2.进程调度
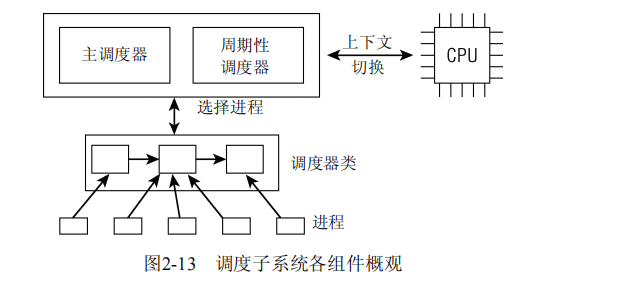
可以用两种方法激活调度。一种是直接的,比如进程打算睡眠或出于其他原因放弃CPU;另一种是通过周期性机制,以固定的频率运行,不时检测是否有必要进行进程切换。在下文中我将这两个组件称为通用调度器(generic scheduler)或核心调度器(core scheduler)。
<sched.h> struct task_struct { ... int prio, static_prio, normal_prio; unsigned int rt_priority; struct list_head run_list; const struct sched_class *sched_class; struct sched_entity se; unsigned int policy; cpumask_t cpus_allowed; unsigned int time_slice; ... }
prio和normal_prio表示动态优先级,static_prio表示进程的静态优先级。静态优先级是进程启动时分配的优先级。它可以用nice和sched_setscheduler系统调用修改,否则在进程运行期间会一直保持恒定。
normal_priority表示基于进程的静态优先级和调度策略计算出的优先级(实时进程基于调度策略,非实时等于静态优先级)。因此,即使普通进程和实时进程具有相同的静态优先级,其普通优先级也是不同的。进程分支时,子进程会继承普通优先级。
但调度器考虑的优先级则保存在prio。由于在某些情况下内核需要暂时提高进程的优先级,因此需要第3个成员来表示。由于这些改变不是持久的,因此静态和普通优先级不受影响。
rt_priority表示实时进程的优先级。最低的实时优先级为0,而最高的优先级是99。值越大,表明优先级越高。这里使用的惯例不同于nice值。(prio越小,优先级越高)
sched_class表示该进程所属的调度器类。
调度器不限于调度进程,还可以处理更大的实体。故用sched_entity表示。
policy保存了对该进程应用的调度策略。Linux支持5个可能的值。
SCHED_NORMAL用于普通进程,我们主要讲述此类进程。它们通过完全公平调度器来处理。SCHED_BATCH和SCHED_IDLE也通过完全公平调度器来处理,不过可用于次要的进程。SCHED_BATCH用于非交互、CPU使用密集的批处理进程。
SCHED_RR和SCHED_FIFO用于实现软实时进程。
调度器类
<sched.h> struct sched_class { const struct sched_class *next; void (*enqueue_task) (struct rq *rq, struct task_struct *p, int wakeup); void (*dequeue_task) (struct rq *rq, struct task_struct *p, int sleep); void (*yield_task) (struct rq *rq); void (*check_preempt_curr) (struct rq *rq, struct task_struct *p); struct task_struct * (*pick_next_task) (struct rq *rq); void (*put_prev_task) (struct rq *rq, struct task_struct *p); void (*set_curr_task) (struct rq *rq); void (*task_tick) (struct rq *rq, struct task_struct *p); void (*task_new) (struct rq *rq, struct task_struct *p); };
在必要的情况下,会调用check_preempt_curr,用一个新唤醒的进程来抢占当前进程。例如,在用wake_up_new_task唤醒新进程时,会调用该函数。
task_tick在每次激活周期性调度器时,由周期性调度器调用。
SCHED_NORMAL、SCHED_BATCH和SCHED_IDLE映射到fair_sched_class,而SCHED_RR和SCHED_FIFO与rt_sched_class关联。fair_sched_class和rt_sched_class都是struct sched_class的实例,分别表示完全公平调度器和实时调度器。
check_preempt_curr在非实时是check_preempt_wakeup,在实时是check_preempt_curr_rt,check_preempt_curr函数在try_to_wake_up或wake_up_new_task中唤醒,
pick_next_task在非实时是直接取自cfs_rq的最左红黑树结点,在实时则是从0遍历位图
task_new只在非实时上找到
task_tick只在周期性调度器被调度,非实时是task_tick_fair,用于检测自身是否运行足够长时间,task_tick_rt则是根据实时类型,若是FIFO直接返回,若是RR,判断是否时间片已经用完,没用完则返回。
就绪队列
