K8S从入门到放弃系列-(16)Kubernetes集群Prometheus-operator监控部署
Prometheus Operator不同于Prometheus,Prometheus Operator是 CoreOS 开源的一套用于管理在 Kubernetes 集群上的 Prometheus 控制器,它是为了简化在 Kubernetes 上部署、管理和运行 Prometheus 和 Alertmanager 集群。
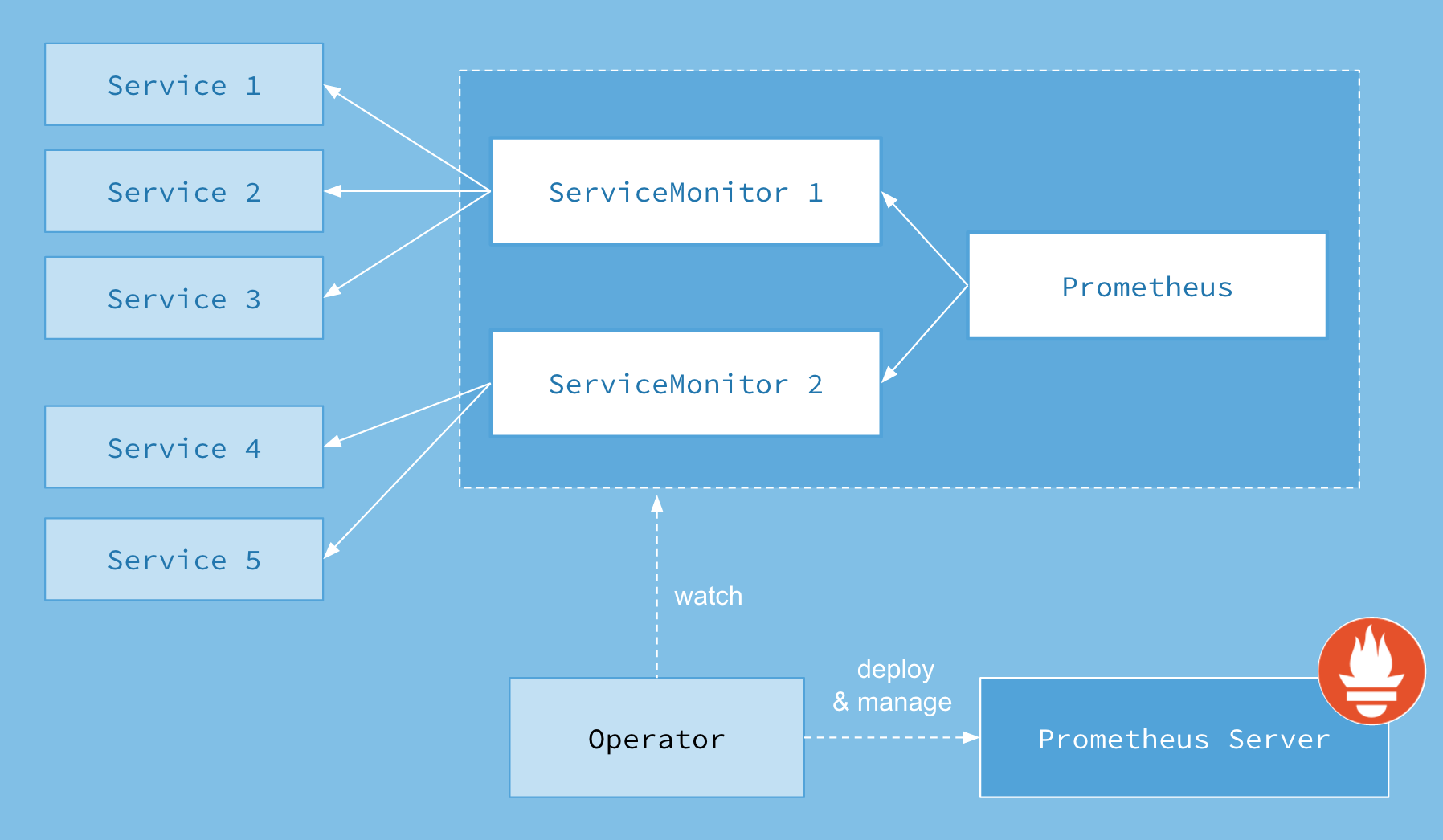
官方提供的架构图:
kubernetes也在官方的github上关于使用prometheus监控的建议:
地址:https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/prometheus
相关服务说明:
Operator: Operator 资源会根据自定义资源(Custom Resource Definition / CRDs)来部署和管理 Prometheus Server,同时监控这些自定义资源事件的变化来做相应的处理,是整个系统的控制中心。
Prometheus: Prometheus 资源是声明性地描述 Prometheus 部署的期望状态。
Prometheus Server: Operator 根据自定义资源 Prometheus 类型中定义的内容而部署的 Prometheus Server 集群,这些自定义资源可以看作是用来管理 Prometheus Server 集群的 StatefulSets 资源。
ServiceMonitor: ServiceMonitor 也是一个自定义资源,它描述了一组被 Prometheus 监控的 targets 列表。该资源通过 Labels 来选取对应的 Service Endpoint,让 Prometheus Server 通过选取的 Service 来获取 Metrics 信息。
Service: Service 资源主要用来对应 Kubernetes 集群中的 Metrics Server Pod,来提供给 ServiceMonitor 选取让 Prometheus Server 来获取信息。简单的说就是 Prometheus 监控的对象,例如之前了解的 Node Exporter Service、Mysql Exporter Service 等等。
Alertmanager: Alertmanager 也是一个自定义资源类型,由 Operator 根据资源描述内容来部署 Alertmanager 集群
1、下载配置文件
官方地址:https://github.com/coreos/kube-prometheus
因为整个项目并没有多大,这里我把整个项目克隆下来,你也可以下载单独的文件,把https://github.com/coreos/kube-prometheus/tree/master/manifests下面的文件全部下载到本地。
[root@k8s-master01 k8s]# git clone https://github.com/coreos/kube-prometheus.git
