prometheus operator介绍
prometheus
operator介绍
- 引出operator
从本质上来讲Prometheus属于是典型的有状态应用,而其有包含了一些自身特有的运维管理和配置管理方式。
而这些都无法通过Kubernetes原生提供的应用管理概念实现自动化。为了简化这类应用程序的管理复杂度,CoreOS率先引入了Operator的概念,
并且首先推出了针对在Kubernetes下运行和管理Etcd的Etcd Operator。并随后推出了Prometheus Operator。Operator基于kubernetes的资源和控制器概念上构建,
但同时又包含了应用程序特定的领域知识。创建Operator的关键是CRD(自定义资源)的设计
- operator介绍
Prometheus Operator为监控Kubernetes Service、Deployment和Prometheus实例的管理提供了简单的定义,
简化在Kubernetes上部署、管理和运行Prometheus和Alertmanager集群。Prometheus Operator作为一个控制器,他会去创建Prometheus、PodMonitor、ServiceMonitor、AlertManager以及PrometheusRule这些个CRD资源对象,
然后会一直监控并维持这几个资源对象的状态。Prometheus Operator负责监听这些自定义资源的变化,并且根据这些资源的定义自动化的完成如Prometheus Server自身以及配置的自动化管理工作。
CRD资源对象说明:
Prometheus:作为Prometheus Service存在
ServiceMonitor:提供metrics数据接口的exporter的抽象,Prometheus就是通过ServiceMonitor提供的metrics数据接口去pull数据的
AlertManager:对应alertManager组件,实现告警
PrometheusRule:告警规则定义
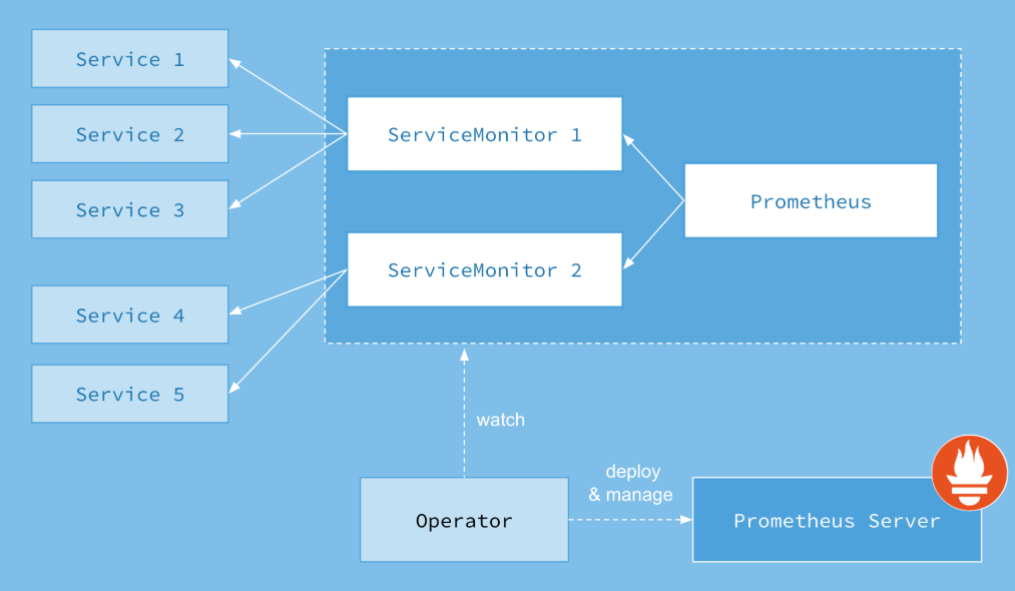
架构中的各组成部分以不同的资源方式运行在Kubernetes集群中,它们各自有不同的作用。
- Operator:Operator资源会根据自定义资源(Custom Resource Definition,CRD)来部署和管理Prometheus Server,
同时监控这些自定义资源事件的变化来做相应的处理,是整个系统的控制中心。- Prometheus: Prometheus资源是声明性地描述Prometheus部署的期望状态。
- Prometheus Server: Operator根据自定义资源Prometheus类型中定义的内容而部署的Prometheus Server集群,
这些自定义资源可以看作用来管理Prometheus Server 集群的StatefulSets资源。- ServiceMonitor:ServiceMonitor也是一个自定义资源,它描述了一组被Prometheus监控的target列表。该资源通过标签来选取对应的Service Endpoint,
让Prometheus Server通过选取的Service来获取Metrics信息。- Service:Service资源主要用来对应Kubernetes集群中的Metrics Server Pod,提供给ServiceMonitor选取,让Prometheus Server来获取信息。
简单说就是Prometheus监控的对象,例如Node Exporter Service、Mysql Exporter Service等。- Alertmanager:Alertmanager也是一个自定义资源类型,由Operator根据资源描述内容来部署Alertmanager集群。
operator持久化配置
prometheus crd资源对象文件 & grafana持久化配置,默认在使用operator中存储方式为empty
修改仅针对prometheus和grafana
# prometheus 持久化
storage:
volumeClaimTemplate:
spec:
storageClassName: prometheus-pv
resources:
requests:
storage: 50Gi
# grafana 持久化
volumeMounts:
- mountPath: /var/lib/grafana
name: grafana-storage
volumes:
- name: grafana-storage
persistentVolumeClaim:
claimName: grafana-pvc
静态配置
在Prometheus Operator中是通过声明式的创建如Prometheus,ServiceMonitor这些自定义的资源类型来自动化部署和管理Prometheus的相关组件以及配置。
而在一些特殊的情况下,可能还是希望能够手动管理Prometheus配置文件,而非通过Prometheus Operator自动完成。以下为静态配置的实现方式:
# 1. 创建文件作为secret
kubectl create secret generic additional-configs --from-file=prometheus-additional.yaml -n monitoring
# 2. 如黑盒监控
- job_name: 'blackbox'
metrics_path: /probe
params:
module: [http_2xx]
static_configs:
- targets:
- http://www.google.com
- https://www.baidu.com
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: blackbox-exporter:19115
# 3. prometheus crd资源对象新增
additionalScrapeConfigs:
key: prometheus-additional.yaml
name: additional-configs
optional: true
# 4. 配置的修改只需replace文件,无需对prometheus pod重启,prometheus也能抓取到改配置。
监控流程
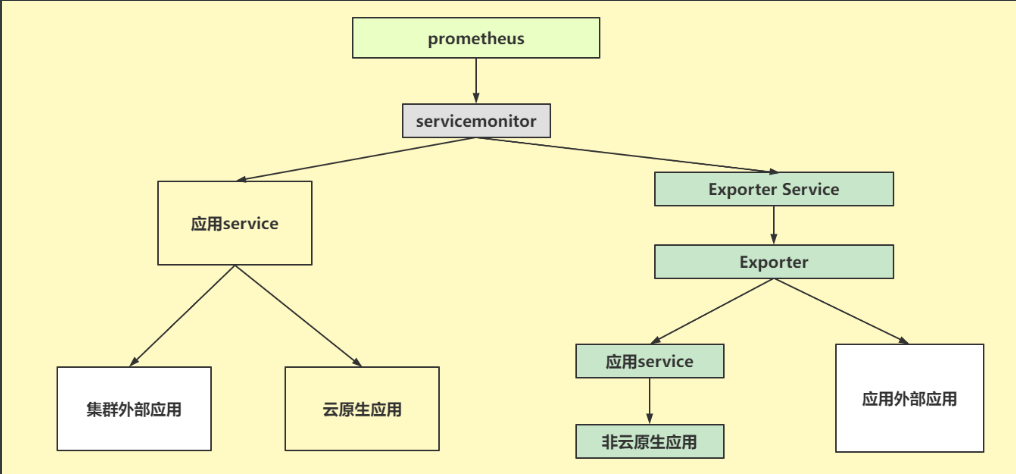
ServiceMonitor也是一种资源类型,使用prometheus向servicemonitor抓取监控项,通过servicemonitor抓取监控目标,
servicemonitor里面包含了node-expoter和blockbox等监控。servicemonitor监控是针对operator安装形式才具备的。云原生监控:
云原生监控指apiserver,etcd等这种k8s中的组件监控,已经暴露了metrics接口,可以通过ServiceMonitor直接绑定svc,从而实现自动被prometheus监控。
非云原生监控:
非云原生监控指,并非k8s组件监控,比如像mysql,es等,自身没有暴露监控指标,需要在mysql的基础上部署mysql-exporte,有了exporter,
相应的 非云原生应用的指标也就暴露出来,可以通过ServiceMonitor进行绑定,从而被prometheus实现监控。grafana的模板也可以通过grafana官网进行获取,
从而导入,但需要注意导入的模板与exporter抓取监控项是否匹配。
配置介绍
配置介绍围绕监控体系流程展开,以宿主机节点监控为例,实现非云原生如何从metrics到被prometheus抓取,包括告警规则以及告警通知的配置。
- 1. 宿主机metrics采集
# daemonset的形式部署nodeexport作为节点指标采集器
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: node-exporter
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 1.1.2
name: node-exporter
namespace: monitoring
spec:
selector:
matchLabels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: node-exporter
app.kubernetes.io/part-of: kube-prometheus
template:
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: node-exporter
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 1.1.2
spec:
containers:
- args:
- --web.listen-address=127.0.0.1:9100
- --path.sysfs=/host/sys
- --path.rootfs=/host/root
- --no-collector.wifi
- --no-collector.hwmon
- --collector.filesystem.ignored-mount-points=^/(dev|proc|sys|var/lib/docker/.+|var/lib/kubelet/pods/.+)($|/)
- --collector.netclass.ignored-devices=^(veth.*)$
- --collector.netdev.device-exclude=^(veth.*)$
image: quay.io/prometheus/node-exporter:v1.1.2
name: node-exporter
resources:
limits:
cpu: 250m
memory: 180Mi
requests:
cpu: 102m
memory: 180Mi
volumeMounts:
- mountPath: /host/sys
mountPropagation: HostToContainer
name: sys
readOnly: true
- mountPath: /host/root
mountPropagation: HostToContainer
name: root
readOnly: true
- args:
- --logtostderr
- --secure-listen-address=[$(IP)]:9100
- --tls-cipher-suites=TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384,TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384,TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305,TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305
- --upstream=http://127.0.0.1:9100/
env:
- name: IP
valueFrom:
fieldRef:
fieldPath: status.podIP
image: quay.io/brancz/kube-rbac-proxy:v0.8.0
name: kube-rbac-proxy
ports:
- containerPort: 9100
hostPort: 9100
name: https
resources:
limits:
cpu: 20m
memory: 40Mi
requests:
cpu: 10m
memory: 20Mi
securityContext:
runAsGroup: 65532
runAsNonRoot: true
runAsUser: 65532
hostNetwork: true
hostPID: true