kernel/sched.c struct rq { unsigned long nr_running; #define CPU_LOAD_IDX_MAX 5 unsigned long cpu_load[CPU_LOAD_IDX_MAX]; ... struct load_weight load; struct cfs_rq cfs; struct rt_rq rt; struct task_struct *curr, *idle; u64 clock; ... };
load提供了就绪队列当前负荷的度量。队列的负荷本质上与队列上当前活动进程的数目成正比,其中的各个进程又有优先级作为权重。
cpu_load用于跟踪此前的负荷状态。
cfs和rt是嵌入的子就绪队列,分别用于完全公平调度器和实时调度器。
clock和prev_raw_clock用于实现就绪队列自身的时钟。每次调用周期性调度器时,都会更新clock的值。另外内核还提供了标准函数update_rq_clock,可在操作就绪队列的调度器中多处调用,例如,在用wakeup_new_task唤醒新进程时。
系统的所有就绪队列都在runqueues数组中,该数组的每个元素分别对应于系统中的一个CPU。在单处理器系统中,由于只需要一个就绪队列,数组只有一个元素。
内核也定义了一些便利的宏,其含义很明显。
kernel/sched.c #define cpu_rq(cpu) (&per_cpu(runqueues, (cpu))) #define this_rq() (&__get_cpu_var(runqueues)) #define task_rq(p) cpu_rq(task_cpu(p)) #define cpu_curr(cpu) (cpu_rq(cpu)->curr)
调度实体
由于调度器可以操作比进程更一般的实体,因此需要一个适当的数据结构来描述此类实体。
<sched.h> struct sched_entity { struct load_weight load; /* 用于负载均衡 */ struct rb_node run_node; unsigned int on_rq; u64 exec_start; u64 sum_exec_runtime; u64 vruntime; u64 prev_sum_exec_runtime; ... }
load指定了权重,决定了各个实体占队列总负荷的比例。
on_rq表示该实体当前是否在就绪队列上接受调度
新进程加入就绪队列时,或者周期性调度器中
会计算当前时间和exec_start之间的差值,exec_start则更新到当前时间。差值则被加到sum_exec_runtime。
在进程执行期间虚拟时钟上流逝的时间数量由vruntime统计。
在进程被撤销CPU时,其当前sum_exec_runtime值保存到prev_exec_runtime。此后,在进程抢占时又需要该数据。但请注意,在prev_exec_runtime中保存sum_exec_runtime的值,并不意味着重置sum_exec_runtime!原值保存下来,而sum_exec_runtime则持续单调增长。
处理优先级
p->prio = effective_prio(p); static int effective_prio(struct task_struct *p) { p->normal_prio = normal_prio(p); /* * 如果是实时进程或已经提高到实时优先级,则保持优先级不变。否则,返回普通优先级: */ if (!rt_prio(p->prio)) return p->normal_prio; return p->prio; } static inline int normal_prio(struct task_struct *p){ int prio; if (task_has_rt_policy(p)) prio = MAX_RT_PRIO-1 -p->rt_priority; else prio = __normal_prio(p); return prio; } static inline int __normal_prio(struct task_struct *p) { return p->static_prio; }
为什么内核在effective_prio中检测实时进程是基于优先级数值,而非task_has_rt_policy?对于临时提高至实时优先级的非实时进程来说,这是必要的,这种情况可能发生在使用实时互斥量(RT-Mutex)时。
在新建进程用wake_up_new_task唤醒时,或使用nice系统调用改变静态优先级时,则用上文给出的方法设置p->prio。
请注意,在进程分支出子进程时,子进程的静态优先级继承自父进程。子进程的动态优先级,即task_struct->prio,则设置为父进程的普通优先级。这确保了实时互斥量引起的优先级提高不会传递到子进程。

程序的优先级范围为[0,139],有效的实时优先级(RT priority)范围为[0,99],SCHED_NORMAL和SCHED_BATCH这两个非实时任务的优先级为[100,139]。[100,139]这个区间的优先级又称为静态优先级(static priority)。之所以称为静态优先级是因为它不会随着时间而改变,内核不会修改它,只能通过系统调用nice去修改。静态优先级用进程描述符中的static_prio表示。优先级的值越低,表示具有更高的优先级,0的优先级最高。
计算负荷权重