2、部署
2.1 配置清单yml文件归档
## 因为官方把所有资源配置文件都放到一个文件目录下,这里我们为了方便,把不同服务的清单文件分别归档
[root@k8s-master01 ~]# cd /opt/k8s/kube-prometheus/manifests
[root@k8s-master01 manifests]# mkdir serviceMonitor operator grafana kube-state-metrics alertmanager node-exporter adapter prometheus [root@k8s-master01 manifests]# mv *-serviceMonitor* serviceMonitor/ [root@k8s-master01 manifests]# mv 0prometheus-operator* operator/ [root@k8s-master01 manifests]# mv grafana-* grafana/ [root@k8s-master01 manifests]# mv kube-state-metrics-* kube-state-metrics/ [root@k8s-master01 manifests]# mv alertmanager-* alertmanager/ [root@k8s-master01 manifests]# mv node-exporter-* node-exporter/ [root@k8s-master01 manifests]# mv prometheus-adapter-* adapter/ [root@k8s-master01 manifests]# mv prometheus-* prometheus/
2.2 部署operator
## 首先创建prometheus监控专有命名空间
[root@k8s-master01 manifests]# kubectl apply -f 00namespace-namespace.yaml
## 部署operator
[root@k8s-master01 manifests]# kubectl apply -f operator/
## 查看pod运行情况,配置清单中镜像仓库地址为,quay.io,所以无需进行其它操作
[root@k8s-master01 manifests]# kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
prometheus-operator-69bd579bf9-mjsxz 1/1 Running 0 20s
2.3 部署metrics
这里部署metrics之前,需要先确定集群中kube-apiserver是否已经开启聚合(支持集群接入第三方api)以及其它组件参数是否正确,否则会导致无法获取数据的情况出现,具体请参考前面文章K8S从入门到放弃系列-(13)Kubernetes集群mertics-server部署.
