pytorch10——使用TensorBoard可视化训练过程
训练过程的可视化在深度学习模型训练中扮演着重要的角色。学习的过程是一个优化的过程,我们需要找到最优的点作为训练过程的输出产物。一般来说,我们会结合训练集的损失函数核验证集的损失函数,绘制两条损失函数的曲线来确定训练的终点,找到对应的模型用于测试。那么除了记录训练中每个epoch的loss值,能否实现观察损失函数曲线的变化,及时捕捉的变化呢?
此外,我们也希望可视化其他内容,如输入数据(尤其是图片)、模型结构、参数分布等,这些对于我们在debug中查找问题来源非常重要(比如输入数据和我们想象的是否一致)。
TensorBoard作为一款可视化工具能够满足上面提到的各种需求。TensorBoard由TensorFlow团队开发,最早和TensorFlow配合使用,后来广泛应用于各种深度学习框架的可视化中来。
1.Tensorboard安装
pip install tensorboardX
也可以使用Pytorch自带的tensorboard工具,此时不需要额外安装tensorboard。
2.Tensorboard可视化的基本逻辑
我们将Tensorboard看作一个记录员,它可以记录我们指定的数据,包括模型的每一层的feature map,权重,以及训练loss等等。Tensorboard将记录下来的内容保存在一个用户指定的文件夹里,程序不断运行中Tensorboard会不断记录。记录下的内容可以通过网页的形式加以可视化。
3.Tensorboard的配置和启动
在使用Tensorboard前,我们需要先指定一个文件夹供tensorboard保存记录下来的数据,然后调用tensorboard中SummaryWriter作为上述“记录员”。
from tensorboardX import SummaryWriter
writer = SummaryWriter('./runs')
上面的操作实例化SummaryWritter为变量writer,并指定writer的输出目录为当前目录下的"runs"目录。也就是说,之后tensorboard记录下来的内容都会保存在runs。
如果使用PyTorch自带的tensorboard,则采用如下方式import:
from torch.utils.tensorboard import SummaryWriter
我们也可以手动往runs文件夹里添加数据用于可视化,或者把runs文件夹里的数据放到其他机器上可视化。只要数据被记录,你可以将这个数据分享给其他人,其他人在安装了tensorboard的情况下就会看到你分享的数据。
