道法之间——软工第2次博客作业
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 2021春季计算机学院软件工程(罗杰 任健) |
| 这个作业的要求在哪里 | 个人阅读作业#1要求 |
| 我在这个课程的目标是 | 进一步提升工程化开发能力,积累团队协作经验,熟悉全栈开发流程 |
| 这个作业在哪个具体方面帮助我实现目标 | 通过阅读《构建之法》和学习CI/CD集成评测,有助于系统性了解软工流程和掌握相关工具的使用 |
软件工程究竟是什么?怀着这样的疑问,我仔细地翻阅了《构建之法》这本书,也算是系统性地对软件工程的各个环节与组成有了一个大致的了解,这才终于得到了一个大致满意的答案:
其实这个公式只是把邹老师在本书一开始给出的\(\text{软件} = \text{程序}+\text{软件工程}\)作了简单的移项变换,就从对软件的定义变成了对软件工程的定义:所谓软件工程,即是指在软件的开发过程中,把与算法程序有关的部分剥去之后所剩下来的内容,这部分内容与程序的编写者直接相关。
于是说到底,软件工程这门课程所真正想要讨论的核心是”人在软件开发过程中所应该扮演的角色“,而非”如何去编写一段高质量的代码“;尽管这两者看起来似乎有些因果的味道。
如果将”人的立身之本“看作【道】,将程序的撰写比作【法】,那么软件工程所处的位置,正是这道法之间。
《构建之法》疑问梳理
Q1. 什么样的功能才有实现的必要?
- 问题出处:P7 ~【Ch01 概论——航空业与软件业的类比】
在这部分内容中,为了说明商用软件和爱好者写的程序的区别,作者以航空业类比进行了如下的论述:
说到商用软件和爱好者写的程序的区别,我们还可以看看这个例子:
如果一架民用飞机上有一个功能,用户使用它的概率是百万分之一,你还要做这个功能么?你会选择:
根本不考虑
如果没时间实现这个功能就算了
做了,但是不用告诉用户
做了,而且不厌其烦地告诉用户如何使用
你会如何选择呢?选择之后,这个功能究竟是什么呢?
谜底是:
飞机的安全功能
我认为作者在这里的论述存在着明显的误导性,似乎想要证明无论是什么功能,只要用户有可能要用到,即便可能性很小,一个合格的商用软件开发者也必须要在一开始加以考虑并予以实现。否则万一这个功能就像飞机的安全功能一样在关键时刻可以救人一命的话,到时候再后悔就为时已晚了。
首先需要承认的是,确实存在一些用户平时甚少使用但却极为重要的功能,就如同飞机里的安全功能一样。但对于这些功能,我们之所以在程序中需要加以实现,显然不是因为它被使用到的概率很低,而是因为它的重要性不容忽略。同样是民用飞机上一个使用概率为百万分之一的功能,甚至比这个高一些,可能有万分之一,比如给飞机上的电影库中更新一部最近刚刚上映的小众电影,难道也需要开发者在一开始就要去考虑实现它吗?
因此,我想作者在这里真正想要强调的其实是对一个功能重要性的判定问题,即如何在开发一个软件之前就能预先判定哪些功能是必不可少的,哪些功能是可有可无的,且这种判定本身与这一功能的使用频率之间不应构成直接的相关关系。这也正是取分商用软件和爱好者的关键所在。
至于具体应该如何衡量这一重要性,则是第8章【需求分析】所讨论的内容了。
Q2. 单元测试应该由谁来写?
- 问题出处:P25 ~【Ch02 个人技术和流程——单元测试】
在讨论”好的单元测试的标准时“,作者给出了以下观点:
单元测试必须由最熟悉代码的人(程序的作者)来写。
代码的作者最了解代码的目的、特点和实现的局限性。所以,写单元测试没有比作者更适合的人选了。
对此我并不是完全认同。一方面,进行测试工作的人必须是熟悉代码的人,这点毋庸置疑:如果一个人之前从未阅读过这份代码,那么他也很难对代码的细节和功能有一个清晰的认识。但另一方面,写单元测试的一定得是最熟悉的人(也就是作者)吗?
在现如今许多成熟的科技公司中,面向编程开发人员往往会设置多种岗位,其中就包括算法岗、运维岗、测试岗——这也就意味着在一个成熟的商业公司中,【开发】与【测试】这两步往往都是分离的,并不是由同一个人甚至是同一个团队来完成,而是会交给专门的测试人员去做。之所以这样,乃是因为一般来说代码的编写者本身往往会陷入到自己的思维定势中,很难跳出自己的视角彻头彻尾地审视这段代码,正所谓”不识庐山真面目,只缘身在此山中“。
当然,要想确保测试人员能够清楚地理解开发者编写的代码,对代码进行良好的封装与抽象以及一份清晰的说明文档是必不可少的,这就对一个商业公司的规范与文化提出了较高的要求。对于普通的业余编程爱好者而言,或许还是自己来写单元测试的好——谁让没有经费呢。
Q3. 专和精的关系到底是什么?
- 问题出处:P53 -【Ch03 软件工程师的成长——软件工程师的职业发展】
在这部分内容中,作者举了街头卖艺的单人乐队、只研习某一乐器的交响乐团中的乐手和编写交响乐的作曲家的例子,似乎想要引发读者对于【专和精的关系】的思考。(原文较长,故在此不再引用)
这里我对于作者的论述过程感到非常疑惑。在我的认识中,”专“和”精“这两个概念应该是同义词,【专】即专业,【精】即精通——一个人的专业自然就是一个人精通的内容,这有什么思考的必要吗?
鉴于作者所举的3个音乐方面的例子,我认为可能他真正想要讨论的是【专和”全“的关系】,即对于弹奏一种乐器的乐手而言,精通这一种乐器似乎要比对每种乐器都略知一二要更受人们的欢迎;但对于作曲家、指挥家们而言,则必须要对所有可能用到的乐器都要有一定程度的理解。那么,对于一名工程师而言,究竟应该是更”专“一点好,还是更”全“一点好呢?
对于这个问题,我认为单纯强调”专“更好或者”全“更好都过于片面而不够客观,归根结底还是对于【软件工程师】这一职位地定义太过模糊与宽泛。同样都是工程师,不同人的分工也有所不同:有人专精于前端或后端相关技术栈,有人则需要统筹全局地架构和部署。此外,在一个人的职业生涯中,其承担的职责也是在不断流动的。也许他在入门时可能只是擅长某一特定方向的程序员,但在不断的磨砺与成长后也完全有可能去独自领导一个团队;或者也许他在入门时各方面基础都比较扎实,但在不断的探索中他也完全有可能找到自己擅长且感兴趣的方向,最终成为这个方向上的开拓者。
Q4. ”技能的反面“与提高技能的方法
- 问题出处:P57 -【Ch03 软件工程师的成长——技能的反面】
在这部分内容中,作者举了他小时候玩魔方的例子,意在说明绝大部分人口中的技能其实远远达不到真正意义上的技能的标准。而为了说明什么才是真正的技能,作者援引了比尔·塞克斯顿关于”技能的反面“的相关论述:塞克斯顿认为,技能的反面是【解决问题】;因此一个真正拥有某项技能的人在完成相应的任务时应当不再像一个生手一样把这一切还当作是一系列解决”新问题“的过程,而是能够超越低层次的问题,将主要的精力放在更高层次更抽象的思考上。
而关于如何提高技能,作者给出的答案是:不断地练习。原文如下:
那怎么提高技能呢?答案很简单,通过不断的练习,把那些低层次的问题都解决了,变成不用经过大脑的自动操作,然后才有时间和脑力来解决较高层次的问题。
对此我有不同的看法。首先,对于某一特定技能的熟练程度在很大程度上决定了劳动的生产效率,一名熟练工人单位时间内可以生产出更多的工件,从而创造更多的利润。但是否对于我们所尝试的每一件事都要达到如此熟练的程度,甚至连玩魔方这样的兴趣爱好都不放过呢?我认为大可不必。
因为,技能。或者说熟练度,其本质上其实是一个人在劳动中逐渐异化的过程。他越熟练于某一特定的工作,就越有可能囿于这项工作所设下的囹圄中。而反过来,解决问题,也就是技能的反面,所体现的才恰恰是一个人真正意义上的真实能力,是人之所以为人的证明。
以编程语言为例,现在市面上的编程语言多如牛毛,比较有名的就有C、python、java、C#、Rust、Go……而每一种语言都有它自己的语言特性,那么对于一个优秀软件工程师的衡量标准,难道是看他所精通的编程语言的多少吗?再比如,随着软件生态的日趋成熟,很多领域都已经有了一套成熟的软件体系和自己定义的各种API与函数接口,像在科学计算领域,就有Matlab,Mathmetica以及Python语言支持的scipy库等等,它们的很多函数虽功能类似,但名称、调用形式却千差万别,难道我们也需要对这里面的每一个API都烂熟于心吗?