进程的重要性不仅是由优先级指定的,而且还需要考虑保存在task_struct->se.load的负荷权重。set_load_weight负责根据进程类型及其静态优先级计算负荷权重。
<sched.h> struct load_weight { unsigned long weight, inv_weight; }; kernel/sched.c static const int prio_to_weight[40] = { /* -20 */ 88761, 71755, 56483, 46273, 36291, /* -15 */ 29154, 23254, 18705, 14949, 11916, /* -10 */ 9548, 7620, 6100, 4904, 3906, /* -5 */ 3121, 2501, 1991, 1586, 1277, /* 0 */ 1024, 820, 655, 526, 423, /* 5 */ 335, 272, 215, 172, 137, /* 10 */ 110, 87, 70, 56, 45, /* 15 */ 36, 29, 23, 18, 15, }; kernel/sched.c #define WEIGHT_IDLEPRIO 2 #define WMULT_IDLEPRIO (1 << 31) static void set_load_weight(struct task_struct *p) { if (task_has_rt_policy(p)) { p->se.load.weight = prio_to_weight[0] * 2; //只要是实时进程获得的权重即为2倍 p->se.load.inv_weight = prio_to_wmult[0] >> 1; return; } /* * SCHED_IDLE进程得到的权重最小: */ if (p->policy == SCHED_IDLE) { p->se.load.weight = WEIGHT_IDLEPRIO; p->se.load.inv_weight = WMULT_IDLEPRIO; return; } p->se.load.weight = prio_to_weight[p->static_prio -MAX_RT_PRIO]; 与static有关 p->se.load.inv_weight = prio_to_wmult[p->static_prio -MAX_RT_PRIO]; }
每次进程被加到就绪队列时,内核会调用inc_nr_running。这不仅确保就绪队列能够跟踪记录有多少进程在运行,而且还将进程的权重添加到就绪队列的权重中
调度器
1. 周期性调度器
周期性调度器在scheduler_tick中实现。如果系统正在活动中,内核会按照频率HZ自动调用该函数。
由于调度器的模块化结构,主体工程实际上比较简单,因为主要的工作可以完全委托给特定调度器类的方法:
kernel/sched.c if (curr != rq->idle) curr->sched_class->task_tick(rq, curr); }
task_tick的实现方式取决于底层的调度器类。例如,完全公平调度器会在该方法中检测是否进程已经运行太长时间,以避免过长的延迟,如果当前进程应该被重新调度,那么调度器类方法会在task_struct中设置TIF_NEED_RESCHED标志,以表示该请求,而内核会在接下来的适当时机完成该请求。
2. 主调度器
kernel/sched.c asmlinkage void __sched schedule(void) { struct task_struct *prev, *next; struct rq *rq; int cpu; need_resched: cpu = smp_processor_id(); rq = cpu_rq(cpu); prev = rq->curr; //首先确定当前就绪队列,并在prev中保存一个指向(仍然)活动进程的task_struct的指针
...
__update_rq_clock(rq);
clear_tsk_need_resched(prev); //类似于周期性调度器,内核也利用该时机来更新就绪队列的时钟,并清除当前运行进程task_struct中的重调度标志TIF_NEED_RESCHED。
... if (unlikely((prev->state & TASK_INTERRUPTIBLE) &&unlikely(signal_pending(prev)))) { prev->state = TASK_RUNNING; } else { deactivate_task(rq, prev, 1); } ... prev->sched_class->put_prev_task(rq, prev); next = pick_next_task(rq, prev); //优先调度实时进程
if (likely(rq->nr_running == rq->cfs.nr_running)) { p = fair_sched_class.pick_next_task(rq); if (likely(p)) return p; }
... if (likely(prev != next)) { //不见得必然选择一个新进程。也可能其他进程都在睡眠,当前只有一个进程能够运行,这样它自然就被留在CPU上。
rq->curr = next; context_switch(rq, prev, next); } ...
