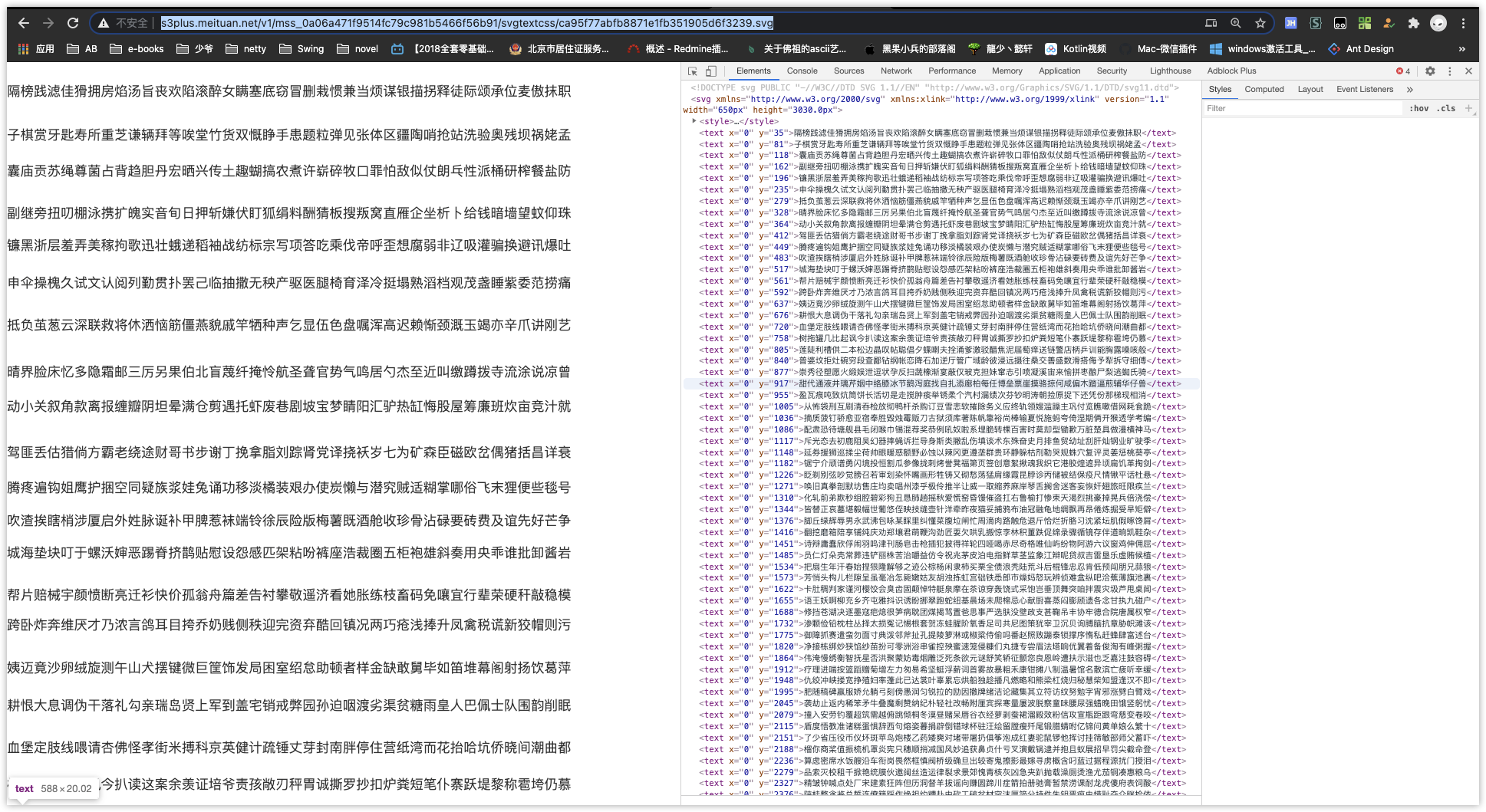
但是基本上是一个意思,这种反而简单了。
爬到的页面:
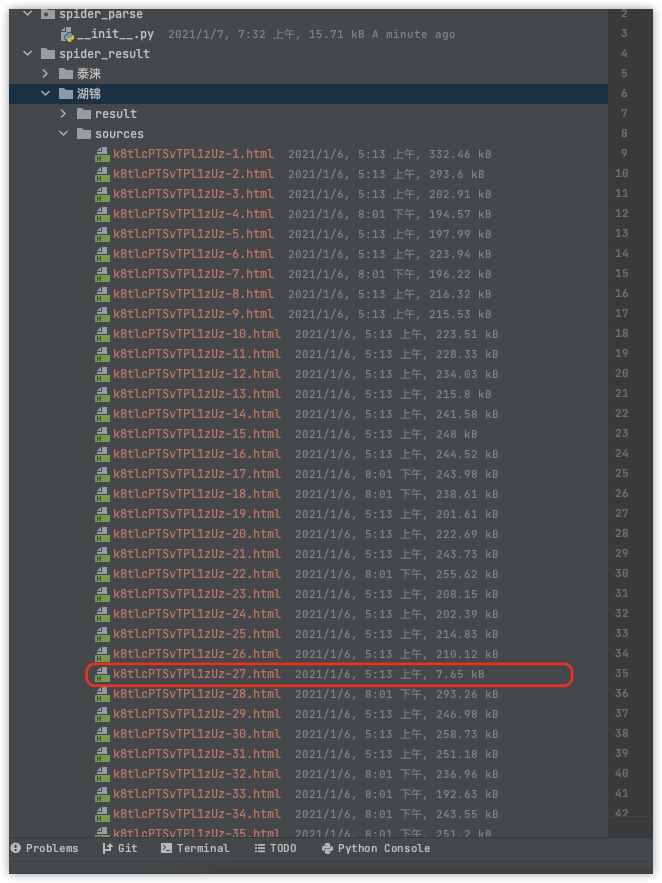
其中这个 7kb 的就是错误的页面 403 了
写入 excel 结果:

目录结构:
这里我做了一下傻瓜式操作,为了就是方便我的小伙伴简单使用。所以是这样的
├── README.md
├── main.py --------------------入口
├── spider_parse ---------------解析相关的
│ └── __init__.py
└── sprider_network ------------爬页面相关的
└── __init__.py
核心代码:
main.py
# 抓取模块
import sprider_network
# 解析模块
import spider_parse
# 把爬到的数据写到一个 Excel 表里。也就是 sheet 名为 "湖锦" 后续跟店名替换即可
excel_sheet_name = "湖锦"
if __name__ == '__main__':
menu_choose = input("请输入菜单序号: 1. 爬页面 2. 解析 html 文件 3. 抓取未抓取到的页面: ")
if menu_choose == "1":
# 抓取页面
page_path = input("请输入待抓取页面的 URL(只写到 p 前面的即可,如http://www.dianping.com/shop/k8tlcPTSvTPl1zUz/review_all/p):")
page_num = input("请输入要抓取的页面数量(如要抓取100页,则输入100):")
cookies = input("请输入 COOKIE(防封):")
sprider_network.spider_html(page_path, page_num, cookies)
elif menu_choose == "2":
# 解析html 文件 默认只解析文件大小大于 100KB 的文件
dir_path = \
input("请输入抓取的页面所在的路径:")
# "/Users/yunxuan/PycharmProjects/spider/spider_result/红鼎豆捞/sources"
spider_parse.load_dir(dir_path)
else:
# 防止一次没抓完,有403/404 问题
page_path = input("请输入待抓取页面的 URL(只写到 p 前面的即可,如http://www.dianping.com/shop/k8tlcPTSvTPl1zUz/review_all/p):")
page_num = input("请输入要抓取的页码,以英文逗号分开,如:1,3,8:")
cookies = input("请输入 COOKIE(防封):")
page_number = page_num.split(",")
for i in range(0, len(page_number)):
sprider_network.spider_html(page_path, page_num, cookies)
抓页面:
# 浏览器标识
from fake_useragent import UserAgent
# 请求
import requests
# 文件读写
import os
import time
# 初始化一个浏览器标识对象
ua = UserAgent()
# 抓取页面的请求头信息
request_pages_headers = {
'User-Agent': ua.random,
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Host": "www.dianping.com",
"Connection": "keep-alive",
"Cache-Control": "max-age=0",
"Accept-Language": "zh-CN,zh;q=0.9,fr;q=0.8",
"Accept-Encoding": "gzip, deflate",
}
def spider_html(url, page_num, cookie):
"""
抓取 URL 页面
:param url: 待抓取的 URL 前缀,不含页码
:param page_num: 待抓取的页面数量
:param cookie: 登陆后的 COOKIE
:return: 没返回的
"""
# 给字典添加 Cookie
request_pages_headers["Cookie"] = cookie
# 页码字符串转成数字
page_num_int = int(page_num)
# 不做过多判断了,毕竟不是商业化。只是方便使用的,不会随便传参数- -
# 定义一个错误页面数组
error_page = []