如果真是这样的话,那还要机器干什么,都让人来做好了。
所以,我始终认为,衡量一个科班出身的CS人的能力究竟如何,不是看他会调多少包,而是看他能否举一反三、快速把握问题的关键和本质,至于具体的实现细节,还是交给文档的好。
当然,如果一个人连一门编程语言都不会就敢说自己是CS人,那就不在本文的讨论范围之内了。
Q5. goto到底该不该用?
- 问题出处:P69 -【Ch04 两人合作——代码设计规范】
这里作者在讨论什么是良好的程序设计规范时,认可了对goto语句的使用,原文如下:
函数最好有单一的出口,为了达到这一目的,可以使用goto。只要有助于程序逻辑的清晰体现,什么方法都可以使用,包括goto。
而荷兰计算机科学家Dijkstra在很久以前就提出了著名的"goto有害论",反对在程序中使用goto语句,这显然与本书作者的观点不合。对此,我本人也更倾向于Dijkstra的观点,即一旦允许使用goto,那么很有可能就会破坏程序原有的清晰逻辑结构,造成多出口的结果,这一过程往往是不可控的。因此,有必要在源头上断绝goto被使用的可能。
Q6. 商业价值与开源精神是否矛盾?
- 问题出处:P134 -【Ch07 实战中的软件工程——MSF基本原则】
这部分内容在书中主要以阿超、二柱等人的对话的形式加以展开。当涉及到团队项目在完成后是否应该开源这一问题时,二柱、阿超等人均在不同程度上表达了反对,因此也可以认为作者本人也更倾向于以“闭源”的形式对待商业软件。
但另一方面,我们也应该看到,如果没有当初Linus等人将最初的Linux系统以邮件的形式开源发布出来,那么也不会有今天整个Linux大家族的繁荣;同样,现在的GitHub社区也充分倡导开源精神,鼓励更多人把他们的idea分享出来;就连微软也在不久前公开了其Office家族的一部分代码接口,以允许其他文本编辑软件与之兼容;至于Google、Facebook开源的Tensorflow、Pytorch等深度学习框架就更是如此了。
现如今,开源已成为CS界的一种潮流,这与传统制造业可以说是大相径庭,但至于这种趋势究竟是否会促进IT公司商业价值的提升还是会在一定程度上影响其(特别是小公司)商业化产品的成功落地,现在也是众说纷纭。对此,我本人也没有一个明确的答案——但我相信,未来一定会出现一种基于开源的全新商业模式,从而可以兼顾对个体劳动贡献的肯定与对社区繁荣的维系。
Q7. “只先一步”最终一定会带来“颠覆式”创新吗?
- 问题出处:P357 -【Ch15 IT行业的创新——创新的时机】
在本书第16章的开始【创新的迷思】部分,作者提出了两种不同的创新方式(P342),分别是改良式(Incremental)创新与颠覆式(Disruptive)创新;紧接着,在【创新的时机】部分,作者又以黄金点游戏为例,试图说明最终真正能够成功的创新往往每次都是比大众的平均值先走了一小步,实现所谓的“相对优势”;而那些一开始最激进的创新却反而有可能归于失败。
对此我不敢苟同。应该看到,很多对人类文明产生重大影响的发明创造往往对人们的认知都是颠覆性的,远的有牛顿三定律直接打破了人们过去所认可的【力是维持物体运动状态的原因】这一错误观念,近的有乔布斯首创的iPhone系列手机彻底颠覆了人们过去对手机的功能定位。如果任何事都只追求一点一点的迭代式创新的话,那么整个人类文明的发展甚至很有可能会逐渐“收敛”,最终停滞不前。
Q8. PM与开发测试人员的关系和分工应当是怎样的?
- 问题出处:P185 -【Ch09 项目经理——PM做开发和测试之外的所有事情】
正如标题中所言,这部分内容中作者的基本观点就是【PM做开发和测试之外的所有事情】。那么问题来了,是不是开发和测试人员要做的事情PM就统统不用管了呢?他们具体都写了哪些代码,这些代码究竟能不能实现客户的需求,难道这些问题PM就不用去考虑了吗?而另一方面,开发和测试人员是不是也无需关心客户的需求了呢?假设客户后面又提出了更复杂的功能要求导致软件全部需要重构,那这个锅应该是PM背还是开发人员背呢?
因此,我认为,单纯地把PM的工作定义为【开发和测试的补集】是非常不合理的。一个合格的PM他在一个团队中所起到的作用更像是【粘合剂+方向标】,他既需要随时把握各个开发测试岗位的当前进度(这如果没有基本的技术功底的显然无法做到),同时也需要及时将客户的需求传达给团队的其他成员们,从而共同协商出下阶段合理的任务计划与分工进度安排。
Q9. “杀手” + “辅助” = “维持”?
- 问题出处:P165 -【Ch08 需求分析——功能的定位和优先级】
这里作者将产品的功能从实现和需求两个角度进行了划分,得到了如下图所示的功能象限图。

可以看到,对于【杀手功能+辅助需求】这样的组合,作者给出的建议是采取“维持”的办法进行实现,而对于【杀手+必要】这样的组合,作者则给出了“差异化”的建议。
对此我有所异议。在如今的互联网时代,整体上来看,多数公司与产品所采用的商业模式已经与传统制造业截然不同——传统制造业销售的是产品本身,而互联网公司们销售的则往往是产品周边与服务。比如Google公司的核心是搜索引擎算法,但它所采用的盈利方式则是靠广告投放:假如当时Google把全部重心都放在优化它的搜索引擎的性能上的话,那么缺少有效盈利手段的它有可能拥有如今的市场占有率吗?
再比如,现在非常火热的《王者荣耀》等一系列手游,它们的核心功能无疑是游戏的玩法本身,但很遗憾这部分功能通常是免费的,而真正收费的却是各种【皮肤】等看起来并无任何实际用处的外围功能:那这是否意味着游戏公司就只需要提供最基本的皮肤给玩家就够了呢?