启动tensorboard也很简单,在命令行中输入
tensorboard --logdir=/path/to/logs/ --port=xxxx
其中“path/to/logs/"是指定的保存tensorboard记录结果的文件路径(等价于上面的“./runs",port是外部访问TensorBoard的端口号,可以通过访问ip:port访问tensorboard,这一操作和jupyter notebook的使用类似。如果不是在服务器远程使用的话则不需要配置port。
有时,为了tensorboard能够不断地在后台运行,也可以使用nohup命令或者tmux工具来运行
4.TensorBoard模型结构可视化
首先定义模型:
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3,out_channels=32,kernel_size = 3)
self.pool = nn.MaxPool2d(kernel_size = 2,stride = 2)
self.conv2 = nn.Conv2d(in_channels=32,out_channels=64,kernel_size = 5)
self.adaptive_pool = nn.AdaptiveMaxPool2d((1,1))
self.flatten = nn.Flatten()
self.linear1 = nn.Linear(64,32)
self.relu = nn.ReLU()
self.linear2 = nn.Linear(32,1)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
x = self.conv1(x)
x = self.pool(x)
x = self.conv2(x)
x = self.pool(x)
x = self.adaptive_pool(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.relu(x)
x = self.linear2(x)
y = self.sigmoid(x)
return y
model = Net()
print(model)
输出如下:
Net(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1))
(adaptive_pool): AdaptiveMaxPool2d(output_size=(1, 1))