for i in range(0, page_num_int):
current_page_number = str(i + 1)
print("正在抓取第[" + current_page_number + "]张页面")
# 拼装待抓取的 URL 全路径
request_url = url + str(i)
# 模拟打开浏览器,输入路径
html = requests.get(request_url, headers=request_pages_headers)
if html.status_code != 200:
print("第[" + current_page_number + "]张页面抓取失败,请记录序号,后续使用 3 菜单重新抓取")
error_page.append(current_page_number)
else:
# 抓取成功的,写入文件
html_file_name = "page(" + current_page_number + ").html"
# 声明一个目录
dir_path = os.path.abspath("spider_result")
# 判断是否存在
is_exists = os.path.exists(dir_path)
if not is_exists:
# 不存在 创建目录
os.makedirs(dir_path)
# 存在 直接写入
with open(dir_path + "/" + html_file_name, "w", encoding="UTF-8") as f:
f.write(html.text)
f.close()
print("第[" + current_page_number + "]张页面已保存在" + dir_path)
time.sleep(3)
# 错误页面信息写入日志
dir_path = os.path.abspath("log")
is_exists = os.path.exists(dir_path)
if not is_exists:
# 不存在 创建目录
os.makedirs(dir_path)
with open(dir_path + "/error.log", "w", encoding="UTF-8") as f:
f.write(str(error_page))
f.close()
print("错误页面已保存至 error.log 文件中,路径:", dir_path)
print("休息完毕,继续工作")
页面解析:
import os
import xlwt
import re
import requests
from pyquery import PyQuery as pq
import datetime
from fake_useragent import UserAgent
ua = UserAgent()
css_header = {
"Accept": "text/k8tlcPTSvTPl1zUz,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate",
'Accept-Language': 'zh-CN,zh;q=0.9,fr;q=0.8',
'Connection': 'keep-alive',
"Host": "s3plus.meituan.net",
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': ua.random,
}
def load_dir(dir_path):
"""
加载目录
:param dir_path: html 文件存放目录
:return: 不返回了吧
"""
# 对目录下文件进行一个排序操作
file_paths = sorted(os.listdir(dir_path))
# 定义一下有多少个文件
file_count = len(file_paths)
# 只抓取2019-1.1 到 2021-1-1 即 2018-12-31 23:59 to 2021-01-01 00:00
# 定义一个 Excel 文件
workbook = xlwt.Workbook(encoding='utf-8')
# 添加一个工作表
worksheet = workbook.add_sheet("未命名工作表")
# 0-10 第 0 行 0 - 10 列。 当做表名
worksheet.write(0, 0, label='评论时间')
worksheet.write(0, 1, label='用户名')
worksheet.write(0, 2, label='评论内容')
worksheet.write(0, 3, label='评论字数')
worksheet.write(0, 4, label='图片数量')
