学习笔记 后缀数组
【写在之前】
其实听说过这个东西 据说很牛B
但这其实是一个蒟蒻无力的挣扎
【正式开始】
后缀排序 求SA
这里只介绍倍增算法
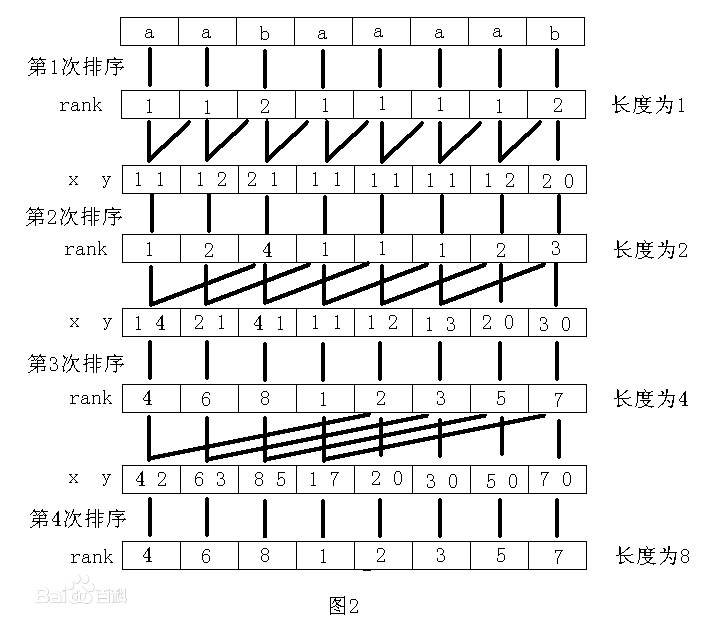
\(SA[i]\) 表示排名为\(i\)的后缀的开头位置
\(rnk[i]\) 表示第\(i\)个位置的后缀的排名
其实二者互补
\(SA[\ rnk[i]\ ]=i\)
\(rnk[\ SA[i]\ ]=i\)
\(cdy[i]\) 表示第一关键字 也就是\(rnk\)
然后是\(wzy[i]\) 表示第二关键字对应的\(SA[i]\)
然后就是\(vis[i]\) 表示一个权值桶
TA的原理:
1.倍增的是比较跨度
2.使用二元数组进行比较机理 基数排序
然后就是这样
我们先上代码 (其实就这里不明白)
#include<iostream>
#include<cstdio>
#include<cstring>
#include<cmath>
#include<algorithm>
#include<cstdlib>
#include<string>
#include<queue>
#include<map>
#include<stack>
#include<list>
#include<set>
#include<deque>
#include<vector>
#include<ctime>
#define ll long long
#define inf 0x7fffffff
#define N 500008
#define IL inline
#define M 1008611
#define D double
#define ull unsigned long long
#define R register
using namespace std;
template<typename T>void read(T &a)
{
T x=0,f=1;char ch=getchar();
while(!isdigit(ch))
{
if(ch=='-')f=0;ch=getchar();
}
while(isdigit(ch))
{
x=(x<<1)+(x<<3)+ch-'0';ch=getchar();
}
a=f?x:-x;
}
/*-------------OI使我快乐-------------*/
char s[N<<1];
int n,key;
int SA[N<<1],rnk[N<<1],vis[N<<1],wzy[N<<1],cdy[N<<1];
//cdy 作为第一关键字
//wzy 作为第二关键字
IL void Rsort()
{
for(R int i=0;i<=key;++i) vis[i]=0;
for(R int i=1;i<=n;++i) vis[cdy[i]]++;
for(R int i=1;i<=key;++i) vis[i]+=vis[i-1];
for(R int i=n;i;--i) SA[vis[cdy[wzy[i]]]--]=wzy[i];
}
IL void get_SA()
{
for(R int i=1;i<=n;++i) cdy[i]=s[i],wzy[i]=i;
Rsort();
for(R int x=1;x<=n;x<<=1)
{
int cnt=0;
for(R int i=n-x+1;i<=n;++i) wzy[++cnt]=i;
for(R int i=1;i<=n;++i) if(SA[i]>x) wzy[++cnt]=SA[i]-x;
Rsort();swap(cdy,wzy);
cdy[SA[cnt=1]]=1;
for(R int i=2;i<=n;++i)
cdy[SA[i]]=(wzy[SA[i]]==wzy[SA[i-1]] && wzy[SA[i]+x]==wzy[SA[i-1]+x] ? cnt:++cnt);
if(cnt==n) break;
else key=cnt;
}
}
int main()
{
// freopen(".in","r",stdin);
// freopen(".out","w",stdout);
scanf("%s",s+1);n=strlen(s+1);key=130;
get_SA();