下列代码检测当前进程的重调度位是否设置,并跳转到如上所述的标号,重新开始搜索一个新进程:
if (unlikely(test_thread_flag(TIF_NEED_RESCHED))) goto need_resched; }
上述代码片段可能在两个不同的上下文中执行。在没有执行上下文切换时,它在schedule函数的末尾直接执行。但如果已经执行了上下文切换,当前进程会正好在这以前停止运行,新进程已经接管了CPU。但稍后在前一进程被再次选择运行时,它会刚好在这一点上恢复执行。在这种情况下,由于prev不会指向正确的进程,所以需要通过current和test_thread_flag找到当前线程。
原因:
switch_to3个参数:prev,next和last。last的作用:A切换到B时,prev=A,next=B, 经过一定时间后,A被重新调度到CPU上执行时,A需要知道从哪个进程切换过来的,需要从last参数得到。
![]()

4. 上下文切换
kernel/sched.c static inline void context_switch(struct rq *rq, struct task_struct *prev, struct task_struct *next) { struct mm_struct *mm, *oldmm; prepare_task_switch(rq, prev, next); mm = next->mm; oldmm = prev->active_mm; ..
内核线程没有自身的用户空间内存上下文,可能在某个随机进程地址空间的上部执行。其task_struct->mm为NULL。从当前进程“借来”的地址空间记录在active_mm中。
enter_lazy_tlb通知底层体系结构不需要切换虚拟地址空间的用户空间部分。这种加速上下文切换的技术称之为惰性TLB。
if (unlikely(!mm)) { next->active_mm = oldmm; atomic_inc(&oldmm->mm_count); enter_lazy_tlb(oldmm, next); } else switch_mm(oldmm, mm, next);该工作的细节取决于处理器,主要包括加载页表、刷出地址转换后备缓冲器(部分或全部)、向内存管理单元(MMU)提供新的信息。
...
如果前一进程是内核线程(即prev->mm为NULL),则其active_mm指针必须重置为NULL,以断开与借用的地址空间的联系
if (unlikely(!prev->mm)) { prev->active_mm = NULL; rq->prev_mm = oldmm; } ... /* 这里我们只是切换寄存器状态和栈。 */ switch_to(prev, next, prev); //编译器指令
barrier(); /* * this_rq必须重新计算,因为在调用schedule()之后prev可能已经移动到其他CPU, * 因此其栈帧上的rq可能是无效的。 */ finish_task_switch(this_rq(), prev); }
finish_task_switch完成一些清理工作,使得能够正确地释放锁。finish_task_switch的有趣之处在于,调度过程可能选择了一个新进程,而清理则是针对此前的活动进程。请注意,这不是发起上下文切换的那个进程,而是系统中随机的某个其他进程!