worksheet.write(0, 5, label='有无视频')
worksheet.write(0, 6, label='评分总分')
worksheet.write(0, 7, label='评论者等级')
worksheet.write(0, 8, label='评论下的评论数')
worksheet.write(0, 9, label='点赞数')
worksheet.write(0, 10, label='用户描述')
# 定义一个行数,用来写到 Excel 文件对应位置中
row_index = 1
for i in range(0, file_count):
if row_index == -1:
# 结束了,别解析了
break
# 解析文件
row_index = parse_html_file(dir_path + "/" + file_paths[i], worksheet, row_index)
workbook.save(dir_path + "/result.xlsx")
def parse_html_file(file_path, worksheet, row_index):
"""
解析 html 文件
:param file_path: 文件路径
:param worksheet: Excel 文件对象
:param row_index: Excel 的行号 从第 1 行开始,向下写
:return:
row_index: 是否结束解析标志 -1 结束解析
"""
# 读取文件内容到ret 变量中
ret = open(file_path).read()
# 使用选择器把文本转成对象
doc = pq(ret)
# 找页面中的评论区
comments_area = doc("div.reviews-items > ul > li").items()
for data in comments_area:
# 解析 css
dict_svg_text, list_svg_y, dict_css_x_y, is_continue = parse_css(ret)
if not is_continue:
# css 样式解析失败,没必要再解析html 页面了。解析出来也是错误的
print("加密 css 样式解析失败:", file_path)
return row_index
# 用户名
user_name = data("div.main-review > div.dper-info > a").text()
# 用户评分星级[10-50]
start_shop = str(data("div.review-rank > span").attr("class")).split(" ")[1].replace("sml-str", "")
# 用户描述:机器:非常好 环境:非常好 服务:非常好 人均:0元
describe_shop = data("div.review-rank > span.score").text()
# 关键部分,评论HTML,待处理,评论包含隐藏部分和直接展示部分,默认从隐藏部分获取数据,没有则取默认部分。(查看更多)
comments = data("div.review-words.Hide").html()
try:
len(comments)
except:
# 展开评价
comments = data("div.review-words").html()
# 图片数量
pictures = data("div.main-review > div.review-pictures > ul > li > a > img")
# 数量
pic_num = pictures.length
pic_link = str(pic_num) + "张:\n"
# 链接
for pic in pictures.items():
pic_link += (str(pic.attr('data-big')) + "\n")
# 评论点赞数
comments_click_goods_num_wrapper = data("div.main-review > div.misc-info.clearfix > span.actions")
comments_click_goods_number_wrapper_children = comments_click_goods_num_wrapper.children()
comments_goods_num = comments_click_goods_number_wrapper_children.text().replace("(", "").replace(")", "")
# 发表评论的时间
comments_time = data("div.main-review > div.misc-info.clearfix > span.time").text()
if "更新于" in comments_time:
comments_time_array = comments_time.split('更新于')
date_string = comments_time_array[0].replace("\xa0", "").strip()
comments_time_date_time_type = datetime.datetime.strptime(date_string, '%Y-%m-%d')
# 结束时间 2019-01-01
end_time = datetime.datetime.strptime("2018-12-31 23:59", "%Y-%m-%d %H:%M")
# 日期比较 如果到达这个时间。 则不继续爬
diff = comments_time_date_time_type - end_time
if diff.days <= 0:
# 说明是2018 年 12 月 31 日前的数据
return -1
else:
# 评论时间转日期类型
comments_time_date_time_type = datetime.datetime.strptime(comments_time, '%Y-%m-%d %H:%M')
# 结束时间 2019-01-01
end_time = datetime.datetime.strptime("2018-12-31 23:59", "%Y-%m-%d %H:%M")
# 日期比较 如果到达这个时间。 则不继续爬
diff = comments_time_date_time_type - end_time
if diff.days <= 0:
# 说明是2018 年 12 月 31 日前的数据
return -1
# 评论内容 根据上边的字典,去对应评论区的文字
comments_content = css_decode(dict_css_x_y, dict_svg_text, list_svg_y, comments)
print("评论内容:", comments_content)
worksheet.write(row_index, 0, label=comments_time)
worksheet.write(row_index, 1, label=user_name)
worksheet.write(row_index, 2, label=comments_content)
worksheet.write(row_index, 3, label=len(comments_content))
worksheet.write(row_index, 4, label=pic_link)
worksheet.write(row_index, 5, label="1")
worksheet.write(row_index, 6, label=start_shop)
worksheet.write(row_index, 7, label="1")
worksheet.write(row_index, 8, label="见点赞数中的信息")
worksheet.write(row_index, 9, label=comments_goods_num)
worksheet.write(row_index, 10, label=describe_shop)
row_index += 1
return row_index
def parse_css(ret):
"""
解析css的方法 主要用来处理评论区中的 css 样式 以及处理加密字体
注意:这里大众点评有目前有两种形式,所以我们要针对两种不同的方式使用不同的解析方式处理:
一种 svg 数据
以 <path id="xxx" d="xx xxx xxx" /> 为键
以 <textPath xlink:href="xx" textLength="xx">xxxx</textPath>为value 的形式存储明文
我们定义为 A 方式
另外一种直接
以 <text x="xxx" y="xxx">xxx</text>的形式存储
我们定义为 B 方式
:param ret: 网页源代码
:return:
dict_svg_text:key - value 形式返回 svg 数据
list_svg_y:
A 方式返回 <path>标签里的[x,y]坐标轴,以[x,y]形式返回
B 方式返回 <text>标签里的y数据,x 以自增的形式组装成[x,y]的形式
dict_css_x_y:css 样式中,每个加密字体的密文 形如:<svgmtsi class="xxxx"></svgmtsi>之类的
根据class 找到对应样式中的background: apx bpx 中的[a,b]
is_continue:
是否继续的标志
"""
# 定义一个是否继续的标识,True 代表继续 False 代表不继续
is_continue = True
