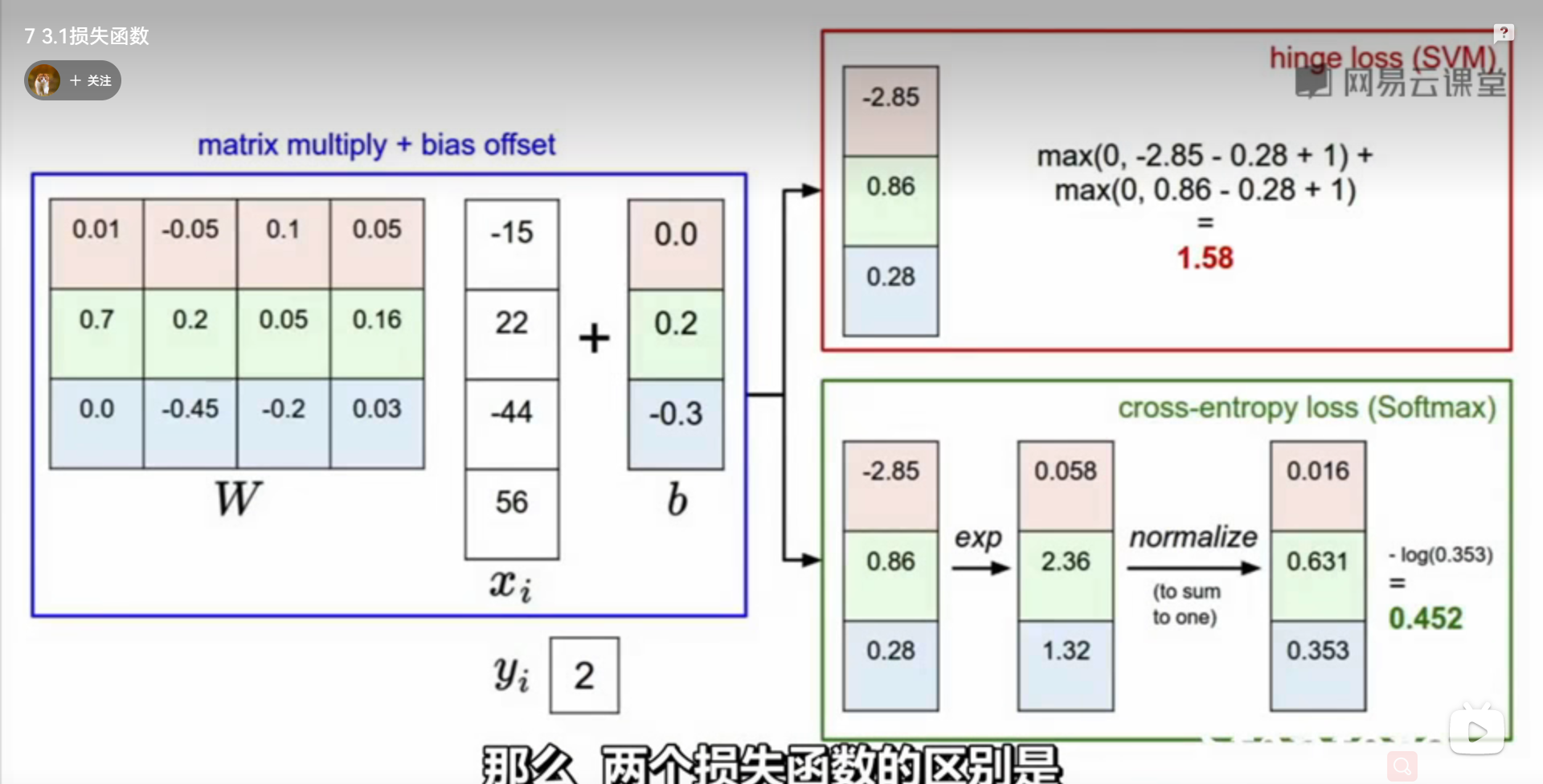
2.LOSS(svm和softmax)
1.loss设计
主要是表征预测的类别的准确性,我认为主要是 为了边界化的问题
2.svm
svm的设计主要是为了保证预测的准确性,一旦超过了边界,那么即使我们修改值或者让错误值和正确值差距很大,也不会改变损失值,依旧是0,这点也是svm的特性,不会过分强调之间的实际差距
svm分类器
计算公式如下:

3.softmax
softmax的函数设计,会鼓励正确的分类,数落错误的分类,也就是期待正确分类的对数概率变高,而错误分类的对数分类的概率变低,相比svm 正确分类与错误分类的得分值会对 softmax的 对数值概率产生较大影响,这一点和svm形成相反对比。

4.softmax 与 svm
本文来自博客园,作者:TCcjx,转载请注明原文链接:https://www.cnblogs.com/tccjx/p/16566921.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号