pytorch搭建多层感知机(使用detaset进行重构数据集和dataloader类进行小批次训练数据集)
项目演示是在jupyter notebook上运行的
import torch
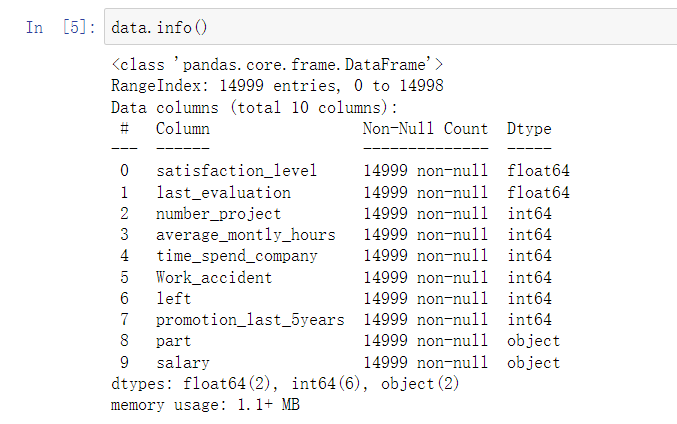
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# 1.读取数据
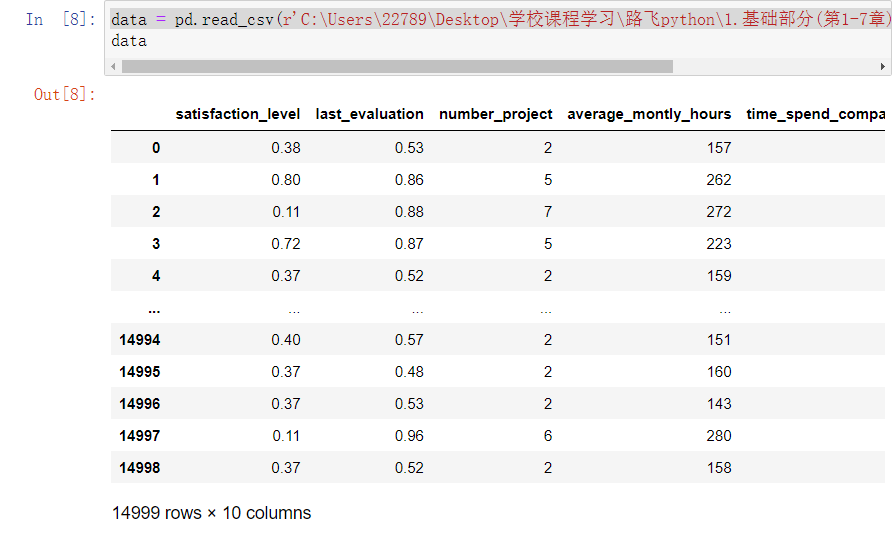
data = pd.read_csv(r'C:\Users\22789\Desktop\学校课程学习\路飞python\1.基础部分(第1-7章)参考代码和数据集\第5章\HR.csv')
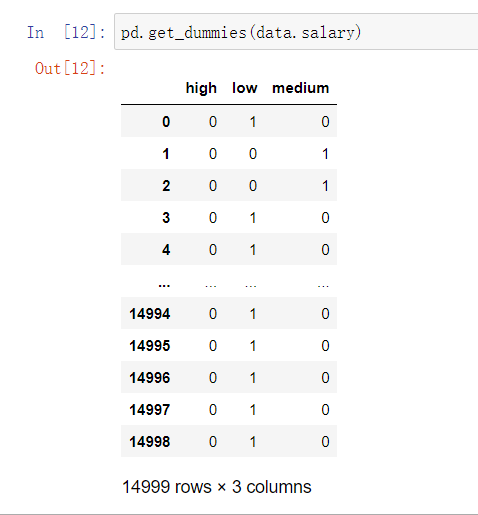
# 2.对数据salary和part进行编码处理
data = data.join(pd.get_dummies(data.salary))
del data['salary']
data = data.join(pd.get_dummies(data.part))
del data['part']
# 3.进行数据预处理
Y_data = data.left.values.reshape(-1,1)
Y = torch.from_numpy(Y_data).type(torch.FloatTensor)
X_data = data[[c for c in data.columns if c != 'left']].values
X = torch.from_numpy(X_data).type(torch.FloatTensor)
# 4.创建模型
from torch import nn
"""
自定义模型:
nn.Module: 继承这个类
__init__: 初始化所有的层
forward: 定义模型的运算过程(前向传播的过程)
"""
class Model(nn.Module):
def __init__(self):
super().__init__()#继承父类中的所有属性
self.linear_1 = nn.Linear(20,64)
self.linear_2 = nn.Linear(64,64)
self.linear_3 = nn.Linear(64,1)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
def forward(self,input):
x = self.linear_1(input)
x = self.relu(x)
x = self.linear_2(x)
x = self.relu(x)
x = self.linear_3(x)
x = self.sigmoid(x)
return x
model = Model()
# 模型改写
import torch.nn.functional as F #提供一种函数式的调用方法
class Model(nn.Module):
def __init__(self):
super().__init__()#继承父类中的所有属性
self.linear_1 = nn.Linear(20,64)
self.linear_2 = nn.Linear(64,64)
self.linear_3 = nn.Linear(64,1)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
def forward(self,input):
x = F.relu(self.linear_1(input))
x = F.relu(self.linear_2(x)) # 主要是简化代码
x = F.sigmoid(self.linear_3(x))
return x
lr = 0.0001#设置学习率
def get_model():
model = Model()
opt = torch.optim.Adam(model.parameters(),lr=lr)
return model,opt
# 5.定义损失函数
loss_fn = nn.BCELoss()
batch = 64 # 每个批次送进去 64个样本
number_of_batches = len(data)//batch
number_of_batches
epoches = 100 #总共训练100个epoch
# 6.训练过程
for epoch in range(epoches):
for i in range(number_of_batches):
start = i*batch
end = start+ batch
x = X[start:end]
y = Y[start:end]
y_pred = model(x)
loss = loss_fn(y_pred,y)
opt.zero_grad()
loss.backward()
opt.step()
print(f'第{epoch+1}轮训练结束,损失值为{loss_fn(model(X),Y)}')
离职分布情况