# 从当前页面中找到第一个包含 svgtextcss 关键字的 css 路径 目前来说,页面一般只有一个
# <link style="text/css" href="//xxxxx/svgtextcss/xxxx.css"/>
css_path_obj = re.search(r'<link re.*?css.*?href=\"(.*/svgtextcss/.*?)\"', ret)
try:
# 组装完整 url 这个1 代表上述正则中的第二个 (.*?)内容 即 (.*/svgtextcss/.*?)
css_link = "http:" + str(css_path_obj[1])
except:
# 没找到。为啥没找到?说明页面中没有,为啥没有。说明页面抓取失败- -
is_continue = False
return None, None, None, is_continue
print("获取 CSS 样式中...", css_link)
# css 文件的内容 通篇 .className{ background: apx bpx; } 其中有三个带 url(//) 的
css_html = requests.get(css_link, headers=css_header)
# svg 加密文字的 URL 路径,目前来说,一个 css 文件中有3 个。经测试,一般第二个是我们使用的,第一个跟第三个我也不知道干啥的,
# 第一个打开是一串数字,大概9 位
# 第三个打开是一小部分明文,但是感觉不太像,跟着感觉走~
svg_link_array = re.compile("\/\/(.*?)\)").findall(str(css_html.text))
# 解析 svg 文本内容
dict_avg_text, list_svg_y = parse_svg_text(svg_link_array)
# 解析 css 样式表,取background 中 a,b 组装字典
dict_css_x_y = parse_css_text(css_html.text)
return dict_avg_text, list_svg_y, dict_css_x_y, is_continue
def parse_svg_text(svg_link_array):
"""
解析加密字典的文件
:param svg_link_array: 文件的 URL 数组
:return:
dict_svg:组装的字典
list_y:
"""
length = 0
svg_html_text = ''
for i in range(0, len(svg_link_array)):
# 请求连接
svg_html = requests.get("http://" + svg_link_array[i], headers=css_header)
content_length = int(svg_html.headers["Content-Length"])
if content_length > length:
length = content_length
svg_html_text = svg_html.text
dict_svg, list_y = parse_svg_test(svg_html_text)
return dict_svg, list_y
def parse_svg_test(svg_html_text):
svg_text_r = r'<textPath xlink:href="(.*?)" textLength="(.*?)">(.*?)</textPath>'
svg_text_re = re.findall(svg_text_r, svg_html_text)
if len(svg_text_re) == 0:
return parse_svg_test_b(svg_html_text)
else:
return parse_svg_test_a(svg_html_text)
# A 方式
def parse_svg_test_a(svg_html):
"""
形如:
http://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/74d63812e5b327d850ab4a8782833d47.svg
页面上有两部分内容
一部分是位于上方的 <defs> 下的
<path id="(.*?)" d="(.*?) (.*?) (.*?)"/>
一部分是位于下方的 <text lengthAdjust="spacing"> 下的
<textPath xlink:href="(.*?)" textLength="(.*?)">(.*?)</textPath>
<defs>
<path xmlns="http://www.w3.org/2000/svg" id="32" d="M0 1317 H600"/>