完全公平调度类
kernel/sched_fair.c static const struct sched_class fair_sched_class = { .next = &idle_sched_class, .enqueue_task = enqueue_task_fair, .dequeue_task = dequeue_task_fair, .yield_task = yield_task_fair, .check_preempt_curr = check_preempt_wakeup, .pick_next_task = pick_next_task_fair, .put_prev_task = put_prev_task_fair, ... .set_curr_task = set_curr_task_fair, .task_tick = task_tick_fair, .task_new = task_new_fair, };
所有与虚拟时钟有关的计算都在update_curr中执行,该函数在系统中各个不同地方调用,包括周期性调度器之内。
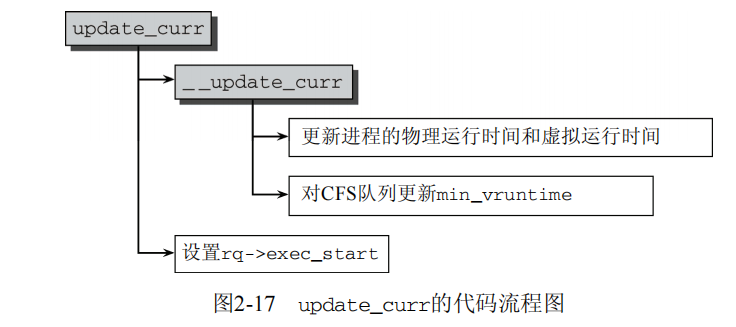
static void update_curr(struct cfs_rq *cfs_rq) { struct sched_entity *curr = cfs_rq->curr; u64 now = rq_of(cfs_rq)->clock; //获取主调度器就绪队列的实际时钟值
unsigned long delta_exec; if (unlikely(!curr)) return; ... delta_exec = (unsigned long)(now -curr->exec_start); //计算当前和上一次更新负荷统计量时两次的时间差,并将其余的工作委托给__update_curr。
__update_curr(cfs_rq, curr, delta_exec); curr->exec_start = now; } static inline void __update_curr(struct cfs_rq *cfs_rq, struct sched_entity *curr, unsigned long delta_exec) { unsigned long delta_exec_weighted; u64 vruntime; curr->sum_exec_runtime += delta_exec; //物理时间的更新 ... delta_exec_weighted = delta_exec; if (unlikely(curr->load.weight != NICE_0_LOAD)) { delta_exec_weighted = calc_delta_fair(delta_exec_weighted, &curr->load); } curr->vruntime += delta_exec_weighted; ...
calc_delta_fair所作的就是根据下列公式计算: ![]() (越重要的进程会有越高的优先级(即,越低的nice值),会得到更大的权重,因此累加的虚拟运行时间会小一些)
(越重要的进程会有越高的优先级(即,越低的nice值),会得到更大的权重,因此累加的虚拟运行时间会小一些)
kernel/sched_fair.c /* * 跟踪树中最左边的结点的vruntime,维护cfs_rq->min_vruntime的单调递增性 */
//first_fair是一个辅助函数,检测树是否有最左边的结点,即是否有进程在树上等待调度。 if (first_fair(cfs_rq)) { vruntime = min_vruntime(curr->vruntime, __pick_next_entity(cfs_rq)->vruntime); } else vruntime = curr->vruntime; cfs_rq->min_vruntime = max_vruntime(cfs_rq->min_vruntime, vruntime); }
红黑树的排序过程是根据下列键进行的:
static inline s64 entity_key(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
return se->vruntime -cfs_rq->min_vruntime;