因此,我认为在资金有限的前提下,一些必要需求,哪怕是杀手功能,反而只需要“维持”即可;而恰恰是一些看似不那么重要也不难实现的辅助需求,才是真正需要做到“差异化”的关键所在。
源代码版本管理软件调研
本部分将逐一对GitHub、Gitlab与Bitbucket这三个目前主流的用于源代码版本管理的软件进行简要介绍,最后再对它们之间的异同加以分析。
GitHub
GitHub 是首个供“用Git进行版本控制系统的软件开发项目”使用的基于Web的代码托管服务,是目前全球最大的开源社交编程及代码托管网站。GitHub 于 2008 年 4 月 10 日正式上线,除了基本的服务以外,还提供了订阅、讨论组、文本渲染、在线文件编辑器、协作图谱(报表)、代码片段分享(Gist)等功能。
Gitlab
GitLab 是一个利用 Ruby on Rails 开发的开源应用程序,实现一个自托管的 Git 项目仓库,可通过 Web 界面访问公开或者私人的项目。
Bitbucket
BitBucket 是 2008 年创建的源代码托管网站,采用 Mercurial 和 Git 作为分布式版本控制系统,同时提供免费账户和商业计划。2010 年被 Atlassian 收购,与 Atlassian 的其他服务(Git GUI SourceTree、HipChat、Cloud9)顺利集成,主要面向慈善企业和企业用户,其主要市场是大型企业。
团队协作流程
由于这三者均为基于Git的分布式版本管理系统,因此在团队协作流程上基本上也是大同小异。以GitHub为例,整体的协作流程大致可分为以下10个基本阶段:
- 在 Github 上创建 organization
- 邀请队友加入 organization 并创建 team
- 建立团队项目仓库,在设置中将 team 的权限设置为 read
- 创建开发分支,让队友 fork 到个人仓库
- clone 项目到本地
- 添加 REMOTE 关联到团队远程仓库
- 切换到 dev 分支
- 提交commit到自己的远程仓库
- 和团队远程保存同步
- push 到自己的远程仓库 & 请求 pull request 到团队远程
相同点分析
- 都是分布式版本管理系统,基于Git实现
- 目前都已支持私人的免费仓库,但通常存在容量和人数的限制
- 三者都支持CI\CD功能
- GitHub 和 GitLab 都是基于 web 的 Git 仓库
不同点分析
