pytorch06——模型微调
随着深度学习的发展,在大模型的训练上都是在一些较大数据集上进行训练的,比如Imagenet-1k,Imagenet-11k,甚至是ImageNet-21k等。但我们在实际应用中,我们的数据集可能比较小,只有几千张照片,这时从头训练具有几千万参数的大型神经网络是不现实的,因为越大的模型对数据量的要求越高,过拟合无法避免。
因为试用于ImageNet数据集的复杂模型,在一些小的数据集上可能会过拟合,同时因为数据量有限,最终训练得到的模型的精度也可能达不到实用要求。
解决上述问题的方法:
1.收集更多数据集,当然这对于研究成本会大大增加
2.应用迁移学习,从源数据集中学到知识迁移到目标数据集上。迁移学习的一大应用场景就是模型微调,简单的来说就是把在别人训练好的基础上,换成自己的数据集继续训练,来调整参数。Pytorch中提供很多预训练模型,学习如何进行模型微调,可以大大提升自己任务的质量和速度。
1.模型微调的流程
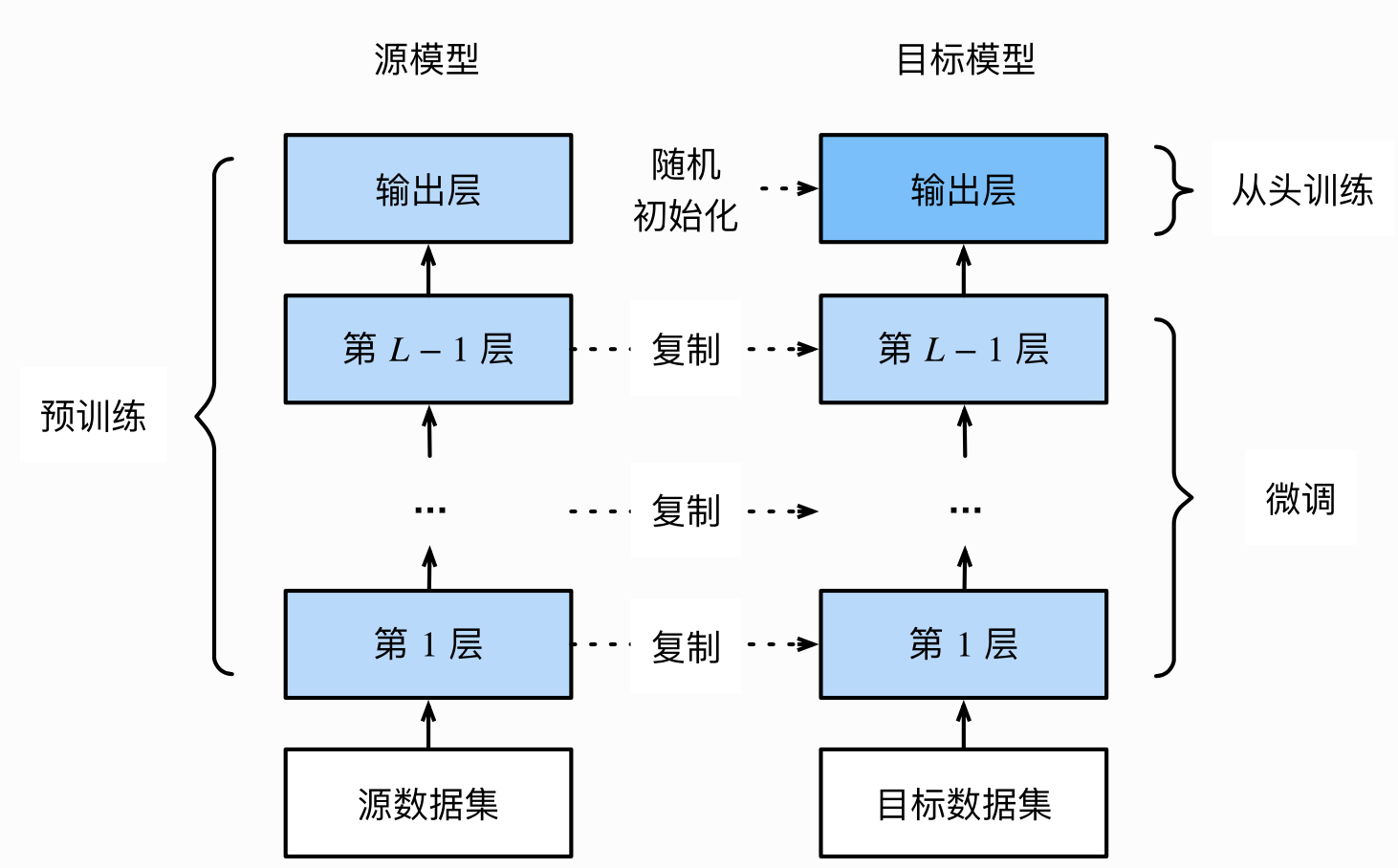
1.1 在源数据集上预训练一个神经网络模型,即源模型。
1.2 创建一个新的神经网络模型,即目标模型。他复制了源模型上除了输出层外的所有模型设计及其参数。我们假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样试用于目标数据集,我们还假设源模型的输出层跟源数据集的标签紧密相关,因此输出层在目标模型上可以采用。
1.3 为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数
1.4 在目标数据集上训练目标模型,我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。
2.使用已经有的模型结构
2.1 实例化网络
import torchvision.models as models
resnet18 = models.resnet18()
# resnet18 = models.resnet18(pretrained=False) 等价于与上面的表达式
alexnet = models.alexnet()
vgg16 = models.vgg16()
squeezenet = models.squeezenet1_0()
densenet = models.densenet161()
inception = models.inception_v3()
googlenet = models.googlenet()
shufflenet = models.shufflenet_v2_x1_0()
mobilenet_v2 = models.mobilenet_v2()
mobilenet_v3_large = models.mobilenet_v3_large()
mobilenet_v3_small = models.mobilenet_v3_small()
resnext50_32x4d = models.resnext50_32x4d()
wide_resnet50_2 = models.wide_resnet50_2()
mnasnet = models.mnasnet1_0()
2.2 传递pretrained参数
通过True或者False来决定是否使用预训练好的权重,在默认情况下(不写参数的情况下)pretrained = False,意味着我们不适用预训练得到的权重,当pretrained = True ,意味着我们将使用一些数据集上预训练得到的权重。
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True)
alexnet = models.alexnet(pretrained=True)
squeezenet = models.squeezenet1_0(pretrained=True)
vgg16 = models.vgg16(pretrained=True)
densenet = models.densenet161(pretrained=True)