}
键值较小的结点,排序位置就更靠左,因此会被更快地调度。
(1) 在进程运行时,其vruntime稳定地增加,它在红黑树中总是向右移动的。因为越重要的进程vruntime增加越慢,因此它们向右移动的速度也越慢,这样其被调度的机会要大于次要进程,这刚好是我们需要的。
(2) 如果进程进入睡眠,则其vruntime保持不变。因为每个队列min_vruntime同时会增加(回想一下,它是单调的!),那么睡眠进程醒来后,在红黑树中的位置会更靠左,因为其键值变得更小了。①
延迟跟踪
sysctl_sched_latency可通过/proc/sys/kernel/sched_latency_ns控制,默认值为20 000 000纳秒或20毫秒,即保证每个可运行的进程都应该至少运行一次的某个时间间隔。
sched_nr_latency,控制在一个延迟周期中处理的最大活动进程数目。如果活动进程的数目超出该上限,则延迟周期也成比例地线性扩展。
分配给进程的运行时间 = 调度周期 * 进程权重 / 所有进程权重之和 (公式1)
vruntime = 实际运行时间 * 1024 / 进程权重 (公式2)
vruntime =调度周期 * 1024 / 所有进程总权重
CFS的思想就是让每个进程的vruntime互相追赶,而由于每个进程的vruntime增加速度不同,权重越大的增加的越慢,这样就能获得更多的CPU执行时间了
加入队列
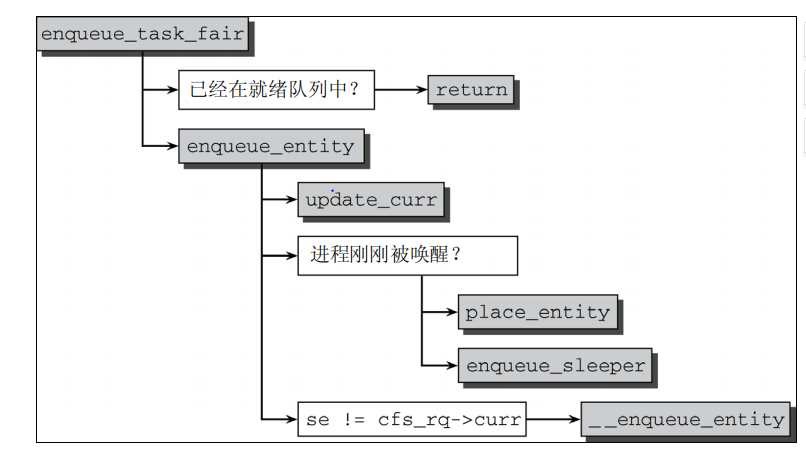
kernel/sched_fair.c static void place_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int initial) { u64 vruntime; vruntime = cfs_rq->min_vruntime; if (initial) vruntime += sched_vslice_add(cfs_rq, se); //加上公式中的vruntime if (!initial) { vruntime -= sysctl_sched_latency; //减去基准虚拟实践 vruntime = max_vruntime(se->vruntime, vruntime); } se->vruntime = vruntime; }
只有在新进程加入到队列时才会设置initial,即fork创建时
选择下一个进程
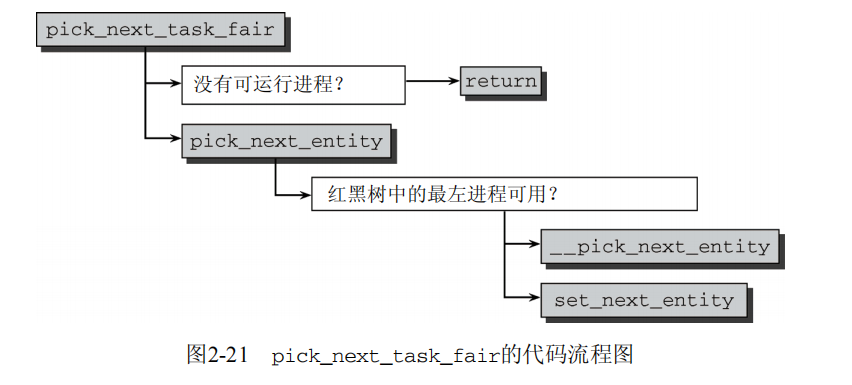
kernel/sched_fair.c static void set_next_entity(struct cfs_rq *cfs_rq, struct sched_entity *se) { /* 树中不保存“当前”进程。 */ if (se->on_rq) { __dequeue_entity(cfs_rq, se); } ...
当前执行进程不保存在就绪队列上,因此使用__dequeue_entity将其从树中移除。
尽管该进程不再包含在红黑树中,但进程和就绪队列之间的关联没有丢失,因为curr标记了当前运行的进程:
kernel/sched_fair.c
cfs_rq->curr = se;
se->prev_sum_exec_runtime = se->sum_exec_runtime;
}
处理周期性调度器
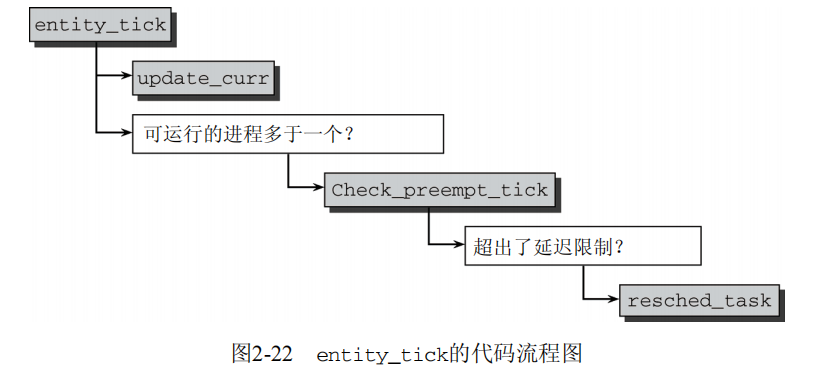
首先,一如既往地使用update_curr更新统计量。如果队列的nr_running计数器表明队列上可运行的进程少于两个,则实际上无事可做。如果某个进程应该被抢占,那么至少需要有另一个进程能够抢占它。如果进程数目不少于两个,则由check_preempt_tick作出决策:
kernel/sched_fair.c static void check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr) { unsigned long ideal_runtime, delta_exec; ideal_runtime = sched_slice(cfs_rq, curr); delta_exec = curr->sum_exec_runtime -curr->prev_sum_exec_runtime;