for(R int i=1;i<=n;++i) printf("%d%c",SA[i],(i==n ? '\n':' '));
// fclose(stdin);
// fclose(stdout);
return 0;
}
基数排序
一开始不怎么明白 但是看了看基数排序之后就懂了
首先 这里的基数排序是\(LSD\)(从低位到高位)
但是按照制胡窜来讲 显然是\(MSD\)更容易一些
但是随着序列长度的上升 \(MSD\)的性能远不及\(LSD\)
所以这里只好使用\(LSD\)
实在不懂的话就 。。。。。。
IL void Rsort()
{
for(R int i=0;i<=key;++i) vis[i]=0;
for(R int i=1;i<=n;++i) vis[cdy[i]]++;
for(R int i=1;i<=key;++i) vis[i]+=vis[i-1];
for(R int i=n;i;--i) SA[vis[cdy[wzy[i]]]--]=wzy[i];
}
前三行都是比较好理解 唯独最后一行不太好理解
首先我们看看第二关键字是如何让处理的
for(R int i=n-x+1;i<=n;++i) wzy[++cnt]=i;
for(R int i=1;i<=n;++i) if(SA[i]>x) wzy[++cnt]=SA[i]-x;
再看这张解惑图
\(wzy[i]=j\) 表示第二关键字排名为\(i\)位于第\(j\)个位置
第一行代码表示
上面由于倍增从而没有第二关键字的 那么就是空
自然排名也位于最前面
第二行代码表示
然后就是顺序存入 \(SA[i]-x\)表示TA是可以作为前面\(SA[i]-x\)的第二关键字
然后这样就可以了
然后再回来看第四行
一开始的处理就已经处理好了第二关键字
所以现在满足\(LSD\) 开始对第一关键字的排序
然后按照基数排序的逻辑
我们按照第二关键字的顺序
倒序存入之后 有里向外 数组下标发生了
**排名 --wzy--> 位置 **
**位置 ---cdy-> 排名 **
排名--vis--> 原始排名作为权值成为新的排名
排名 --SA--> 成为我们要的SA
更多的来说 是由于仅靠前面的字符无法分出胜负
所以我们使用后面的字符 作为第二关键字
在内部进行更深层次的划分
这就是基数排序的本质所在
大数之所以大 在于其有高位
但是没有低位的话 TA就会被别的大数压下去
维护关键字
for(R int x=1;x<=n;x<<=1)
{
int cnt=0;
for(R int i=n-x+1;i<=n;++i) wzy[++cnt]=i;
for(R int i=1;i<=n;++i) if(SA[i]>x) wzy[++cnt]=SA[i]-x;
Rsort();swap(cdy,wzy);
cdy[SA[cnt=1]]=1;
for(R int i=2;i<=n;++i)
cdy[SA[i]]=(wzy[SA[i]]==wzy[SA[i-1]] && wzy[SA[i]+x]==wzy[SA[i-1]+x] ? cnt:++cnt);
if(cnt==n) break;
else key=cnt;
}
首先委会第二关键字我们已经透彻了
接下来就是第一关键字
为了节约空间 所以使用了\(swap()\) 反正也没有什么用了
然后排在第一的位置 当然排名就是第一了
然后的话每一次我们都同上一个比较
观察是否第一第二关键字都相同
是的话 TA们的排名就是相同的
否则的话 我们的倍增已经使得TA们互不相同了
那么接下来就没有必要了
所以就可以结束了
当然 后缀排序仅仅是一个板子
【update】
高度数组\(height[]\)
\(hei[rnk[i]]=LCP(rnk[i],rnk[i]-1)\)
最长公共前缀
\(hei[i]≥hei[i-1]+1\)
IL void get_he()
{
int lat,k=0;
for(R int i=1;i<=n;++i) rnk[SA[i]]=i;
for(R int i=1;i<=n;++i)
{
if(k) k--;
lat=SA[rnk[i]-1];
while(s[i+k]==s[lat+k]) ++k;
hei[rnk[i]]=k;
}
}
最长公共子串
我们把两个串 接在一起 然后求\(SA\)
可以想象到的是