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear1): Linear(in_features=64, out_features=32, bias=True)
(relu): ReLU()
(linear2): Linear(in_features=32, out_features=1, bias=True)
(sigmoid): Sigmoid()
)
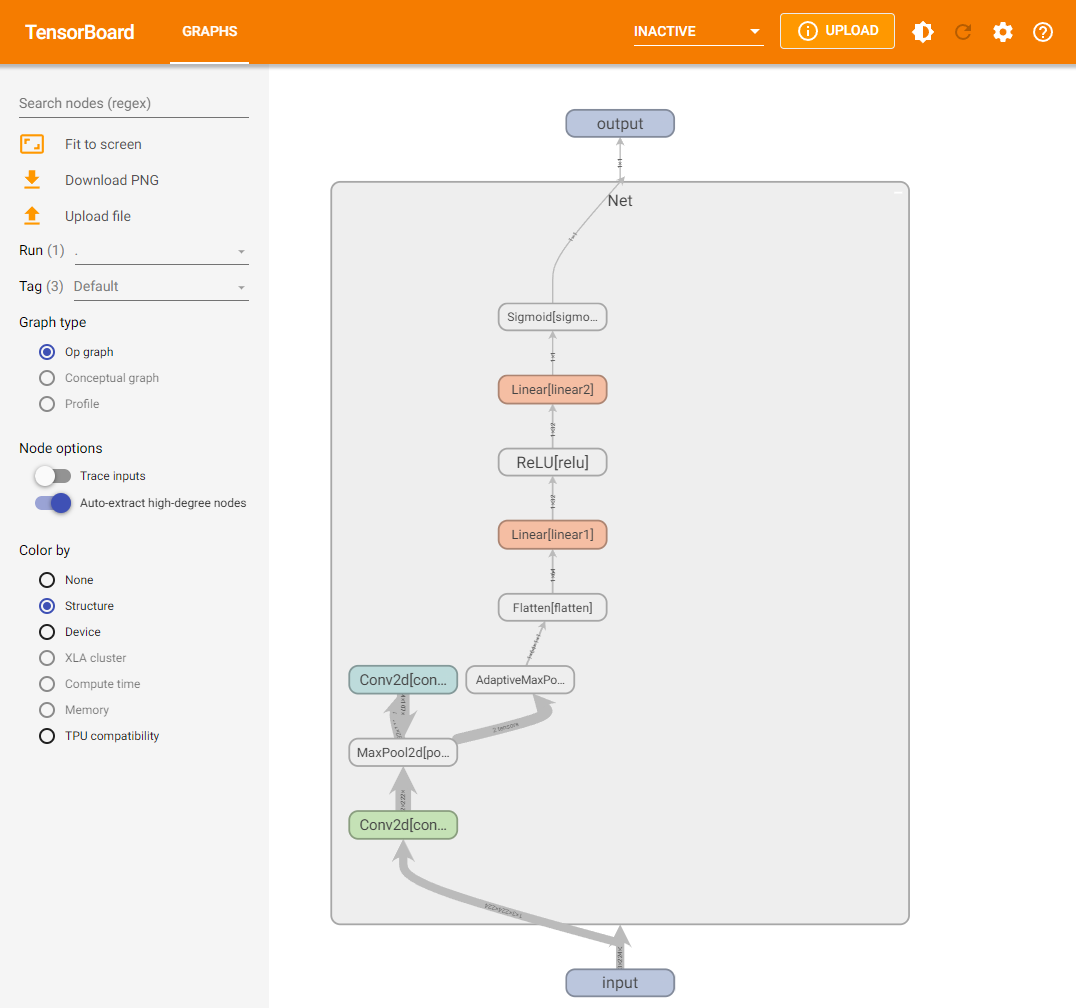
可视化模型的思路和上一节是差不多的,都是给定一个输入数据,前后传播得到模型结构,再通过Tensorboard进行可视化,使用add_graph:
writer.add_graph(model, input_to_model = torch.rand(1, 3, 224, 224))
writer.close()
展示结果如下(其中框内部分初始会显示为“Net",需要双击后才会展开):
5.Tensorboard图像可视化
当我们做图像相关的任务时,可以方便地将所处理的图片在tensorboard中进行可视化展示。
- 对于单张图片的显示使用add_image
- 对于多张图片的显示使用add_images
- 有时需要使用torchvision.utils.make_grid将多张图片拼成一张图片后,用writer.add_image显示
这里我们使用torchvision的CIFAR10数据集为例:
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
transform_train = transforms.Compose(
[transforms.ToTensor()])
transform_test = transforms.Compose(
[transforms.ToTensor()])
train_data = datasets.CIFAR10(".", train=True, download=True, transform=transform_train)
test_data = datasets.CIFAR10(".", train=False, download=True, transform=transform_test)
train_loader = DataLoader(train_data, batch_size=64, shuffle=True)