//进程对应额对应的实际时间长度在sched_slice中计算,如上文上述,进程在CPU上已经运行的实际时间间隔由sum_exec_runtime-prev_sum_exec_runtime给出
if (delta_exec > ideal_runtime) resched_task(rq_of(cfs_rq)->curr); //这会在task_struct中设置TIF_NEED_RESCHED标志,核心调度器会在下一个适当时机发起重调度。
}
唤醒抢占
当在try_to_wake_up和wake_up_new_task中唤醒进程时,内核使用check_preempt_curr看看是否新进程可以抢占当前运行的进程。请注意该过程不涉及核心调度器!对完全公平调度器处理的进程,则由check_preempt_wakeup函数执行该检测。
kernel/sched_fair.c static void check_preempt_wakeup(struct rq *rq, struct task_struct *p) { struct task_struct *curr = rq->curr; struct cfs_rq *cfs_rq = task_cfs_rq(curr); struct sched_entity *se = &curr->se, *pse = &p->se; unsigned long gran;
新唤醒的进程不必一定由完全公平调度器处理。如果新进程是一个实时进程,则会立即请求重调度,因为实时进程总是会抢占CFS进程
if (unlikely(rt_prio(p->prio))) { update_rq_clock(rq); update_curr(cfs_rq); resched_task(curr); return; } ...
当运行进程被新进程抢占时,内核确保被抢占者至少已经运行了某一最小时间限额。
gran = sysctl_sched_wakeup_granularity; if (unlikely(se->load.weight != NICE_0_LOAD)) gran = calc_delta_fair(gran, &se->load); ...
如果新进程的虚拟运行时间,加上最小时间限额,仍然小于当前执行进程的虚拟运行时间(由其调度实体se表示),则请求重调度:
if (pse->vruntime + gran < se->vruntime) resched_task(curr); }
处理新进程
static void task_new_fair(struct rq *rq, struct task_struct *p) { struct cfs_rq *cfs_rq = task_cfs_rq(p); struct sched_entity *se = &p->se, *curr = cfs_rq->curr; int this_cpu = smp_processor_id(); sched_info_queued(p); update_curr(cfs_rq);
在这种情况下,调用place_entity时的initial参数设置为1,以便用sched_vslice_add计算初始的vruntime。
place_entity(cfs_rq, se, 1); /* 'curr' will be NULL if the child belongs to a different group */
sysctl_sched_child_runs_first控制新建子进程是否应该在父进程之前运行,默认为1
if (sysctl_sched_child_runs_first && this_cpu == task_cpu(p) && curr && curr->vruntime < se->vruntime) { /* * Upon rescheduling, sched_class::put_prev_task() will place * 'current' within the tree based on its new key value. */
如果父进程的虚拟运行时间(由curr表示)小于子进程的虚拟运行时间,则意味着父进程将在子进程之前调度运行。回想一下前文的内容,可知虚拟运算时间比较小,则在红黑树中的位置比较靠左。如果子进程应该在父进程之前运行,则二者的虚拟运算时间需要换过来。
swap(curr->vruntime, se->vruntime); }