## 这里addon-resizer服务镜像使用的是google的仓库,我们修改为阿里云仓库
[root@k8s-master01 manifests]# vim kube-state-metrics/kube-state-metrics-deployment.yaml
#image: k8s.gcr.io/addon-resizer:1.8.4 ## 原有配置,注释修改为一下地址
image: registry.aliyuncs.com/google_containers/addon-resizer:1.8.4
[root@k8s-master01 kube-state-metrics]# kubectl apply -f kube-state-metrics/
2.4 部署其它组件
其它组件按照以上部署即可,镜像无需FQ均可以正常下载。镜像下载速度取决与本地网络状况。
[root@k8s-master01 kube-state-metrics]# kubectl apply -f adapter/ [root@k8s-master01 kube-state-metrics]# kubectl apply -f alertmanager/ [root@k8s-master01 kube-state-metrics]# kubectl apply -f node-exporter/ [root@k8s-master01 kube-state-metrics]# kubectl apply -f grafana/ [root@k8s-master01 kube-state-metrics]# kubectl apply -f prometheus/ [root@k8s-master01 kube-state-metrics]# kubectl apply -f serviceMonitor/
## 部署完成后,可以查看下个资源运行部署详情
NAME READY STATUS RESTARTS AGE
pod/grafana-558647b59-bhqmq 1/1 Running 0 94m
pod/kube-state-metrics-79d4446fb5-5mj7d 4/4 Running 0 98m
pod/node-exporter-4xq5t 2/2 Running 0 111m
pod/node-exporter-9b88m 2/2 Running 0 111m
pod/node-exporter-fdntx 2/2 Running 0 111m
pod/node-exporter-mwbxj 2/2 Running 0 111m
pod/node-exporter-tn7tl 2/2 Running 0 111m
pod/prometheus-adapter-57c497c557-vbgxd 1/1 Running 0 144m
pod/prometheus-k8s-0 3/3 Running 0 96m
pod/prometheus-k8s-1 3/3 Running 0 96m
pod/prometheus-operator-69bd579bf9-mjsxz 1/1 Running 0 155m
service/grafana ClusterIP 10.254.42.208 <none> 3000/TCP 94m
service/kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 104m
service/node-exporter ClusterIP None <none> 9100/TCP 111m
service/prometheus-adapter ClusterIP 10.254.107.95 <none> 443/TCP 144m
service/prometheus-k8s ClusterIP 10.254.82.246 <none> 9090/TCP 96m
service/prometheus-operated ClusterIP None <none> 9090/TCP 96m