- Gitlab在GitHub的功能之外,还支持更多的优秀特性,比如权限设置。因此一般企业内部软件产品多使用Gitlab,而开源产品则一般放在GitHub上。
- Gitlab的“Snippet support”支持用户分享一个project的部分代码,而不是整个project。
- Gitlab的源码本身是开源的,而GitHub、Bitbucket虽然社区开源,但其本身却是闭源的。
- 在支持仓库类型上,除Git外,GitHub还支持SVN,HG,TFS,Bitbucket还支持CodePlex,Google Code,HG,SourceForge,SVN。
持续集成/部署工具调研
Gitlab CI
GitLab CI 是GitLab内置的进行持续集成的工具,只需要在仓库根目录下创建.gitlab-ci.yml文件,并配置GitLab Runner;每次提交的时候,GitLab将自动识别到.gitlab-ci.yml文件,并且使用GitLab Runner执行该脚本。
本部分采用大二下OO课程的Unit3_task2作业作为样例,引入Maven框架,展示GitLab CI/CD的基本过程。
项目根目录
.png)
Pipeline 运行记录
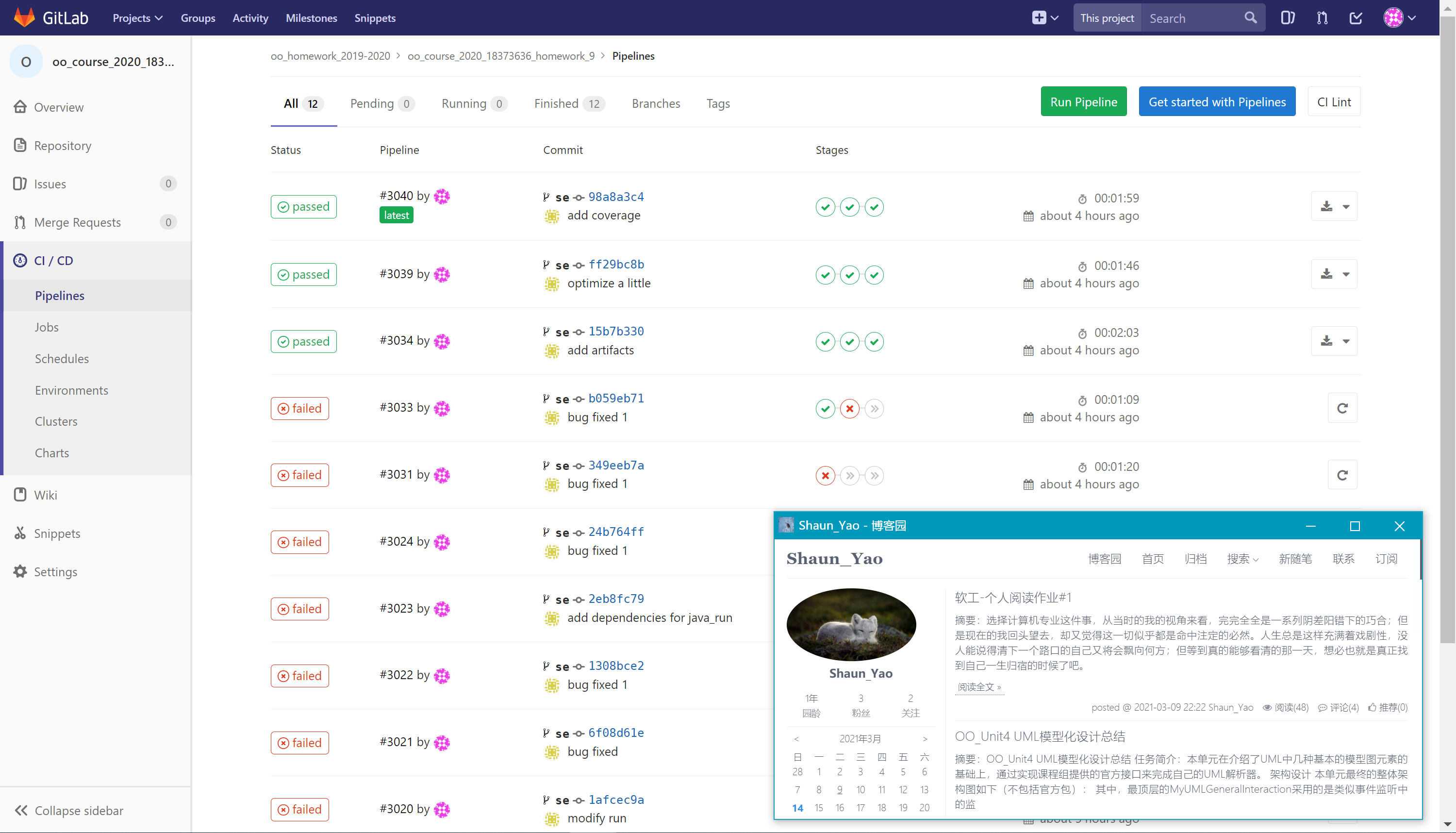
ci各阶段详细执行流程
本部分将结合.gitlab-ci.yml中的相关代码予以说明,其中Maven相关的配置可参考仓库中的pom.xml文件。
-
所选镜像
image: local-registry.inner.buaaoo.top/image-dev/java:8u201 -
宏定义变量
variables: USER_INFO: tcyhost -
before_script
before_script是用于定义一些在所有任务执行前所需执行的命令, 包括部署工作,可以接受一个数组或者多行字符串。
before_script: - java -version - javac -version - mvn -v -
各阶段定义
阶段是对批量的作业的一个逻辑上的划分,每个 GitLab CI/CD 都必须包含至少一个 Stage。多个 Stage 是按照顺序执行的(但同一个stage的多个jobs则会并发执行),如果其中任何一个 Stage 失败,则后续的 Stage 不会被执行,整个 CI 过程被认为失败。