最长公共子串一定是某个后缀的前缀
然后两个最相近的前缀对应的位置 字典序一定是相邻的
所以我们枚举排名然后判断位置是否属于两个串 然后对于最长公共前缀取\(Max\)即可
int ans=0;
for(R int i=1;i<=n;++i)
{
int x,y;
x=SA[i-1];y=SA[i];
if((x>len1&&y<len1)||(x<len1&&y>len1))
//是否属于两个不同的串
ans=max(ans,hei[i]);
}
printf("%d\n",ans);
求本质不同的的子串数量
本质不同的子串数量 :\(\sum_{i=1}^{n}n-SA[i]+1-hei[i]\)
int main()
{
// freopen(".in","r",stdin);
// freopen(".out","w",stdout);
read(T);
while(T--)
{
scanf("%s",s+1);n=strlen(s+1);key=130;ans=0;
get_SA();get_he();
// for(R int i=1;i<=n;++i) printf("%d%c",hei[i],(i==n ? '\n':' '));
for(R int i=1;i<=n;++i)
ans+=1ll*(n-SA[i]+1-hei[i]);
printf("%lld\n",ans);
}
// fclose(stdin);
// fclose(stdout);
return 0;
}
求本质不同的第\(k\)小子串
我们首先由排名从高到低
依次计算每一个位置的贡献 用前缀和以及二分查找来实现
然后找到对应的位置 暴力枚举即可
int main()
{
// freopen(".in","r",stdin);
// freopen(".out","w",stdout);
scanf("%s",s+1);n=strlen(s+1);key=130;
get_SA();get_hei();
// for(R int i=1;i<=n;++i) printf("%d%c",SA[i],(i==n ? '\n':' '));
for(R int i=1;i<=n;++i) sum[i]=sum[i-1]+(n-SA[i]+1-hei[i]);
int T,k;
read(T);
while(T--)
{
read(k);
int id=lower_bound(sum+1,sum+n+1,k)-sum;
int bw=k-sum[id-1]+hei[id];
for(R int i=0;i<bw;++i)
printf("%c",s[i+SA[id]]);puts("");
}
// fclose(stdin);
// fclose(stdout);
return 0;
}
求第\(k\)大子串(本质相同的也要计算)
对于给出的排名
我们用二分答案确定其本质不同时对应的排名
然后以此我们可以确定其开头对应的\(x\)以及长度\(len\)
那么比其小的子串的个数就是
\(\sum_{i=1}^{x=1}(n-SA[i]+1)+\sum_{i=x}^{n}min(LCP(x,i),len)\)
顺道提一下
\(LCP(x,y)=min(LCP(x,x+1),LCP(x+1,x+2),......,LCP(y-1,y))\)
IL int check(int x)
{
int s1=0,s2=0;
//s1 统计答案
//s2 本质不同
for(R int i=1;i<=n;++i)
{
if(s2+n-SA[i]+1-hei[i]>=x)
{//我们找到了
int len=0,tox=x-s2+hei[i];
for(R int j=0;j<tox;++j) len++;
int minx=hei[i+1];s1+=len;
for(R int j=i+1;j<=n;++j)
{
minx=min(minx,hei[j]);
if(hei[j]<len)
{
for(R int k=j;k<=n;++k)
{
minx=min(minx,hei[k]);
s1+=minx;
}
return s1;
}
s1+=len;
}
}
s1+=n-SA[i]+1;s2+=n-SA[i]+1-hei[i];
}
}
int le=1,ri=k,ans;