service/prometheus-operator ClusterIP None <none> 8080/TCP 156m
daemonset.apps/node-exporter 5 5 5 5 5 beta.kubernetes.io/os=linux 111m
deployment.apps/grafana 1/1 1 1 94m
deployment.apps/kube-state-metrics 1/1 1 1 98m
deployment.apps/prometheus-adapter 1/1 1 1 144m
deployment.apps/prometheus-operator 1/1 1 1 156m
replicaset.apps/grafana-558647b59 1 1 1 94m
replicaset.apps/kube-state-metrics-5b86559fd5 0 0 0 98m
replicaset.apps/kube-state-metrics-79d4446fb5 1 1 1 98m
replicaset.apps/prometheus-adapter-57c497c557 1 1 1 144m
replicaset.apps/prometheus-operator-69bd579bf9 1 1 1 156m
statefulset.apps/prometheus-k8s 2/2 96m
3、创建ingress服务
这里我没有采用NodePort的方式暴露服务,而是使用的Ingress,具体Ingress安装部署,查看前面文章K8S从入门到放弃系列-(15)Kubernetes集群Ingress部署
3.1 编辑ingress配置文件
### 配置prometheus、grafana、alertmanager三个服务可视化web界面Ingress访问
[root@k8s-master01 manifests]# cat ingress-all-svc.yml apiVersion: extensions/v1beta1 kind: Ingress metadata: name: prometheus-ing namespace: monitoring spec: rules: - host: prometheus.monitoring.k8s.local http: paths: - backend: serviceName: prometheus-k8s servicePort: 9090 --- apiVersion: extensions/v1beta1 kind: Ingress metadata: name: grafana-ing namespace: monitoring spec: rules: - host: grafana.monitoring.k8s.local http: paths: - backend: serviceName: grafana servicePort: 3000 --- apiVersion: extensions/v1beta1 kind: Ingress metadata: name: alertmanager-ing namespace: monitoring spec: rules: - host: alertmanager.monitoring.k8s.local http: paths: - backend: serviceName: alertmanager-main servicePort: 9093
[root@k8s-master01 manifests]# kubectl apply -f ingress-all-svc.yml
## 可以看到三个服务对应域名已经创建
[root@k8s-master01 manifests]# kubectl get ingress -n monitoring
NAME HOSTS ADDRESS PORTS AGE
alertmanager-ing alertmanager.monitoring.k8s.local 80 3d21h
