软工-结对编程作业#1
教学班级地址:BUAA_SE_2021_LR
GitLab项目地址:2021_Yilong_Li-Changyao_Tian_pair_work
| 成员学号 | |
|---|---|
| L同学 | 3580 |
| T同学 | 3636 |
结对编程感受分享

From T同学
结对编程的初衷,或者说是其本来目的,我想应当是为了提高编程的效率。毕竟只要精诚合作,两个人的力量总是要胜过一个人的单打独斗。但要只是仅仅为了使编程这件事本身更加高效,那未免又有些太没有人情味了。所以我又想,这其中多少应当还有些培养双方默契、增进一下友谊的意味在里面。
但具体到每一组里,那又是千人千面了。别的组不好说,但就我们组而言,因为种种客观因素的限制(i.e. deadline太近,双方时间错不开等等),所以真正能够在一起当面编程的时间并不算充裕,更多地还是采取双方协力的分工合作形式完成。但即便如此,我也还是觉得两个人的编程体验比起一个人来还是更加愉悦;至于按照"人·时"为单位整体效率是提升了还是降低了,那还真不好说。
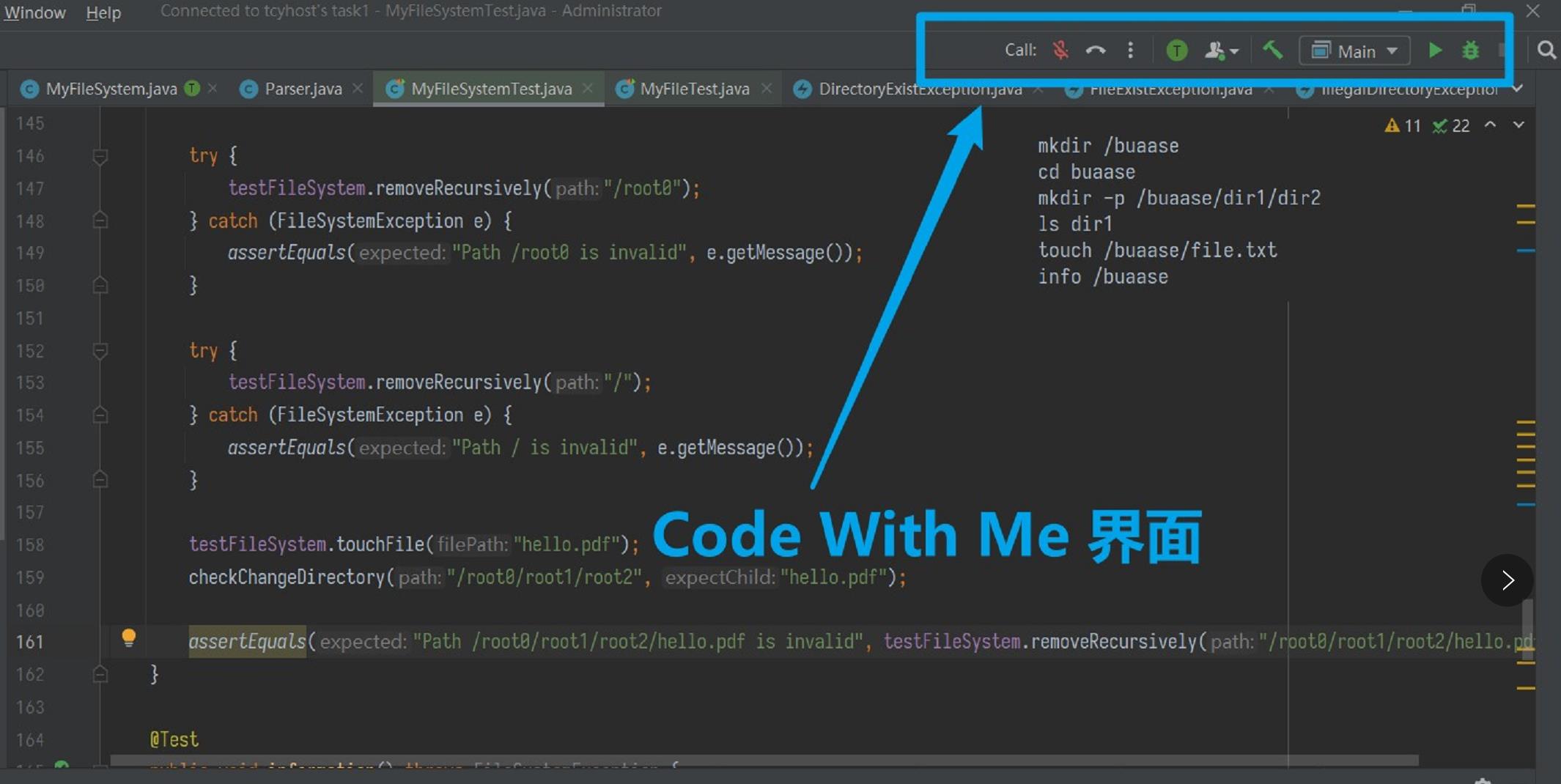
这里首先要特别感谢L同学分享的Code with Me插件,与IDEA搭配起来进行结对编程,体验可以说是非常的赞——有一点多人联机的那种感觉。两人可以同时对代码进行编辑,并且进行远程实时的语音沟通,很大程度上弥补了不能在一块当面编程的缺憾。不过唯一的缺点就是似乎它目前仅支持单人代码提示,希望以后能继续改进~
此外,无论是采用Ping-Pang还是Navigator-Driver,我认为结对编程不是为了在工作量上做到两人平分,而是希望在思维模式上实现两人互补,在编程习惯上实现两人互鉴。唯有如此,才能真正让双方都能在这场奇妙的体验中有所收获。