inception = models.inception_v3(pretrained=True)
googlenet = models.googlenet(pretrained=True)
shufflenet = models.shufflenet_v2_x1_0(pretrained=True)
mobilenet_v2 = models.mobilenet_v2(pretrained=True)
mobilenet_v3_large = models.mobilenet_v3_large(pretrained=True)
mobilenet_v3_small = models.mobilenet_v3_small(pretrained=True)
resnext50_32x4d = models.resnext50_32x4d(pretrained=True)
wide_resnet50_2 = models.wide_resnet50_2(pretrained=True)
mnasnet = models.mnasnet1_0(pretrained=True)
注意事项:
1.通常Pytorch模型的扩展为.pt或.pth,程序运行时会首先检查默认路径种是否有已经下载的模型权重,如果权重被下载了,下次加载就不需要下载了。
2.一般情况下预训练模型的下载会比较慢,我们可以直接通过迅雷或者其他方式去查看自己的模型里面model_urls,然后手动下载,预训练模型的权重在LInux和Mac的默认下载路径是用户根目录下的.cache文件夹。在windows下就是在C:\Users<username>.cache\torch\hub\checkpoint。我们可以通过使用 torch.utils.model_zoo.load_url()设置权重的下载地址。
3.觉得麻烦的话,还可以将自己的权重下载下来放到同文件夹下,然后再将参数加载网络
self.model = models.resnet50(pretrained=False)
self.model.load_state_dict(torch.load('./model/resnet50-19c8e357.pth'))
4.如果中途强行停止下载的话,一定要把对应路径下的权重文件删除干净,要不然可能会报错。
3.训练特定层
在默认情况下,参数的属性.requires_grad - True,如果我们从头开始训练或微调不需要注意这里。但如果我们正在提取特征并且只想为新初始化的层计算梯度,其他参数不进行改变。那我们就需要通过设置一个requires_grad = False来冻结部分层。
官方例程:
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
4.实例
在下面我们仍旧使用resnet18为例的将1000类改为4类,但是仅改变最后一层的模型参数,不改变特征提取的模型参数;注意我们先冻结模型参数的梯度,再对模型输出部分的全连接层进行修改,这样修改后的全连接层的参数就是可计算梯度的。
import torchvision.models as models
# 冻结参数的梯度
feature_extract = True
model = models.resnet18(pretrained=True)
set_parameter_requires_grad(model, feature_extract)
# 修改模型
num_ftrs = model.fc.in_features
model.fc = nn.Linear(in_features=512, out_features=4, bias=True)
之后在训练过程中,model仍会进行梯度回传,但是参数更新只发生在fc层。通过设定参数的required_grad属性,我们可以实现只对特定层训练的目标,这对实现模型微调很重要
本文来自博客园,作者:TCcjx,转载请注明原文链接:https://www.cnblogs.com/tccjx/articles/16026663.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号