<path xmlns="http://www.w3.org/2000/svg" id="33" d="M0 1364 H600"/>
</defs>
<text lengthAdjust="spacing">
<textPath xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="#32" textLength="336">枪畜栏督胖扶遍秒搞笨类敏蛛与诊绵病蓝份碑往气焰望</textPath>
<textPath xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="#33" textLength="476">腥钉息元易分绝归当洽疑桂畅朵照仍船从论织朗瓣讲首此苗砌能您泛押蜜徐膏</textPath>
<textPath xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="#34" textLength="378">数幼段请攻议耐仙锻征兼句拼愁义食校楚商姻映辆黎鸽怕被测</textPath>
</text>
我们要根据 path 标签里 d 的第二位,对应 css 样式表中 background 的bpx 参数
假设有一个 css .ory4hj{background:-168.0px -1353.0px;}
其中 a = -168.0 b = -1353.0
全部取正 1317 < b < 1364 则我们要的字在 1364 的 id 33 中
33 对应 <textPath> 中的 xlink:href="#33"
:param svg_html: 源文件
:return:
"""
svg_text_r = r'<textPath xlink:href="(.*?)" textLength="(.*?)">(.*?)</textPath>'
svg_text_re = re.findall(svg_text_r, svg_html)
dict_avg = {}
i = 0
# 生成svg加密字体库字典
for data in svg_text_re:
dict_avg[i] = list(data[2])
# print("生成解密字典", i, ":", dict_avg[i])
i += 1
svg_y_r = r'<path id="(.*?)" d="(.*?) (.*?) (.*?)"/>'
svg_y_re = re.findall(svg_y_r, svg_html)
list_y = []
# 存储('18', 'M0', '748', 'H600') eg:(x坐标,未知,y坐标,未知)
for data in svg_y_re:
data_ = [int(data[0]) - 1, data[2]]
list_y.append(data_)
# print("存储解密索引", "行号:", data_, "行索引", data[2])
return dict_avg, list_y
# B 方式
def parse_svg_test_b(svg_html):
"""
http://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/ca95f77abfb8871e1fb351905d6f3239.svg
同理。解密思路不变。只是找数据的方式变了。参考方式 A
<text xmlns="http://www.w3.org/2000/svg" x="0" y="805">莲陡利槽供二本松边晶叹帖聪倡夕蝶喇夫拴涌爹激驳醋焦泥届萄痒送链警店柄乒训能胸露嗓咳般</text>
:param svg_html:
:return:
"""
svg_text_r = r'<text x="(.*?)" y="(.*?)">(.*?)</text>'
svg_text_re = re.findall(svg_text_r, svg_html)
dict_avg = {}
i = 0
# 生成svg加密字体库字典
for data in svg_text_re:
dict_avg[i] = list(data[2])
i += 1
svg_y_r = r'<text x="(.*?)" y="(.*?)">(.*?)</text>'
svg_y_re = re.findall(svg_y_r, svg_html)
list_y = []
j = 0
for data in svg_y_re:
list_y.append([j, data[1]])
j += 1
return dict_avg, list_y
def parse_css_text(css_html):
"""
http://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/883f229cc13ecde07cc3e3e3af16819e.css