nodeSelector:
kubernetes.io/os: linux
securityContext:
runAsNonRoot: true
runAsUser: 65534
serviceAccountName: node-exporter
tolerations:
- operator: Exists
volumes:
- hostPath:
path: /sys
name: sys
- hostPath:
path: /
name: root
updateStrategy:
rollingUpdate:
maxUnavailable: 10%
type: RollingUpdate
- 2. metrics SVC暴露
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: node-exporter
app.kubernetes.io/part-of: kube-prometheus
name: node-exporter
namespace: monitoring
spec:
clusterIP: None
ports:
- name: https
port: 9100
targetPort: https
selector:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: node-exporter
app.kubernetes.io/part-of: kube-prometheus
- 3. ServiceMonitor标签选择绑定metrics svc
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: node-exporter
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 1.1.2
name: node-exporter
namespace: monitoring
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 15s
port: https
relabelings:
- action: replace
regex: (.*)
replacement: $1
sourceLabels:
- __meta_kubernetes_pod_node_name
targetLabel: instance
scheme: https
tlsConfig:
insecureSkipVerify: true
jobLabel: app.kubernetes.io/name
selector:
matchLabels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: node-exporter
app.kubernetes.io/part-of: kube-prometheus
- 4. prometheus对ServiceMonitor绑定
在prometheus crd资源对象文件中,定义ServiceMonitorSelect,所有创建的ServiceMonitor都能被prometheus进行抓取。
serviceMonitorSelector: {}
- 5.定义告警规则
和ServiceMonitor类似,在prometheus中配置ruleSelect,可以编写CRD为prometheusrule,从而被prometheus进行抓取
# prometheus配置ruleSelect,凡是CRD资源对象为prometheusrule,并且标签和ruleSelect中匹配一致,则达到目标被prometheus抓取的效果
ruleSelector:
matchLabels:
prometheus: k8s
role: alert-rules
prometheusRule 告警规则在operator中和传统prometheus中相差不大,但告警规则需要在prometheusRule中进行配置。
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-prometheus
app.kubernetes.io/part-of: kube-prometheus
prometheus: k8s
role: alert-rules
name: kube-prometheus-rules
namespace: monitoring
spec:
groups:
- name: general.rules
rules:
- alert: TargetDown
annotations:
description: '{{ printf "%.4g" $value }}% of the {{ $labels.job }}/{{ $labels.service }} targets in {{ $labels.namespace }} namespace are down.'
runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/targetdown
summary: One or more targets are unreachable.
expr: 100 * (count(up == 0) BY (job, namespace, service) / count(up) BY (job, namespace, service)) > 10
for: 10m
labels:
severity: warning
- alert: Watchdog
annotations:
description: |
This is an alert meant to ensure that the entire alerting pipeline is functional.
This alert is always firing, therefore it should always be firing in Alertmanager
