1.进程地址空间的布局
虚拟地址空间中包含了若干区域。其分布方式是特定于体系结构的,但所有方法都有下列共同成分。
当前运行代码的二进制代码。该代码通常称之为text,所处的虚拟内存区域称之为text段。
程序使用的动态库的代码。
存储全局变量和动态产生的数据的堆。
用于保存局部变量和实现函数/过程调用的栈。
环境变量和命令行参数的段。
将文件内容映射到虚拟地址空间中的内存映射。
系统中的各个进程都具有一个struct mm_struct的实例,可以通过task_struct访问。这个实例保存了进程的内存管理信息:
<mm_types.h> struct mm_struct { ... unsigned long (*get_unmapped_area) (struct file *filp, unsigned long addr, unsigned long len, unsigned long pgoff, unsigned long flags); ... unsigned long mmap_base; /* mmap区域的基地址 */ unsigned long task_size; /* 进程虚拟内存空间的长度 */ ... unsigned long start_code, end_code, start_data, end_data; unsigned long start_brk, brk, start_stack; unsigned long arg_start, arg_end, env_start, env_end; ... }
可执行代码占用的虚拟地址空间区域,其开始和结束分别通过start_code和end_code标记。类似地,start_data和end_data标记了包含已初始化数据的区域。请注意,在ELF二进制文件映射到地址空间中之后,这些区域的长度不再改变。
堆的起始地址保存在start_brk,brk表示堆区域当前的结束地址。尽管堆的起始地址在进程生命周期中是不变的,但堆的长度会发生变化,因而brk的值也会变。
参数列表和环境变量的位置分别由arg_start和arg_end、env_start和env_end描述。两个区域都位于栈中最高的区域。
mmap_base表示虚拟地址空间中用于内存映射的起始地址,可调用get_unmapped_area在mmap区域中为新映射找到适当的位置。
task_size,顾名思义,存储了对应进程的地址空间长度。对本机应用程序来说,该值通常是TASK_SIZE。
我们需要考虑进程标志PF_RANDOMIZE。如果设置了该标志,则内核不会为栈和内存映射的起点选择固定位置,而是在每次新进程启动时随机改变这些值的设置。这引入了一些复杂性,例如,使得攻击因缓冲区溢出导致的安全漏洞更加困难。如果攻击者无法依靠固定地址找到栈,那么想要构建恶意代码,通过缓冲器溢出获得栈内存区域的访问权,而后恶意操纵栈的内容,将会困难得多。
图4-1说明了前述的各个部分在大多数体系结构的虚拟地址空间中的分布情况。
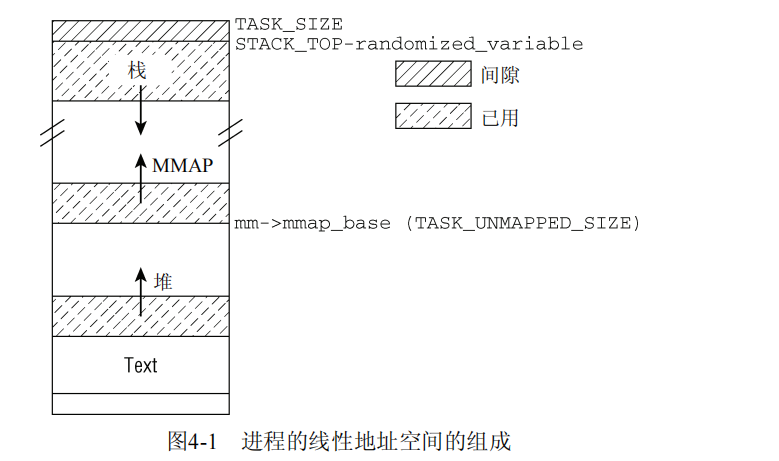
text段如何映射到虚拟地址空间中由ELF标准确定。IA-32系统起始于0x08048000,在text段的起始地址与最低的可用地址之间有大约128 MiB的间距,用于捕获NULL指针。堆紧接着text段开始,向上增长。
栈起始于STACK_TOP,如果设置了PF_RANDOMIZE,则起始点会减少一个小的随机量。每个体系结构都必须定义STACK_TOP,大多数都设置为TASK_SIZE,即用户地址空间中最高的可用地址。进程的参数列表和环境变量都是栈的初始数据。
用于内存映射的区域起始于mm_struct->mmap_base,通常设置为TASK_UNMAPPED_BASE,每个体系结构都需要定义。几乎所有的情况下,其值都是TASK_SIZE/3。要注意,如果使用内核的默认配置,则mmap区域的起始点不是随机的。
如果计算机提供了巨大的虚拟地址空间,那么使用上述的地址空间布局会工作得非常好。但在32位计算机上可能会出现问题。考虑IA-32的情况:虚拟地址空间从0到0xC0000000,每个用户进程有3 GiB可用。TASK_UNMAPPED_BASE起始于0x4000000,即1 GiB处。糟糕的是,这意味着堆只有1 GiB空间可供使用,继续增长则会进入到mmap区域,这显然不是我们想要的。
问题在于,内存映射区域位于虚拟地址空间的中间。这也是在内核版本2.6.7开发期间为IA-32计算机引入一个新的虚拟地址空间布局的原因(经典布局仍然可以使用)。新的布局如图4-2所示。
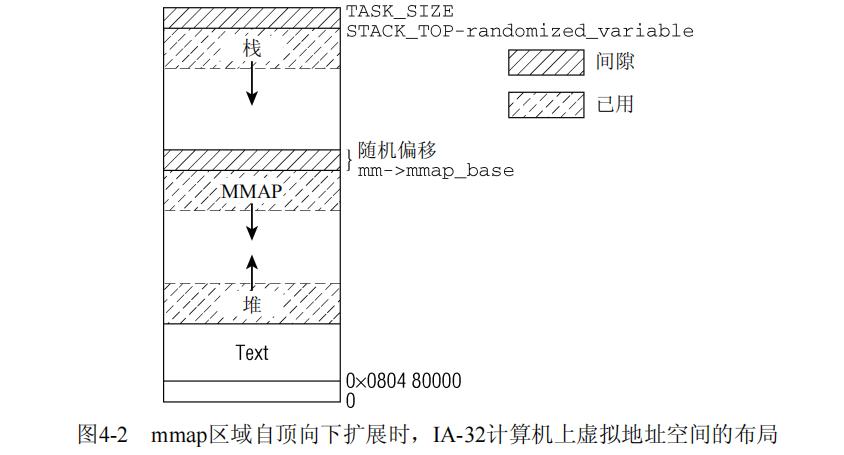