这个就比较简单了。取.ory4hj{background:-168.0px -1353.0px;} a 值 b 值就行
:param css_html: css 源文件
:return:
"""
css_text_r = r'.(.*?){background:(.*?)px (.*?)px;}'
css_text_re = re.findall(css_text_r, css_html)
dict_css = {}
for data in css_text_re:
"""
加密字库.ory4hj{background:-168.0px -1353.0px;} 与svg文件对应关系,x/14,根据font-size 计算
y,原样返回,需要在svg函数中做处理
"""
x = int(float(data[1]) / -14)
"""
字典参数:{css参数名:(background-x,background-y,background-x/14,background-y)}
"""
dict_css[data[0]] = (data[1], data[2], x, data[2])
# print("存储加密解析数据", "索引值:", data[0], "x 向量: ", data[1], "y 向量:", data[2], "加密字符位置:", x)
return dict_css
def css_decode(css_html, svg_dictionary, svg_list, comments_html):
"""
最终评论汇总
:param css_html: css 的HTML源码
:param svg_dictionary: svg加密字库的字典
:param svg_list: svg加密字库对应的坐标数组[x, y]
:param comments_html: 评论的HTML源码,对应0-详情页的评论,在此处理
:return: 最终合成的评论
"""
css_dict_text = css_html
csv_dict_text, csv_dict_list = svg_dictionary, svg_list
# 处理评论源码中的 svgmtsi 标签,生成字典key
comments_text = comments_html.replace('<svgmtsi class="', ',').replace('"/>', ",").replace('">', ",")
comments_list = [x for x in comments_text.split(",") if x != '']
comments_str = []
for msg in comments_list:
# 如果有加密标签
if msg in css_dict_text:
# 参数说明:[x,y] css样式中background 的[x/14,y]
x = int(css_dict_text[msg][2])
y = -float(css_dict_text[msg][3])
# 寻找background的y轴比svg<path>标签里的y轴小的第一个值对应的坐标就是<textPath>的href值
for g in csv_dict_list:
if y < int(g[1]):
comments_str.append(csv_dict_text[int(g[0])][x])
break
# 没有加密标签
else:
comments_str.append(msg.replace("\n", "").replace(" ", ""))
str_comments = ""
for x in comments_str:
str_comments += x
# 处理特殊标签
dr = re.compile(r'</?\w+[^>]*>', re.S)
dr2 = re.compile(r'<img+[^;]*', re.S)
dr3 = re.compile(r'&(.*?);', re.S)
dd = dr.sub('', str_comments)
dd2 = dr2.sub('', dd)
comments_str = dr3.sub('', dd2)
return comments_str
总结:
思路基本上就是分析到抓取的页面,主要是定位需要的数据在页面的什么地方,是怎样的结构
然后模拟请求,正则匹配取需要的数据。py的好处,我个人感觉在于有像 jQuery 一样的选择器。方便从页面上取数据。
最后附上环境相关的
| 项 | 值 |
|---|---|
| 硬件环境 | MacBookPro |
| 软件环境 | Python 3.8 |
| IDE 版本 | PyCharm 2020.3 |
嗯。别的应该也没什么啦。就这样啦。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号