grafana-ing grafana.monitoring.k8s.local 80 3d21h
prometheus-ing prometheus.monitoring.k8s.local 80 3d21h
## 查看ingress暴露svc端口,后面访问需要加上端口号
[root@k8s-master01 manifests]# kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx NodePort 10.254.102.184 <none> 80:33848/TCP,443:45891/TCP 4d3h
4、访问
配置本地host解析,路径:C:\Windows\System32\drivers\etc\hosts
172.16.11.123 prometheus.monitoring.k8s.local 172.16.11.123 grafana.monitoring.k8s.local 172.16.11.123 alertmanager.monitoring.k8s.local
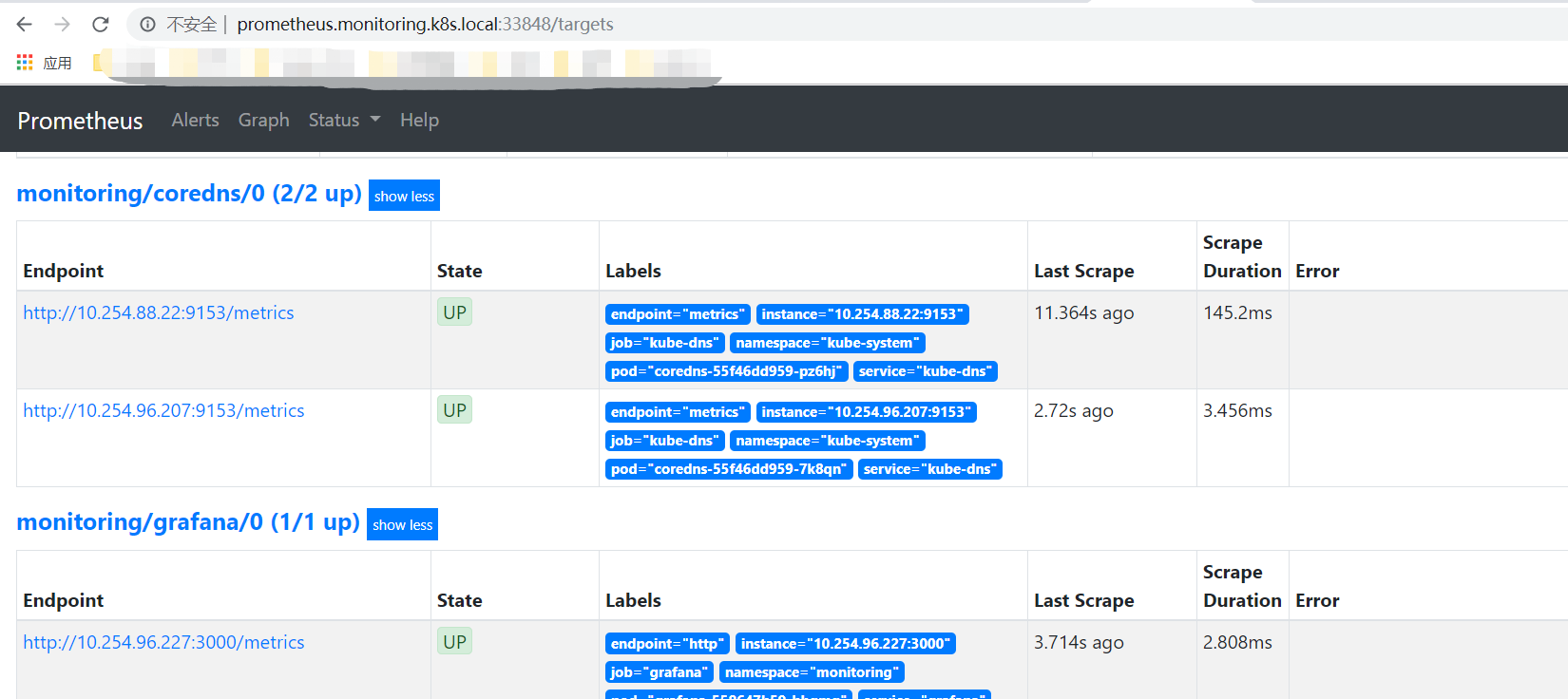
浏览器打开http://prometheus.monitoring.k8s.local:33848,可以看到已经监控的主机及pod
4.2 问题
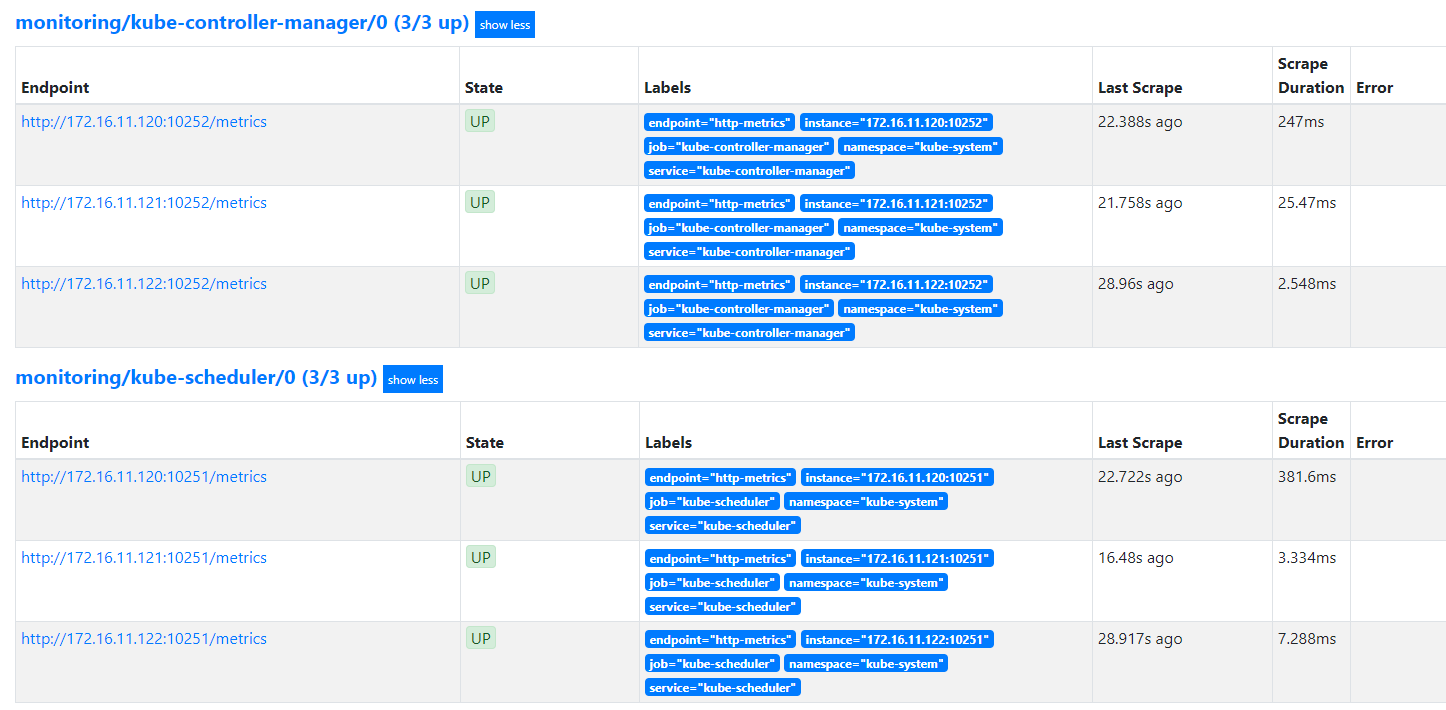
这里部署好后,查看prometheus target界面,看到kube-controller-manager、kube-scheduler目标主机都为0

原因分析:
这是因为serviceMonitor选择svc时,是根据labels标签选取,而在指定的命名空间(kube-system),并没有对应的标签。kube-apiserver之所以正常是因为kube-apiserver 服务 namespace 在default使用默认svc kubernetes。其余组件服务在kube-system 空间 ,需要单独创建svc。
## 查看serviceMonitor选取svc规则
[root@k8s-master01 manifests]# grep -2 selector serviceMonitor/prometheus-serviceMonitorKube* serviceMonitor/prometheus-serviceMonitorKubeControllerManager.yaml- matchNames: serviceMonitor/prometheus-serviceMonitorKubeControllerManager.yaml- - kube-system serviceMonitor/prometheus-serviceMonitorKubeControllerManager.yaml: selector: serviceMonitor/prometheus-serviceMonitorKubeControllerManager.yaml- matchLabels: serviceMonitor/prometheus-serviceMonitorKubeControllerManager.yaml- k8s-app: kube-controller-manager -- serviceMonitor/prometheus-serviceMonitorKubelet.yaml- matchNames: serviceMonitor/prometheus-serviceMonitorKubelet.yaml- - kube-system serviceMonitor/prometheus-serviceMonitorKubelet.yaml: selector: serviceMonitor/prometheus-serviceMonitorKubelet.yaml- matchLabels: serviceMonitor/prometheus-serviceMonitorKubelet.yaml- k8s-app: kubelet -- serviceMonitor/prometheus-serviceMonitorKubeScheduler.yaml- matchNames: serviceMonitor/prometheus-serviceMonitorKubeScheduler.yaml- - kube-system serviceMonitor/prometheus-serviceMonitorKubeScheduler.yaml: selector: serviceMonitor/prometheus-serviceMonitorKubeScheduler.yaml- matchLabels: serviceMonitor/prometheus-serviceMonitorKubeScheduler.yaml- k8s-app: kube-scheduler
##查看kube-system命名空间下的svc,可以看到并没有kube-scheduler、kube-controller-manager
[root@k8s-master01 manifests]# kubectl -n kube-system get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.254.0.2 <none> 53/UDP,53/TCP,9153/TCP 49d
kubelet ClusterIP None <none> 10250/TCP 4d2h
但是却有对应的ep(没有带任何label)被创建,另外如果你的集群是kubeadm部署的就没有kubelet的ep,二进制部署的会有。
[root@k8s-master01 manifests]# kubectl get ep -n kube-system
NAME ENDPOINTS AGE
kube-controller-manager <none> 6m38s
kube-dns 10.254.88.22:53,10.254.96.207:53,10.254.88.22:53 + 3 more... 49d
kube-scheduler <none> 6m39s
kubelet 172.16.11.120:10255,172.16.11.121:10255,172.16.11.122:10255 + 12 more... 4d3h
解决:
1)创建kube-controller-manager、kube-scheduler两个组件服务的集群svc,需要打上对应的标签,使其可以被servicemonitor选中。
## svc服务
[root@k8s-master01 manifests]# cat controller-scheduler-svc.yml apiVersion: v1 kind: Service metadata: namespace: kube-system name: kube-controller-manager labels: k8s-app: kube-controller-manager spec: type: ClusterIP clusterIP: None ports: - name: http-metrics port: 10252 targetPort: 10252 protocol: TCP --- apiVersion: v1 kind: Service metadata: namespace: kube-system name: kube-scheduler labels: k8s-app: kube-scheduler spec: type: ClusterIP clusterIP: None ports: - name: http-metrics port: 10251 targetPort: 10251 protocol: TCP
#####################注意##################################
这里可以看到定义的svc并没有使用selector去过滤pod的标签,是因为