# 1.使用dataset类进行重构
from torch.utils.data import TensorDataset
HRdataset = TensorDataset(X,Y) # 构建样本和标签
model,opt =get_model()
for epoch in range(epoches):
for i in range(number_of_batches):
x,y = HRdataset[i*batch:i*batch+batch]
y_pred = model(x)
loss = loss_fn(y_pred,y)
opt.zero_grad()
loss.backward()
opt.step()
print(f'第{epoch+1}轮训练结束,损失值为{loss_fn(model(X),Y)}')
# 2.使用dataloader类进行构建训练数据集
from torch.utils.data import DataLoader
HR_ds = TensorDataset(X,Y)
HT_dl = DataLoader(HR_ds,batch_size=batch,shuffle=True)
# 相当于每次直接取出batch个大小的训练数据,并且打乱
model,opt = get_model()
for epoch in range(epoches):
for x,y in HT_dl:
y_pred = model(x)
loss = loss_fn(y_pred,y)
opt.zero_grad()
loss.backward()
opt.step()
print(f'第{epoch+1}轮训练结束,损失值为{loss_fn(model(X),Y)}')
重点
添加验证和过拟合与欠拟合
过拟合:对于训练数据过度拟合,对于未知数据预测很差
欠拟合:对于训练数据拟合不太够,当然对于未知数据预测也很差
机器学习库 sklearn
from sklearn.model_selection import train_test_split
train_x,test_x,train_y,test_y = train_test_split(X_data,Y_data)
#默认训练数据集和验证数据集划分比例 3:1
train_x = torch.from_numpy(train_x).type(torch.float32)
train_y = torch.from_numpy(train_y).type(torch.float32)
test_x = torch.from_numpy(test_x).type(torch.float32)
test_y = torch.from_numpy(test_y).type(torch.float32)
train_ds = TensorDataset(train_x,train_y)
train_dl = DataLoader(train_ds,batch_size=batch,shuffle=True)
test_ds = TensorDataset(train_x,train_y)
test_dl = DataLoader(train_ds,batch_size=batch)
def accuracy(y_pred,y_true):
y_pred = (y_pred > 0.5).type(torch.int32)
acc = (y_pred == y_true).float().mean()
return acc
for epoch in range(epoches):
for x,y in train_ds:
y_pred = model(x)
loss = loss_fn(y_pred,y)
opt.zero_grad()
loss.backward()
opt.step()
with torch.no_grad():
epoch_accuracy = accuracy(model(train_x),train_y)
epoch_loss = loss_fn(model(train_x),train_y).data
epoch_test_accuracy = accuracy(model(test_x),test_y)
epoch_test_loss = loss_fn(model(test_x),test_y).data
print("epoch:",epoch,'loss:',loss_fn(model(X),Y).data.item(),'acc:',epoch_accuracy.item())
print(f'验证集准确度:{epoch_test_accuracy},验证集loss:{epoch_test_loss}')
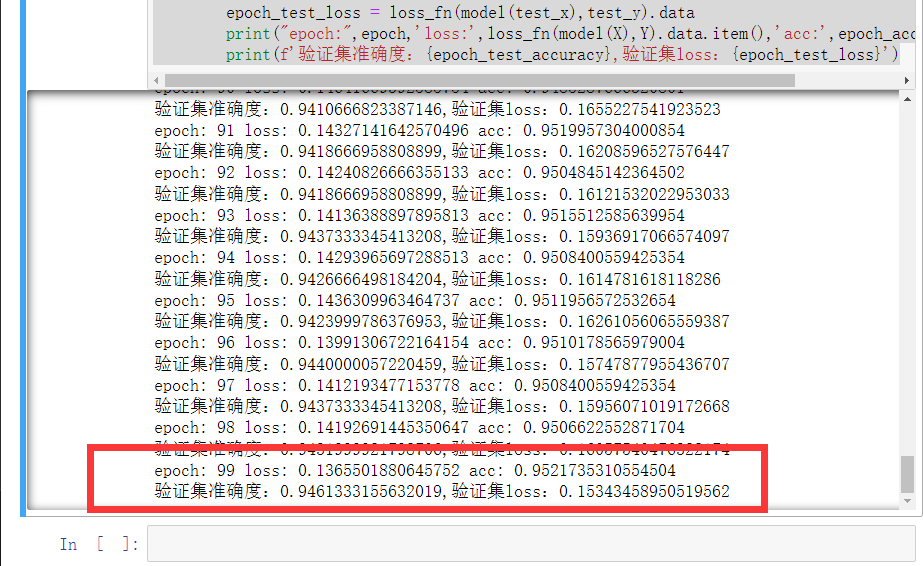
训练一百轮的效果:
本文来自博客园,作者:TCcjx,转载请注明原文链接:https://www.cnblogs.com/tccjx/articles/16475421.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号