以我们自己为例,比如在实现阶段,我最开始为了尽可能地将代码进行封装和复用,采用了内部抛异常+外部try-catch的方法对一些特殊情况进行特判。我自己写的时候并不觉得这有什么不妥,但L同学作为旁观者第一时间就敏锐地发现了我这样做会明显降低代码的可读性,并造成上层调用者与下层被调者之间的深度耦合。于是,我也在思考后及时决定换了另一种更清晰的方式进行实现,事实最终也证明另一种方法也同样能够实现很好的封装,并且无需处理复杂的异常情况。
如果只有我一个人,会不会选择这plan B呢?我想,或许最终也是会的,但很可能就要等到我把全部代码都实现之后进行优化时才会考虑了。
再比如,如果只是我自己写代码的话,常常会自己和自己有一些约定俗成的惯例,比如一些变量的缩写等等。像这次我一开始就把父目录定义为fatDir,我自己当然一目了然,但其他人或许就会在想这个胖目录是个什么东西了。于是最后,我也在L同学的建议下,采用了fatherDir这样的全称加以命名。
类似的细节还有很多,比如更良好的代码注释,更统一的架构设计等等。我想也正是这些细节的改变方能真正展现出结对的魅力之所在。他人就像一面镜子,既能照出你的风光,也能让那些微小的缺陷暴露无遗。
From L同学
本次结对编程的任务量较大,让人不免担忧之后的两次迭代将如何收尾。结对编程也是二人团队互相磨合的过程,在合作中我感受到了T同学的很强的责任心,这种特质在实际的工程团队中想来也是珍贵的。
具体设计过程遇到的问题上文已经介绍过,结对中我主要负责
由于双方重合的空闲时间并不多,我们进行了两次线下讨论,多数时间则借助IDEA的 Code With Me 插件进行协同。Code With Me是IDEA 2020.3版本的新特性,可以与其他人实施协同处理IDE中的项目,通过视频和音频建立成员间的实时交流。只需Host进行相关环境的配置,Guest则可以对现有代码进行修改。不过在实际使用过程中,发现Code With Me还是存在不少有待改进之处:
- 成员同时编辑单文件时,只能有一个人收到代码提示
- Host无法向Guest开放创建文件的权限
- 网络信号差时,Guest编辑的代码没有缓存,会直接丢失
在这次结对中我也有要反思的地方:比如T同学举的用try catch处理部分业务逻辑的例子,在我刚Review时就感觉这段代码有些奇怪,但我又欠缺相关的专业知识,难以清晰将问题表述出来。最后在查阅资料后才重新与T讨论,并导致T同学在已经用这种方式写完
总的来说,第一周是从单打独斗到适应结对编程的缓冲期,希望在之后能做得更好。
项目设计与实现思路
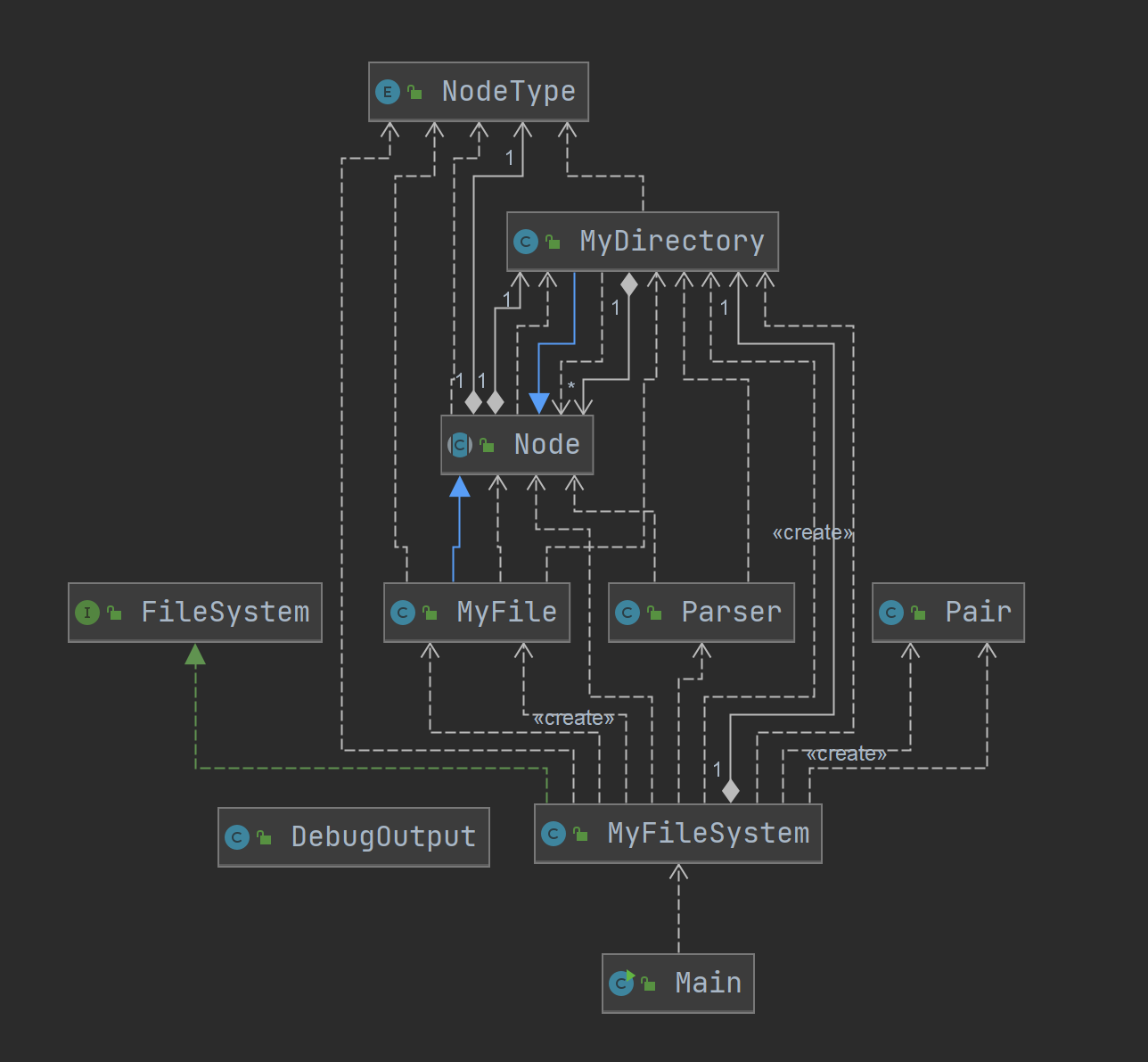
本次结对编程的主要任务为实现一个基于内存的文件管理系统。整体开发流程遵循传统的软件开发思路,分为"设计——实现——测试"三个阶段。其中设计阶段由两人共同完成,主要侧重于整体架构设计和一些主要的类及其属性和方法的简要说明,并且撰写了简单的设计文档(篇幅所限&比较粗糙,这里就不放了)。其中,lyl主要负责
而在实现部分,lyl主要负责Code With Me实现了远程协作编程,从而可以及时地发现互相的错误和问题,避免更多错误的产生。
在具体实现上,一方面,我们尽可能地提取出顶层各个接口方法中共性的内容,如目录的递归查找、叶节点的获取与判断等,并对其进行封装和复用,从而降低了代码整体的冗余度,提升了可读性与可维护性。
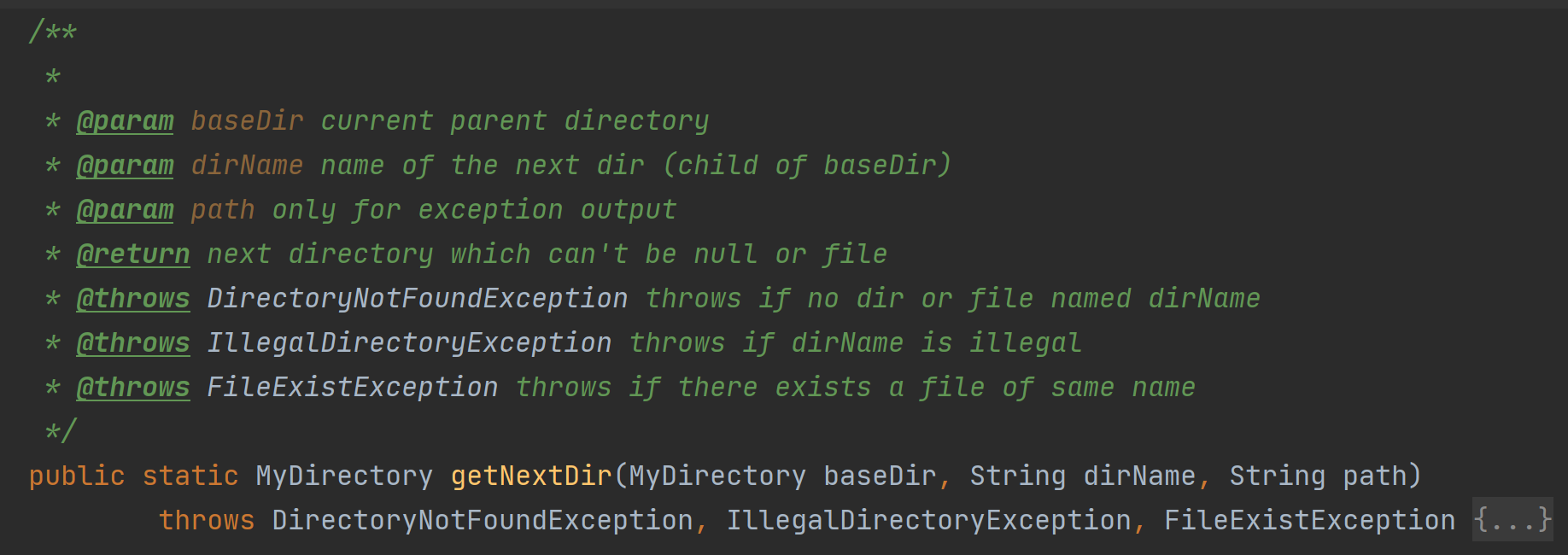
另一方面,虽然指导书中对于所有的异常行为都完全一样,但为了提升可读性,同时也为了日后潜在的拓展,我们仍专门为所有的异常构建了不同的exception子类,从而保证处理过程中可能发生的所有异常行为均能被顶层有效地捕捉到。
在测试部分,tcy主要负责MyFileSystem与MyFile类的测试,最终整体的单元测试覆盖率达到97%,基本实现了各部分内容的完全覆盖。
此外,我们还进行了压力测试,考虑了边界数据的情况。实测证明,在极端情况下,程序的运行时间可能会超过指导书要求的真实时间,但这似乎无法利用编码进行进一步的优化,因此希望课程组可以手下留情。
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 90 | 150 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 720 | 1000 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 30 |
| · Design Spec | · 生成设计文档 | 15 | 25 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 60 | 75 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 15 |
| · Design | · 具体设计 | 60 | 120 |
| · Coding | · 具体编码 | 600 | 800 |
| · Code Review | · 代码复审 | 60 | 75 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 200 | 300 |
| Reporting | 报告 | 60 | 90 |
| · Test Report | · 测试报告 | 10 | 10 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 870 | 1240 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号