stages: - build - run - test-
build
build阶段的核心为
mvn compile命令,对项目进行编译,并打印编译成功后的目录结构。mvn_build: stage: build script: - echo "[${USER_INFO}] Build Project" - mvn compile - tree -I .git artifacts: paths: - target/注意这里利用
artifacts字段将mvn编译得到的结果传递给接下来的jobs,从而使后续任务无需重新进行编译。运行结果如下:
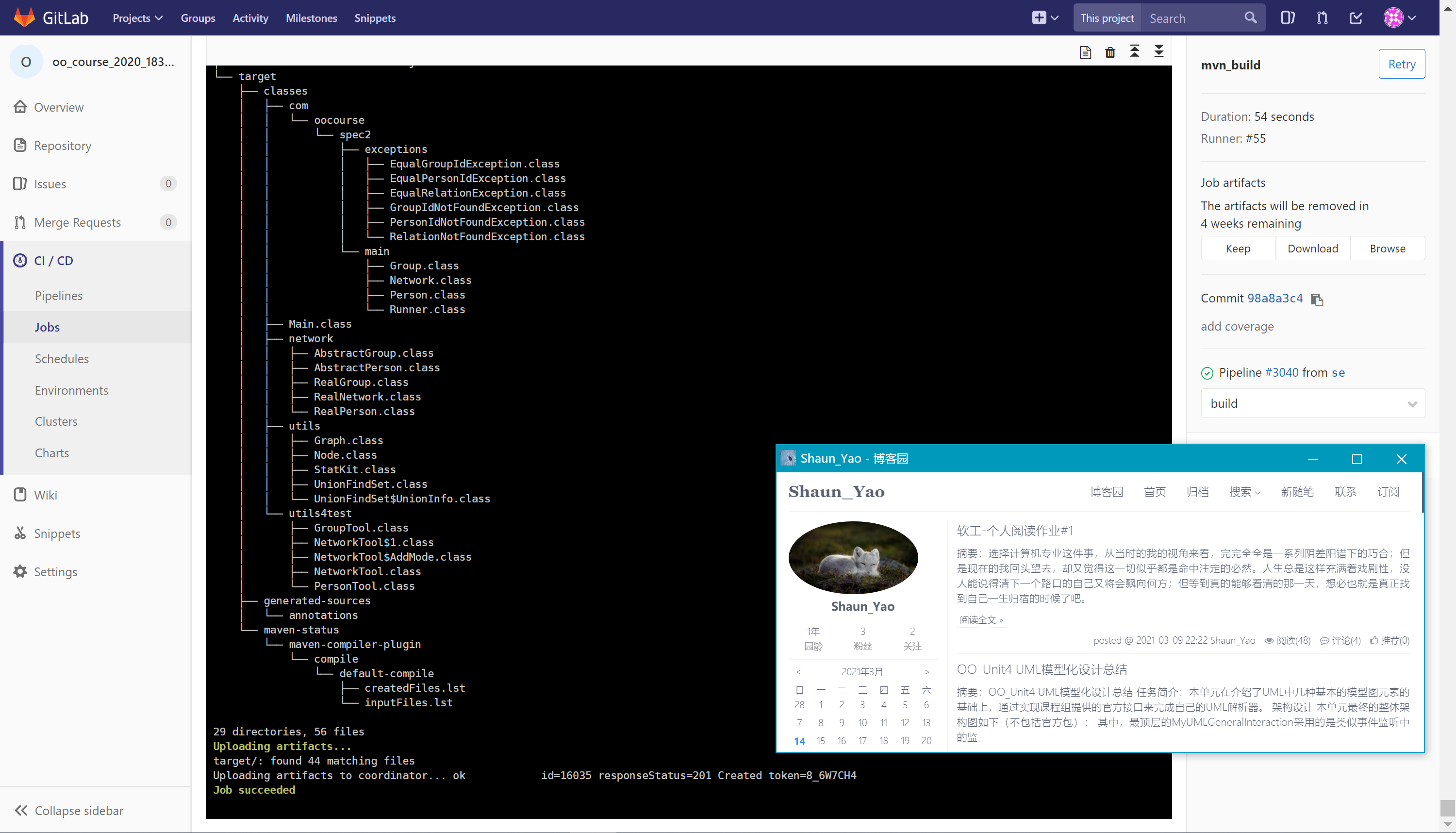
-
run
run阶段主要任务为执行一个简单的测试样例,从而初步判断项目的正确性。
java_run: stage: run dependencies: - mvn_build script: - echo "[${USER_INFO}] Running" - cd target/classes - java Main < ../../src/test/in0.txt only: - se注意这里通过添加
only字段,限制该job只能在se分支发生变动时运行,master或其他分支出现变化时,该job不会被执行。运行结果如下:
.png)
-
test
test阶段主要任务为对原始项目进行Junit单元测试,并计算测试的覆盖率。
mvn_test: stage: test dependencies: - mvn_build script: - echo "[${USER_INFO}] Test JUnit4" - mvn cobertura:cobertura - mvn cobertura:dump-datafile coverage: '/coverage line-rate="\d+/'注意由于这里是利用
cobertura接口实现Junit测试,因此在正则匹配时应关注line-rate的结果。运行结果如下:
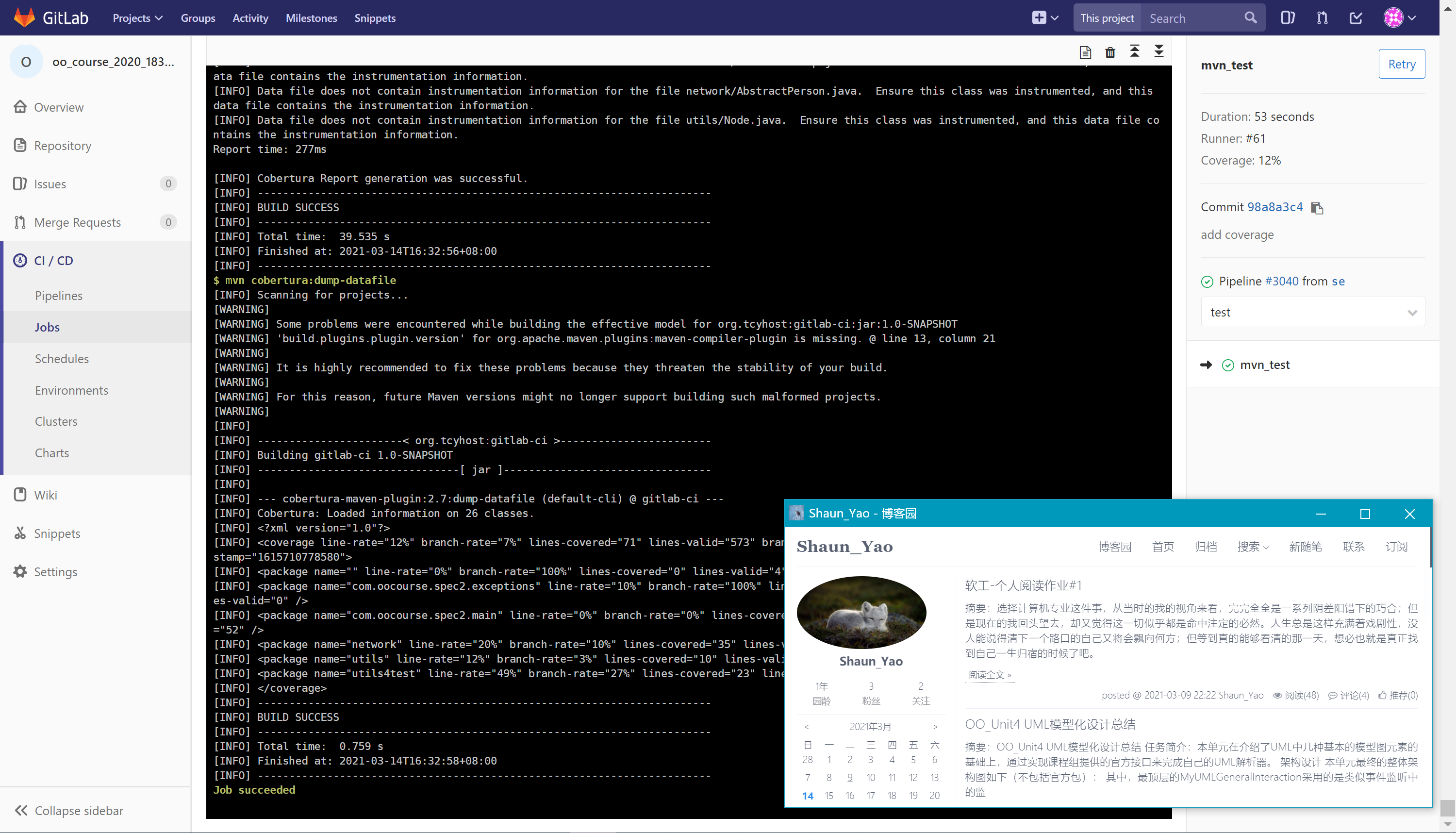
-
GitHub Actions
GitHub Actions与GitLab CI在功能上类似,都是用于对代码进行持续集成操作;但GitHub Actions将这些操作进行了解耦合,从而允许开发者把每个操作写成独立的脚本文件存放到代码仓库中,使得其他开发者也可以引用。因此,如果你需要某个 action,就不必再自己写复杂的脚本,而是直接引用他人写好的 action 即可。整个持续集成过程,也就变成了各种actions的组合。