and always fire against a receiver. There are integrations with various notification
mechanisms that send a notification when this alert is not firing. For example the
"DeadMansSnitch" integration in PagerDuty.
runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/watchdog
summary: An alert that should always be firing to certify that Alertmanager is working properly.
expr: vector(1)
labels:
severity: none
- name: node-network
rules:
- alert: NodeNetworkInterfaceFlapping
annotations:
message: Network interface "{{ $labels.device }}" changing it's up status often on node-exporter {{ $labels.namespace }}/{{ $labels.pod }}
runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/nodenetworkinterfaceflapping
expr: |
changes(node_network_up{job="node-exporter",device!~"veth.+"}[2m]) > 2
for: 2m
labels:
severity: warning
- 6.触发告警
当prometheusRule中的告警规则达到promql语句的触发条件,将告警通知相关人员。
prometheusRule同样使用标签作为触发条件通知到altermanager中,altermanager以自定义的告警通知形式发送告警信息。
在altermanager中不仅可以定义不同告警媒介,还可针对告警发送模板进行编排,也可区分告警等级,按紧急度分别发送至不同人员。
apiVersion: v1
kind: Secret
metadata:
labels:
alertmanager: main
app.kubernetes.io/component: alert-router
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.21.0
name: alertmanager-main
namespace: monitoring
stringData:
alertmanager.yaml: |-
"global":
"resolve_timeout": "5m"
wechat_api_url: 'https://abc.weixin.qq.com/cgi-bin/'
wechat_api_secret: 'JJ'
wechat_api_corp_id: 'ww'
"inhibit_rules":
- "equal":
- "namespace"
- "alertname"
"source_match":
"severity": "critical"
"target_match_re":
"severity": "warning|info"
- "equal":
- "namespace"
- "alertname"
"source_match":
"severity": "warning"
"target_match_re":
"severity": "info"
"receivers":
- "name": "Default"
- "name": "Watchdog"
- "name": "wechat"
wechat_configs:
- send_resolved: true
corp_id: 'aa'
api_secret: 'bb'
to_tag: '2'
agent_id: '1000777'
api_url: 'https://abc.weixin.qq.com/cgi-bin/'
message: '{{ template "wechat.default.message" . }}'
"route":
"group_by":
- "namespace"
"group_interval": "5m"
"group_wait": "30s"
"receiver": "Default"
"repeat_interval": "12h"
"routes":
- "match":
"alertname": "Watchdog"
"receiver": "Watchdog"
- "match":
"severity": "warning"
"receiver": "wechat"
type: Opaque
告警规则
- alert:告警策略的名称
- annotations:告警注释信息,一般写为告警信息
- expr:告警表达式
- for:评估等待时间,告警持续多久才会发送告警数据
- labels:告警的标签,用于告警的路由
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.26.0
prometheus: k8s
role: alert-rules
name: prometheus-k8s-prometheus-rules
namespace: monitoring
spec:
groups:
- name: prometheus
rules:
- alert: PrometheusBadConfig
annotations:
description: Prometheus {{$labels.namespace}}/{{$labels.pod}} has failed to reload its configuration.
runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/prometheusbadconfig
summary: Failed Prometheus configuration reload.
expr: |
max_over_time(prometheus_config_last_reload_successful{job="prometheus-k8s",namespace="monitoring"}[5m]) == 0
for: 10m
labels:
severity: critical
告警通知
# global块配置下的配置选项在本配置文件内的所有配置项下可见
global:
resolve_timeout: 1h
# 邮件告警配置
smtp_smarthost: 'smtp.exmail.qq.com:25'
smtp_from: 'dd@xxx.com'
smtp_auth_username: 'dd@xxx.com'
smtp_auth_password: 'ddxxx'
# HipChat告警配置
wechat_api_url: 'https://abc.weixin.qq.com/cgi-bin/'
wechat_api_secret: 'JJ'
wechat_api_corp_id: 'ww'
# 告警通知模板
templates:
- '/etc/alertmanager/config/*.tmpl'
# route: 根路由,该模块用于该根路由下的节点及子路由routes的定义. 子树节点如果不对相关配置进行配置,
则默认会从父路由树继承该配置选项。每一条告警都要进入route,即要求配置选项group_by的值能够匹配到每一条告警的至少一个labelkey
(即通过POST请求向altermanager服务接口所发送告警的labels项所携带的<labelname>),告警进入到route后,将会根据子路由routes节点中的
配置项match_re或者match来确定能进入该子路由节点的告警(由在match_re或者match下配置的labelkey: labelvalue是否为告警labels的子集决定,
是的话则会进入该子路由节点,否则不能接收进入该子路由节点).
route:
# 例如所有labelkey:labelvalue含cluster=A及altertname=LatencyHigh labelkey的告警都会被归入单一组中
group_by: ['job', 'altername', 'cluster', 'service','severity']
# 若一组新的告警产生,则会等group_wait后再发送通知,该功能主要用于当告警在很短时间内接连产生时,在group_wait内合并为单一的告警后再发送
group_wait: 30s
# 再次告警时间间隔
group_interval: 5m
# 如果一条告警通知已成功发送,且在间隔repeat_interval后,该告警仍然未被设置为resolved,则会再次发送该告警通知
repeat_interval: 12h
# 默认告警通知接收者,凡未被匹配进入各子路由节点的告警均被发送到此接收者
receiver: 'wechat'
# 上述route的配置会被传递给子路由节点,子路由节点进行重新配置才会被覆盖
# 子路由树
routes:
# 该配置选项使用正则表达式来匹配告警的labels,以确定能否进入该子路由树
# match_re和match均用于匹配labelkey为service,labelvalue分别为指定值的告警,被匹配到的告警会将通知发送到对应的receiver
- match_re:
service: ^(foo1|foo2|baz)$
receiver: 'wechat'
routes:
- match:
severity: critical
receiver: 'wechat'
- match:
service: database
receiver: 'wechat'
- match:
severity: critical
receiver: 'wechat'
# 抑制规则,当出现critical告警时 忽略warning
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
# 收件人配置
receivers:
- name: 'team-ops-mails'
email_configs:
- to: 'qqq@xxx.com'
- name: 'wechat'
wechat_configs:
- send_resolved: true
corp_id: 'aa'
api_secret: 'bb'
to_tag: '2'
agent_id: '1000777'
api_url: 'https://abc.weixin.qq.com/cgi-bin/'
message: '{{ template "wechat.default.message" . }}'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号