test_loader = DataLoader(test_data, batch_size=64)
images, labels = next(iter(train_loader))
# 仅查看一张图片
writer = SummaryWriter('./pytorch_tb')
writer.add_image('images[0]', images[0])
writer.close()
# 将多张图片拼接成一张图片,中间用黑色网格分割
# create grid of images
writer = SummaryWriter('./pytorch_tb')
img_grid = torchvision.utils.make_grid(images)
writer.add_image('image_grid', img_grid)
writer.close()
# 将多张图片直接写入
writer = SummaryWriter('./pytorch_tb')
writer.add_images("images",images,global_step = 0)
writer.close()
依次运行上面三组可视化(注意不要同时在notebook的一个单元格内运行),得到的可视化结果如下(最后运行的结果在最上面):
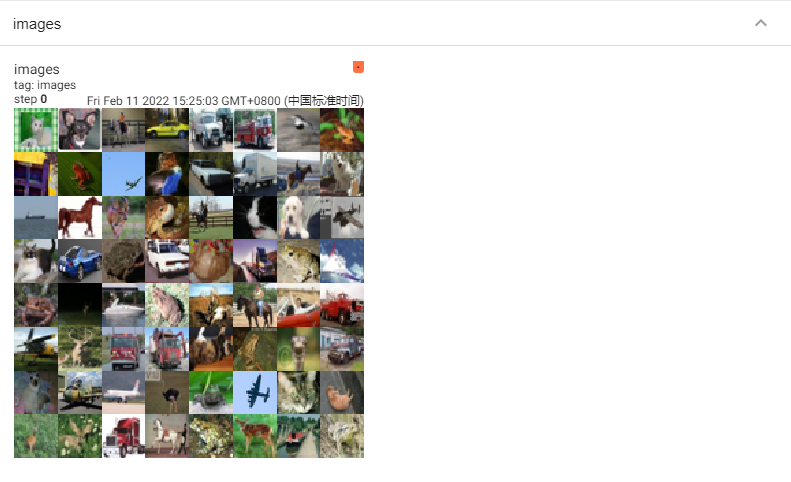
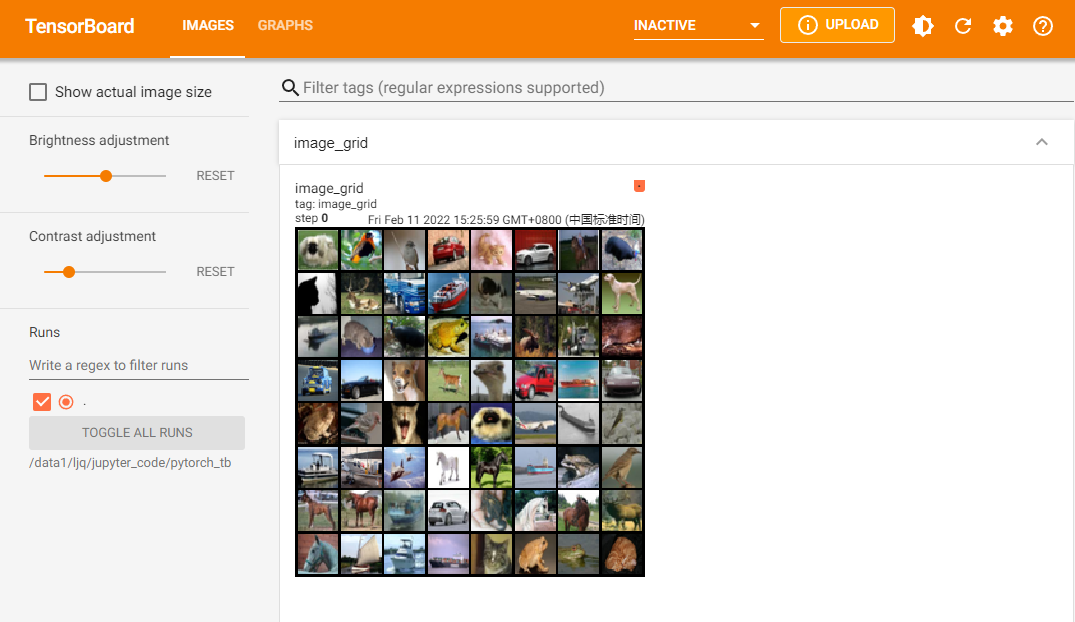
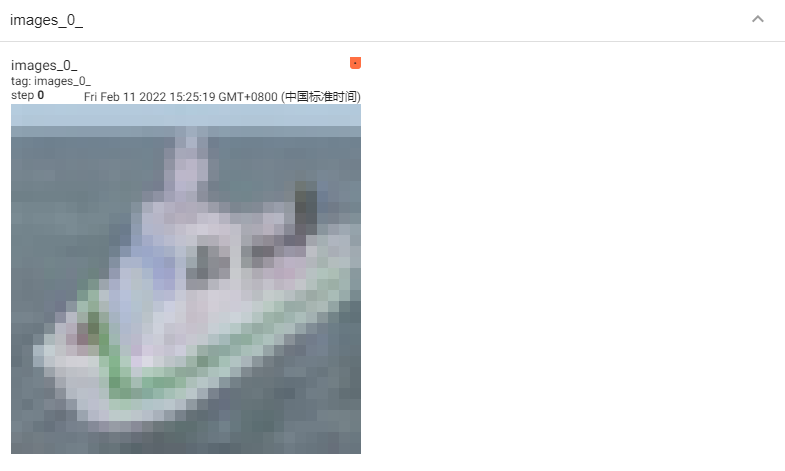
另外注意上方menu部分,刚刚只有“GRAPHS"栏对应模型的可视化,现在则多出了”IMAGES“栏对应图像的可视化。左侧的滑动按钮可以调整图像的亮度和对比度。
此外,除了可视化原始图像,TensorBoard提供的可视化方案自然也适用于我们在Python中用matplotlib等工具绘制的其他图像,用于展示分析结果等内容。
6.tensorboard连续变量可视化
writer = SummaryWriter('./pytorch_tb')
for i in range(500):
x = i
y = x**2
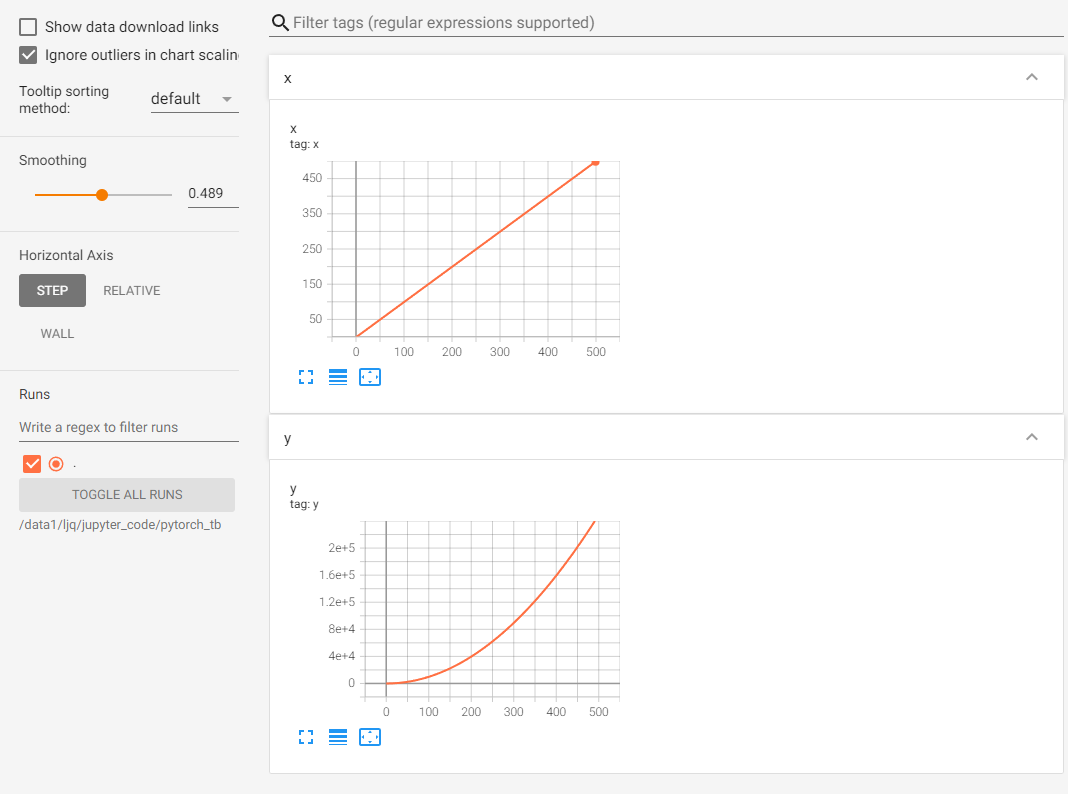
writer.add_scalar("x", x, i) #日志中记录x在第step i 的值
writer.add_scalar("y", y, i) #日志中记录y在第step i 的值
writer.close()
可视化结果:
如果想在同一张图中显示多个曲线,则需要分别建立存放子路径(使用SummaryWriter指定路径即可自动创建,但需要在tensorboard运行目录下),同时在add_scalar中修改曲线的标签使其一致即可:
writer1 = SummaryWriter('./pytorch_tb/x')
writer2 = SummaryWriter('./pytorch_tb/y')
for i in range(500):
x = i
y = x*2
writer1.add_scalar("same", x, i) #日志中记录x在第step i 的值
writer2.add_scalar("same", y, i) #日志中记录y在第step i 的值
writer1.close()
writer2.close()
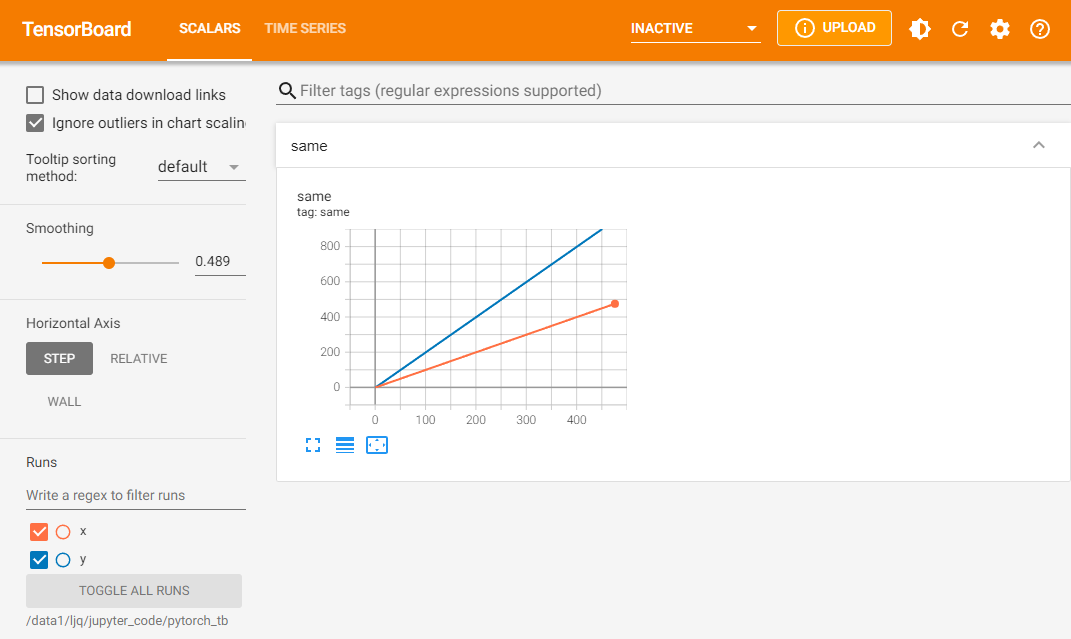
这里也可以用一个writer,但for循环中不断创建SummaryWriter不是一个好选项。此时左下角的Runs部分出现了勾选项,我们可以选择我们想要可视化的曲线。曲线名称对应存放子路径的名称(这里是x和y)。
这部分功能非常适合损失函数的可视化,可以帮助我们更加直观地了解模型的训练情况,从而确定最佳的checkpoint。左侧的Smoothing滑动按钮可以调整曲线的平滑度,当损失函数震荡较大时,将Smoothing调大有助于观察loss的整体变化趋势。
7.tensorboard参数分布可视化
import torch
import numpy as np
def norm(mean, std): # 创建正态分布的张量模拟参数矩阵
t = std * torch.randn((100, 20)) + mean
return t
writer = SummaryWriter('./pytorch_tb/')
for step, mean in enumerate(range(-10, 10, 1)):
w = norm(mean, 1)
writer.add_histogram("w", w, step)
writer.flush()
writer.close()
结果如下:

总结:
tensorboard本质就是通过对数据的存储然后来实现数据的可视化,功能十分强大。
本文来自博客园,作者:TCcjx,转载请注明原文链接:https://www.cnblogs.com/tccjx/articles/16041645.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号