然后子进程按常规加入就绪队列,并请求重调度。
enqueue_task_fair(rq, p, 0); resched_task(rq->curr); }
实时调度类
kernel/sched.c struct rt_prio_array { DECLARE_BITMAP(bitmap, MAX_RT_PRIO+1); /* 包含1比特用于间隔符 */ struct list_head queue[MAX_RT_PRIO]; }; struct rt_rq { struct rt_prio_array active; };
实时调度器类中对应于update_cur的是update_curr_rt,该函数将当前进程在CPU上执行花费的时间记录在sum_exec_runtime中。所有计算的单位都是实际时间,不需要虚拟时间。这样就简化了很多。
具有相同优先级的所有实时进程都保存在一个链表中,表头为active.queue[prio],而active.bitmap位图中的每个比特位对应于一个链表,凡包含了进程的链表,对应的比特位则置位。如果链表中没有进程,则对应的比特位不置位。
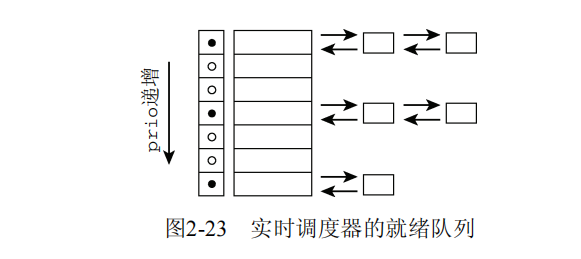
调度器操作
两个比较有趣的操作分别是,如何选择下一个将要执行的进程,以及如何处理抢占。首先考虑pick_next_task_rt,该函数放置选择下一个将执行的进程。其代码流程图在图2-24给出。
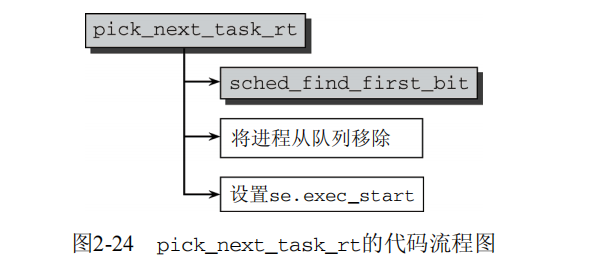
sched_find_first_bit是一个标准函数,可以找到active.bitmap中第一个置位的比特位,这意味着高的实时优先级(对应于较低的内核优先级值),因此在较低的实时优先级之前处理。
周期调度的实现同样简单。SCHED_FIFO进程最容易处理。它们可以运行任意长的时间,而且必须使用yield系统调用将控制权显式传递给另一个进程:
kernel/sched.c static void task_tick_rt(struct rq *rq, struct task_struct *p) { update_curr_rt(rq); /* * 循环进程需要一种特殊形式的时间片管理。 * 先进先出进程没有时间片。 */
SCHED_FIFO进程最容易处理。它们可以运行任意长的时间,而且必须使用yield系统调用将控制权显式传递给另一个进程 if (p->policy != SCHED_RR) return; ...
如果当前进程是循环进程,则减少其时间片。在尚未超出时间段时,没什么可作的
if (--p->time_slice) return; p->time_slice = DEF_TIMESLICE; /* * 如果不是队列上的唯一成员,则重新排队到末尾。 */
if (p->run_list.prev != p->run_list.next) { requeue_task_rt(rq, p);
如果该进程不是链表中唯一的进程,则重新排队到末尾。通过用set_tsk_need_resched设置TIF_NEED_RESCHED标志,照常请求重调度
set_tsk_need_resched(p);
}
}
为将进程转换为实时进程,必须使用sched_setscheduler系统调用。这里不详细讨论该函数了,因为它只执行了下列简单任务。
使用deactivate_task将进程从当前队列移除。
在task_struct中设置实时优先级和调度类。
重新激活进程。
如果进程此前不在任何就绪队列上,那么只需要设置调度类和新的优先级数值。停止进程活动和重激活则是不必要的。
要注意,只有具有root权限(或等价于CAP_SYS_NICE)的进程执行了sched_setscheduler系统调用,才能修改调度器类或优先级。否则,下列规则适用。
调度类只能从SCHED_NORMAL改为SCHED_BATCH,或反过来。改为SCHED_FIFO是不可能的。
只有目标进程的UID或EUID与调用者进程的EUID相同时,才能修改目标进程的优先级。此外,优先级只能降低,不能提升。
问题:是否可以用获得的时间片减去已运行时间作为键值呢?
1.非实时进程优先级
2.主调用器
3.周期性调度器(实时非实时)
4.唤醒新进程(实时非实时)
5.处理新进程(非实时)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号