本部分以一个简单的基于Python实现的M/M/n队列模拟器程序为例,利用pytest和flake8等包,展示GitHub Actions的基本过程。
项目根目录
.png)
Workflows 运行记录
- 所有workflows的执行情况
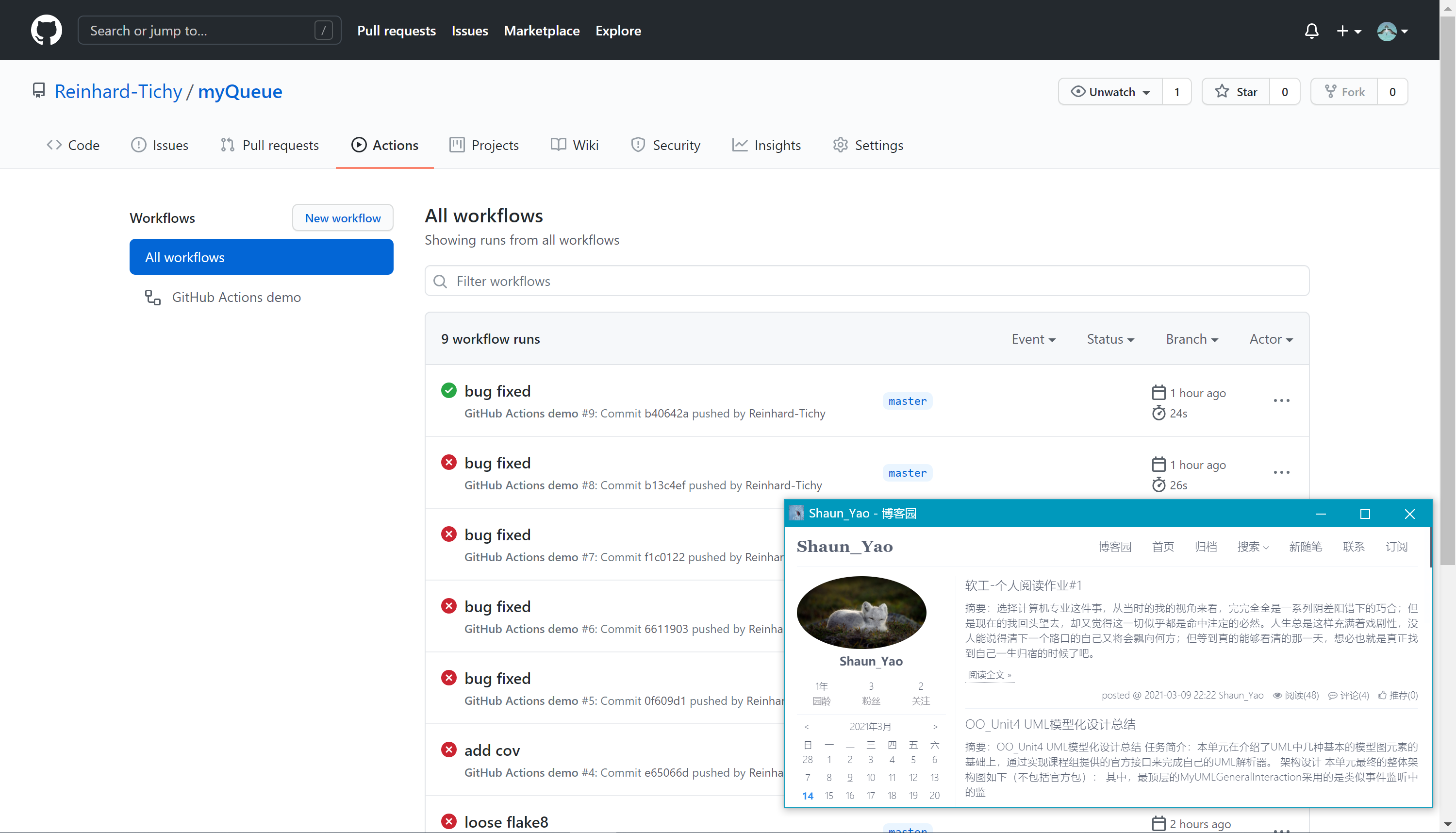
- 某一特定workflows中各个job的执行情况
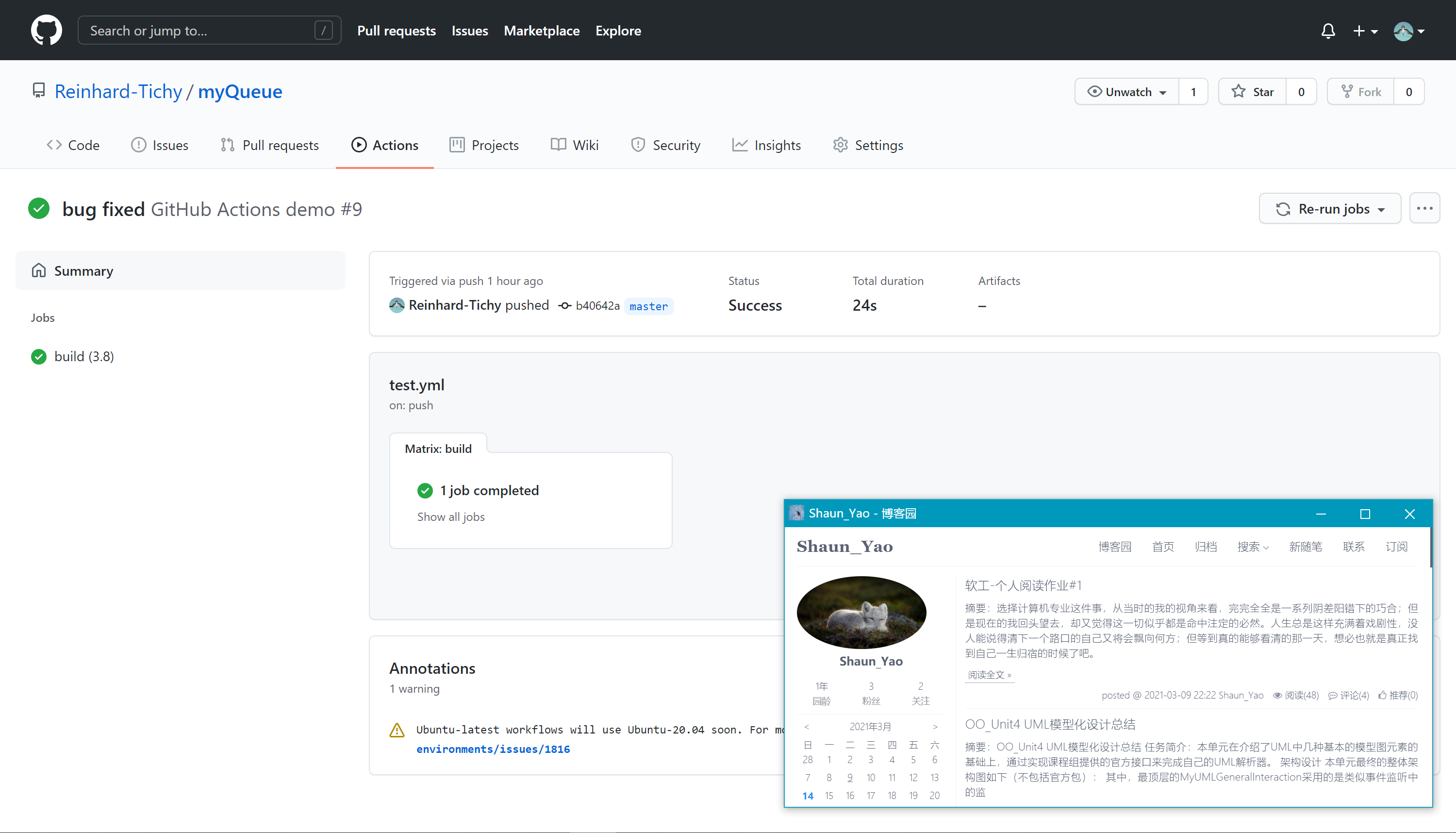
- jobs中各个action的执行情况
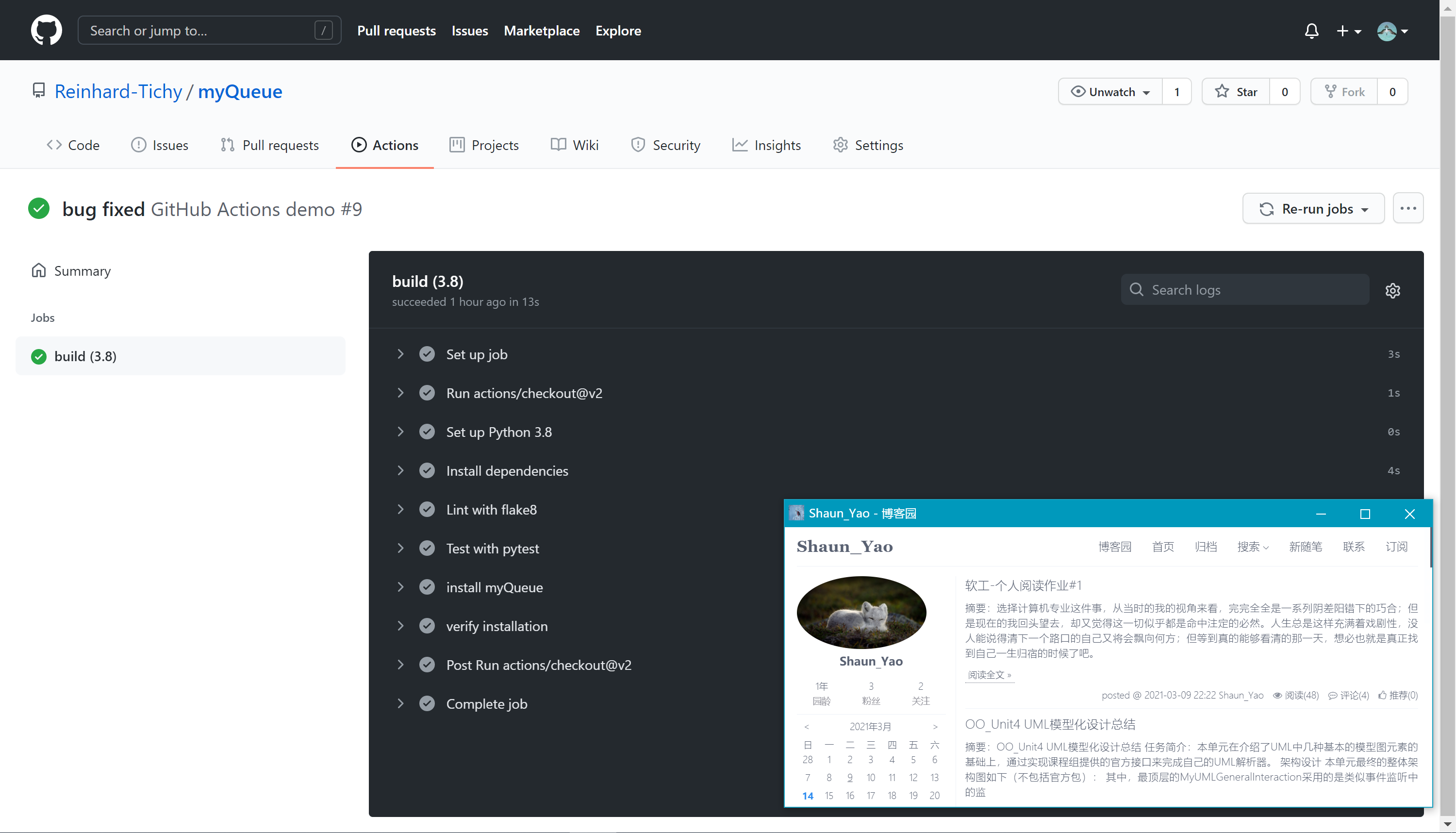
Actions各阶段详细执行流程
本部分将结合.github/workflows/test.yml中的相关代码予以说明。
-
基本配置与环境初始化
name: GitHub Actions demo on: - push - pull_request jobs: build: runs-on: ubuntu-latest strategy: matrix: python-version: - '3.8' steps: - uses: actions/checkout@v2 - name: Set up Python ${{ matrix.python-version }} uses: actions/setup-python@v2 with: python-version: ${{ matrix.python-version }}运行结果如下:
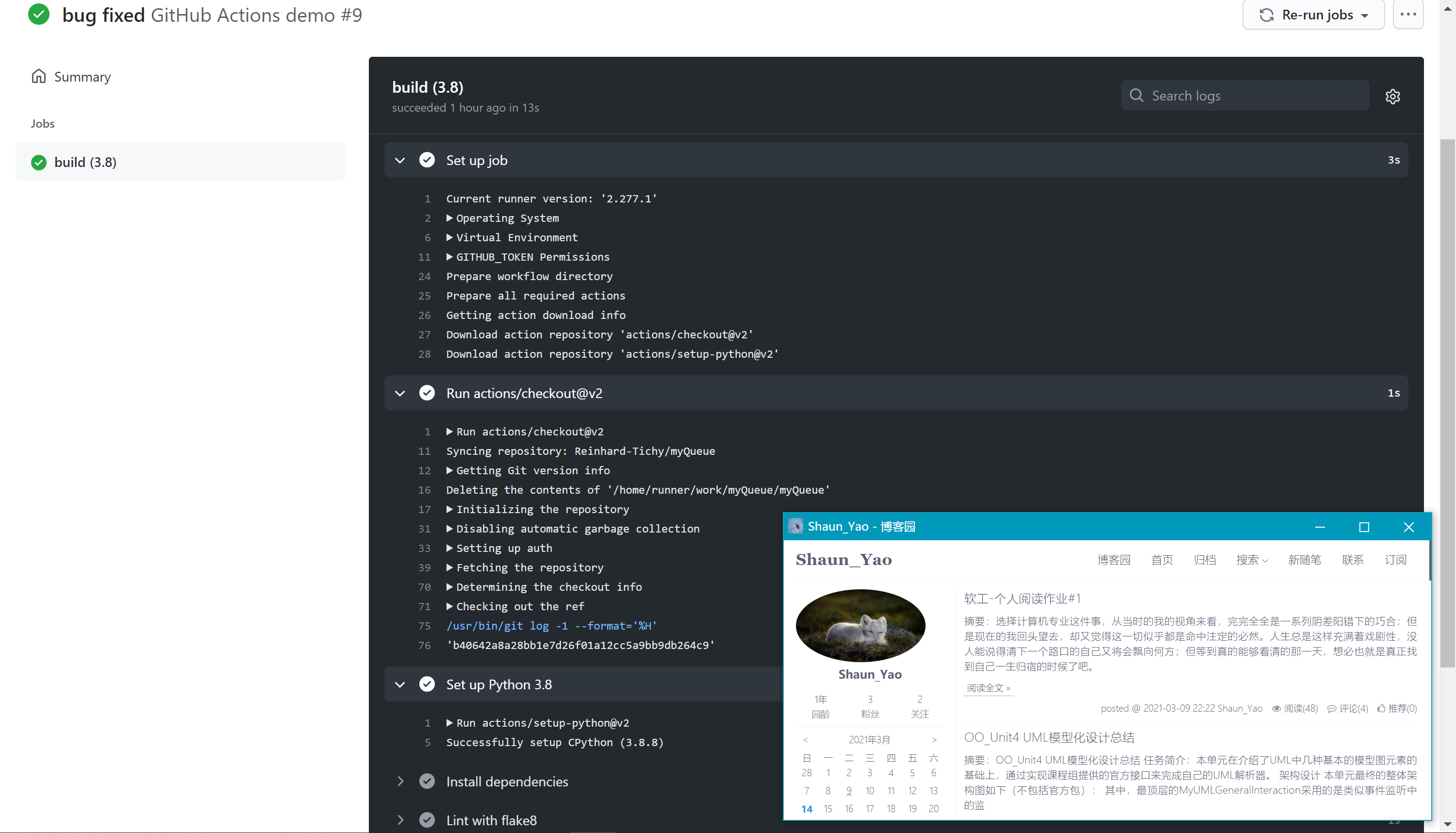
-
安装依赖包
- name: Install dependencies run: | python -m pip install --upgrade pip pip install flake8 pytest pytest-cov if [ -f requirements.txt ]; then pip install -r requirements.txt; fi运行结果如下:

-
flake8静态语法测试