kube-controller-manager、kube-scheduler属于非pod模式运行,所以
无需使用selector过滤,但是需要手动创建endpoints与svc进行映射。
官方文档解释:https://kubernetes.io/zh/docs/concepts/services-networking/service/
##########################################################
## ep修改,二进制部署需要我们把svc对应的ep的属性修改下,ip地址修改为自己的集群ip
[root@k8s-master01 manifests]# cat controller-scheduler-ep.yml
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-controller-manager
name: kube-controller-manager
namespace: kube-system
subsets:
- addresses:
- ip: 172.16.11.120
- ip: 172.16.11.121
- ip: 172.16.11.122
ports:
- name: http-metrics
port: 10252
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-scheduler
name: kube-scheduler
namespace: kube-system
subsets:
- addresses:
- ip: 172.16.11.120
- ip: 172.16.11.121
- ip: 172.16.11.122
ports:
- name: http-metrics
port: 10251
protocol: TCP
## 查看创建资源
NAME ENDPOINTS AGE
endpoints/kube-controller-manager 172.16.11.120:10252,172.16.11.121:10252,172.16.11.122:10252 18m
endpoints/kube-dns 10.254.88.22:53,10.254.96.207:53,10.254.88.22:53 + 3 more... 49d
endpoints/kube-scheduler 172.16.11.120:10251,172.16.11.121:10251,172.16.11.122:10251 18m
endpoints/kubelet 172.16.11.120:10255,172.16.11.121:10255,172.16.11.122:10255 + 12 more... 4d3h
service/kube-controller-manager ClusterIP None <none> 10252/TCP 12m
service/kube-dns ClusterIP 10.254.0.2 <none> 53/UDP,53/TCP,9153/TCP 49d
service/kube-scheduler ClusterIP None <none> 10251/TCP 12m
service/kubelet ClusterIP None <none> 10250/TCP 4d3h
2)修改kube-controller-manager、kube-scheduler监听地址使其能访问 metrics。
## 修改为0.0.0.0
--address=0.0.0.0
修改完,重启服务,再次查看prometheus targets界面,可以看到都已经正常监听目标主机服务
5、grafana监控查看
1)可以看到grafana已经有多个dashboard页面
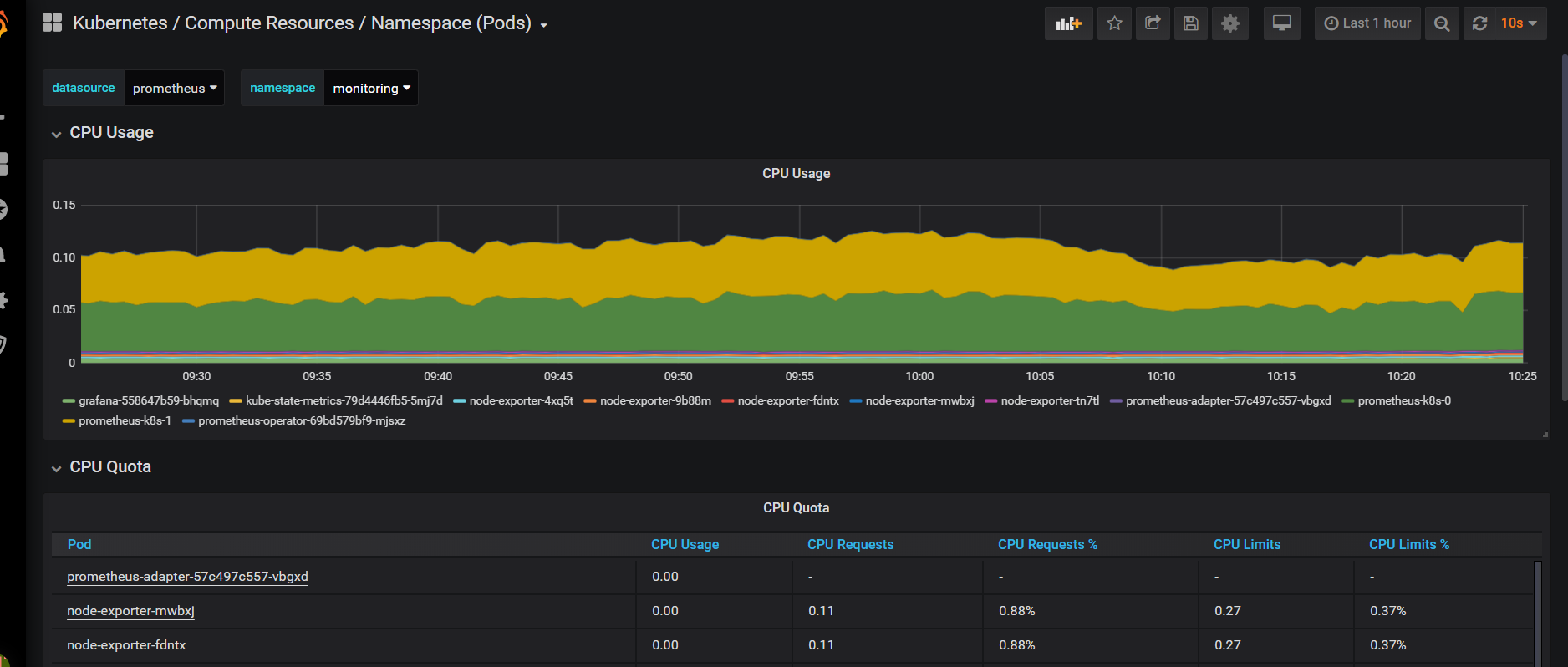
2)可以正常监控

 浙公网安备 33010602011771号
浙公网安备 33010602011771号