其想法在于使用固定值限制栈的最大长度。由于栈是有界的,因此安置内存映射的区域可以在栈末端的下方立即开始。与经典方法相反,该区域现在是自顶向下扩展。由于堆仍然位于虚拟地址空间中较低的区域并向上增长,因此mmap区域和堆可以相对扩展,直至耗尽虚拟地址空间中剩余的区域。为确保栈与mmap区域不发生冲突,两者之间设置了一个安全隙。
建立布局
在使用load_elf_binary装载一个ELF二进制文件时,将创建进程的地址空间。而exec系统调用刚好使用了该函数。
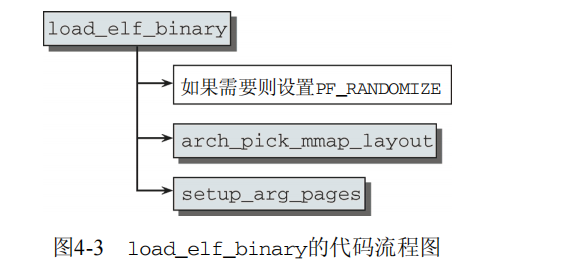
如果全局变量randomize_va_space设置为1,则启用地址空间随机化机制。 通常情况下都是启用的,此外,用户可以通过/proc/sys/kernel/randomize_va_space停用该特性。
选择布局的工作由arch_pick_mmap_layout完成。如果对应的体系结构没有提供一个具体的函数,则使用内核的默认例程,按如图4-1所示建立地址空间。但我们更感兴趣的是,IA-32如何在经典布局和新的布局之间选择:
arch/x86/mm/mmap_32.c void arch_pick_mmap_layout(struct mm_struct *mm) { /* /* 如果设置了personality比特位,或栈的增长不受限制,则回退到标准布局: */ if (sysctl_legacy_va_layout || (current->personality & ADDR_COMPAT_LAYOUT) || current->signal->rlim[RLIMIT_STACK].rlim_cur == RLIM_INFINITY) { mm->mmap_base = TASK_UNMAPPED_BASE; mm->get_unmapped_area = arch_get_unmapped_area; mm->unmap_area = arch_unmap_area; } else { mm->mmap_base = mmap_base(mm); mm->get_unmapped_area = arch_get_unmapped_area_topdown; mm->unmap_area = arch_unmap_area_topdown; } }
如果用户通过/proc/sys/kernel/legacy_va_layout给出明确的指示,或者要执行为不同的UNIX变体编译、需要旧的布局的二进制文件,或者栈可以无限增长(最重要的一点),则系统会选择旧的布局。这使得很难确定栈的下界,亦即mmap区域的上界。
在经典的配置下,mmap区域的起始点是TASK_UNMAPPED_BASE,其值为0x4000000,而标准函数arch_get_unmapped_area用于自下而上地创建新的映射。
在使用新布局时,内存映射自顶向下增长。标准函数arch_get_unmapped_area_topdown负责该工作。更有趣的问题是如何选择内存映射的基地址:
arch/x86/mm/mmap_32.c #define MIN_GAP (128*1024*1024) #define MAX_GAP (TASK_SIZE/6*5) static inline unsigned long mmap_base(struct mm_struct *mm) { unsigned long gap = current->signal->rlim[RLIMIT_STACK].rlim_cur; unsigned long random_factor = 0; if (current->flags & PF_RANDOMIZE) random_factor = get_random_int() % (1024*1024); if (gap < MIN_GAP) gap = MIN_GAP; else if (gap > MAX_GAP) gap = MAX_GAP; return PAGE_ALIGN(TASK_SIZE -gap -random_factor); }
可以根据栈的最大长度,来计算栈最低的可能位置,用作mmap区域的起始点。但内核会确保栈至少跨越128 MiB的空间。另外,如果指定的栈界限非常巨大,那么内核会保证至少有一小部分地址空间不被栈占据。
如果要求使用地址空间随机化机制,上述位置会减去一个随机的偏移量,最大为1 MiB。另外,内核会确保该区域对齐到页帧,这是体系结构的要求。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号