- name: Lint with flake8 run: | # stop the build if there are Python syntax errors or undefined names flake8 --count --ignore F403,F405,W504,E226 --max-line-length=127 myQueue/ --statistics运行结果如下:
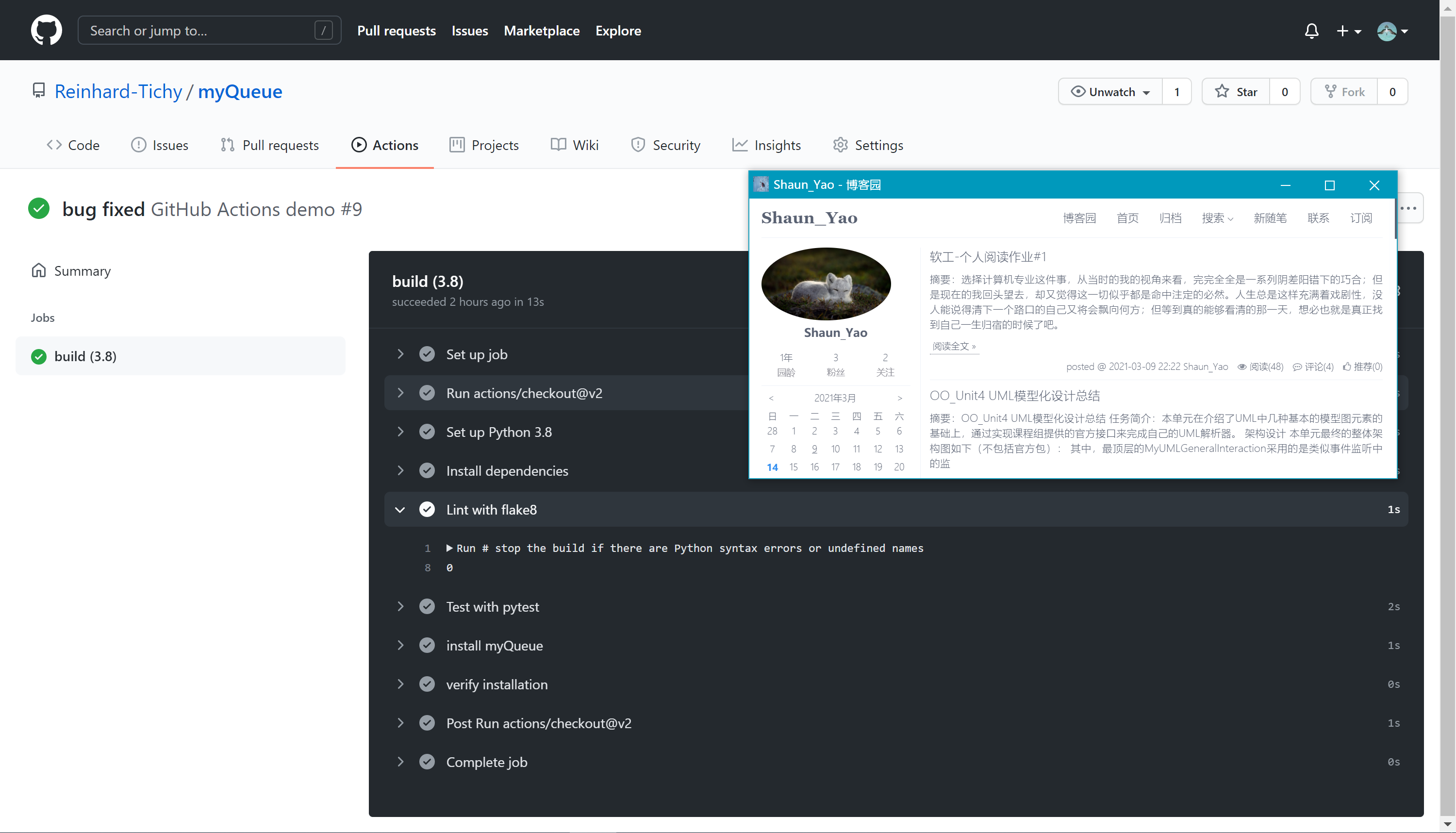
-
pytest单元测试
- name: Test with pytest run: | tree -I .git pip install -e . pytest ./test --cov-report term-missing --cov=./myQueue/ -sv运行结果如下:
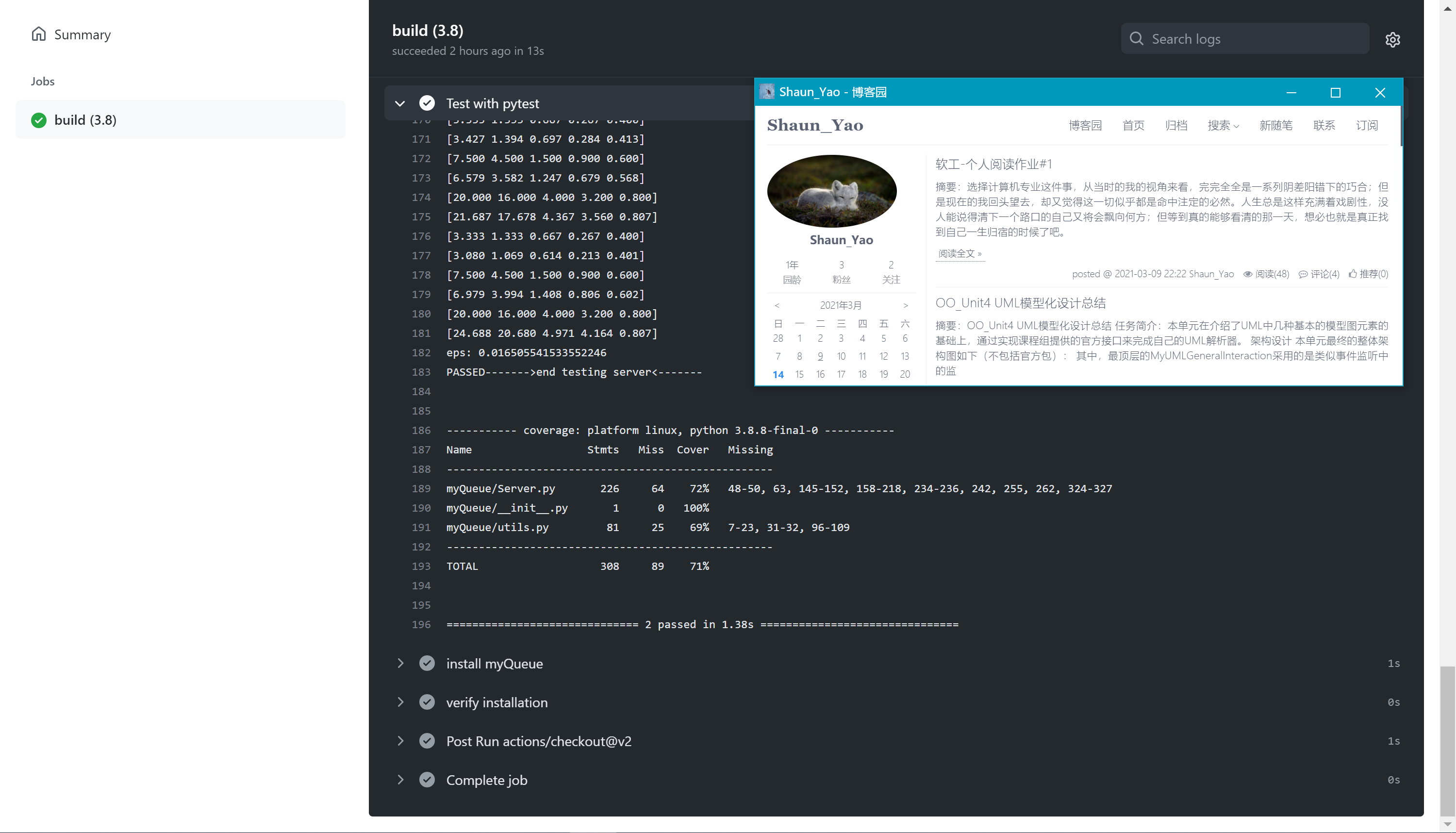
-
安装部署包并验证是否安装成功
- name: install myQueue run: | pip install -e . - name: verify installation run: | python -c "import myQueue; print(myQueue.__version__)"运行结果如下:
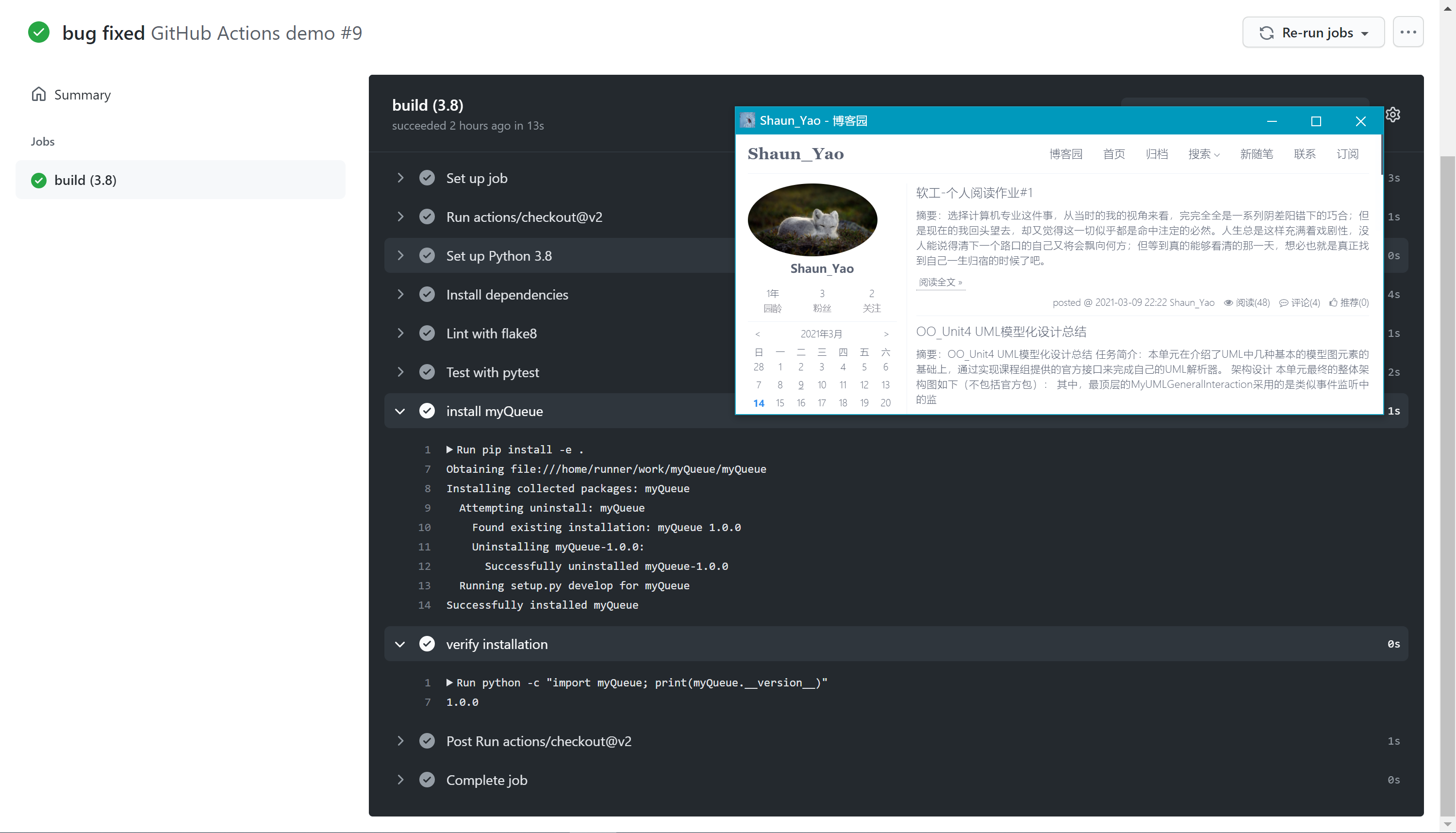
CI/CD工具使用小结
在充分调研并实践后,我认为无论是Gitlab CI还是GitHub Actions,其背后的核心宗旨无外乎两点:自动化与标准化。
首先是自动化。我们知道,CI/CD工具关注的对象并非是代码的创造过程本身,而是代码在编写出来后对其进行编译、测试、提交、部署的这一系列过程。不难发现,这些过程其实都是非常机械的,不仅不需要什么创造力,而且过于繁琐的环境配置过程反而还会耗费开发者大量的精力,造成团队整体的生产效率低下。因此,将这一部分内容从代码开发中分离出来,并在服务器上自动加以实现,无疑是诸多软件开发团队的普遍需求,也是一类工具的核心使命。
其次是标准化。既然希望将这部分内容交由机器去完成,那么一方面,为了让机器的执行流程更加高效清晰,另一方面也是为了进一步减轻开发者的编程负担,标准化就显得至关重要了。