while(le<=ri)
{
int mid=(le+ri)>>1;
if(check(mid)>=k) {ans=mid;ri=mid-1;}
else le=mid+1;
}
求旋转字典序排序之后字符串
我们还是在其后面再接一个同样的串
然后跑\(SA\) 然后我们直接看位置是否合法
然后求结尾字符即可
int main()
{
// freopen(".in","r",stdin);
// freopen(".out","w",stdout);
scanf("%s",s+1);n=strlen(s+1);key=130;
for(R int i=1;i<=n;++i) s[n+i]=s[i];n<<=1;
get_SA();
// for(R int i=1;i<=n;++i) printf("%d%c",SA[i],(i==n ? '\n':' '));
for(R int i=1;i<=n;++i)
if(SA[i]<=(n>>1)) ans[++tot]=s[SA[i]+(n>>1)-1];
for(R int i=1;i<=n;++i)
printf("%c",ans[i]);
// fclose(stdin);
// fclose(stdout);
return 0;
}
求两个串的相同子串的数量
答案就是$$\sum_{i=1}{n}\sum_{j=1}m LCP(i,j)$$
其中\(i,j\)属于两个不同的串
我们把两个串拼在一起之后
就是求任意两个后缀的最长公共前缀
由于 $$LCP(i,j)=min{LCP(k,k+1)}(i≤k<j)$$
所以我们可以使用单调栈维护
也就是T2
然后再减去两个串自己的贡献即可
IL ll qury(char *s,int len)
{
memset(SA,0,sizeof SA);memset(cdy,0,sizeof cdy);
memset(wzy,0,sizeof wzy);memset(rnk,0,sizeof rnk);
memset(hei,0,sizeof hei);
ll sum=0;key=130;get_SA(s,len);get_hei(s,len);
// for(R int i=1;i<=len;++i) printf("%d%c",SA[i],(i==len ? '\n':' '));
for(R int i=2;i<=len;++i) hei[i-1]=hei[i];len--;
for(R int i=1;i<=len;++i) Le[i]=0,Ri[i]=len+1;
top=0;memset(sta,0,sizeof sta);
for(R int i=1;i<=len;++i)
{
while(top&&hei[sta[top]]>=hei[i]) Ri[sta[top--]]=i;
sta[++top]=i;
}
top=0;memset(sta,0,sizeof sta);
for(R int i=len;i;--i)
{
while(top&&hei[sta[top]]>hei[i]) Le[sta[top--]]=i;
sta[++top]=i;
}
for(R int i=1;i<=len;++i) sum+=1ll*(Ri[i]-i)*(i-Le[i])*hei[i];
return sum;
}
int main()
{
// freopen(".in","r",stdin);
// freopen(".out","w",stdout);
scanf("%s%s",sx+1,sy+1);
le=strlen(sx+1);ri=strlen(sy+1);
for(R int i=1;i<=le;++i) sk[++n]=sx[i];
sk[++n]='#';for(R int i=1;i<=ri;++i) sk[++n]=sy[i];
// for(R int i=1;i<=n;++i) cout<<s[i];
ans=qury(sk,n)-qury(sx,le)-qury(sy,ri);
printf("%lld\n",ans);
// fclose(stdin);
// fclose(stdout);
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号