这里的标准化有三层含义,首先是执行流程的标准化。无论是Gitlab CI还是Github Actions,都利用YAML文件将整个持续集成过程分成了多个阶段,各阶段之间相互独立、顺序执行,从而使得执行流程清晰简明;其次是执行指令的标准化,这一点GitHub Actons做的明显要更好些——它将原本一条条原子化的指令进行了进一步封装,构成了一个个action,从而允许开发者彼此之间进行调用,进一步降低了编程负担;最后是执行环境的标准化,比如Gitlab中的Runner,通过在团队之间进行共享,就可以实现统一的运行环境,从而便于最后的集成和部署。
若从需求分析、技术支持与产品实现的角度进行归纳的话,那么CI/CD工具的核心特性可整理如下:
需求分析:许多软件开发团队为了使集成开发的环境、流程做到统一、规范,个人开发者希望实现测试、部署等过程的自动化
技术支持:Docker等虚拟环境技术的成熟,基于web的分布式版本管理技术的推广,yaml工具的出现等
产品实现:GitLab CI/CD、GitHub Actions、Travis……
GitLab CI与GitHub Actions的系统化优劣对比如下表所示:
 |
 |
|
|---|---|---|
| YES | 支持非第三方的嵌入式CD | NO |
| YES | 自托管 | NO |
| YES | 有自己的生态系统(https://about.gitlab.com/partners/) | NO |
| NO | 有自己的市场平台 | YES |
| YES | CI/CD 充分集成 - 无需第三方插件或工具 | NO |
| YES | 内置Kubernetes部署和监控管理 | NO |
| YES | 自动CI/CD Pipeline配置 | NO |
| YES | 嵌入式CI-CD安全审查 - 无需第三方插件或工具 | NO |
| YES | 安全仪表板(Dashboard)可实现安全团队协作 | NO |
| YES | 容器注册表集成在CI-CD Pipeline中 - 无需第三方插件或工具 | NO |
当然,应该要认识到很多问题是有两面性的。比如究竟是否应该支持第三方插件这件事,支持的话有助于提升市场开放性和灵活性,但也会出现鱼龙混杂的情况;不支持的话有助于进行统一的管理和优化,但可能缺少足够的个性化服务。
总之,从我个人的角度来看,我会更倾向于使用GitLab CI进行团队项目的集成开发,使用GitHub Actions进行个人开源项目的测试部署。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号